WEELでAIエンジニアをしているモモサキと申します。
Difyを使ったRAG(Retrieval-Augmented Generation)システムの開発にあたり、「親子チャンク構造」の構造化検証を実施しました。
本記事では、その検証を通じて得られた知見や実践的なポイントを共有します。
背景
今回は、高精度な回答生成に対する強い要望があったため、Difyが提供する柔軟なフォーマット変換機能や親子チャンク構造の設計・さらに高性能なLLMとの組み合わせによって、資料検索や回答生成の精度を構造的に検証し、早期にその有効性を評価することを目的としました。
Difyとは
Difyは、OpenAIやローカルLLMを活用した生成AIアプリケーションを、GUI操作で効率よく構築できるオープンソースのフレームワークです。
プロンプトのバージョン管理、ユーザー入力の可視化、データソース連携(RAG)、エージェント機能など、実運用を想定した機能が豊富に搭載されています。
公式情報です。
チャンク構造について
RAG(Retrieval-Augmented Generation)システムでは、AIが情報を参照するために、対象資料を小さな塊(チャンク)に分割します。
チャンク構造には、主に以下の2種類があります。
- 汎用チャンク構造
文書やテキストデータを、一定のルールに基づいて機械的に分割する基本的な手法です。
一般的には「文字数」や「段落数」などの基準をもとに、文書を均等な長さのチャンクに区切ります。
例):1チャンクあたり2,000文字、または3段落で分割
この方式はシンプルかつ自動化しやすい一方で、文脈や意味のつながりが途切れやすいという課題があります。
- 親子チャンク構造
親子チャンク構造は、資料の構造をもとに「親(pppp)」と「子(cccc)」の関係を定義し、より柔軟かつ意味的な分割を行う手法です。
子チャンクは、検索時にヒットするキーとなる情報を持ち、親チャンクにはその背景や前提知識などの文脈情報が含まれます。
これにより、子チャンクを起点として、関連する文脈(親チャンク)をセットでLLMに渡すことが可能になります。
今回の検証では、チャンクに親子関係を持たせた「親子チャンク構造」を採用しました。
これにより、局所的な情報(子チャンク)から広い文脈(親チャンク)を同時に参照することで、AIがより正確に意図を理解し、回答生成に活用できるようになります。
Dify構造化検証で得られた2つの知見
検証の前提
事前にクライアントから、「質問」「理想的な回答」「参照用資料」の3点セットが共有されていました。
検証の目的
本検証では、共有された情報をもとに、Difyが「理想的な回答」を生成するために必要なコンテキスト(=チャンク情報)を、資料内から正確に取得できるかどうかを確認することを目的としました。
① 情報取得精度は「LLM × 親子チャンク × クエリ変換」で大きく向上する
高性能なLLM・親子チャンク構造・クエリ変換を組み合わせることで、情報取得の精度が大幅に向上することを確認しました。
