スマートコントラクトとしての分散型 NoSQL データベース
ブロックチェーンは分散化により、検閲耐性と停止不可能なネットワークを備え、フィンテックに革命をもたらしています。しかし、これまでのところ、その主な使用例はトークン送金であり、そのスケーラビリティは大規模な金融導入には不十分です。一方、インターネットとウェブはデータで構成されており、web3 は金融セクターを超えた中央集権的なデータサイロへのアンチテーゼです。現在のブロックチェーンは、ウェブレベルまでスケールすることはできません。
多くの人が分散型ソーシャルネットワークの構築を試みましたが、完全に分散化されたものを構築することには失敗しています。これは主に、web2 クラウドデータベースの実用的な代替手段がこれまで不可能だったためです。多くの分散型データベースプロジェクトがありましたが、それらはすべてブロックチェーンインデクサー、p2p グラフ DB、zkp ベースのプライバシー DB などの特定ドメイン向けであり、web2 データベースを置き換えるための汎用データベースではありませんでした。結果として、ほとんどの web3 ソーシャルネットワークは十分に分散化されていると自称しながらも、データのインデックス作成や複雑なサービスロジック、API には中央集権型のサーバーとデータベースを使用しています。
これは分散型アプリケーションにとって明らかに大きな問題です。なぜなら、中央集権型データベースを失うと、データ抽出のための API に依存するサービスは機能を停止するからです。そして、中央集権的な組織がデータベース層を管理している限り、それは遅かれ早かれ停止することになります。データベース層は、スケーラブルなサービスを運営する際に最もコストがかかるものであり、開発チームはインフラストラクチャーの費用を永遠に支払い続けることはできません。プロバイダーが API の価格を任意に変更したり、API を完全に停止してサービス自体を閉鎖したりする例は数多くあります。
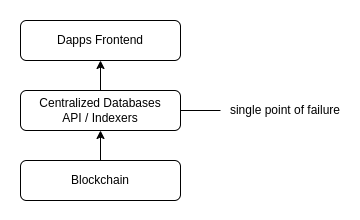
中央集権型データベースなしで完全に分散化されたアプリケーションを構築することも可能ですが、その場合、すべてのロジックはスマートコントラクト上で実行する必要があり、効果的なデータインデックス作成なしでは機能が非常に限られたものになります。
WeaveDB は、web2 クラウドデータベースのパフォーマンスとスケーラビリティを備えた完全に分散化されたデータベースを構築することで、これらの問題の解決を目指しています。
4 つのボトルネック
汎用の完全に分散化されたデータベースが実現されていない理由は、4 つの大きなボトルネックがあるためです:
-
コスト
ブロックチェーンの計算とストレージは、L2 ロールアップを含め、法外に高額です。イーサリアムでは 1GB のデータを保存するのに 1,000 万ドルかかります。 -
パフォーマンス
ブロックチェーンのファイナリティは遅く、500ms から 10 分の範囲です。しかし、実用的な DB には 1ms 未満のファイナリティと 10,000 - 100,000 TPS が必要です。 -
スケーラビリティ
ストレージサイズは法外なコストによってボトルネックとなっています。2024 年現在、イーサリアムの総ストレージサイズはわずか 1TB 程度です。ウェブ上では毎日 300M TB 以上のデータが作成され、加速しています。 -
アクセス制御
管理者のいる web2 データベースとは異なり、分散型データベースはパーミッションレスであり、デフォルトでは誰でもどこからでも何でも書き込むことができます。正確なアクセス制御が必要ですが、単純なデータ所有権を超えるためには、複雑な実装を伴う高度に柔軟なロジックが必要であり、これまでどのデータベースプロジェクトもそれを解決できていません。
したがって、スマートコントラクトとしての実用的な分散型データベースの構築は不可能に思えますが、このペーパーでは Arweave 永続ストレージによるソリューションを提示します。
なぜスマートコントラクトデータベースなのか?
