はじめに
WED株式会社でデータエンジニアをしているryuya-matsunawaです。
こちらの記事で紹介されたBigQueryコスト削減の取り組みの別アプローチとして、BigQueryのコストを50%削減した話をします。
やったこと
- BigQueryのINFORMATION_SCHEMAを使って、クエリの実行時間やスキャンバイト数を取得
- 実行元ごとにクエリのコストが高くなる原因を調査および改善
- 改善後のコストをMetabaseで可視化
1. BigQueryのINFORMATION_SCHEMAを使って、クエリの実行時間やスキャンバイト数を取得
BigQueryのINFORMATION_SCHEMAを使って、クエリの実行時間やスキャンバイト数を取得することができます。
なお、INFORMATION_SCHEMAで確認できるクエリ履歴は最大で約6か月(180日)までしか保持されないため、長期的な分析ができるよう、BigQuery内に別テーブルを作成して履歴を保存する仕組みを整えました。
こちらの記事を参考に、クエリの実行時間やスキャンバイト数を取得するSQLを作成しました。
SELECT
job_id,
parent_job_id,
user_email,
statement_type as query_type,
query,
total_bytes_billed,
ROUND(total_bytes_billed / POW(1024, 4) * 6.25, 4) as charges_doller,
total_slot_ms,
SAFE_DIVIDE(total_slot_ms, timestamp_diff(end_time, creation_time, millisecond)) as avg_usage_slots,
datetime(creation_time, 'Asia/Tokyo') as execute_date,
timestamp_diff(end_time, creation_time, millisecond) as execute_time
FROM
`region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
job_type = 'QUERY'
and date(creation_time, 'Asia/Tokyo') >= current_date() - 1
ORDER BY
creation_time desc
このクエリは日次で実行し、結果をBigQuery内の別テーブルに蓄積しています。
2. 実行元ごとにクエリのコストが高くなる原因の調査および改善
次に、実行元ごとにコスト増加の原因を調査しました。
まず、user_emailだけでは細かすぎるため、より大きな単位でグループ化するカラムを追加しています。
- BigQuery
- Metabase
- Airflow
- スプレッドシート
- その他
例えば、スプレッドシートでは、他チームが作成したものにBigQueryが連携されており、日次で自動実行されるクエリが、不要になった後も実行され続けていました。
これらは実行元を特定して停止し、コスト削減につなげました。
また、古いクエリの中にはパーティションを指定していないものや、クエリ最適化が不十分なものも見つかりました。こちらも実行元を特定し、クエリの見直し・最適化を行うことでコストを抑えることができました。
3. 改善後のコストをMetabaseで可視化
改善後のコストは、Metabaseを使って可視化しました。
クエリの実行時間とスキャンバイト数を指標に、ダッシュボード上で状況を確認できるようにしています。
Metabaseのダッシュボードは以下のようなものです。
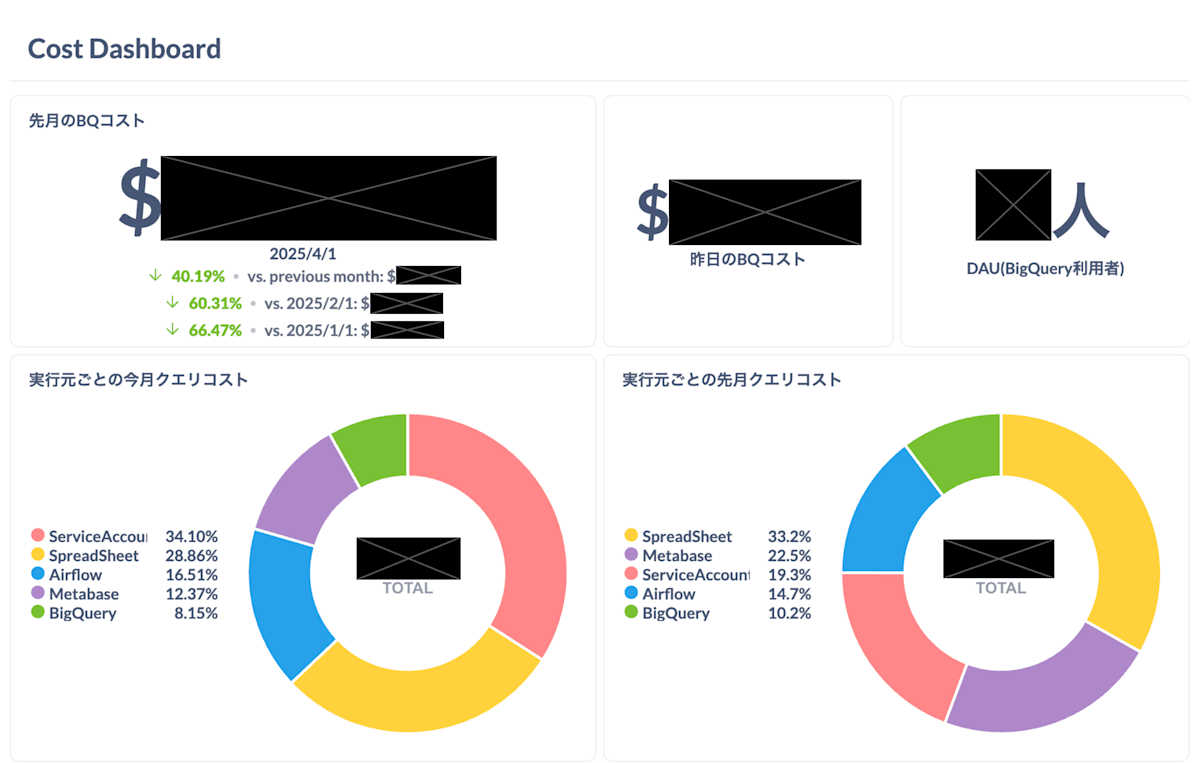
2月からコスト削減の取り組みを始め、徐々にコストが削減されていることがわかります。
まとめ
クエリ履歴の可視化からスタートし、実行元ごとの原因分析と改善を行った結果、BigQueryのコストを約50%削減することができました。
以前からクエリ履歴の記録はしていたものの、ようやく本格的に改善へ動き出すことができました。
特に、Spread Sheetからの不要なクエリの削減や、クエリの最適化は大きな効果がありました。
まだ手を付けられていないクエリもあるため、今後も継続的にコスト最適化に取り組んでいきます。

Discussion