はじめに
WED株式会社で機械学習エンジニアをしています、ishi2kiです。
当社では以前、Slack のOutgoing Webhook をトリガーにして特定のタスクを実行する Cloud Run services を作成したことがあります。
Slack から簡単に実行できるので、非エンジニアでも自動化の恩恵を受けられ、単純作業の工数を削減することができました。
しかし、これには以下のような課題がありました。
- Outgoing Webhook ではなく Slack API を使うことが推奨されている
- タスクの実行に1時間以上かかる場合、Cloud Run services がタイムアウトしてしまう
- タスクの実行結果を Slack のスレッドに返信することができない
これらの課題を解決するために仕組みを一新したので、その内容を紹介します。
アーキテクチャ概要
今回構築した仕組みでは、以下のようなフローで処理が行われます。
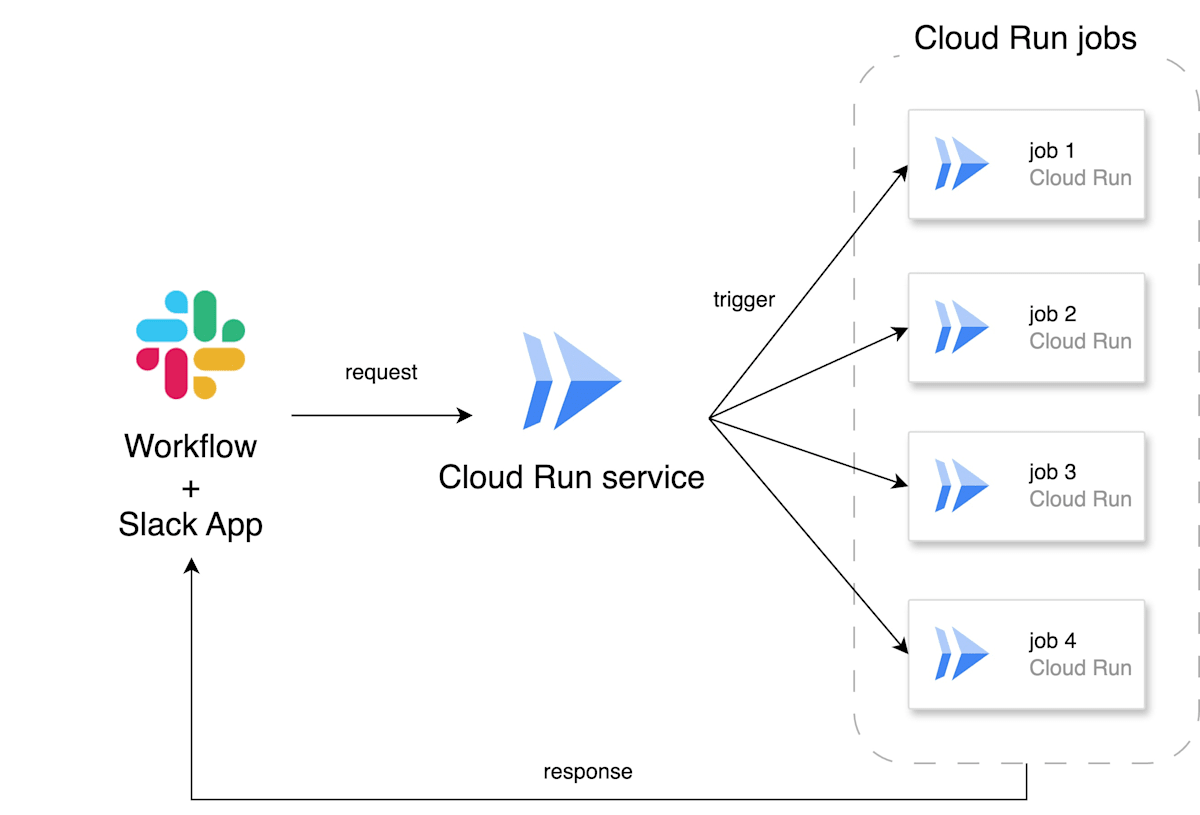
- 実行したい job に対応する Slack のワークフローを開始し、タスクの実行に必要なパラメータを含んだメッセージを生成する
- 1 のメッセージをトリガーに、Slack App が Cloud Run services にリクエストを送る
- Cloud Run services が、メッセージの内容を parse し、対象の Cloud Run jobs にパラメータを渡して実行する
- Cloud Run jobs から Slack のスレッドに結果を返す
実装
レシート画像の重複検知の job を例に、各箇所の実装について紹介します。
重複検知の実装は、こちらの記事で紹介しています。興味のある方は是非ご覧ください。
検品作業を96%カット!Geminiでレシートの重複判定をしてみた
1. Slack Workflow の設定
各 Cloud Run jobs に対応するワークフローを個別に作成します。これにより、ジョブごとに異なるパラメータや設定を簡単に管理できます。
ワークフローで使用者にタスクの実行に必要なパラメータを入力させ、Slack App を trigger するメッセージを生成します。
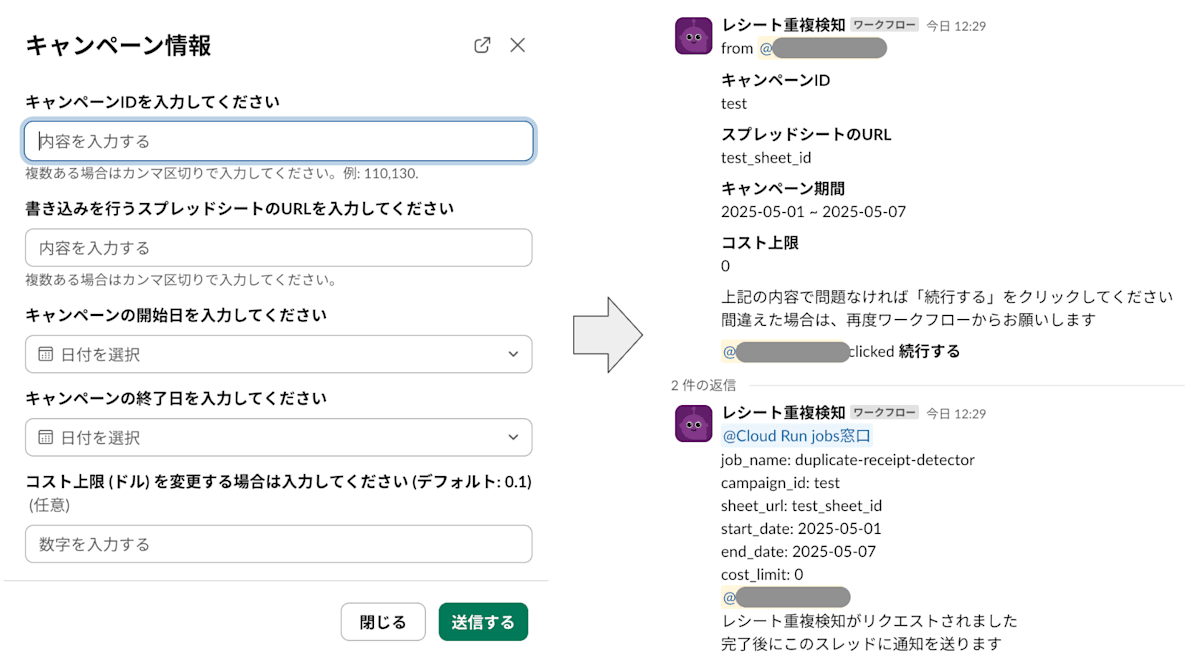
メッセージには、ワークフローで入力した内容の他に、タスクごとに一意に設定したjob_nameを含めるようにしています。
後続の Cloud Run services では、このjob_nameをもとに、実行する Cloud Run job を特定します。
2. Slack App の実装
Slack App は、自身宛てのメンションを受け取ると、Cloud Run services にリクエストを送るように設定しています。
このあたりは、Event Subscriptions の設定で行えます。

3. Cloud Run services の実装
Cloud Run services は以下の役割を担当します:
- メッセージを parse し、パラメータを取得する
- 適切な Cloud Run jobs を起動する