解決策に入る前に、スマートコントラクトデータベースの重要性を強調したいと思います。既存の技術を使用して分散型データベースを構築し、データベースを実行するノードのネットワークを分散化することもできます。しかし、このアプローチはデータベースの使用可能性を大きく制限します。なぜなら、web3 データベースと web2 データベースのコアコンポーネントは完全に異なるべきだからです。その代わりに、私たちはすべてのコンポーネントをスマートコントラクトとして一から新しいデータベースを構築しました。これにより、分散型ネットワークのコンテキスト内で重要な機能が解放されます。
-
計算とステートの検証可能性
データ操作のためのすべてのアクセスロジックと計算はオンチェーンに記録され、誰でも検証可能である必要があります。スマートコントラクトとそのストレージベースのステートだけがそのような公開検証を可能にします。 -
他のスマートコントラクトとの構成可能性
スマートコントラクトは分散型アプリケーションの構成要素であり、他のスマートコントラクトと構成可能です。WeaveDB は DeFi、SocialFi、NFT、DAO、ブロックチェーンゲームなど、他のスマートコントラクトプロトコルの一部となることができます。 -
他のブロックチェーンとの相互運用性
スマートコントラクトプロトコルとして確立され、分散型ネットワークによって管理されることで、他のブロックチェーンとの相互運用性が開かれます。私たちは 3 種類の相互運用性を実装しており、詳細は後のセクションで説明します。- ゼロ知識証明 (ZKP)
- インターブロックチェーンコミュニケーション (IBC)
- しきい値署名スキーム (TSS)
これらの機能はすべて、データベース自体がブロックチェーン上のスマートコントラクトである場合にのみ、ブロックチェーン標準プロトコルで解放されます。
私たちはスマートコントラクトを、分散型ネットワークを持つブロックチェーン上で誰でも検証可能な不変のスクリプトと定義しています。この意味では、EVM 上の Solidity だけがスマートコントラクトの実装ではなく、スマートコントラクトはどんな言語でもどんな VM 上でも書くことができます。
どのように問題を解決するか
Arweave ストレージベースのコンセンサスパラダイム(コスト)
Arweave は永続ストレージに特化したブロックチェーンのようなプロトコル(Blockweave)です。アップロード時に少額の一回限りの料金を支払うだけで、データは事実上永久に(最も悲観的な見積もりでも少なくとも 200 年間)保存されます。GB あたり約 5 ドルのコストで、イーサリアムの 40 万分の 1 の価格であり、ストレージハードウェアのコストが毎年下がるにつれてさらに安くなります。
永続ストレージ上にスマートコントラクト層を構築する新しい方法があり、この方法論は Storage-based Consensus Paradigm (SCP) と呼ばれています。SCP はスマートコントラクト層のコストを大幅に下げるために、オフチェーン計算とストレージコンセンサスを使用するというアイデアです。本質的には、スマートコントラクト評価に必要なすべてのデータは Arweave に永続的に保存され、ステート評価はクライアント側とオフチェーンで遅延実行が可能で、これはコストがかかりません。つまり、安価な永続ストレージと無料のオフチェーン計算の組み合わせがスマートコントラクト層を可能にします。これは SmartWeave と呼ばれています。

Warp SmartWeave シーケンサー(パフォーマンス)
Arweave は絶対的なファイナリティを採用していないため、安全なブロック時間は約 20 分です。これはもちろんスマートコントラクト実行層にとっては遅すぎるため、Warp は評価なしで即座にトランザクションを順序付けて確定する効率的なシーケンサーを導入しました。スマートコントラクトトランザクションをバンドルし、Irys や ArIO などのバンドルプロトコルを介して Arweave にアップロードします。これによりファイナリティまでの時間(TTF)が 10ms にまで短縮されます。
前述のように、Warp シーケンサーはコントラクトのステートを評価せず、クライアント側での遅延評価を行うため、web2 クラウドデータベースよりもさらに高速なパフォーマンスと低レイテンシーを実現します。しかし、これは別の問題を引き起こし、それは本論文の最後で扱う WeaveDB Rollup の開発につながりました。

KV ストレージアダプター(スケーラビリティ)
データベース全体はスマートコントラクトとして実装されていますが、すべてのデータをスマートコントラクトのステートとして保存することはスケーラブルでもポータブルでもありません。データベースが何かを評価する必要があるたびに、データベース全体をメモリにロードする必要があり、例えば 1 億のデータセットがある場合は不可能です。
幸いなことに、Warp SmartWeave は、インターフェース(get/put/del)のみを持つ基礎となる KV ストレージを可能にするプロトコルを実装しています。これは KVS アダプターとして機能し、KV インターフェースを介してデータをどのように保存するかはノード実装次第です。ノードはインターフェースを介して決定論的にデータを保存するために、既存のデータベース技術を使用でき、データベースがどれだけスケールするかはスマートコントラクトの制約ではなく、ノードの KV 実装次第です。これは将来的にハードウェアとデータベース技術が改善されるため、よりフューチャープルーフです。このようにして、データベースを無限にスケーラブルにします。これはイーサリアムクライアントの多様性と同等です。
