💫
【RAG】What is Reranking Model?
RAGの概要
RAG (Retrieval Augmented Generations) は、RetrieverとGeneratorの二つの段階に分けられる。
- Retriever: 与えられたクエリに関連した文書をデータベースから取ってくる
- Generator: 取得された文書をもとにクエリに対しての回答文を生成する

Retrieverの知識がなければ、うまく回答を生成することができない。
今回はこのRetrieverに着目する。
埋め込みモデルとリランキングモデル
Retrieverは、主にEmbedding Model(埋め込みモデル)とReranking Model(リランキングモデル)の二つがある。
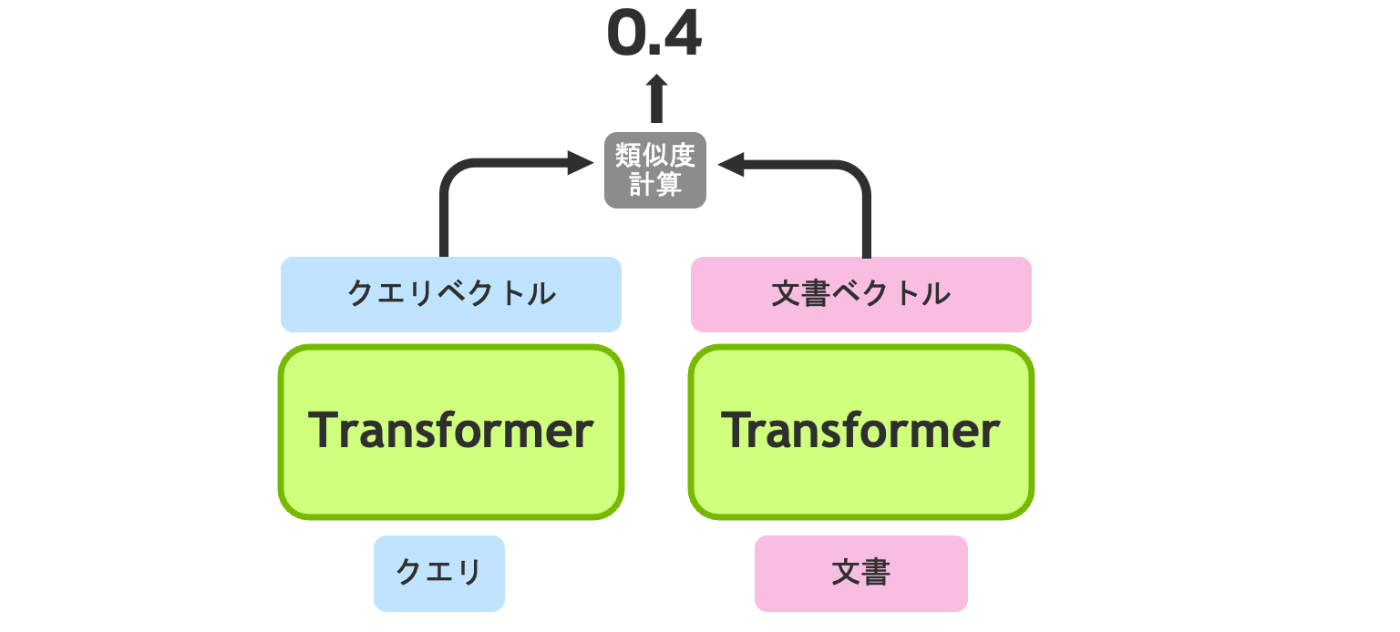
Embedding Model
- クエリを入力としてそのベクトルを出力する部分と、文書を入力としてそのベクトルを出力する部分で分かれる
- 最終的に、この二つのベクトルの類似度を計算し、クエリと文書がどのくらい関連しているかを決定する
- RAGでは、Embedding Modelとしてこの流れ(Bi-Encoderと呼ぶ)を用いる
Reranking Model
- クエリと文書を別々に入力するのではなく、結合した上で直接、類似度を出力する
- RAGでは、Reranking Modelとしてこの流れ(Cross-Encoderと呼ぶ)を用いる
- クエリと文書の関係を、ベクトル情報だけでなく、Transformerに含まれるAttentionなどの全層から獲得するため、Bi-Encoderよりも一般的に高精度なことが多い