Slack App は、リクエスト先からの応答が 3 秒以内に届かない場合、リクエストを再送するようになっています。
確実に 3 秒以内に応答することは難しいと判断し、再送リクエストは無視するようにしました。
また、Slack App からのリクエストには、ワークフローが開始されたチャンネルの ID (channel_id) と、スレッドの ID (thread_ts) が含まれています。
この値も Cloud Run jobs に渡し、job がスレッドに返信できるようにしました。
from duplicate_receipt_detector.trigger import trigger_run as duplicate_receipt_detector_run
from fastapi import FastAPI, Request
from slack import SlackClient
app = FastAPI()
@app.post("/trigger")
async def trigger_job(request: Request):
# 再送リクエストを無視する
headers = request.headers
if "x-slack-retry-num" in headers.keys():
print("Ignore retry request")
return
body = await request.json()
slack_client = SlackClient(body)
# job_nameによって処理を分岐
if slack_client.job_name == "duplicate-receipt-detector":
return duplicate_receipt_detector_run(slack_client)
elif slack_client.job_name == "other_job_name":
return other_job_run(slack_client)
else:
raise ValueError(f"Unknown job_name: {slack_client.job_name}")
# Slack App からのリクエストを処理するためのクラス
import re
SLACK_API_URL = "https://slack.com/api/chat.postMessage"
class SlackClient:
def __init__(self, request_body: dict):
self.request_body = request_body
self.text = request_body["event"].get("text")
self.channel = request_body["event"]["channel"]
self.thread_ts = request_body["event"]["thread_ts"]
self.set_params()
def set_params(self):
"""
リクエストボディからパラメータを取得し、attrとして保存
メッセージの param_name: value の形式を想定
"""
pattern = r"(\S*)\s*:\s*([^\n\r]*)[\n\r]?"
