インタラクティブな可視化システムの要件整理とモック作成
背景
インタラクティブなデータ可視化を行うようなアプリケーションを開発しています。ユーザーのインタラクションによって画面の更新を行う可視化システムの実装を進めやすくなるように要件などを整理しつつ開発を行なったので、今作っている具体的なアプリを例にその内容を共有します。アプリケーション自体の話というよりは、インタラクティブな可視化アプリケーションを作る際のアーキテクチャについての考えたこととその実装を書いています。
可視化システムの概要
高次元の時系列データの次元削減による可視化においてズーム動作を行うようなアプリケーションのモックです。通常のズーム動作とは異なっており、ユーザーの選択範囲に応じたレイアウト更新を行います。

(使用技術)
Fast API, D3.js, numpy, pandas, sklearn, scipy
次元削減を含むデータ処理を高速に行うライブラリがあるpythonを使いたくてこの選択になっています。そこまでのこだわりは今回はないです...
要件の整理
データをある手法を使って処理することで可視化し、それに対してユーザーがインタラクションを与えることでレイアウトの更新を行うようなアプリケーションを考えます。
クライアント
- 初期レイアウトの情報を受け取り描画を行う
- ユーザーのインタラクションを受け取る(今回はzoom)
- 新しいレイアウトの情報を受け取り、描画を行う: この際にユーザーが認知的負荷を減らすためにアニメーションなどを加える
- 手法などを切り替える設定UI
バックエンド
- データの読み込み
- レイアウト計算方法の設定
- 初期レイアウトの計算
- リクエスト(インタラクション)に応じたレイアウト計算
- レイアウトの補正やアライメント
- 設定の更新: データ処理手法の切り替え

バックエンドの詳細な要件
- 処理方法などの設定をユーザーが切り替えたい
- データ処理の手法を追加したい
- 複数のデータ処理を組み合わせたい
- アライメントのために一つ前のレイアウトを保存しておきたい
- 複数ユーザーがアクセスし、それぞれが状態をもつ
主にこれらの要件について、どういう形を取った実装がいいか考えていく
実装
主にコードの構造的な話です。なんとなく整理しながらどんなデザインパターンや方法が向いているかを考えながら進めてみました。
全体
データ処理部分
今回は高次元の時系列データに対して次元削減とアライメントのデータ処理があります。それぞれでいくつかの手法があり、次元削減だとPCAだったりt-SNEだったり。
データ処理の手法を追加したいという目的が合ったのでそれに対して基底クラスを定義して継承する形を取りました。
# 抽象クラス
class DimensionalityReducer(ABC):
n_components:int
@abstractmethod
def __init__(self, n_components:int):
self.n_components = n_components
@abstractmethod
def reduce(self, X: np.ndarray) -> np.ndarray:
pass
# 具体クラス
class PCADimensionalityReducer(DimensionalityReducer):
def __init__(self, n_components:int):
super().__init__(n_components)
def reduce(self, X: np.ndarray) -> np.ndarray:
pca = PCA(n_components=self.n_components)
return pca.fit_transform(X)
加えてユーザーが動的に手法を切り替えたいという目的があります。それをまた分けるとこんな感じ。
- 次元削減の手法を変えたい
- データ処理のパイプラインを変えたい
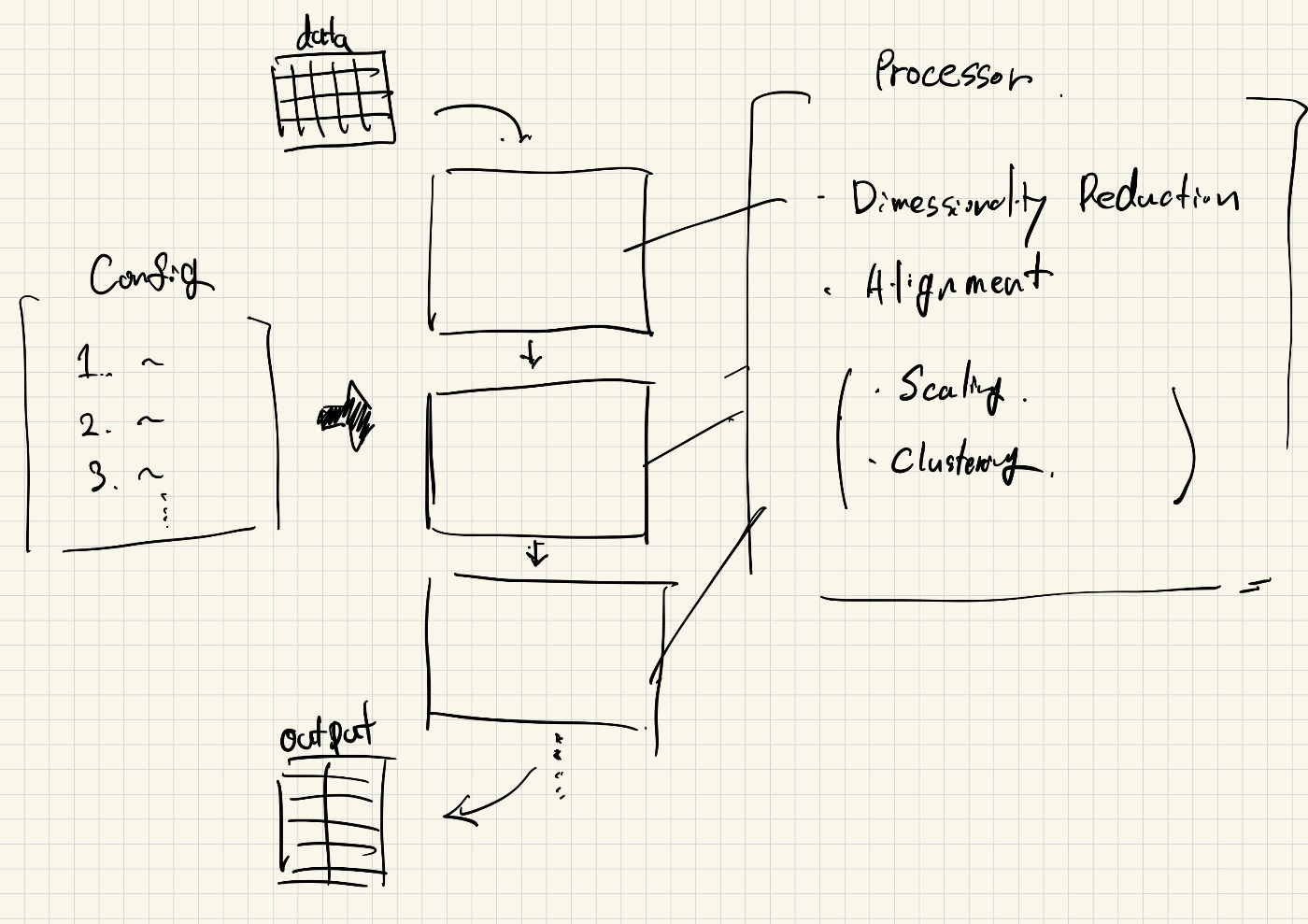
一つ目のデータ処理手法の変更に対しては、設定をもとに手法を切り替えるようなクラスを作成することにしました。
DimensionalityReuctionType = Literal["pca", "tsne", "custom-pca"]
class DimensionalityReductionManager(Processor):
def __init__(self, method: DimensionalityReductionType = "pca", n_components:int = 2):
self.method: DimensionalityReductionType = method
self.n_components = n_components
self.reducer = self.get_reducer(method)
def get_reducer(self, method: DimensionalityReductionType) -> DimensionalityReducer:
if method == "pca":
return PCADimensionalityReducer(self.n_components)
elif method == "tsne":
return TSNEDimensionalReducer(self.n_components)
else:
print(f"invalid method: {method}, use pca instead")
raise ValueError(f"invalid method: {method}")
def process(self, X: np.ndarray) -> np.ndarray:
if self.reducer is None:
raise ValueError("reducer is not set")
return self.reducer.reduce(X)
