エンジニア向け動画面接AIを作ってみた!Mastraで実現する動画面談と自動評価システム
はじめに 👋
こんにちは、株式会社LogickyのCEOのえどいち(@edo1z)です!😊
最近、動画面接AIが流行っている気がしますし、仕組み的にも興味深かったので、自分でも作ってみました!
具体的にどんなことができるかというと:
- 🎥 WebRTCでブラウザからカメラとマイクを使った面接ができる
- 🧠 面接官AIが募集条件に基づいて質問を自動生成してくれる
- 🎤 Whisperを使って話した内容を自動的にテキスト化
- 📊 技術力・主体性・責任感・カルチャーフィットを数値評価+コメント
エンジニア採用の一次面接だけでなく、面接練習ツールとしても使えるんじゃないかな?と思っています。
使った技術の紹介
今回のシステムは以下の技術を組み合わせて作りました:
- フロントエンド: SvelteKit + WebRTC + Tailwind CSS
- バックエンド: Node.js + Mastra
- 音声認識: OpenAI Whisper API
- LLM: OpenAI GPT-4
それではさっそく、作ったものを見ていきましょう!
完成したものを見てみよう 📱
実際に動く様子を見てもらった方が早いと思うので、まずは動画をどうぞ!
システムの各画面紹介
面談設定画面 ⚙️

ここでは、AIに面接の設定を教えます。例えば:
- 「バックエンドエンジニア募集中で、Node.jsとMastraの経験がある人を探してます」
- 「Webフロントエンドの経験3年以上、ReactとTypeScriptが使える人」
みたいな感じで、募集内容や技術スタック、求める役割などを入力します。
⭐ ポイント: 詳しく書けば書くほど、AIがそれに沿った質問を生成してくれるので、自分が知りたいことを具体的に書くと良いです!
面談実行画面 🎬
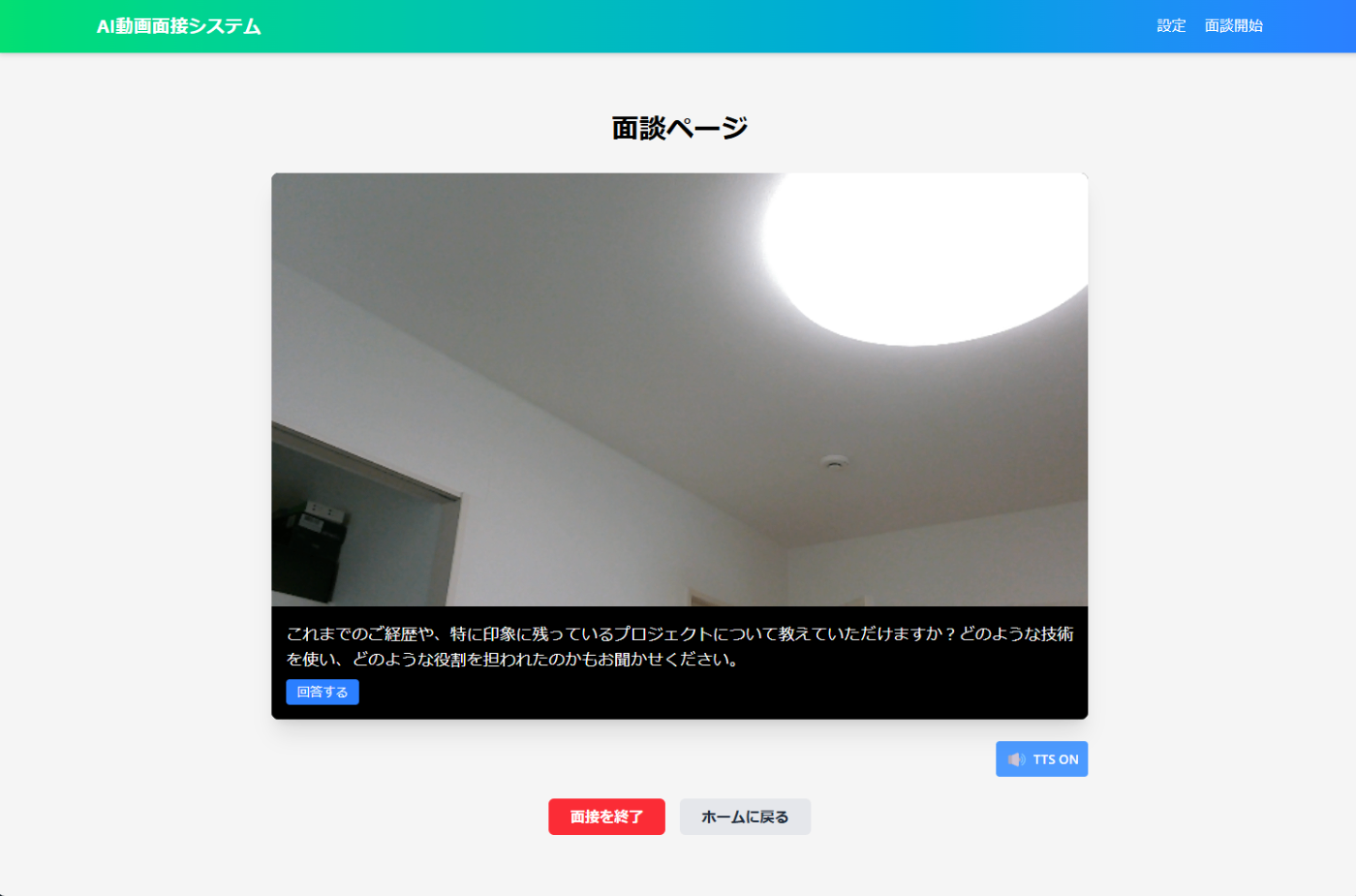
ここが一番のメイン画面!WebRTCを使ってカメラとマイクにアクセスし、AIとの面接が始まります。
画面の特徴:
- 自分の姿がカメラに映る
- AIからの質問が音声再生とテキスト表示される
- 「回答終了」ボタンを押すと次の質問に進む
- 5秒間無言だとボタンが光って「もう終わり?」と教えてくれる
- 15秒無言だと自動的に次に進む(便利!)
