IPFS概要
分散型Webのハイパーメディア[1]プロトコルであるIPFSの概要を解説します。
IPFSとは
IPFS(InterPlanetary File System)とは、P2Pネットワーク上でデータを保存、共有するための分散ファイルシステムを構築するためのプロトコルです。
場所(サーバーやパス)を指定してコンテンツを取得するHTTPに対し、IPFSはコンテンツのハッシュ値を指定してコンテンツを取得します。これをコンテンツアドレス指定(Content Addressing)といいます。コンテンツは接続されたコンピュータ(ピア)から探します。
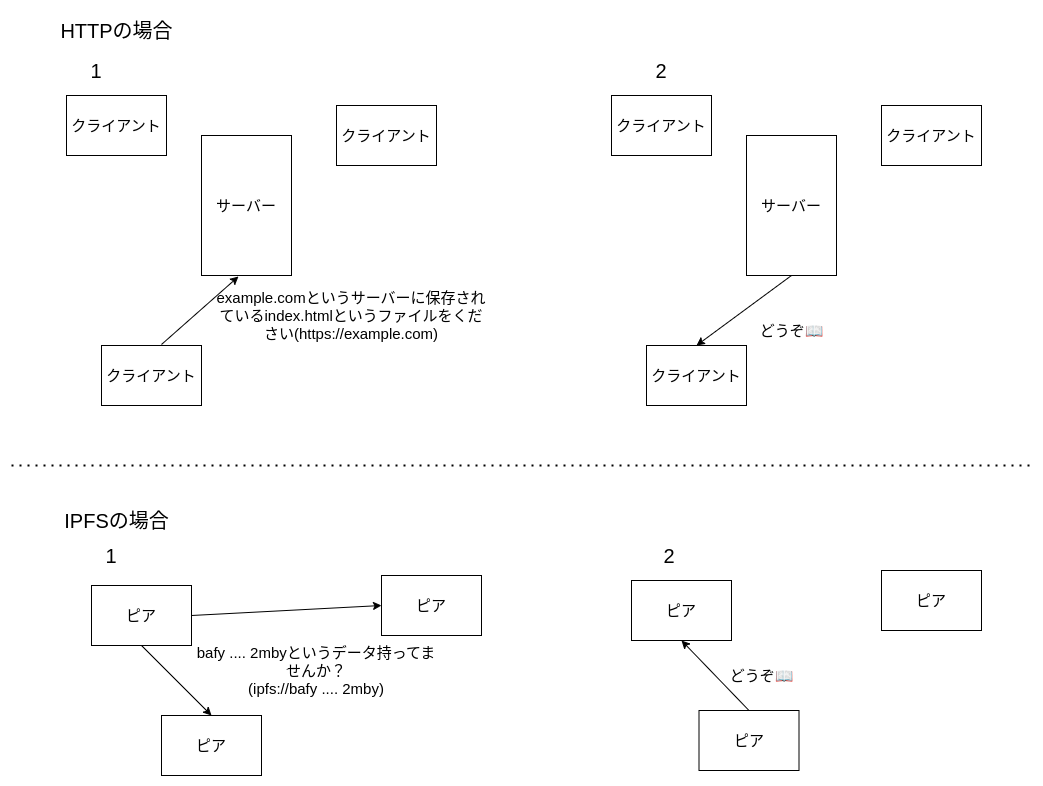
IPFSのメリット
検証可能性
IPFSは暗号学的ハッシュ関数を使います。そのためデータの検証が容易にできます。
データ完全性の検証をするにはハッシュ値を比較するだけです。
情報サイロの削除
情報サイロとは、情報が一部の組織内にとどまり、他の組織には公開されない状態のことです。
大量の情報を所持してことで有名なのが、やはりGAFAではないでしょうか。私達はこれらの第三者機関を信用して自分の持っているデータを預けています。しかし実際にこれらのデータが漏洩なく、不正に利用されていないという保証はありません。
IPFSはP2Pネットワーク上にあるデータならば誰でも取得でき、特定の組織のみに情報が集中しないようになっています。
パフォーマンスの改善
IPFSはピアの中で、目当てのコンテンツを持っている最も近い距離にあるものを探します。そのため、通信時間を削減することができます。さらにコンテンツが様々な場所に分散して保存されているので、コンテンツのダウンロードをピアごとに並列化して行うこともできます。
リンク切れの防止
コンテンツアドレス指定方式なので、特定のサーバーが稼働しなくなってもリンク切れを起こしません。
ベンダーロックインの削除
IPFSはオープンソースであるため、自由にカスタマイズして使用することができます。
また、特定の技術に依存しないように設計されています。例えばIPFSに保存されるデータは暗号化などはされていません。これにより、利用者はデータを暗号化するかどうか、暗号化方式はどうするかなどをIPFSに依存せずに決定できます。
IPFSの関連技術
IPFSは様々な技術の集合体とも言えます。以下にIPFSを構成するプロトコルやフレームワークを示します。
-
CIDs
コンテンツを一意に識別するための仕様です。 -
Bitswap
データを他のコンピュータから取得、送信するためのプロトコルです。 - Distributed Hash Tables(DHT)
一部のコンピュータに処理が集中しないようにしながらコンテンツを探すための技術です。様々なアルゴリズムがありIPFSはKademliaというものを使っています。 - DNSLink
コンテンツの指定にドメインネームを使うというものです。これにより、コンテンツの変更があっても同じ識別子でコンテンツにアクセスできます。 -
IPLD(InterPlanetaryLinkedData)
IPFSで保存されるデータのフォーマットが定義されています。 -
IPNI(InterPlanetary Network Indexer)
どのピアが目的のコンテンツを持っているかを高速に見つけるためのプロトコルです。 -
IPNS(InterPlanetary Name System)
DNSLinkのように任意の名前をつけることはできませんが、IPNS自身が署名を含んでいるなど、分散Webにとってよい特性を持ちます。 -
libp2p
P2Pで通信するためのネットワークのプロトコル、フレームワークの集まりです。libp2pの実装はTCP、やUDPなど様々なプロトコルを使用できます[2]。
IPFSの使用例
-
IPFS
IPFSの実装は様々な言語でされていますが公式が紹介しているのはGoでの実装のようです。デスクトップ版もあります。 -
Brave
デフォルトでIPFSをサポートしています。インストールしてipfs://bafybeicg2rebjoofv4kbyovkw7af3rpiitvnl6i7ckcywaq6xjcxnc2mby/と打ち込んでみてください。 -
Fleek
IPFS上にWebサイトを構築できます。Github連携でとても簡単にデプロイできます。 -
OrbitDB
IPFSを利用した分散データベースです。 -
Filecoin
分散型ストレージを利用するためのトークンです。マイナーはデータが正しく保存されている証明と引き換えにFilecoinを受け取れます。
参考文献
-
テキストやリンクを含むハイパーテキストに音声、映像などを追加して拡張したもの。 ↩︎
Discussion