Transformerの図解 - レイヤーごとの紹介
一、概要
第一部分では、すでにTransformerの全体的なアーキテクチャについて説明しました:

- データがエンコーダーとデコーダーに入力される前に、次の層を通過します:
- 単語埋め込み層
- 位置エンコーディング層
- エンコーダースタックは複数のエンコーダーから成り立っています。各エンコーダーは以下の要素で構成されています:
- マルチヘッドアテンション層
- フィードフォワード層
- デコーダースタックも複数のデコーダーから成り立っています。各デコーダーは以下の要素で構成されています:
- 2つのマルチヘッドアテンション層
- フィードフォワード層
- 最終的な出力は以下の層によって生成されます:
- 線形層
- Softmax層
各コンポーネントの役割をより深く理解するために、翻訳タスクにおいてTransformerをステップバイステップで訓練していきます。訓練データとして、1つのサンプルのみを使用します。このサンプルには、入力シーケンス(英語の "You are welcome")と目標シーケンス(スペイン語の "De nada")が含まれています。
二、単語埋め込み層と位置エンコーディング
Transformerの入力には、各単語の2つの情報に注目する必要があります:その単語の意味とシーケンス内での位置です。
-
最初の情報は、埋め込み層を通じて単語の意味をエンコードすることで得られます。
-
2つ目の情報は、位置エンコーディング層を通じてその単語の位置を表現することで得られます。
Transformerは2つの層を追加することで、2種類の異なる情報エンコーディングを完了します。
1. 埋め込み層(Embedding)
Transformerのエンコーダーとデコーダーにはそれぞれ埋め込み層(Embedding)があります。
エンコーダーでは、入力シーケンスがエンコーダーの埋め込み層に送られ、これを入力埋め込み(Input Embedding)と呼びます。

デコーダーでは、目標シーケンスを右に1つシフトし、最初の位置にStartトークンを挿入してからデコーダーの埋め込み層に送ります。なお、推論プロセスでは目標シーケンスがないため、最初の記事で述べたように、出力シーケンスを繰り返しデコーダーの埋め込み層に送ります。このプロセスは「出力埋め込み」(Output Embedding)と呼ばれます。
各テキストシーケンスは、入力埋め込み層に入る前に、語彙表内の単語IDの数値シーケンスにマッピングされています。埋め込み層はさらに各数値シーケンスを埋め込みベクトルに射影し、これがその単語の意味のより豊かな表現となります。

2. 位置エンコーディング(Position Encoding)
RNNは循環プロセスの中で、各単語を順番に入力するため、暗黙的に各単語の位置を知っています。
しかし、Transformerではシーケンス内のすべての単語が並列に入力されます。これはRNNアーキテクチャに対する主な利点ですが、同時に位置情報が失われることを意味し、別途追加する必要があります。
デコーダースタックとエンコーダースタックにはそれぞれ位置エンコーディング層があります。位置エンコーディングの計算は入力シーケンスとは独立しており、固定値で、シーケンスの最大長にのみ依存します。
-
最初の項は、最初の位置を表す定数コードです。
-
2番目の項は、2番目の位置を表す定数コードです。

posはそのシーケンス内での単語の位置、d_modelはエンコーディングベクトルの長さ(埋め込みベクトルと同じ)、iはこのベクトルのインデックス値です。式は行列のpos行目、2i列と(2i+1)列の要素を表しています。

