🫠
Pythonでモデルから出力した予測値と実測値を比較する方法
sklearn.treeのDecisionTreeRegressorのモデル例
モデル作成と予測結果出力
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)
model = DecisionTreeRegressor(random_state=1)
model.fit(train_X, train_y)
predictions = model.predict(val_X)
散布図を使った比較
import matplotlib.pyplot as plt
# 散布図をプロット
plt.scatter(predictions, val_y)
plt.xlabel('val_y')
plt.ylabel('predictions')
plt.title('val_y vs predictions')
plt.plot([min(val_y), max(val_y)], [min(val_y), max(val_y)], color='red') # 45度線
plt.show()

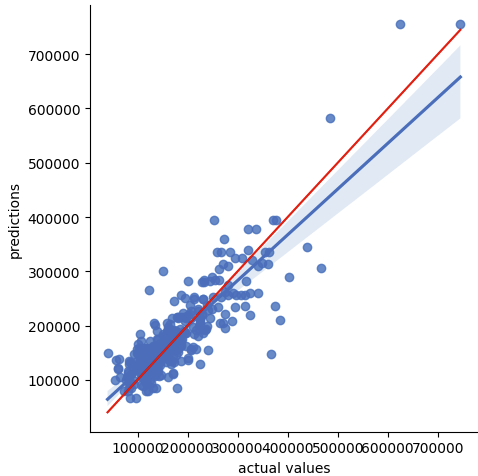
回帰直線を使った比較
import seaborn as sns
import matplotlib.pyplot as plt
# データフレームを作成
import pandas as pd
data = pd.DataFrame({'actual values':val_y , 'predictions': predictions})
# 回帰直線をプロット
sns.lmplot(x='actual values', y='predictions', data=data)
plt.plot([min(val_y), max(val_y)], [min(val_y), max(val_y)], color='red') # 45度線
plt.show()
評価指標を使った比較
from sklearn.metrics import mean_absolute_error, mean_squared_error
mae = mean_absolute_error(predictions, val_y)
mse = mean_squared_error(predictions, val_y)
rmse = mean_squared_error(predictions, val_y, squared=False)
print(f'MAE: {mae}')
print(f'MSE: {mse}')
print(f'RMSE: {rmse}')
MAE: 29652.931506849316
平均絶対誤差。予測値と実測値の絶対誤差の平均を示します。
MSE: 1745663966.7561643
均二乗誤差。予測値と実測値の誤差の二乗の平均を示します。
RMSE: 41781.1436745832
平均二乗誤差の平方根。MSEの平方根を取ったもので、元のデータの単位に戻すことができます。
Discussion