評価結果画面 📊

面接が終わると、AIがあなたの回答を分析して評価してくれます:
- 技術力: 80点 - 「Mastraの知識が豊富で実装経験も十分...」
- 主体性: 75点 - 「自ら課題を見つけて解決した経験が...」
- 責任感: 90点 - 「トラブル時の対応が適切で...」
- カルチャーフィット: 85点 - 「チームでの協業スタイルが...」
また、面接の質問・回答履歴と、面接中の15秒おきに撮影された写真も表示されるので、細かい回答内容や、自分の表情や姿勢も振り返れます。
AIの質問例
実際にAIがどんな質問をするか気になりますよね?例えばこんな感じです:
- 「Mastraを使ったプロジェクトの経験について教えてください」
- 「チームで意見が分かれた時、あなたはどのように調整しますか?」
- 「技術的な難問に直面した時の解決プロセスを教えてください」
面白いのは、あなたの回答を聞いてから次の質問を考えてくれることです。つまり、「ただ決まった質問を順番に聞いてくるだけ」じゃなくて、ちゃんと会話の流れに沿った質問をしてくれます。
まるで本物の面接官と話しているような...とまでは言いませんが、かなりリアルな体験ができますよ!
それでは次に、このシステムがどう設計されているのか、作り方のポイントを見ていきましょう!
作り方のポイント① - 全体設計 🏗️
さて、どうやってこのシステムを作ったのか、興味ある方もいると思うので、ちょっと技術的な話をしていきます。まずは全体設計から見ていきましょう!
システム構成図
全体の構成はこんな感じです↓
[フロントエンド - SvelteKit]
↑↓ WebSocket通信
[バックエンド - Node.js + Mastra]
↑↓ API通信
[OpenAI API (GPT-4 + Whisper)]
シンプルですね!基本的には、フロントエンドでUIを表示して、カメラ・マイクを操作。バックエンドではAIの処理を担当、という役割分担です。
フロントエンドとバックエンドの役割
フロントエンド側の主な仕事 🖥️
- ユーザーインターフェース(UI)の表示
- WebRTCを使ったカメラ・マイク操作
- VAD(Voice Activity Detection)で無音検出
- 15秒ごとに静止画をキャプチャ
- WebSocketを使ってバックエンドと通信
バックエンド側の主な仕事 🧮
- 面接シナリオの自動生成(LLM)
- 音声のテキスト変換(Whisper API)
- 面接の進行管理(Mastra Workflow)
- 回答の評価と次の質問生成(LLM)
- 最終評価の作成(LLM)
WebSocketによるリアルタイム通信
このシステムのポイントは、WebSocketによるリアルタイム通信です。REST APIだと「リクエスト→レスポンス」の一方通行になってしまいますが、WebSocketを使うと双方向のリアルタイム通信ができます。
具体的な通信内容はこんな感じです:
フロントエンド → バックエンド
- 面接開始通知(シナリオデータ込み)
- 音声データの送信(録音したデータ)
- 回答終了シグナル
- TTS(音声読み上げ)のON/OFF切替
バックエンド → フロントエンド
- 面接開始確認
- 次の質問テキスト
- システムメッセージ(「考え中...」など)
- 面接終了通知
技術選定のポイント
なぜSvelteKit? 🤔
React, Vue, Angularなど選択肢はたくさんありましたが、SvelteKitを選んだ理由は:
- シンプルな文法: 書きやすく読みやすい
- 個人的に好き: 最近Svelteをよく使っていますw
なぜMastra? 🧠
LLMのアプリケーションフレームワークはLangChainなど他にもありますが:
- 今流行ってる: なんか今流行ってるからですw
- TypeScriptとの相性: 型安全に開発できる
- 直感的なAPI: シンプルで使いやすい
開発環境
開発環境はこんな感じで準備しました:
frontend/ - SvelteKitプロジェクト
├── src/
│ ├── routes/ - 各画面のコンポーネント
│ ├── lib/ - ユーティリティ関数など
│ └── ...
backend/ - Node.jsプロジェクト
├── src/
│ ├── index.ts - メインのサーバーコード (WebSocket含む)
│ ├── lib/
│ │ ├── mastra/
│ │ │ ├── agents/ - Mastraエージェント関連
│ │ │ └── ...
│ │ └── ...
│ └── ...
└── ...
これで全体構成のイメージがつかめたでしょうか?次は、Mastraの活用方法についてもう少し詳しく見ていきます!
作り方のポイント② - Mastraエージェントの活用 🧩
今回のシステムの一番の肝となるのが、Mastraを使ったエージェント設計です。Mastraというのは、LLMアプリケーションを作るためのフレームワークで、状態管理やメモリ機能など便利な機能が揃っています。
このシステムのエージェント構成
このシステムでは、Mastraのエージェントを複数作りました:
- シナリオ生成エージェント: 設定情報から面談シナリオを生成
- 質問生成エージェント: 会話履歴と評価結果から次の質問を生成
- 回答評価エージェント: ユーザーの回答を評価して点数とコメントを生成
- 最終フィードバックエージェント: 面談全体の評価結果と総合フィードバックを生成
それぞれのエージェントがそれぞれの役割に特化することで、全体として高品質な面接システムを実現しています。では、具体的に見ていきましょう。
シナリオ生成エージェント
どんな役割?
フロントエンドの設定画面でユーザーが入力した情報(募集内容や技術スタックなど)をもとに、面談の流れを決める「シナリオ」を自動生成します。
生成されるシナリオデータの構造
実際に生成されるデータはこんな感じです👇
{
"evaluation_focus": [
{
"category": "技術力",
"keywords": [
"TypeScript",
"SvelteKit",
"Express",
"Socket.IO",
"Mastra",
"PostgreSQL",
"DrizzleORM",
"AWS(S3, CloudWatch, EC2, APIGateway, RDS, SES, SQS)"
]
},
{
"category": "主体性",
"keywords": [
"自発的な取り組み",
"積極性"
]
},
{
"category": "責任感",
"keywords": [
"業務遂行",
"納期厳守"
]
},
{
"category": "カルチャーフィット",
"keywords": [
"企業文化との適合性",
"チームワーク"
]
}
],
"interview_rules": "カジュアルに丁寧に対応してください。",
"job_description": "営業を支援するAIエージェントの開発・運用",
"system_overview": "営業を支援するAIエージェントシステム。商材に合わせた提案資料の作成、ターゲット企業の抽出などをAIにより高度に自動化するシステム。",
"tech_stack": "TypeScript, SvelteKit, Express, Socket.IO, Mastra, PostgreSQL, DrizzleORM, AWS(S3, CloudWatch, EC2, APIGateway, RDS, SES, SQS)",
"desired_role": "バックエンドエンジニア\nフロントエンドエンジニア\nAWS設定"
}
この構造を見ると、いくつかのパートに分かれていることがわかります:
- 評価ポイント(evaluation_focus): 面接で重視する項目とそのキーワード
- 面接ルール(interview_rules): 面接の進め方に関する指示
- 募集情報(job_description, system_overview, tech_stack, desired_role): 具体的な職務内容や技術スタック
これらの情報は、あとで質問生成エージェントが「何について質問すべきか」を判断する材料になります。人間の面接官が「この求人には○○のスキルが必要だから、それについて詳しく聞こう」と考えるのと同じですね。
質問生成エージェント - 面接の心臓部
次に、面談中に実際に質問を生成する「質問生成エージェント」を見ていきましょう。このエージェントこそが、システムの中で最も重要な役割を担っています。
どう動く?