class AignmentManager(Processor):
class ClusteringManager(Processor):
二つ目の動的なデータ処理パイプラインの構築に関しては、各データ処理をProcessorとして同列に扱い、それをつなげることができるような形を取りました。設定に関するオブジェクトを読み込むことでデータ処理タイプの選択と必要なデータからデータ処理のインスタンスが作成され、パイプラインに追加されていきます。
設定
config = [
DimensionalityReductionConfig(type="dimensionality_reduction", method="pca"),
AlignmentConfig(type="alignment", method="procrustes")
]
パイプライン構築
class Processor(ABC):
def __init__(self):
pass
@abstractmethod
def process(self):
pass
class ProcessPipeline:
pipeline: List[Processor] = []
def __init__(self, config: PipelineConfig, prev_layout: PositionData):
self.generate(config, prev_layout)
def generate(self, config: PipelineConfig, prev_layout: Optional[PositionData]):
self.pipeline = []
for process_config in config:
process_type = process_config.type
if process_type == "dimensionality_reduction":
method = process_config.method
n_components = 2 # hardcoded
self.pipeline.append(DimensionalityReductionManager(method, n_components))
elif process_type == "alignment":
method = process_config.method
self.pipeline.append(AlignManager(prev_layout, method))
else:
raise ValueError(f"Invalid process type: {process_type}")
def update(self, config: PipelineConfig):
self.pipeline = []
prev_layout = None
self.generate(config, prev_layout)
def execute(self, X: np.ndarray) -> np.ndarray:
for processor in self.pipeline:
X = processor.process(X)
return X
これによって、パイプライン構築を動的に行いつつ、その構成に柔軟性をもたせることができそうです。例えば、間に新しくデータのクレンジングの処理を加えたり複数のアライメントを行ったりといった拡張ができます。
課題
次元削減とアライメントでは入力が違うので引数の受け渡しが複雑になっています。
ユーザーによる設定
可視化システムを使う中で、ユーザーがいろんな手法や処理のon/off、ハイパーパラメータなどを切り替えたくなることがあります。そのためConfigとそれを管理するようなモジュールを切り出しました。

class Config(BaseConfig):
data: str
dimensionality_reduction_config: DimensionalityReductionConfig
alignment_config: AlignmentConfig
def __init__(self, data: str, dimensionality_reduction_config: DimensionalityReductionConfig, alignment_config: AlignmentConfig):
self.data = data
self.dimensionality_reduction_config = dimensionality_reduction_config
self.alignment_config = alignment_config
class ConfigManager(BaseConfigManager):
config: Config
def __init__(self, config: Config):
self.config = config
def get_config(self) -> Config:
return self.config
def set_config(self, config: Config) -> None:
self.config = config
現在の設定は主にデータ処理の方法に関するものですが、他にもデータ自体だったり色々増やすことがあると思います。
複数ユーザーのアクセスと状態保持
クライアント・サーバー方式
今回のようなクライアントで可視化してサーバーでレイアウトに関する計算の処理をしたいといった場合には、複数のユーザーによるアクセスを考える必要があります。今回だと手法とインタラクションに関する状況などがユーザーによって異なるため、それを別々に扱う必要があります。
ユーザー固有の状況を読み込む -> データ処理のパイプラインの生成 -> 実行
という流れにするため、サーバー上にデータをキャッシュしアクセスすることを考えます。

ここデータアクセスに関しては抽象化することで扱いやすくなりそうです。以下は一つ前のレイアウトという状態を保存するものの例です。レイアウトのアライメントに一つ前のレイアウトを使用するため、保持しておく必要があります。
