はじめに
WED株式会社でONEの開発をしているサーバーサイドエンジニアのnagashimaです。
弊社では、ONEでレシートデータを収集しており、データ分析データベースとしてBigQuery、マイクロサービスのデータベースとしてCloud Spannerを使用しています。
先日、リアルタイムなデータをCloud Spannerから取得して結果をCSV形式でエクスポートしたいという場面がありました。
Cloud Spannerではコンソール上からクエリ結果をCSV形式で出力する機能がありません。BigQueryだとそれができるのですが、普通にBigQueryに同期されているデータを使うと最新データの同期まで一定時間の遅延があるためリアルタイムなデータが取れません。
そこで連携クエリを使ってBigQueryからCloud Spannerに対してクエリを送り、リアルタイムなデータを取ることにしました。
その際に出たエラーと解決策についてまとめていきたいと思います。
Cloud Spanner
Google Cloudのフルマネージドな分散型データベースです。
水平オートスケーリングを実現しながら、データの強整合性も保ちます。「分散型」ということで、データはスプリットという単位でグローバルに分散されて保持されていますが、ユーザーはそれを気にする事なく1つのデータベースとして扱うことができます。
連携クエリ(Federated Query)
連携クエリとは異なるデータベースサービス間でデータのやり取りをするためのクエリです。
以下の関数を使用することで連携クエリを実行することができます。
EXTERNAL_QUERY('connection_id', '''external_database_query'''[, 'options'])
Cloud Spanner内でクエリされた結果が一時テーブルという形でBigQueryに返されます。
実際に使ってみる
私が実行しようとしたクエリは以下のようなものです。
SELECT price, name
FROM EXTERNAL_QUERY(
'projects/project-name/locations/asia-northeast1/connections/spanner_connection',
'''
SELECT b.price, a.name
FROM books b
JOIN authors a
ON b.author_id = a.id
'''
)
見ての通りただテーブル結合しただけのクエリです。(実際にはもっとたくさんのテーブルをJOINして条件も書いていた)
しかし、これを実行しようとすると以下のようなエラーが出てしまいます。
Error while reading data, error message: Error accessing Cloud Spanner. Query is not root partitionable since it does not have a DistributedUnion at the root. Please check the conditions for a query to be root-partitionable.