このエージェントは、面接の流れに沿って、その場に適した質問を生成します。ポイントは「流れに沿って」というところ。単に予め用意された質問リストから選ぶのではなく、応募者の前の回答を考慮して、自然な会話の流れを維持しながら質問を考えます。
プロンプト設計
まず、質問生成エージェントのシステムプロンプトを見てみましょう:
// システムプロンプト
const systemPrompt = `
あなたは面接官AIとして、これまでの会話履歴と評価結果に基づいて、次の質問を生成します。
自然な会話の流れを保ちつつ、未質問のトピックをカバーするように質問してください。
応募者に対する次の質問を1つだけ生成してください。質問は具体的で、回答しやすく、対話を深める工夫をしてください。
以下のような質問の仕方を工夫してください:
- オープンエンドな質問(「はい/いいえ」では答えられない質問)
- 具体例を求める質問(「〜の例を教えていただけますか?」)
- 掘り下げ質問(「〜とおっしゃいましたが、もう少し詳しく教えていただけますか?」)
- 経験を引き出す質問(「〜の時、どのように対応されましたか?」)
質問の前後に余計な説明は不要です。質問文のみを出力してください。
可能であれば、この質問が未質問トピックのどれに該当するか、そのトピックIDも出力してください。
`;
このプロンプトの特徴は:
- 役割の明確化: 「面接官AI」として次の質問を生成する役割を明示
- 質問の質に関する指示: オープンエンドな質問、具体例を求める質問など、良い質問の特徴を具体的に指示
- 出力形式の制限: 質問文のみを出力するよう制限し、余計な説明を入れないよう指示
- トピック管理: 未質問トピックに関連する質問であれば、そのトピックIDも出力するよう指示
この詳細な指示により、エージェントは単なる質問だけでなく、対話を深める質の高い質問を生成できるようになっています。
エージェント定義コード
次に、エージェントの定義と、ユーザープロンプトの生成関数を見てみましょう:
// エージェントの定義
export const questionGeneratorAgent = new Agent({
name: 'question-generator-agent',
model: openai('gpt-4o'),
instructions: systemPrompt
});
// ユーザープロンプト生成関数
function buildUserPrompt(input: z.infer<typeof questionGeneratorInputSchema>): string {
const {
conversationHistory,
currentEvaluation,
unaskedTopics,
evaluationFocus,
interviewRules,
isFirstQuestion
} = input;
return `
【会話履歴】
${conversationHistory.map(msg => `${msg.role === 'assistant' ? '面接官' : '応募者'}: ${msg.content}`).join('\n')}
【これまでの評価】
${JSON.stringify(currentEvaluation, null, 2)}
【未質問トピック】
${JSON.stringify(unaskedTopics, null, 2)}
【評価ポイント】
${JSON.stringify(evaluationFocus, null, 2)}
【面接ルール・追加指示】
${interviewRules}
【次の質問生成指示】
${isFirstQuestion ?
'これは面接の最初の質問です。応募者が話しやすい質問から始めてください。自己紹介や経歴について質問するのが良いでしょう。' :
'応募者の前回の回答に自然につながる質問をしてください。前の回答の内容を掘り下げたり、関連する新しい話題に進めたりしてください。'}
【質問するトピックのID】
可能であれば、この質問が上記の未質問トピックのどれに該当するか、そのトピックIDも出力してください。形式は以下の通り:
TOPIC_ID: [トピックID]
`;
}
このコードのポイント:
-
Mastraのエージェントパターン: Mastraの
Agentクラスを使用して、モデルとプロンプトを設定 - GPT-4oモデル: 高性能な最新モデルを使用して質問の質を確保
-
豊富なコンテキスト:
- 会話履歴: これまでの会話を「面接官」と「応募者」の形式で提供
- 評価結果: これまでの回答に対する評価情報を提供
- 未質問トピック: まだ聞いていない重要なトピックのリスト
- 評価ポイント: 面接で重視すべき項目と関連キーワード
- 面接ルール: 面接の進め方に関する指示
-
最初の質問の特別扱い:
-
isFirstQuestionフラグを使って、面接の最初の質問と続きの質問で異なる指示を出す - 最初は「話しやすい質問」、それ以降は「前の回答に自然につながる質問」を重視
-
この構造化されたプロンプトにより、エージェントは会話の文脈を十分に理解した上で質問を生成できます。
エージェント実行コード
最後に、質問生成を実行する関数を見てみましょう:
// 質問生成の実行関数
export async function generateQuestion(input: z.infer<typeof questionGeneratorInputSchema>) {
try {
// 入力を検証
const validatedInput = questionGeneratorInputSchema.parse(input);
// ユーザープロンプトを生成
const userPrompt = buildUserPrompt(validatedInput);
// エージェントに渡すメッセージを作成
const messages: CoreMessage[] = [{ role: 'user', content: userPrompt }];
// エージェントを実行
const response = await questionGeneratorAgent.generate(messages);
// 生成されたテキストを取得
const generatedText = response.text;
// トピックIDの抽出を試みる
const topicIdMatch = generatedText.match(/TOPIC_ID: ([^\n]+)/);
const topicId = topicIdMatch ? topicIdMatch[1].trim() : undefined;
// 質問テキストからトピックID部分を除去
const question = generatedText.replace(/TOPIC_ID: [^\n]+/, "").trim();
return {
success: true,
data: {
question,
topicId
}
};
} catch (error) {
console.error('Question generation failed:', error);
// エラー時のデフォルト質問を、最初の質問かどうかで分ける
const defaultQuestion = input.isFirstQuestion
? "では面接を始めましょう。まず、あなたの経歴や自己紹介をお願いできますか?"