WeaveDB はコントラクトステートとして最小限のデータベース設定のみを保存します。実際のデータとインデックスは、ノードアダプタースクリプトが定義する方法でノードによって設定された基礎となる KV ストレージに保存されます。
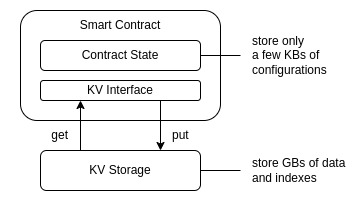
さらに、Arweave ネットワーク自体は無限にスケーラブルであることが想定されています。上限はストレージコストによってのみ制約されます。したがって、データベースが大量のデータを保存する必要がある場合、理論的には誰かがそれに対して支払いさえすればよいのです。そして、スマートコントラクト KVS インターフェースを介してデータをどのように扱うかは、ノード KVS 次第です。
FPJSON(アクセス制御)
単純なデータ所有権ロジックは単純な署名検証フローで実装できますが、それは web2 データベースの仕組みとは全く異なります。web2 データベースは実際には、サーバー/クライアント側のアプリケーションロジックとデータベースに設定されたデータアクセスルールの組み合わせです。ユーザーがデータベースにどこからアクセスするかを制御できないため、そのような web2 のユースケースを完全にカバーするには、web3 データベースはデータベース側に高度なアプリケーションロジックと高度なアクセス制御ルールの両方を含める必要があります。言い換えれば、データ所有権はデータベースロジック内でプログラム可能である必要があります。不変のスマートコントラクトでこれらすべてをどのように達成するのでしょうか?
答えは FPJSON です。これは JSON 配列の形式で関数型プログラミングを可能にするために開発したドメイン固有言語(DSL)です。FPJSON には 250 以上の構成可能な関数が付属しており、どのレベルの高度なロジックでも JSON 配列として表現できます。
["add", 1, 2][("difference", [1, 2, 3], [3, 4, 5])] = // = 3
[1, 2][(["map", ["inc"]], [1, 2, 3])][ // = [4, 5, 6]
(["compose", ["map", ["inc"]], ["difference"]], [1, 2, 3], [3, 4, 5])
]; // = [2, 3]
FPJSON はスマートコントラクトデータベースにおいて極めて重要な役割を果たします。なぜなら、あらゆるロジックをコントラクトステートとして保存し、データベース機能を拡張するために新しいコントラクトをデプロイすることなく再利用できるからです。FPJSON がなければ、データベースへのアクセス制御ルールを更新するたびに新しいスマートコントラクトをデプロイする必要があります。
以下は、FPJSON で定義された複雑なアクセス制御ルールの例です。
[
// ユーザーをフォローするクエリタイプを定義する($signer=$from が $to をフォローする)
"set:follow",
[
// ドキュメント ID を分割する(ID は "from:to" 形式)
["split()", [":", "$id", ["=$from", "=$to"]]],
// 署名者が from であるかチェックする(署名者は署名で検証される)
["=$isFromSigner", ["equals", "$from", "$signer"]],
// アップロードされたデータを修正し、クエリのタイムスタンプで誰が誰をフォローしているかを追加
["mod()", { from: "$from", to: "$to", date: "$ms" }],
// $isFromSigner が true の場合のみクエリを受け入れる
["allowif()", "$isFromSigner"],
],
];
WeaveDB には、分散型データベースに必要な非常に強力で独自の機能セットが付属しており、それらはすべて FPJSON で定義されています。新しいコントラクトをデプロイしてデータベースをアップグレードする必要はなく、JSON 形式でコントラクトステートを更新するだけで、新しい機能でデータベースをアップグレードできます。WeaveDB 自体は、EVM の Solidity などの任意のスマートコントラクトよりも強力です。
await setRules(fpjson_snippet, COLLECTION_NAME);
これだけでデータベースロジックをアップグレードでき、新しいスマートコントラクトをデプロイするのと同じくらい強力です。
FPJSON に関する 3 つの重要なポイント:
- 250 以上の関数を JSON 形式で構成することで、あらゆるレベルの複雑なロジックを構築できます。
- FPJSON はスマートコントラクトステートとして保存された再利用可能な JSON データなので、データベースロジックをアップグレードするために新しいスマートコントラクトをデプロイする必要がありません。