root-partitionableなクエリとはどのようなものなのでしょうか、、、
エラー原因
EXTERNAL_QUERYで指定しているクエリはroot-partitionableである必要があります。以下のいずれかの条件を満たすものがroot-partitionableと言えます。
- 実行プランの最初の演算子が分散ユニオン演算子で、分散ユニオン以外の分散演算子が含まれない
- 実行プランに分散演算子を含まない
私が書いたクエリはこのいずれも満たしていないためエラーとなるようです。
2024/10/02更新
コメントにもありますが、root-partitionableについての詳細はぜひ以下の記事を読んでみてください!
分散ユニオン
分散ユニオン(Distributed Union)はクエリ演算子の一種です。
クエリ演算子とはデータに対する特定の処理を表したもので、例えば並び替え演算子は入力として行を受け取り、列で並び替えたものを出力として返す処理を表します。実行計画における各ステップがクエリ演算子となります。
(↓実行計画とそれを構成するクエリ演算子)
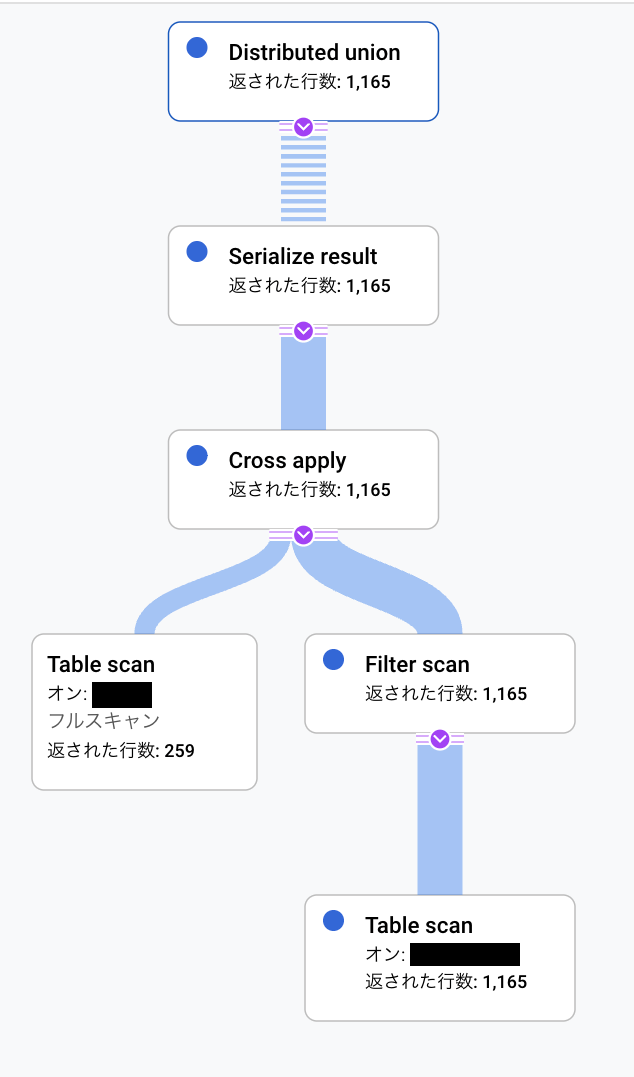
分散ユニオンは、サブプラン[1]をリモートサーバーに分散させてその結果を受け取り、結合したものを出力として返します。
(出典: https://cloud.google.com/spanner/docs/query-execution-plans?hl=ja#life-of-query)
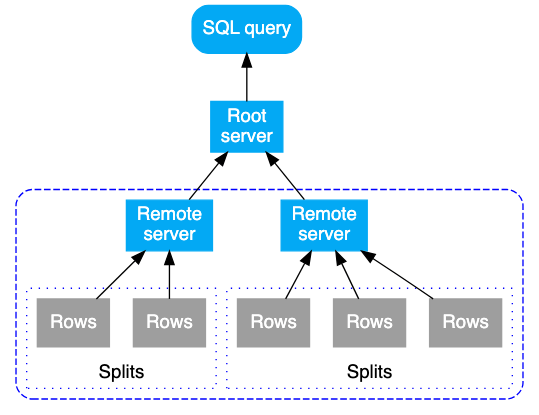
先ほども言及しましたが、Spannerはデータをスプリットという形で異なるサーバーに分散してデータを保持しています。
この分散したデータを個々のサーバーから取得する起点となるのが分散ユニオンです。(文字通り、分散したものをユニオンする)
この分散ユニオンを走らせるには、個々の分散サーバーで処理が完結するようなSQLを書くと良いです。
具体的にはSELECT文 + WHEREによる絞り込みだけのようなシンプルなSQLです。
SELECT s.SongName, s.SongGenre
FROM Songs AS s
WHERE s.SingerId = 2 AND s.SongGenre = 'ROCK';
(出典: https://cloud.google.com/spanner/docs/query-execution-operators?hl=ja#distributed-union)
解決策
では先ほどのエラーはどう解決策するかというと、WITH句を使って分散ユニオンが走るようなSQLを発行します。
WITH b AS (
SELECT author_id
FROM EXTERNAL_QUERY(
'projects/project-name/locations/asia-northeast1/connections/spanner_connection',