言い換えれば、位置エンコーディングは一連の正弦曲線と余弦曲線を織り交ぜています。各位置posに対して、iが偶数の場合は正弦関数で計算し、iが奇数の場合は余弦関数で計算します。
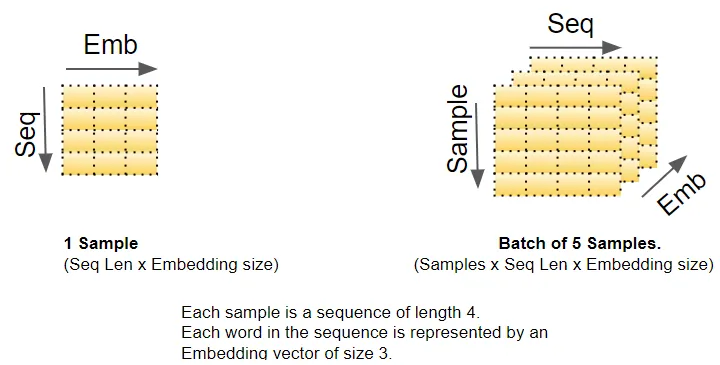
三、行列の次元(Matrix Dimensions)
ディープラーニングモデルは、一度に1バッチの訓練サンプルを処理します。埋め込み層と位置エンコーディング層は、このバッチ全体の行列に対して操作を行います。具体的には、埋め込み層は(samples, sequence_length)形状の2次元単語ID行列を入力として受け取ります。そして、各単語IDをembedding_sizeの大きさの単語ベクトルにエンコードし、(samples, sequence_length, embedding_size)形状の3次元出力行列を生成します。位置エンコーディングは埋め込みと同じサイズの次元を使用するため、同様の形状の行列が生成され、これを埋め込み行列に加算できます。

この(samples, sequence_length, embedding_size)形状は、モデル内で維持されます。データがエンコーダーとデコーダースタックを通過する間もこの形状が保持され、最終的な出力層で形状が変更されます[具体的には(samples, sequence_length, vocab_size)になります]。
以上が、Transformerにおける行列の次元に関する概観です。視覚化を簡略化するために、ここからは一時的に最初の次元(samples次元)を省略し、単一サンプルの2次元表現を使用して説明を進めます。
四、Encoder
エンコーダーとデコーダーのスタックは、それぞれ複数の(通常6つの)エンコーダーとデコーダーで構成され、これらが順番に接続されています。

-
スタックの最初のエンコーダーは、埋め込みと位置エンコーディングから直接入力を受け取ります。スタック内の他のエンコーダーは、前のエンコーダーから入力を受け取ります。
-
各エンコーダーは、前のエンコーダー(または最初のエンコーダーの場合は埋め込みと位置エンコーディング)からの入力を受け取り、それを自身のセルフアテンション層に渡します。このセルフアテンション層の出力は、次にフィードフォワード層に渡されます。そして、このフィードフォワード層の出力が次のエンコーダーへの入力となります。

-
セルフアテンション層とフィードフォワードネットワークの両方に残差接続(residual connection)が加えられ、その後層正規化(layer normalization)が適用されます。なお、デコーダーにおいても、前のデコーダーからの入力が現在のデコーダーに入る際に同様の残差接続が使用されます。
-
補足:李沐教授の著書『ゼロから作るDeep Learning』のP416ページには、「位置ベースのフィードフォワードネットワーク(position-wise feed-forward network)」について詳細な説明があります。具体的には、このフィードフォワードネットワークは線形層、活性化関数、そしてもう1つの線形層で構成されています。また、このネットワークは入力の形状を変更しないという特徴があります。

- エンコーダースタックの最後のエンコーダーの出力は、デコーダースタック内のすべてのデコーダーに送られ、各デコーダーの処理に利用されます。
五、Decoder
デコーダーの構造はエンコーダーの構造と非常に類似していますが、いくつかの重要な違いがあります。
-
エンコーダーと同様に、デコーダースタックの最初のデコーダーは埋め込み層(word embedding + position encoding)から入力を受け取ります。スタック内の他のデコーダーは前のデコーダーから入力を受け取ります。
-
デコーダー内部では、入力はまずセルフアテンション層(self-attention layer)に渡されます。この層の動作はエンコーダーのセルフアテンション層とは以下の点で異なります:
-
訓練過程(training process)では、デコーダーのセルフアテンション層は出力シーケンス全体を受け取ります。しかし、各出力生成時に将来のデータを参照することを防ぐため(つまり情報漏洩を避けるため)、「マスキング(masking)」技術を使用します。これにより、i番目の単語を生成する際に、モデルは1番目からi番目までの単語のみを参照できます。
-
推論過程(inference process)では、各時間ステップの入力は、現在の時間ステップまでに生成された出力シーケンス全体となります。
-
デコーダーとエンコーダーのもう一つの重要な違いは、デコーダーには2つ目のアテンション層、すなわち**エンコーダー-デコーダーアテンション層(Encoder-Decoder attention layer)**が存在することです。この層の動作はセルフアテンション層と類似していますが、その入力は2つの源から来ています:直前のセルフアテンション層の出力とエンコーダースタックの出力です。
-
エンコーダー-デコーダーアテンション層の出力はフィードフォワード層(feed-forward layer)に渡され、その後次のデコーダーに送られます。
-
デコーダー内の各サブレイヤー(セルフアテンション層、エンコーダー-デコーダーアテンション層、フィードフォワード層)には残差接続(residual connection)があり、その後層正規化(layer normalization)が適用されます。