- WeaveDB ではすべてが JSON であり、FPJSON は分散型データベース特有の強力な機能を可能にします。
FPJSON は、プログラム可能なデータ所有権を持つ汎用分散型データベースを実現し、web2 クラウドデータベースの完全な置き換えを可能にするものです。
WeaveDB クエリ
WeaveDB クエリは主に Firestore クエリと互換性がありますが、より単純な構文を持っています。スマートコントラクトステートとして保存可能であるため、クエリを含む WeaveDB 内のすべてのものは JSON として表現されます。
Firestore SDK では、次のようなクエリを作成します:
const ppl = (
await firestore
.collection("people")
.orderBy("age", "desc")
.where("age", ">", 20)
.limit(5)
).map((doc) => docv.data());
WeaveDB SDK には糖衣構文があり、クエリを簡略化します:
const ppl = await weavedb.get("people", ["age", "desc"], ["age", ">", 20], 5);
これは単に簡略化のためだけでなく、JSON 形式との互換性のためでもあります。WeaveDB クエリは FPJSON スニペットで JSON 配列として表現され、アクセス制御ルール、cron ジョブ、トリガーの一部として再利用されます。Firestore クエリ構文ではこれができません。
const query = ["get", "people", ["age", "desc"], ["age", ">", 20], 5]]
利用可能なクエリタイプ:
await get("people", "Bob");
await add({ name: "Mike", age: 15 }, "people"); // docID は自動生成されます
await set({ name: "Bob", age: 20 }, "people", "Bob");
await update({ age: 30 }, "people", "Bob");
await upsert({ name: "Alice", age: 40 }, "people", "Alice");
await delete ("people", "Alice");
複数のドキュメントを取得するには、条件付きクエリを使用できます:
// いくつかの人物を追加してみましょう
await add({ name: "Bob", age: 15, drinks: ["milk", "juice"] }, "ppl")
await add({ name: "Alice", age: 20, drinks: ["cola", "mocha"] }, "ppl")
await add({ name: "Mike", age: 30, drinks: ["water", "beer"] }, "ppl")
// 条件付きで取得
await get("ppl", ["age", "==" 20]) // Alice
await get("ppl", ["age", "!=" 20]) // Bob, Mike
await get("ppl", ["age", ">" 20]) // Mike
await get("ppl", ["age", ">=" 20]) // Alice, Mike
await get("ppl", ["age", "<" 20]) // Bob
await get("ppl", ["age", "<=" 20]) // Bob, Alice
await get("ppl", ["age", "in", [ 20, 21, 22 ]]) // Alice
await get("ppl", ["age", "not-in", [ 20, 21, 22 ]]) // Bob, Mike
await get("ppl", ["drinks", "array-contains", "beer"]]) // Mike
await get("ppl", ["drinks", "array-contains-any", ["milk", "cola"]]]) // Bob, Alice
前述のようにカスタムクエリを定義することもできます。アクセスルールで mod() を使用してデータフィールドが自動入力される場合、空のデータ {} を送信できます。
await query("set:follow", {}, "follows", "Bob_addr:Alice_addr");
// { from: "Bob_addr", to: "Alice_addr", date: TIMESTAMP } が保存されます
batch クエリは同じ署名者からの複数のクエリをバンドルし、bundle クエリは異なる署名者からの単一クエリと batch クエリをバンドルします。WeaveDB ロールアップは bundle クエリを使用して上位層にトランザクションをコミットします。
await db.batch([
["set", { name: "Bob" }, "ppl", "Bob"],
["upsert", { name: "Alice" }, "ppl", "Alice"],