: "次の質問に進みましょう。あなたの強みについて教えてください。";
return {
success: true, // エラーでもユーザー体験のためにsuccessをtrueに
data: {
question: defaultQuestion,
topicId: undefined
},
error: `質問生成中にエラーが発生しました: ${error instanceof Error ? error.message : '不明なエラー'}`
};
}
}
この実装の特徴:
- 入力検証: zodスキーマによる入力データの検証
- プロンプト生成: 専用関数による構造化されたプロンプトの生成
- エージェント実行: Mastraのエージェントパターンによるメッセージ処理
-
応答の後処理:
- トピックIDの抽出: 正規表現を使って返答からトピックIDを抽出
- 質問テキストの整形: トピックID部分を除去して純粋な質問文だけを取得
-
堅牢なエラーハンドリング:
- エラー時にはデフォルト質問を用意
- 最初の質問か否かで異なるデフォルト質問を使い分け
- エラーログの記録とエラーメッセージの返却
このようなエラーハンドリングにより、たとえLLMの応答に問題が発生しても、面接プロセスが中断することなく続行できます。
面談中の状態管理
面談中には、さまざまな情報を「状態」として保持・更新していく必要があります:
// 面談の状態(イメージ)
{
scenario: {
/* 生成されたシナリオデータ */
evaluation_focus: [...],
interview_rules: "...",
job_description: "...",
// その他のシナリオデータ
},
conversation_history: [
{ role: "assistant", content: "最初の質問..." },
{ role: "user", content: "ユーザーの回答..." },
// ...会話の履歴
],
current_evaluation: {
"技術力": { score: 75, comments: ["良い点...", "改善点..."] },
// 他の評価項目...
},
unasked_topics: [
{ topic: "AWS設定の経験", asked: false },
{ topic: "チームでの役割", asked: true },
// ...未質問トピックのリスト
]
}
この「状態」は、質問生成だけでなく、面接の進行管理や最終評価の生成にも使われます。Mastraは、このような複雑な状態管理を簡単に実装できるのが強みです。
面談の進行フロー - 全体像
最後に、面談全体の流れを見てみましょう。以下の図のように、複数のステップが連携して動いています:
-
開始・初期質問: シナリオデータを元に最初の質問を生成(
isFirstQuestion: true) - 音声取得・認識: ユーザーの音声を取得し、Whisperでテキスト化
- 回答評価: 回答を評価して点数とコメントを記録
- 次の質問生成: 会話の文脈とシナリオデータを考慮して次の質問を生成
- 未質問トピックの管理: 質問したトピックを「質問済み」に更新
- 終了判定: 十分な質問数に達したか、重要なトピックを網羅したかを判断
- 最終評価生成: 全ての回答を総合的に評価して最終結果を作成
では次に、動画・音声処理の実装ポイントを見ていきましょう!
作り方のポイント③ - 動画・音声処理 🎤
ここからはフロントエンド側の実装、特に 動画・音声処理 について解説していきます。このパートが実は一番大変だったんですよね...😅
WebRTCによるカメラ・マイク制御
まず最初に必要なのは、ブラウザでカメラとマイクを使えるようにすることです。これには WebRTC という技術を使います。
カメラ&マイクへのアクセス方法
基本的な流れはこんな感じです:
- ユーザーにカメラとマイクの使用許可を求める
- 許可されたらストリームを取得
- そのストリームをビデオ要素に接続
- 音声検出やキャプチャの処理を初期化
ブラウザのAPIを使って、以下のようなコードで実現できます:
// ユーザーのカメラとマイクにアクセス
async function initializeMedia() {
try {
// カメラとマイクへのアクセスをリクエスト
stream = await navigator.mediaDevices.getUserMedia({
video: true,
audio: true
});
// 取得したストリームをビデオ要素にセット
if (videoElement) {
videoElement.srcObject = stream;
videoElement.play().catch((err) => {
console.error('Failed to play:', err);
});
}
console.log('カメラとマイクの準備ができました!');
return true;
} catch (err) {
console.error('カメラ・マイクへのアクセスエラー:', err);
isMediaSupported = false;
error = `カメラへのアクセスに失敗しました: ${err.message}`;
return false;
}
}
このコードの実行時に、ブラウザは「このサイトがカメラとマイクにアクセスしたいと言っています。許可しますか?」というダイアログを表示します。ユーザーが「許可」をクリックすると、カメラの映像がブラウザに表示され、マイクからの音声も取得できるようになります。
ここで注意が必要なのは、ブラウザごとに挙動が異なることです。特にSafariではプライバシー保護が厳しく、ユーザー操作(ボタンクリックなど)がないとメディアデバイスにアクセスできないこともあります。
静止画キャプチャの仕組み
面接中に15秒ごとにユーザーの静止画をキャプチャする機能があると、後から面接の様子を振り返る際に役立ちます。この機能はシンプルですが効果的です!
キャプチャの基本的な仕組み
- 定期的(15秒ごと)にビデオフレームをキャプチャ
- Canvas要素を使って現在のビデオフレームを画像に変換
- その画像をBase64形式で文字列化
- APIを通じてサーバーに送信
コードの核心部分はこんな感じです:
// 15秒ごとに画像をキャプチャ
function startScreenCapture() {
if (!canvasElement || !videoElement || !interviewId) return;
// キャンバスサイズをビデオに合わせる
canvasElement.width = videoElement.videoWidth || 640;
canvasElement.height = videoElement.videoHeight || 480;
// 定期的なキャプチャ設定
captureIntervalId = setInterval(() => {
if (isInterviewStarted) {
captureAndSaveFrame();
} else {
stopScreenCapture();
}
}, CAPTURE_INTERVAL); // 15000ミリ秒 = 15秒
}
// 画像をキャプチャして送信
async function captureAndSaveFrame() {
// キャンバスにビデオフレームを描画
const context = canvasElement.getContext('2d');
context.drawImage(videoElement, 0, 0, canvasElement.width, canvasElement.height);
// 画像データを取得
const imageData = canvasElement.toDataURL('image/png');
// サーバーに送信
await fetch('/api/upload-image', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
image: imageData,
interviewId: interviewId,
timestamp: new Date().toISOString()
})
});
}
ここでのポイントは画像の品質とサイズのバランスです。高品質にすると画像が鮮明になりますが、データサイズが大きくなりネットワーク転送に時間がかかります。
また、バックエンドでは受信した画像をファイルシステムに保存する処理を実装しています。これにより、面接終了後も画像を参照できるようになっています。
VADによる無音検出と自動回答終了
面接中の一番の課題は「回答が終わったかどうか」を判断することでした。ユーザーがボタンを押して終了を知らせる方法もありますが、忘れてしまうことも多いです。そこで VAD (Voice Activity Detection) という技術を導入しました。
VADとは?