'''
SELECT author_id
FROM books
''')
),
a AS (
SELECT id
FROM EXTERNAL_QUERY(
'projects/project-name/locations/asia-northeast1/connections/spanner_connection',
'''
SELECT id
FROM authors
''')
)
SELECT *
FROM b
JOIN a
ON b.author_id = a.id
見ての通りWITH句内のクエリはシンプルなSELECT文となっています。
こうすることで、Spannerに対して分散ユニオンで処理が実行されるようにします。
このクエリ結果がEXTERNAL_QUERYによって一時テーブルとしてBigQueryに返されるので、テーブル結合はその一時テーブルを使ってBigQuery側で行います。
補足・余談
SELECT b.price, a.name
FROM books b
JOIN authors a
ON b.author_id = a.id
これをCloud SpannerのSpanner Studioで実行してみて実行計画を見てみると、先頭がDistributed Unionになっていました。しかし、連携クエリとしてEXTERNAL_QUERYに記載するとエラーになってしまいます。
2024/10/02更新
上記のSQLの実行計画の一部抜粋が以下です。
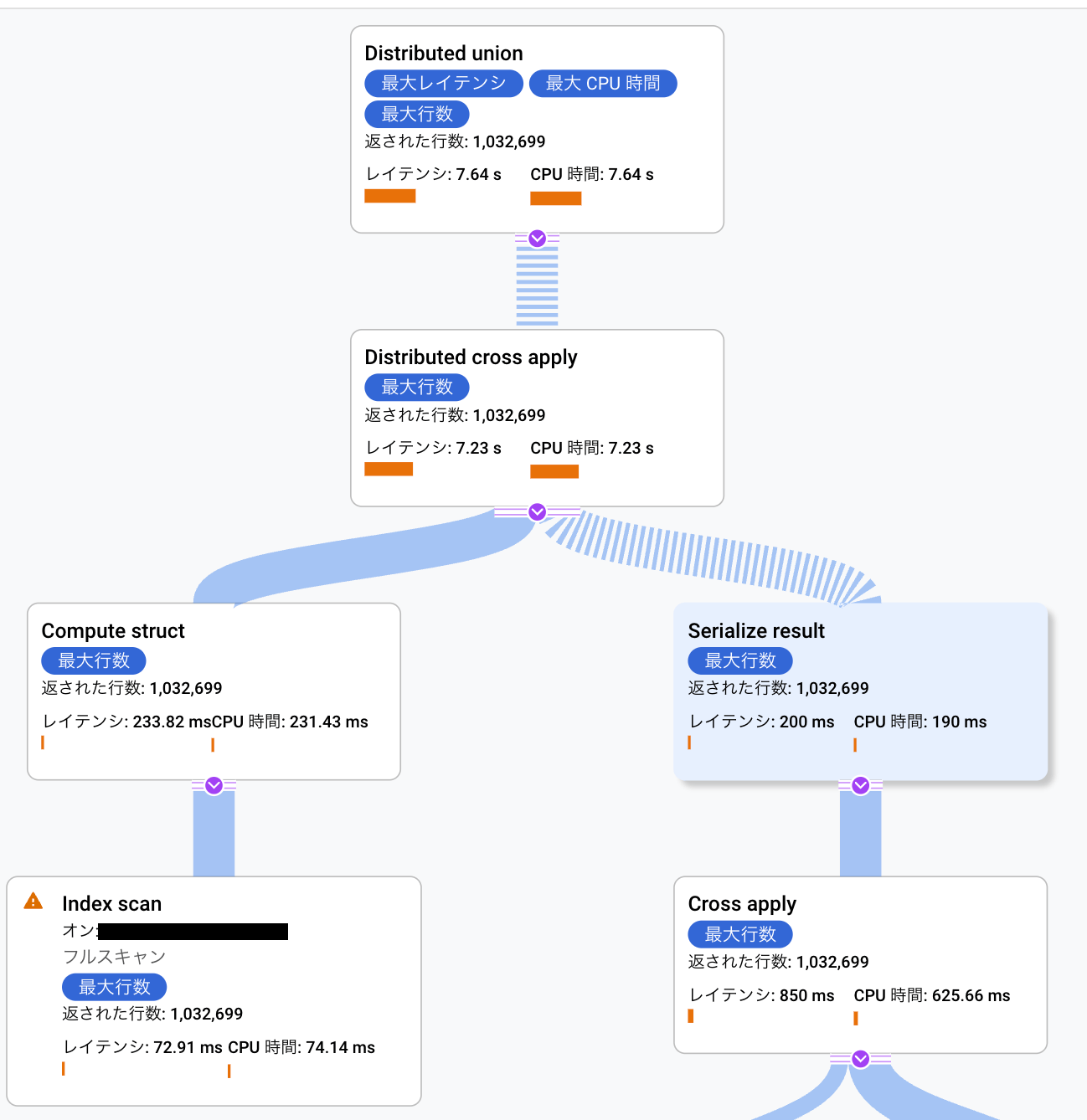
見ての通り、Distributed Unionの下でDistributed Cross Applyが適用されています。
最初の演算子がDistributed Unionだったとしても、他に分散オペレータが含まれる実行計画はroot-partitionableではありません。
そのため上記のクエリを連携クエリとして使おうとするとエラーになってしまいます。
さいごに
Cloud SpannerやBigQueryについて知らない側面がまだまだ多いので、今後とも知識を深めていけたらなと思ってます。
最後まで読んでいただきありがとうございます。記事に対してフィードバック等いただけるととても嬉しいです!!!

Discussion
気付いたのですが、 root-partitionable に関する BigQuery 側のドキュメントが間違っていますね。
Cloud Spanner 側のドキュメントには次のように異なる記述があります。
テーブルスキーマと実行計画が書かれていないので推測ですが、
が root-partitionable ではない扱いされるのは最上位が Distributed Union であってもその下に
booksテーブルとauthorsテーブルを分散 JOIN するための Distributed Cross Apply が含まれるからではないでしょうか。知っていることを書いてみました。
フィードバックいただきありがとうございます!!記事を一部加筆・修正しました!