六、アテンション(Attention)
第一部分では、アテンションメカニズムがなぜ非常に重要であるかを説明しました。Transformerモデルでは、アテンションは以下の3つの場所で使用されています:
-
Encoder内のSelf-attention:入力シーケンス(input sequence)の自身に対するアテンション計算;
-
Decoder内のSelf-attention:目標シーケンス(target sequence)の自身に対するアテンション計算;
-
Decoder内のEncoder-Decoder-attention:目標シーケンスの入力シーケンスに対するアテンション計算。
アテンション層(Attention layer)は、クエリ(Query)、キー(Key)、バリュー(Value)と呼ばれる3つのパラメータを用いて計算を行います:
-
Encoder内のSelf-attentionでは、エンコーダーの入力と対応するパラメータ行列(parameter matrices)を乗算して、Query、Key、Valueの3つのパラメータを得ます。
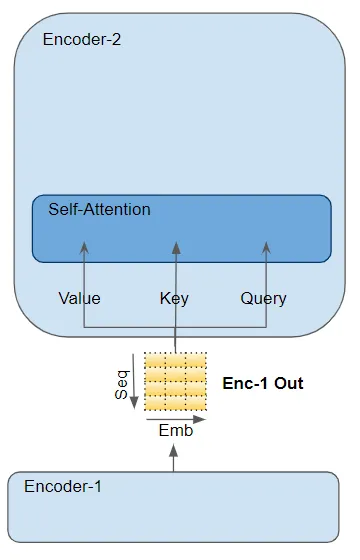
-
Decoder内のSelf-attentionでは、デコーダーの入力が同様の方法でQuery、Key、Valueを得ます。
-
デコーダーのEncoder-Decoder-attentionでは、エンコーダースタックの最後のエンコーダーの出力がValueとKeyパラメータに渡されます。Encoder-Decoder-attentionの直前にあるSelf-attentionとLayer Normalizationモジュールの出力がQueryパラメータに渡されます。

七、マルチヘッドアテンション(Multi-head Attention)
Transformerモデルでは、各アテンション計算ユニットをアテンションヘッド(Attention Head)と呼びます。複数のアテンションヘッドが並行して動作する仕組みを、マルチヘッドアテンション(Multi-head Attention)と呼びます。これは同一のアテンション計算を複数融合させることで、アテンション機構により強力な特徴識別能力を持たせる手法です。

各アテンションヘッドは、独立した線形層(linear layer)を通じて自身の重みパラメータ、すなわちQuery、Key、Valueを持ちます。これらのパラメータと入力との行列乘算(matrix multiplication)により、Q、K、Vを得ます。得られたQ、K、Vは以下に示すアテンション公式によって組み合わされ、アテンションスコア(Attention Score)を生成します。

ここで特に注意すべき重要な点は、Q、K、Vの値がシーケンス内の各単語(token)のエンコーディング表現であるということです。アテンション計算は各単語をシーケンス内の他のすべての単語と関連付けます。これにより、アテンションスコアはシーケンス内の各単語に対して、他の単語との関連性を数値化したスコアをエンコードすることになります。
八、アテンションマスク(Attention Masks)
Attention Scoreの計算と並行して、Attentionモジュールはマスク操作(masking operation)を適用します。このマスク操作には以下の2つの目的があります:
- Encoder Self-attentionとEncoder-Decoder-attentionにおいて:マスクの役割は、入力シーケンスのパディング(padding)位置に対応するAttention Scoreをゼロにすることです。これにより、パディングがSelf-attentionの計算に影響を与えないようにします。
-
パディング(padding)の役割:入力シーケンスの長さが可変であるため、多くのNLP手法と同様に、パディングを埋め込み記号として使用し、固定長のベクトルを生成します。これにより、各サンプルのシーケンスを行列としてTransformerモデルに入力することが可能になります。
-
Attention Scoreの計算時、Softmax関数を適用する前の分子にマスクが適用されます。マスクされた要素(白い四角で表示)は負の無限大に設定され、結果としてSoftmax関数によってこれらの値はゼロになります。