VADは音声の中から「人が話している部分」と「無音部分」を自動的に検出する技術です。マイクからの入力を分析し、音声信号の特徴(振幅、周波数分布など)から話し声を判別します。
今回は ricky0123/vad-web というライブラリを使用しています。このライブラリは機械学習モデルを使った高精度なVADを提供しています。
無音検出のフロー
VADの基本的な実装はこんな感じです:
// VAD初期化関数
async function initializeVAD() {
try {
vad = await MicVAD.new({
// 長い無音を許容する設定
silenceTimeoutMs: 30000,
// 話し始めを検出
onSpeechStart: () => {
console.log('話し始めを検出しました');
// 無音検出状態をリセット
resetSilenceDetection();
// まだ録音中でなければ録音開始
if (!isRecording && !isWaitingForNextQuestion) {
startRecording();
}
},
// 話し終わりを検出
onSpeechEnd: () => {
console.log('話し終わりを検出しました');
// 無音の監視を開始
startSilenceDetection();
}
});
// VAD開始
vad.start();
} catch (error) {
console.error('VAD初期化エラー:', error);
}
}
// 無音検出開始
function startSilenceDetection() {
if (isRecording) {
silenceStartTime = Date.now();
isSilenceDetected = true;
// 無音時間のチェックを開始
silenceCheckIntervalId = setInterval(checkSilenceDuration, 1000);
}
}
// 無音時間のチェック
function checkSilenceDuration() {
if (!isSilenceDetected || !isRecording) return;
const silenceDuration = Date.now() - silenceStartTime;
// 15秒以上の無音で自動停止
if (silenceDuration >= AUTO_STOP_SILENCE_DURATION) { // 15000ms = 15秒
console.log('長時間の無音を検出したため録音を自動停止します');
stopRecording();
resetSilenceDetection();
return;
}
// 5秒以上の無音でボタンを強調表示
if (silenceDuration >= HIGHLIGHT_SILENCE_DURATION) { // 5000ms = 5秒
isButtonHighlighted = true;
}
}
このコードでは、VADが無音を検出した後:
- 5秒間無音が続くと「回答終了ボタン」を強調表示(パルスアニメーション)
- 15秒間無音が続くと自動的に回答を終了
という機能を実装しています。これにより、ユーザーが回答終了を忘れてしまっても自動的に次の質問に進めるようになっています。
音声データの効率的な送信
録音した音声データをサーバーに送信するには WebSocket という技術を使います。WebSocketは双方向通信ができるため、リアルタイム性の高いアプリケーションに適しています。
チャンク分割による効率的な送信
音声データは時間とともに大きくなるので、一度に送ると問題が生じます:
- 長時間の回答で大量のデータが蓄積
- 送信時に一時的にブラウザが固まる可能性
- 通信エラー時にすべてのデータが失われる
そこで、音声データを「チャンク」という小さな単位に分割して送信する方法を採用しました:
// 録音開始
function startRecording() {
if (!mediaRecorder) return;
try {
// チャンクをクリア
audioChunks = [];
// 録音開始
mediaRecorder.start(AUDIO_CHUNK_INTERVAL); // 1秒ごとにデータ取得
isRecording = true;
// 定期的に音声データを送信
audioChunkIntervalId = setInterval(() => {
if (audioChunks.length > 0) {
sendAudioChunk(false); // 通常のチャンク(最後ではない)
}
}, AUDIO_CHUNK_INTERVAL);
} catch (err) {
console.error('録音開始エラー:', err);
}
}
// 音声チャンクを送信
function sendAudioChunk(isLastChunk = false) {
if (!socket || audioChunks.length === 0) return;
// 最新のチャンクを取得
const latestChunk = audioChunks.shift();
// Blobをバイナリデータに変換してBase64に
const reader = new FileReader();
reader.onload = () => {
// ArrayBufferをBase64に変換
const base64Data = btoa(
new Uint8Array(reader.result as ArrayBuffer).reduce(
(data, byte) => data + String.fromCharCode(byte),
''
)
);
// Socket.IOで送信
socket.emit('audio_chunk', {
data: base64Data,
isLastChunk: isLastChunk
});
};
reader.readAsArrayBuffer(latestChunk);
}
// 録音停止時に残りのチャンクを送信
function stopRecording() {
if (mediaRecorder && mediaRecorder.state === 'recording') {
mediaRecorder.stop();
// 残りのチャンクを最後のフラグ付きで送信
sendRemainingAudioChunks();
}
}
このコードのポイントは:
- 定期的な分割: 一定時間(1秒)ごとにデータを取得して送信
- isLastChunk フラグ: 最後のチャンクを識別して処理完了を通知
- Base64 エンコーディング: バイナリデータをテキストに変換して送信
バックエンドでの音声処理連携
フロントエンドから送信されたチャンクデータは、バックエンド側で受信・処理されます:
// バックエンド側でのSocketイベント処理
io.on('connection', (socket) => {
socket.on('audio_chunk', (data) => {
const session = activeInterviews.get(clientId);
if (!session) return;
// Base64データをバイナリに変換
const binaryData = Buffer.from(data.data, 'base64');
// 音声バッファに追加
session.audioBuffer.push(binaryData);
// 最後のチャンク受信時に処理開始
if (data.isLastChunk) {
processAudioBuffer(session, clientId, socket);
}
});
});
// 音声バッファ処理
async function processAudioBuffer(session, clientId, socket) {
// 処理中フラグをセット
session.isProcessingAudio = true;
try {
// すべてのバッファを結合
const combinedBuffer = Buffer.concat(session.audioBuffer);
session.audioBuffer = []; // バッファをクリア
// Whisper APIで音声認識
const transcription = await transcribeAudio(combinedBuffer);
// 回答の評価、次の質問生成など
const evaluation = await evaluateUserAnswer(session, transcription);
const nextQuestion = await generateNextQuestion(session);
// 質問をクライアントに送信