以下の構成を用いて、ユーザーからの入力質問に対し、理想的な回答を生成するために必要な情報を資料から高精度に取得できることを確認しました。
- LLM:Gemma3 27B
- チャンク構造:親チャンク(例:pppp)と、それに紐づく子チャンク(例:cccc)の関係性を明示的に定義
- クエリ変換:ユーザーの入力意図をLLMで解析し、検索に最適化された内部クエリへと動的に変換
この仕組みによって、LLMが必要な情報を的確に参照できるようになり、回答精度の向上を実感することができました。
実際に追加したブロックは下記になります。
ユーザーの意図抽出ブロックの目的
このブロックの目的は、ユーザーからの入力クエリ(質問や指示)を受け取り、そのクエリの意図をLLM(大規模言語モデル)の機能を使って正確に抽出する処理ブロックです。

クエリ変換ブロックの目的
クエリ変換ブロックは、ユーザーが入力した元の質問(クエリ)を、RAG(Retrieval-Augmented Generation)システムがより効率的かつ正確に情報を検索・取得できるよう、最適な形に変換する役割を持つ処理ブロックです。

パラメータ抽出ブロックの目的
パラメータ抽出ブロックは、ユーザーの入力クエリから、特定のタスク実行や情報検索に必要な「パラメータ(変数や条件)」を識別し、抽出する役割を担う処理ブロックです。
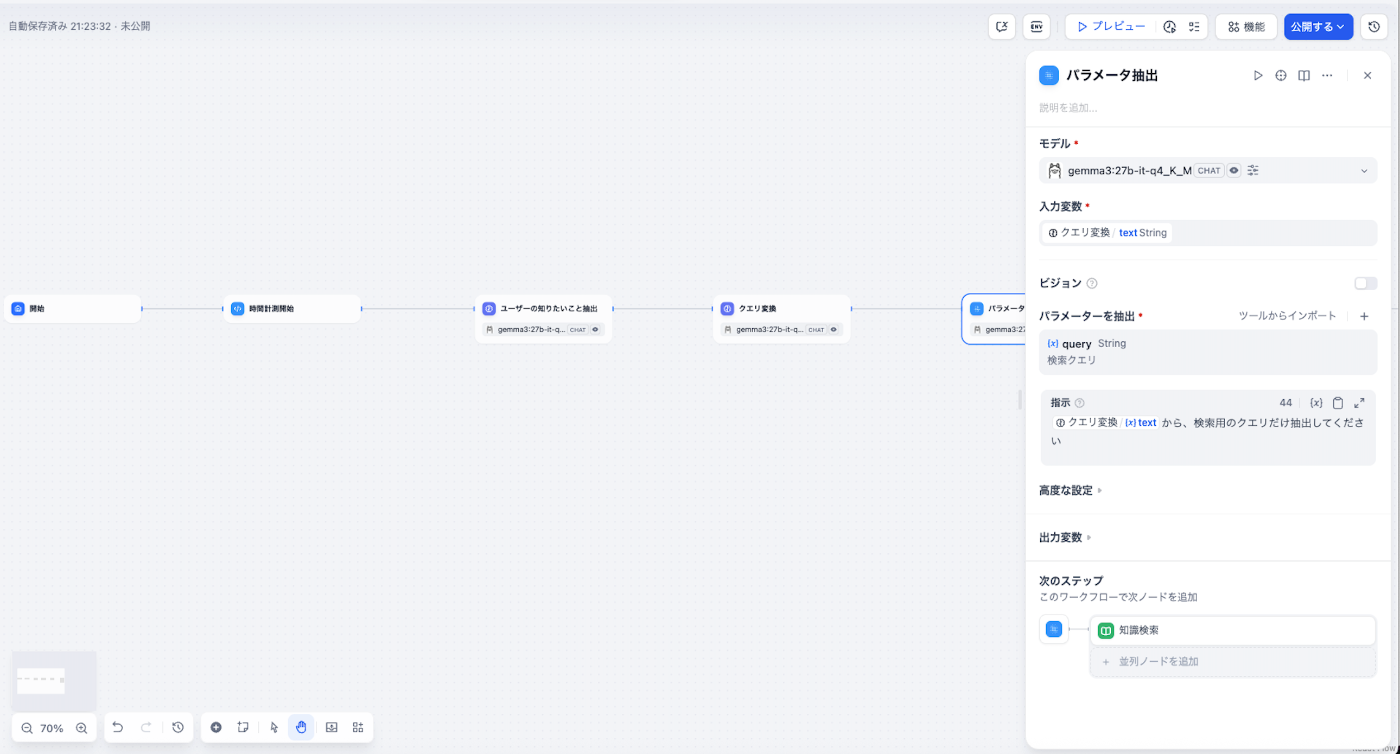
② Difyのチャンク構造における制限と対応策
Difyの親子チャンク構造には約4000文字の制限がある
検証を進める中で、親チャンクと子チャンクの合計が4,000文字を超えるナレッジを登録した場合、Difyでは親と子がそれぞれ独立したチャンクとして扱われることが判明しました。
その結果、本来保持されるべき親子関係が失われ、チャンク間の文脈共有ができなくなってしまいます。
チャンク構造が壊れる例(4,000文字超え)
以下のような親子チャンク構造を想定して、ナレッジ登録を行ったとします。
✅ 本来の構造(親子関係あり)
[pppp_001] ← 親チャンク
Difyとは、オープンソースのLLMアプリケーション開発基盤です。
ユーザーインターフェースを通じて、プロンプトの設計やデータソースとの連携、
AIエージェントのワークフロー構築などがGUIベースで簡単に行えます。
[cccc_001] ← 子チャンク1
例えば、DifyではPDFやWebページ、Notionなどの外部データをベースに、
RAG(Retrieval-Augmented Generation)形式のチャットボットを構築することができます。
[cccc_002] ← 子チャンク2
また、複数のプロンプトを組み合わせたワークフロー設計や、
ユーザーごとのチャット履歴の保持といった高度な機能も実装可能です。
(合計:約4,300文字)
この場合、親と子の合計が4,000文字を超えるため、Difyでは以下のように分離されたチャンクとして扱われます。