RAG においては、Embedding ModelとReranking Modelを併用することが多い。
これにより、検索速度と検索精度のバランスが取れたRetrieverを実現できる。
なぜ高精度のReranking Modelのみにしないのか?
理由はシンプルに時間がかかりすぎるからだ。以下の三つの場合を見てみよう。
Embedding Modelのみの場合
文書をあらかじめベクトル化しておく。
そうすることで、あとはクエリをベクトル化し、クエリと文書のベクトルの類似度を比較するだけ。時間のかかるベクトル化の処理は、一回のみで済む。
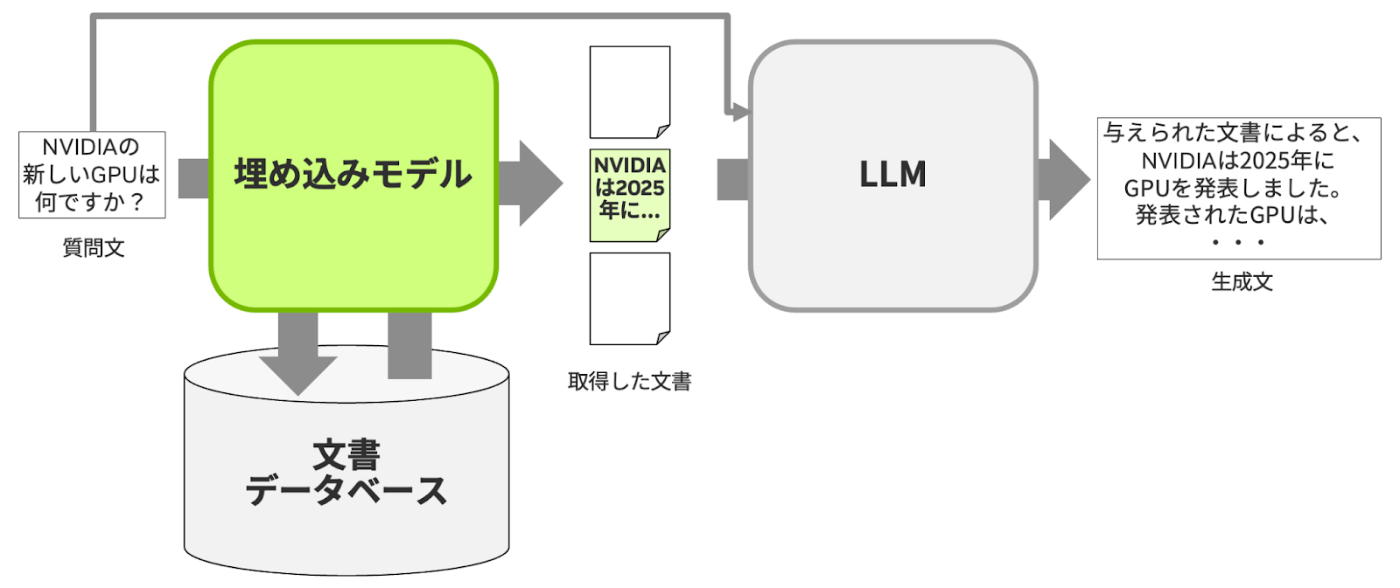
- メリット:高速に全ての文書を取得可能
- デメリット:Reranking Modelと比較し、精度が低い
Reranking Modelのみの場合
クエリ+文書で入力するため、毎回ベクトル化する必要がある。
つまり、文書が100個なら100回、100万個なら100万回ベクトル化する必要がある。データベースが大きいほど、時間がかかってしょうがない。

- メリット:精度が高い
- デメリット:文書が多いほど、処理時間が膨大になる
Embedding Model + Reranking Modelの場合
Embedding ModelでTop N 個に厳選した上で、精度の高いReranking Modelに投げる方法。
これなら、時間がかかりすぎる問題を解消でき、精度の高いReranking Modelに最終的に任せることができる。

まとめ
- RAGには、Retriever (検索) とGenerator (生成) の二つの段階がある
- Retrieverにおいて、高速なEmbedding Modelと高精度なReranking Modelをうまく組み合わせることで、高速かつ高精度な検索が実現できる
参考
Discussion