S3に残ったS3ログを列指向フォーマットに圧縮したい
変換手法の候補
CTAS by Athena
→ これで確定
モチベ
S3のログがバケットに残ってるけど、一覧性が悪いしスペース効率も悪いので、圧縮したい
仕様
ログの形式
ログのスキーマ
CREATE EXTERNAL TABLE `s3_access_logs_db.mybucket_logs`(
`bucketowner` STRING,
`bucket_name` STRING,
`requestdatetime` STRING,
`remoteip` STRING,
`requester` STRING,
`requestid` STRING,
`operation` STRING,
`key` STRING,
`request_uri` STRING,
`httpstatus` STRING,
`errorcode` STRING,
`bytessent` BIGINT,
`objectsize` BIGINT,
`totaltime` STRING,
`turnaroundtime` STRING,
`referrer` STRING,
`useragent` STRING,
`versionid` STRING,
`hostid` STRING,
`sigv` STRING,
`ciphersuite` STRING,
`authtype` STRING,
`endpoint` STRING,
`tlsversion` STRING)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex'='([^ ]*) ([^ ]*) \\[(.*?)\\] ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) (\"[^\"]*\"|-) (-|[0-9]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) (\"[^\"]*\"|-) ([^ ]*)(?: ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*))?.*$')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://awsexamplebucket1-logs/prefix/'
ソリューション候補
by creating a cluster in Amazon EMR and converting it using Hive
Apache Spark
列指向フォーマット
結論: ORC を採用
候補
- Parquet
- ORC
VS
Parquet’s compression ratio was much better as compared to ORC.
As per this benchmark Parquet performed better both in terms of compression and query performance. In both cases snappy compression was used.
ORC is more compression efficient
Note that ZLIB in ORC and GZIP in Parquet uses the same compression codec, just the property name is different.
There is not much storage savings when using ORC and Parquet when using the same compression code like
SNAPPY vs SNAPPYandZLIB vs GZIP.

ref
余談
Avro は行指向なので違う
S3ログのパース
parse_datetime(requestdatetime,'dd/MMM/yyyy:HH:mm:ss Z')
date_trunc
クエリ
with trunc AS
(SELECT date_trunc('day', parse_datetime(requestdatetime, 'dd/MMM/yyyy:HH:mm:ss Z')) AS day
FROM "s3_access_logs"."table_name" )
SELECT day,
count() AS count
FROM trunc
GROUP BY day
ORDER BY day
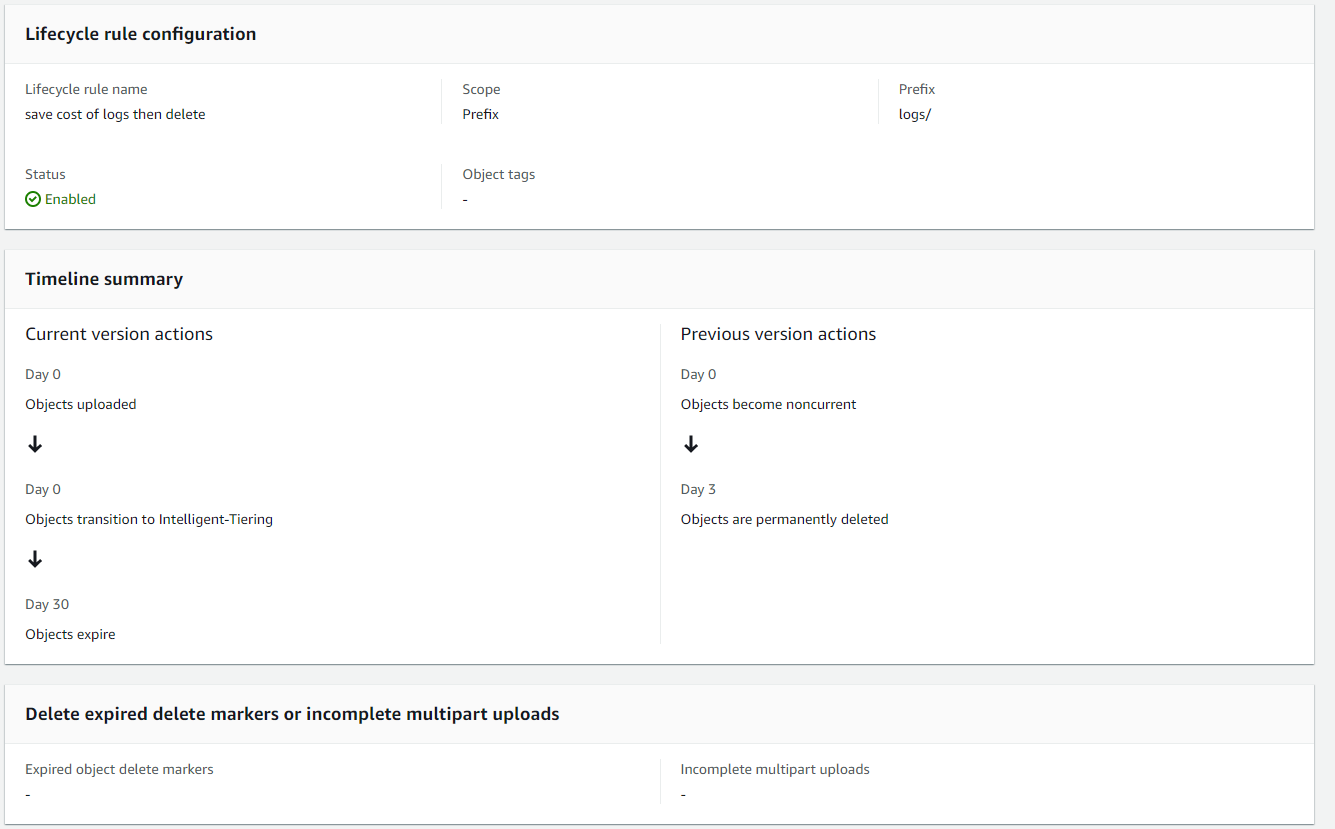
ログの処分
とりあえずコストカット
その後自動削除
S3 のライフサイクル設定UIが分かりやすくなってた
S3 Versioning
もし一度でもバージョニングが有効化されてたら?
Versioning-suspended に遷移することはできる。
suspended
version=null に留意すること