socket.emit('next_question', {
question_text: nextQuestion,
tts_audio_url: ttsAudioUrl, // TTSが有効なら音声URL
is_greeting: false
});
} catch (error) {
console.error('音声処理エラー:', error);
} finally {
// 処理中フラグを解除
session.isProcessingAudio = false;
}
}
この連携により、フロントエンドで録音した音声がバックエンドで適切に処理され、スムーズな面接フローが実現できています。
実装で工夫したポイント
この部分の実装で特に工夫したポイントは:
1. ブラウザの互換性対応
様々なブラウザで動作させるため、以下のような対策を実装しています:
// 再生時のブラウザ互換性対応例
videoElement.onloadedmetadata = () => {
// iOS Safariではloadedmetadataイベントでもautoplayが実行できない場合がある
videoElement.play().catch((err) => {
console.error('自動再生に失敗:', err);
// ユーザーに再生ボタンを表示するなどの代替策
});
};
2. エラーハンドリングの強化
音声認識失敗時や通信エラーが発生した場合でも、面接体験が途切れないよう工夫しています:
// エラーハンドリング例
try {
// 音声認識処理
} catch (error) {
console.error('音声認識エラー:', error);
// フォールバックとして次の質問を生成
socket.emit('next_question', {
question_text: "すみません、音声が聞き取れませんでした。もう一度お話しいただけますか?",
tts_audio_url: null
});
}
3. ユーザー体験の向上
ユーザーが使いやすいよう、視覚的なフィードバックや自動化機能を実装しています:
// 無音検出時のUI強調表示
function checkSilenceDuration() {
// 5秒以上の無音で回答終了ボタンをパルスアニメーション
if (silenceDuration >= 5000 && !isButtonHighlighted) {
isButtonHighlighted = true;
// CSSでパルスアニメーションを適用
// .pulse-animation クラスを追加
}
}
4. リトライメカニズムの実装
通信エラーなどの一時的な問題に対応するため、リトライロジックを導入しています:
// 画像アップロード時のリトライロジック
async function captureAndSaveFrame() {
let retryCount = 0;
const maxRetries = 3;
while (retryCount < maxRetries) {
try {
// 画像アップロード処理
return await fetch('/api/upload-image', {...});
} catch (err) {
retryCount++;
if (retryCount >= maxRetries) throw err;
// 指数バックオフで待機
const delay = Math.pow(2, retryCount - 1) * 1000;
await new Promise(resolve => setTimeout(resolve, delay));
}
}
}
これらの工夫により、様々な環境やネットワーク状況でも安定して動作するシステムを構築できました。
次は、AIによる面接評価の実装について見ていきましょう!
作り方のポイント④ - 面接評価の実装 📊
さて、最後の作り方ポイントは 面接評価の実装 です。エンジニア採用に役立つAIシステムを作るには、ちゃんと評価ができないといけませんよね!
このシステムでは、主に4つの評価軸で面接者を評価します:
- 技術力 💻: 技術的な知識や経験、問題解決能力
- 主体性 🚀: 自発的に行動できるか、能動的な姿勢
- 責任感 🛡️: トラブル対応や期限厳守など、任された仕事への姿勢
- カルチャーフィット 🤝: チームやカルチャーへの適合性
さらに、評価対象ではないけれど情報収集として記録する項目もあります:
- 稼働条件 📅: 週何日稼働可能か、リモート/オンサイトの希望など
- 契約条件 💰: 希望単価、契約形態(業務委託/正社員など)の希望など
これらをどうやってAIに評価させるか、その実装方法を見ていきましょう!
評価機能の全体構成
評価機能は主に2つのエージェントで構成されています:
- 回答評価エージェント : 各質問への回答を個別に評価
- 最終フィードバックエージェント : 面談全体の総合評価を生成
どちらもMastraのエージェントパターンに基づいて実装されており、型安全な設計になっています。
回答評価エージェントの実装
実装の核心部分はこんな感じです:
// 入力スキーマの定義
export const answerEvaluatorInputSchema = z.object({
answer: z.string(),
evaluationFocus: z.array(z.object({
category: z.string(),
keywords: z.array(z.string())
})),
interviewRules: z.string()
});
// 出力スキーマの定義
export const answerEvaluatorOutputSchema = z.object({
技術力: z.object({
score: z.number().optional(),
comments: z.array(z.string())
}).optional(),
主体性: z.object({
score: z.number().optional(),
comments: z.array(z.string())
}).optional(),
責任感: z.object({
score: z.number().optional(),
comments: z.array(z.string())
}).optional(),
カルチャーフィット: z.object({
score: z.number().optional(),
comments: z.array(z.string())
}).optional(),
稼働条件: z.object({
comments: z.array(z.string())
}).optional(),
契約条件: z.object({
comments: z.array(z.string())
}).optional()
});
// システムプロンプト
const systemPrompt = `
あなたは面接官AIとして、応募者の回答を評価します。
提供される評価ポイントに基づいて回答を分析し、各カテゴリのスコア(0-100)とコメントを提供してください。
評価結果は以下のJSON形式で出力してください:
{
"カテゴリ名1": { "score": 数値, "comments": ["コメント1", "コメント2"] },
"カテゴリ名2": { "score": 数値, "comments": ["コメント1", "コメント2"] }
}
重要: 評価ポイントの中でカテゴリが"稼働条件"または"契約条件"のものについては、スコアを計算せず、コメントのみを記録してください。
これらは評価対象外のヒアリング項目であり、回答内容に良し悪しはありません。事実情報として客観的に記録してください。
`;
// エージェントの定義
export const answerEvaluatorAgent = new Agent({
name: 'answer-evaluator-agent',
model: openai('gpt-4o'),
instructions: systemPrompt
});
この実装の特徴を見てみましょう:
- 型安全な設計: zodスキーマで入出力を厳密に定義
- 柔軟な評価構造: 各評価項目のスコアはオプショナル(回答によっては評価できない場合もある)
- コメント配列: 複数のコメントを記録可能
- 特別なカテゴリの扱い: 「稼働条件」と「契約条件」はスコア対象外(評価ではなく事実情報の収集)
LLMによる定量評価の仕組み
LLMに評価させる際のポイントは、明確な評価基準と出力形式を指定することです。実際のプロンプトでは以下のような工夫をしています:
- 役割の明確化: 「面接官AI」としての役割を与える
- 評価対象と基準の提示: 評価ポイント(キーワード)を明示
- 出力形式の指定: JSON形式で構造化された回答を要求
- 特別カテゴリの説明: 評価対象外のカテゴリについての扱い方を明示