["delete", "John"],
]);
const batch = [
["set", { name: "Bob" }, "ppl", "Bob"],
["upsert", { name: "Alice" }, "ppl", "Alice"],
];
const batch_query = await db.sign("batch", batch, { evm: wallet });
const single_query1 = await db.sign("add", { name: "Mike" }, "ppl", {
evm: wallet2,
});
const single_query2 = await db.sign("add", { name: "Beth" }, "ppl", {
evm: wallet3,
});
await db.bundle([batch_query, single_query1, single_query2]);
WeaveDB インデクサー
WeaveDB は Warp KVS アダプターインターフェース用に最適化された独自の B+ ツリーを使用します。すべてのインデックスはオンチェーンで Arweave に永続的に保存されるため、オフチェーンの中央集権型データベースとは異なり、インデックスへのアクセスを失うことはありません。技術的には、インデックスを構築するロジックがオンチェーンに保存されるため、スマートコントラクトを評価すると、コントラクトは自動的にインデックスを再構築します。インデックス自体はノードの基礎となる KV ストレージに保存されます。
単一フィールドのインデックスは自動的に追加されますが、コントラクト所有者は複数フィールドのインデックスを追加して、それらを使用した条件付きクエリを可能にする必要があります。
await db.addIndex("ppl", [
["age", "desc"],
["height", "asc"],
]);
この呼び出しは、ppl をインデックス化するための B+ ツリーを追加し、まず age を descending 順にソートし、次に height を ascending 順にソートします。これにより、以下のようなクエリが ppl コレクションで利用可能になります:
await get("ppl", ["age", "desc"], ["height", "asc"], ["age", ">", 20]);
しかし、このデザインではコントラクト所有者がデータベースにインデックスを追加する唯一の権限を持つことになります。したがって、アプリに必要な特定のインデックスが所有者によって追加されない限り、データベースはアプリにとって役に立ちません。
モジュラーデータベース
この問題に対処するために、モジュラーデータベースアプローチを採用しました。このデザインでは、インデクサーがデータソースから切り離され、誰でも自分のアプリケーション用に任意のインデクサーをコアデータコントラクトにパーミッションレスに追加できます。アーキテクチャは 4 つの層で構成されています。
-
データソース
設定とデータ保存を処理するコアデータベースコントラクト。 -
インデクサー
効率的なデータ抽出を処理するインデクサー。NoSQL データベース用に最適化された B+ ツリー。 -
クエリパーサー
API クエリを評価し、要求されたデータを抽出するために使用するインデクサーを明確にします。 -
パブリック API
データベースにアクセスするための API を定義するパブリックインターフェースコントラクト。

このモジュラーアーキテクチャは、分散型データベースに新しいパラダイムをもたらします。同じデータソースがパーミッションレスなインデクサーを持つ複数のアプリケーションで共有され、同じデータソース上に異なるデータベースタイプ(RDB/NoSQL/GraphDB)を構築することさえできます。パブリック API は永続的に利用可能であり、API に依存する dapps はデータへのアクセスを失うことなく永久に機能することができます。
ユースケースに応じて、永続的なデータソースを使用してオフチェーンインデクサーを構築することもできます。
WeaveDB の特徴
分散型データベースのデータ所有権とアクセス制御は、web2 データベースとは全く異なります。そのため、web2 アプリケーションの分散型バージョンを構築するには、非常に異なる機能セットが必要です。必要な機能を明確にするため、私たちは WeaveDB 上に完全に分散化された Twitter を構築し、単に web2 データベースを分散化するだけでは決して機能しないことを発見し、不足しているすべてのデータベース機能を実装しました。WeaveDB は、完全に分散化された Twitter の代替品を構築できる最初の分散型データベースです。
ここでは、ユニークな機能セットと、分散型データベースがそれらを必要とする理由を説明します。
暗号ウォレット認証
分散型アプリケーションはパーミッションレスにユーザーを認証する方法が必要であり、多くのブロックチェーンで採用されている公開鍵暗号方式はそのための最良の方法です。WeaveDB は、多くのブロックチェーンネットワークと互換性のある複数のタイプの公開鍵アルゴリズムを統合しています。