text = self.request_body["event"]["text"]
for line in text.split("\n"):
match = re.search(pattern, line)
if match is not None and len(match.groups()) == 2:
setattr(self, match.group(1), match.group(2))
# Cloud Run jobs を起動するための関数
import os
from google.cloud import run_v2
from slack import SlackClient
def trigger_run(slack_client: SlackClient):
client = run_v2.JobsClient()
request = run_v2.RunJobRequest(
name="job-name",
overrides=run_v2.types.RunJobRequest.Overrides(
container_overrides=[
run_v2.types.RunJobRequest.Overrides.ContainerOverride(
env=[
run_v2.types.EnvVar(
name="SLACK_BOT_TOKEN", value=os.getenv("SLACK_BOT_TOKEN")
),
run_v2.types.EnvVar(
name="CHANNEL_ID", value=slack_client.channel
),
run_v2.types.EnvVar(
name="THREAD_TS", value=slack_client.thread_ts
),
run_v2.types.EnvVar(
name="CAMPAIGN_ID", value=slack_client.campaign_id
),
run_v2.types.EnvVar(
name="START_DATE", value=slack_client.start_date
),
run_v2.types.EnvVar(
name="END_DATE", value=slack_client.end_date
),
run_v2.types.EnvVar(
name="SHEET_URL", value=slack_client.sheet_url
),
run_v2.types.EnvVar(
name="COST_LIMIT", value=slack_client.cost_limit
),
],
)
]
),
)
client.run_job(request=request)
return
4. Cloud Run jobs の実装
Cloud Run services で、ワークフローに入力されたパラメータは、環境変数として設定されます。
そのため、Cloud Run jobs では、os.getenv を使ってパラメータを取得することができます。
さらに、channel_id と thread_ts をもとに、Slack API を使ってスレッドに結果を返信することができます。
import os
def duplicate_detect():
slack_bot_token = os.getenv("SLACK_BOT_TOKEN")
channel_id = os.getenv("CHANNEL_ID")
thread_ts = os.getenv("THREAD_TS")
campaign_id = os.getenv("CAMPAIGN_ID")
start_date = os.getenv("START_DATE")
end_date = os.getenv("END_DATE")
sheet_url = os.getenv("SHEET_URL")
cost_limit = os.getenv("COST_LIMIT")
your_process()
if __name__ == "__main__":
duplicate_detect()
まとめ
Slack から Cloud Run jobs を実行する仕組みを構築することで、以下のメリットが得られます。
- ワークフローに沿って入力するだけで非エンジニアでも簡単にジョブを実行できる
- 同一のスレッドに結果やエラー通知を送ることができ、処理の進行状況を確認しやすい
- Cloud Run jobs に処理を任せることで、最長 24 時間の処理を実行できる (Cloud Run services は 1 時間でタイムアウト)
- Slack からの窓口とタスクを分けることで、タスクの追加に伴うコーディング量が減り、Slack 側もワークフローの追加のみで済む
特に、Slack から実行したいタスクが複数ある場合や、タスクの実行に時間がかかる場合には、この仕組みが有効です。
本記事が参考になれば幸いです。

Discussion