ユーザープロンプトの生成関数はこのようになっています:
// ユーザープロンプト生成関数
function buildUserPrompt(input: z.infer<typeof answerEvaluatorInputSchema>): string {
const { answer, evaluationFocus, interviewRules } = input;
return `
【評価対象の回答】
${answer}
【評価ポイント】
${JSON.stringify(evaluationFocus, null, 2)}
【面接ルール・追加指示】
${interviewRules}
`;
}
このプロンプトには「回答内容」「評価すべきポイント」「面接のルール」が含まれており、LLMが評価するための十分な情報を提供しています。
評価の実行と結果処理
評価を実行する関数は以下のようになっています:
// 回答評価の実行関数
export async function evaluateAnswer(input: z.infer<typeof answerEvaluatorInputSchema>) {
try {
// 入力を検証
const validatedInput = answerEvaluatorInputSchema.parse(input);
// ユーザープロンプトを生成
const userPrompt = buildUserPrompt(validatedInput);
// エージェントに渡すメッセージを作成
const messages: CoreMessage[] = [{ role: 'user', content: userPrompt }];
// エージェントを実行(JSON出力用)
const response = await answerEvaluatorAgent.generate(messages, {
output: answerEvaluatorOutputSchema
});
return {
success: true,
data: response.object
};
} catch (error) {
console.error('Answer evaluation failed:', error);
return {
success: false,
error: `回答評価中にエラーが発生しました: ${error instanceof Error ? error.message : '不明なエラー'}`
};
}
}
ここで重要なのは、response.objectを使って直接構造化されたデータを受け取っていることです。これにより、LLMの出力を解析する手間が省けます。
最終フィードバックエージェントの実装
プロンプト設計
最終評価を担当するエージェントのシステムプロンプトは以下のようになっています:
// システムプロンプト
const systemPrompt = `
あなたは面接官AIとして、面接全体の評価と最終フィードバックを生成します。
会話履歴と各回答の評価結果に基づいて、総合的な評価を行ってください。
評価結果は以下のJSON形式で出力してください:
{
"overall_impression": "総合的な印象と評価",
"strengths": ["強み1", "強み2", "強み3"],
"areas_for_improvement": ["改善点1", "改善点2"],
"category_scores": {
"技術力": 0-100の数値,
"主体性": 0-100の数値,
"責任感": 0-100の数値,
"カルチャーフィット": 0-100の数値,
"総合スコア": 0-100の数値
},
"category_comments": {
"技術力": "技術力に関する総合コメント",
"主体性": "主体性に関する総合コメント",
"責任感": "責任感に関する総合コメント",
"カルチャーフィット": "カルチャーフィットに関する総合コメント"
},
"condition_summary": {
"稼働条件": "稼働日数・リモート/オンサイト希望などのまとめ",
"契約条件": "希望単価・契約形態などのまとめ"
}
}
重要な指示:
- "稼働条件"および"契約条件"カテゴリは評価対象外のヒアリング項目です。
- これらのカテゴリで収集した情報は事実として"condition_summary"にまとめてください。
- 評価スコアは各カテゴリ(技術力、主体性、責任感、カルチャーフィット)の平均点を「総合スコア」として算出してください。
- 各カテゴリの総合コメントは、そのカテゴリの強みと課題を簡潔にまとめたものを作成してください。
`;
このプロンプトの特徴は以下の通りです:
- 役割と目的の明確化: 「面接官AI」という役割と、「最終フィードバックの生成」という目的を明示
- 出力形式の詳細な指定: JSON形式で各項目を詳細に定義
- 特別カテゴリの扱い: 評価対象外の「稼働条件」「契約条件」は別扱い
- 総合スコアの計算方法: 各カテゴリの平均値を総合スコアとして計算
- コメント作成の指針: 各カテゴリのコメントには強みと課題を含めることを明示
エージェント定義コード
エージェント本体とユーザープロンプト生成関数は以下のように実装されています:
// エージェントの定義
export const finalFeedbackAgent = new Agent({
name: 'final-feedback-agent',
model: openai('gpt-4o'),
instructions: systemPrompt
});
// ユーザープロンプト生成関数
function buildUserPrompt(input: z.infer<typeof finalFeedbackInputSchema>): string {
const { conversationHistory, currentEvaluation, evaluationFocus } = input;
return `
【会話履歴】
${conversationHistory.map(msg => `${msg.role === 'assistant' ? '面接官' : '応募者'}: ${msg.content}`).join('\n')}
【各回答の評価】
${JSON.stringify(currentEvaluation, null, 2)}
【評価フォーカス】
${JSON.stringify(evaluationFocus, null, 2)}
`;
}
ここでのポイント:
-
Mastraエージェント:
Agentクラスを使用して、モデルと命令を設定 - GPT-4oモデル: 高性能なモデルを使用して評価の質を確保
-
ユーザープロンプトの構造化:
- 会話履歴: 全質問と回答を「面接官」「応募者」の形式で表示
- 各回答の評価: これまで蓄積された評価結果
- 評価フォーカス: 募集時に設定した評価の重点項目
エージェント実行コード
最終フィードバックを生成する関数は次のように実装されています:
// 最終フィードバックの生成関数
export async function generateFinalFeedback(input: z.infer<typeof finalFeedbackInputSchema>) {
try {
// 入力を検証
const validatedInput = finalFeedbackInputSchema.parse(input);
// ユーザープロンプトを生成
const userPrompt = buildUserPrompt(validatedInput);
// エージェントに渡すメッセージを作成
const messages: CoreMessage[] = [{ role: 'user', content: userPrompt }];
// エージェントを実行(JSON出力用)
const response = await finalFeedbackAgent.generate(messages, {
output: finalFeedbackOutputSchema
});
// 質問と回答のペアを作成
const qaHistory = createQAPairs(validatedInput.conversationHistory);
// 結果にQA履歴を追加
const result = {
...response.object,
qa_history: qaHistory
};
return {
success: true,
data: result
};
} catch (error) {
console.error('Final feedback generation failed:', error);
// デフォルトの評価結果を生成
const defaultFeedback = {
// エラー時のデフォルト値...