- secp256k1 (Bitcoin / Ethereum / EVM)
- Ed25519 (Dfinity / Cosmos)
- RSA (Arweave)
- BabyJubJub (PolygonID / Intmax)
WeaveDB はリレーヤーメカニズムを通じて他の web3 アイデンティティプロトコルも認証できます。
- Lens Profile NFT (Lens Protocol)
- NextID (Mask Network)
- WebAuthn (生体認証)
認証コンポーネントは拡張可能です。SchnorrとBLS (Boneh-Lynn-Shacham)も統合が計画されています。
データスキーマ
分散型データベースは通常、ドキュメントベースの NoSQL データベースであっても、正確なデータスキーマを必要とします。なぜなら、誰でも不正な形式のデータセットを更新でき、一貫したデータ構造を期待するアプリケーションを破壊する可能性があるからです。私たちは、柔軟なデータスキーマが SQL テーブルスキーマよりも優れていると考えていますが、自由形式のデータスキーマ(またはスキーマなし)は、ほとんどのアプリケーションが特定の固定データモデルを期待するため、最初から何のメリットもありません。
WeaveDB は各コレクションのデータスキーマを定義するためにJSONLogicを採用しています。
{
follows: {
type: "object",
required: ["from", "to", "date"],
properties: {
from: { type: "string" },
to: { type: "string" },
date: { type: "number" },
},
},
}
アクセス制御ルール
1 対 1 のデータ所有権だけが必要な場合、データアップローダーの署名を検証するだけで済み、ほとんどの p2p データベースプロジェクトはそのバリエーションです。しかし、これは web2 データベースの動作方法とはまったく異なります。Web3 はデータ所有権に関するものなので、各データに所有者を割り当てることは良いスタートですが、所有権はプログラム可能であるべきであり、ほとんどのデータは事前定義されたロジックで共有所有権を持つべきです。ここで FPJSON が役立ちます。
FPJSON を使用すると、各コレクションに対して複雑なアクセス制御ルールを設定でき、ルール内でアップロードされたデータを変更してデータフィールドを追加/削除したり、データベースにコミットする前にデータを変更したりすることもできます。また、別々のルールを持つカスタムクエリを任意の数だけ設定できます。
前のセクションで説明したユーザーをフォローするためのカスタムクエリルールの例。
[
"set:follow",
[
["split()", [":", "$id", ["=$from", "=$to"]]],
["=$isFromSigner", ["equals", "$from", "$signer"]],
["mod()", { from: "$from", to: "$to", date: "$ms" }],
["allowif()", "$isFromSigner"],
],
];
自動実行 Cron
SmartWeave の遅延実行の性質を活用することで、WeaveDB はトランザクションを生成せずに定期的に実行されるクエリを可能にします。コントラクトステートは、クライアント側でデータが要求されたときにのみ遅延評価されます。cron ジョブが定義されると、WeaveDB は実行スケジュールを計算し、最新のデータを返す前に遡って実行を適用できます。このようにして、Ethereum スマートコントラクトのように定期的なトランザクションを作成するキーパーノードは必要ありません。
自動実行 Cron は、一時的/期限切れデータの削除や、特定期間内の「いいね」の数に基づくトレンド投稿の計算など、管理タスクに役立ちます。
クエリトリガー
トリガーは、複雑なアプリケーションを構築する際に最も重要な機能の 1 つです。トリガーは、FPJSON で定義された条件に基づいて、あるクエリから別のクエリをトリガーすることができます。例えば、誰かが投稿に「いいね」をした場合、データコレクションをどのように更新すべきかを考えてみましょう。良いデータベース構造は、postsとlikesの 2 つのコレクションを持つことです。各postドキュメントには「いいね」カウントがあるべきですが、postは作成者のみが更新可能であるべきです。つまり、「いいね」をする人は、自分が「いいね」しているpostに対する書き込みアクセス権を持っていません。この場合、likeを追加するクエリは、post内の「いいね」カウントをインクリメントする内部クエリをトリガーする必要があります。このようにして、「いいね」をする人は、更新するアクセス権を持っていない投稿の「いいね」カウントを更新できます。
これは単純な例ですが、web2 アプリケーションを構築している場合、このようなクエリの連鎖はどこにでも存在します。Firestore はサーバーレス関数を持つ内部システムでこれを処理できますが、分散型データベースにはそのような統合システムはありません。WeaveDB トリガーは、スマートコントラクトロジック内でその機能を可能にします。データアクセスと所有権をオーバーロードするための内部クエリ連鎖がなければ、完全に分散化された Twitter を構築することはできません。