パディングマスク操作の図示:
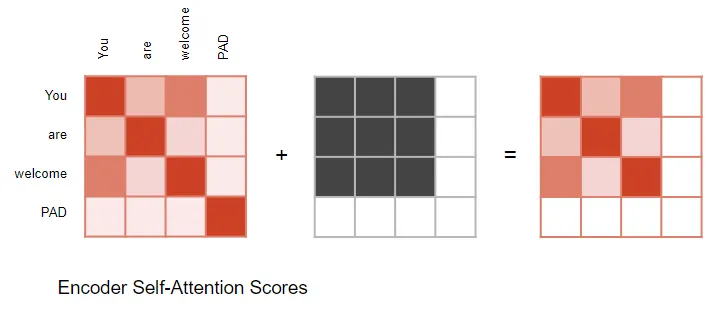
Encoder-Decoder-attentionのマスク操作も同様の方法で行われます:

- DecoderのSelf-attentionにおいて:マスクの役割は、現在の時間ステップでの予測時に、デコーダーが目標文の将来の時間ステップを"先読み"することを防ぐことです:
-
デコーダーはソースシーケンス(source sequence)の単語を処理し、それらを利用して目標シーケンスの単語を予測します。訓練中、このプロセスはTeacher Forcing手法を通じて実行されます。完全な目標シーケンスがデコーダーの入力として使用されるため、ある位置の単語を予測する際、デコーダーはその単語以前の目標単語だけでなく、その後の目標単語も利用可能になってしまいます。これにより、デコーダーは将来の"時間ステップ"の目標単語を使用して"不正"を行うことが可能になります。
-
例えば、下図に示すように、"Word3"を予測する際、デコーダーは目標単語の最初の3つの入力単語のみを参照すべきで、4番目の単語"Ketan"は含まれるべきではありません。したがって、DecoderのSelf-attentionマスク操作は、現在の時間ステップ以降のシーケンス中の目標単語を遮蔽します。


九、出力の生成(Generate Output)
デコーダースタック(Decoder stack)の最後のデコーダー(Decoder)は、その出力を出力コンポーネントに渡します。この出力コンポーネントが、受け取ったデータを最終的な目標文に変換します。
-
線形層(Linear layer)は、デコーダーベクトルを単語スコア(Word Scores)に投影します。目標言語の語彙に含まれる各固有単語に対して、文の各位置でスコア値が割り当てられます。例えば、最終出力文が7単語で、目標のスペイン語語彙に10,000の固有単語がある場合、この7つの各位置に対して10,000のスコア値を生成します。これらのスコア値は、語彙中の各単語がその文の特定の位置に出現する可能性を数値化したものです。
-
Softmax層は、これらのスコアを確率(合計が1.0になる)に変換します。各位置で、最も確率の高い単語のインデックスを選択し(貪欲探索、greedy search)、そのインデックスを語彙表の対応する単語にマッピングします。こうして選択された単語の列が、Transformerの最終的な出力シーケンスとなります。

十、訓練と損失関数(Training and Loss Function)
Transformerの訓練では、生成された出力確率分布と目標シーケンスを比較するために、クロスエントロピー(cross-entropy)を損失関数として使用します。ここで、確率分布は各単語がその位置に出現する確率を表しています。

例として、目標言語の語彙が4つの単語のみで構成されていると仮定します。我々の目標は、期待される目標シーケンス "De nada END" に一致する確率分布を生成することです。
具体的には、以下のような確率分布を目指します:
- 最初の単語位置では、"De" の確率が1で、他のすべての単語の確率が0
- 2番目の単語位置では、"nada" の確率が1で、他のすべての単語の確率が0
- 3番目の単語位置では、"END" の確率が1で、他のすべての単語の確率が0
訓練プロセスでは、通常のディープラーニングの手法に従い、この損失関数に対して勾配(gradient)が計算され、逆伝播(backpropagation)を通じてモデルのパラメータが更新されます。
Discussion