};
return {
success: false,
error: `最終フィードバック生成中にエラーが発生しました: ${error instanceof Error ? error.message : '不明なエラー'}`,
data: defaultFeedback
};
}
}
この実装の特徴:
- 入力検証: zodスキーマによる入力データの検証
- プロンプト生成: 専用関数で構造化されたプロンプトを生成
- エージェント実行: Mastraのエージェントパターンでメッセージ処理
-
構造化出力:
outputオプションで型安全なJSONを直接取得 - QA履歴の追加: 質問と回答のペアを整形して結果に追加
- エラーハンドリング: 例外発生時にはデフォルト評価を返す
このように、2つのエージェントが連携することで、リアルタイムの回答評価と総合的な最終評価の両方を実現しています。
評価精度を上げるコツ
実際に使ってみて、評価の精度を上げるためにいくつかコツがありました:
1. 評価基準を明確に
「技術力が高い」という曖昧な表現よりも、「Node.jsの非同期処理の理解度」「Mastraの実装経験の深さ」など、具体的な評価基準を設定すると良いです。これはevaluationFocusのキーワードを具体的にすることで実現できます。
2. 面接設定をしっかり入力
面接設定画面で、募集要件や技術スタックをできるだけ詳しく入力すると、それに基づいた的確な評価ができます。これらの情報はinterviewRulesとして評価エージェントに渡されます。
3. 質問の文脈も評価に含める
現在の実装では回答だけを評価していますが、質問の内容も含めることで、その質問に対する回答としての適切さも評価できるようになります。これは今後の改善点です。
今後の改善点
評価機能には、まだまだ改善の余地があります:
- 評価の一貫性向上: 同じ回答に対して常に同じような評価ができるよう調整
- カスタム評価軸: デフォルトの評価軸だけでなく、ユーザーが自由に評価軸を設定できるように
- 評価理由の詳細化: なぜその点数になったのかをより詳しく説明
- マルチモーダル評価: 将来的には音声のトーンや表情なども評価に取り入れる
これらは今後のアップデートで対応していきたいと思っています。
さて、次はこのシステムを作ってみた感想と今後の展望について書いていきますね!
作ってみた感想と今後の展望 💭
ここまで、動画面接AI システムの作り方を紹介してきましたが、個人的な感想や今後やってみたいことをシェアしたいと思います!
こんな使い方ができるかも?
採用担当者向けスクリーニングツール 📝
実際の面接前に、基本的なスキルや適性を確認するための一次スクリーニングとして使えそうです。特に、たくさんの応募者がいる場合に、効率的に候補者を絞り込めるかもしれません。
プログラミングスクールの面接練習 🏫
エンジニア転職を目指す人たちの練習ツールとしても活用できそうです。実際の面接と似た環境で練習できるので、緊張感も含めて体験できますね。
営業トークの練習ツール 🗣️
ちょっと違う用途ですが、エンジニア面接だけでなく、営業トークの練習や、プレゼンテーションの練習にも応用できそうです。話し方や内容の評価をAIがしてくれるとか。
今後追加したい機能
もし時間があれば、こんな機能も追加してみたいです:
1. レジュメ連携機能 📄
応募者のレジュメや職務経歴書をアップロードして分析し、それに基づいた質問生成ができるようにしたいです。具体的には:
- レジュメのアップロードと解析: PDFやWordファイルのレジュメをアップロードし、AIが自動的に経歴、スキル、プロジェクト経験を抽出
- 経歴に基づいた質問生成: 「〇〇プロジェクトではどのような課題がありましたか?」など、レジュメの内容に基づいた具体的な質問を生成
- スキルの深掘り: レジュメに記載されたスキルの深さを確認するための質問を自動生成
- レジュメの最適化提案: 面接終了後、レジュメ自体の改善点を提案し、より魅力的な形式でレジュメを再出力
これにより、より個別化された面接体験と、応募者へのフィードバックの価値を高められると思います。
2. カスタム評価軸 🛠️
現在は「技術力・主体性・責任感・カルチャーフィット」という固定の評価軸ですが、ユーザーが自由に評価軸を設定できるようにしたいです。例えば「英語力」「プレゼン能力」などを追加できると、より汎用的に使えるようになりそうです。
3. 面接記録の保存と比較 📊
複数回の面接結果を保存して、時系列での成長を可視化できるといいなと思います。「前回よりプレゼン力が10点アップしました!」みたいな。
最後に
MastraやWebRTCといった便利なライブラリ・技術を使えば、十分に面白いものが作れることがわかりました。特にMastraのようなLLMアプリケーションフレームワークは、複雑なAIの状態管理や処理フローを扱いやすくしてくれるので、今後もどんどん活用していきたいと思います。
次はどんなAIアプリを作ろうかな〜?🤔 アイデア募集中です!
使ってみたい方へ 🚀
このMastra動画面接AIシステムは、現在下記のBOOTHショップで販売中です。
🎥 Mastraで作るAI動画面接PoCテンプレート(LLM × Whisper対応)
ソースコード一式をZIPファイルでダウンロードできます。簡単なセットアップガイドも同封されています。価格は今ならなんと3,000円です!
おわりに
ここまで読んでいただき、ありがとうございました!この記事が「LLMと動画/音声を組み合わせたアプリケーション開発」の参考になれば嬉しいです。
MastraはLLMアプリを作るハードルをグッと下げてくれます。みなさんも、ぜひMastraを使って面白いAIアプリを作ってみてください!
他にも面白いAIアプリを作ったら、またZennで記事にしますね!次回もお楽しみに~🎉
Xやっています!
AIエージェント開発に関する投稿が多目ですので、良かったらフォローしてください!
@edo1z
Discussion