リレーヤー
スマートコントラクトは外部ソースからデータを取り込むためのオラクルを必要とします。WeaveDB には、リレーヤーの署名を検証し、事前定義されたロジックで値を追加/変更するための組み込みリレーヤーメカニズムがあります。例えば、Ethereum 上の一部の NFT の所有権を確認するリレーヤーを設定し、リレーヤーが有効性に署名して所有者のアドレスをアップロードされたデータに追加します。WeaveDB はリレーヤーの署名を検証し、データベースにコミットする前に追加データをアップロードされたデータとマージします。
WeaveDB リレーヤーを Lit プロトコルの PKP と組み合わせて、検証可能なリレーヤーを構築できます。
ZKP 検証機
WeaveDB には、zkp 検証機と接続するためのアダプターインターフェースも備わっています。zk サーキットを記述し、WeaveDB がデータ自体を明らかにすることなく、一部のデータを検証するための証明を検証するようにできます。これにより、オフチェーンデータと接続する多くの新しいユースケースが可能になります。例えば、実際のデータを明らかにすることなく、検証可能な資格情報(VC)内の特定の情報のみを検証できます。
zkDB / zkRollup
別のライトペーパーで、Ethereum スマートコントラクトから直接検証可能な任意の JSON データを作成するゼロ知識証明可能 JSON(zkJSON)について書きました。WeaveDB は NoSQL データベースであり、各ドキュメントは実際に zkJSON であり、全体として zkDB を形成します。したがって、zkRollup 機能をオンにすると、WeaveDB に保存するどのようなデータも他のブロックチェーンスマートコントラクトから直接クエリ可能になります。zkRollup については、別のライトペーパーで説明します。
WeaveDB スマートコントラクトは zkDB のためのマークルツリーを保存し、誰でも簡単な呼び出しで最新のマークルハッシュを検証できます。Warp SmartWeave にはプラグイン拡張(EVM のプリコンパイルに相当)があり、WeaveDB にはプリコンパイルされた zk プルーバーが付属しているため、誰でもクライアント側のチェーン上の任意のデータの証明を生成し、Ethereum やその他の EVM ブロックチェーンからクエリを実行できます。これはある種のオンチェーン zk プルーバーに相当します。
このアプローチの課題
SmartWeave コントラクトとしての分散型データベースは、Arweave 永久ストレージのおかげで非常に低コストで web2 データベースのパフォーマンスとスケーラビリティを実現します。しかし、この設計は新たな一連の問題をもたらします。
クライアント側のスケーラビリティ
計算はクライアント側で遅延実行されるため、現在クライアントはコントラクトの現在のステートを評価する負担を負い、そのために Arweave ゲートウェイからトランザクションをダウンロードしてコントラクトのトランザクション履歴全体をキャッシュする必要があります。数百万のトランザクションがある場合、これには数分かかります。そして各クライアントがこれを行う必要があります。これはクライアント側では決してスケールしません。この問題を解決する 1 つの方法は、クライアントがアクセスして最新のコントラクトステートを即座に取得できる中間評価ノードを持つことです。しかし、このアプローチも次のセクションで説明する 2 番目の問題を解決しません。
低遅延でのデータ一貫性
SmartWeave はクラウドデータベースのパフォーマンスを提供できます。あるいはさらに優れているかもしれません。これは 2 つの要因によって可能になります。
- 計算はクライアント側でローカルに実行される
- Warp シーケンサーは何も評価しない
これら 2 つの最適化により、クライアントが他のクライアントと同期しているかどうか確信できないため、データの一貫性は実際には保証されません。シーケンサーはコントラクトステートを評価してステートの有効性を確保しないため、シーケンサーからのファイナリティを取得し、新しいファイナライズされたキャッシュで現在のステートを評価するまで、データがどうなるかわかりません。データベースのような一貫性を本当に確保したい場合は、クエリを順番に一度に 1 つずつ実行する必要があります。これはファイナリティを取得した後、コミットする前に現在のステートを評価するのに 3〜5 秒かかります。
アプリケーションが高遅延またはデータの不整合のいずれかを許容できる場合は、純粋な SmartWeave コントラクトでうまくいくでしょう。
しかし、データの一貫性と低遅延を持つ高性能アプリケーションの web2 のユースケースを置き換えるには、さらなる最適化が必要であり、これは WeaveDB Rollup ライトペーパーで説明します。

Empowering your applications with a high-performance, scalable, decentralized, and reliable database solution 👉 linktr.ee/weavedb
Discussion