❌ 実際に登録された構造(分離)
[chunk_001]
Difyとは、オープンソースのLLMアプリケーション開発基盤です。
ユーザーインターフェースを通じて、プロンプトの設計やデータソースとの連携、
AIエージェントのワークフロー構築などがGUIベースで簡単に行えます。
[chunk_002]
例えば、DifyではPDFやWebページ、Notionなどの外部データをベースに、
RAG(Retrieval-Augmented Generation)形式のチャットボットを構築することができます。
[chunk_003]
また、複数のプロンプトを組み合わせたワークフロー設計や、
ユーザーごとのチャット履歴の保持といった高度な機能も実装可能です。
このような構造になると、回答生成時に文脈の連続性が断たれ、正確な回答が生成されにくくなるリスクがあります。
✅ 解決策:事前に4,000文字以内でチャンクを設計する
この問題を回避するためには、親チャンクをあらかじめ4,000文字以内に分割し、複数の親チャンクとして構成する工夫が必要です。
望ましい構造(例)
[pppp_001] ← 親チャンク(800文字程度)
Difyとは、オープンソースのLLMアプリケーション開発基盤です。
ユーザーインターフェースを通じて、プロンプトの設計やデータソースとの連携、
AIエージェントのワークフロー構築などがGUIベースで簡単に行えます。
[cccc_001] ← 子チャンク(約3,000文字)
DifyではPDFやWebページ、Notionなどの外部データをもとに、
RAG形式のチャットボットを構築できます。
また、複数プロンプトを組み合わせたワークフロー設計やチャット履歴保持など、
実践的なLLMアプリ構築に役立つ機能も豊富に備えています。
このように構成することで、チャンク単位での文脈保持が可能となり、情報取得の精度と回答生成の品質が向上します。
🛠️ 検証時に直面した課題と対応策
本検証の過程では、以下のような課題が発生しました。
それぞれに対して、原因を分析し、実行可能な解決策を講じています。
パラメータ抽出時の「Query is required」エラーへの対応
Difyの「パラメータ抽出」ブロックにおいて、以下のようなエラーが発生するケースがありました。

このエラーは、LLMの出力がDifyで期待されるJSON形式に従っていない場合に発生します。
原因調査を進める中で、"query" キーそのものが出力から欠損していることがわかりました。
✅ 対応策
クエリ変換のLLLMに渡すシステムプロンプトを調整し、LLMの出力が必ず "query" キーを含むJSON構造になるよう指示を明示化することで、解決しました。
以下は例になります。
{
"query": "..."
}
まとめ
本記事では、RAGシステムの構築に先立って実施した、Difyを用いた構造化検証の取り組みについて紹介しました。

Discussion