class Repository(Generic[T], ABC):
def __init__(self):
pass
@abstractmethod
def set_data(self, data: T, userId: str)-> None:
pass
@abstractmethod
def get_data(self, userId: str) -> T:
pass
class LayoutStateRepository(Repository[Tuple[PositionData, List[int]]]):
cache: Dict[str, Tuple[PositionData, List[int]]]
def __init__(self):
global cache
pass
def set_data(self, data: Tuple[PositionData, List[int]]: userId: str) -> None:
self.cache[userId] = data
def get_data(self, userId:str) -> Tuple[PositionData, List[int]]:
if self.cache.get(userId) is None:
raise ValueError("Cache is not set yet.")
return self.cache
layout_state_cache = {}
layout_state_repository = LayoutStateRepository()
# パイプライン構築時(apiリクエストにuserIdを含む
prev_layout = layout_state_respository.get_date(userId)
# データ処理後やレイアウト初期化時
layout_state_respository.set_data(output_layout)
現状使っているもの
- レイアウトの履歴
- ユーザー設定
- (データ)
状態のキャッシュ部分に関しては、ユーザーがアクセスしている間保持していてほしいものはDictなどですんでいます。永続化したい場合はここをRedisなど他の方法に変えるといいかもです。大規模データセットを扱う際にはメモリ上にデータをすべて乗せることが難しいため、DBなどに保存しリクエストに応じて渡すことが考えられます。
時間計測
インタラクションを含むデータ分析の可視化システムではレスポンス速度が重要な要素になっています。100ms程度が理想的な時間です。システムのモックをつくる際にもその処理時間を把握しやすい形が望ましいです。
既存のコードへの影響を少なくしつつ各処理時間を把握するモジュールがほしい!
def calc_time(func):
@wraps(func)
def wrapper(*args, **kwargs):
start = time.time()
result = func(*args, **kwargs)
end = time.time()
print(f"Time taken by {func.__name__}: {end - start} seconds")
return result
return wrapper
データ処理を行う抽象クラスに記述することで、個別のデータ処理プロセスに書かずとも計測ができそうです。
# PipelineのProcessの中でつなぎ合わせるもの
class Processor(ABC):
_instance = None
def __init__(self):
pass
@abstractmethod
def process(self):
pass
def __new__(cls, *args, **kwargs):
if cls._instance is None:
cls._instance = super().__new__(cls)
cls.process = calc_time(cls.process)
return cls._instance
""" example
1. dimensionality reduction
2. alignment
のデータ処理を実行するとき
Time taken by process: 0.00800180435180664 seconds
Time taken by process: 0.0009996891021728516 seconds
"""
評価と反省とか
コードについての評価する指標がほしいと思いいろいろ試してみます。
flake8
pythonのコードチェッカーツールです。
flake8 --count
line too longとかあまり意識してないところとかもありました。主にコードEのPEP8違反などが多いみたい。blackを導入して自動的にフォーマットを整えてみるとflake8の指標は277 -> 86に減りました。
17 files reformatted, 1 file left unchanged.
pylint
同じくコードのスタイルなどをチェックする静的解析ツール
Your code has been rated at 4.48/10 (previous run: 4.48/10, +0.00)
- wrong-import-position: importの順序
- missing-function-docstring:
重要そうなのは
- redefined-outer-name
- too-many-arguments
- too-few-public-methods
- arguments-differ
次に考えたい要件
他にも可視化システムを作るうえで機能として追加する頻度の高いものがあります。
- 可視化システムのユーザーテスト
- 手法の定量的評価: 今回だとレイアウト変化度の計算とか
- 実行時間の計測: 各データ処理にどれくらいの時間がかかっているのか
Discussion