面白そうな論文紹介【CVPR2025】
2025年2月27日の公式Xの投稿にある通り、CVPR2025の採択結果が著者に通知されました。
今年は1.3万件の提出があり、そのうち22.1%の2878本の論文が採択されました (公式Xを参照)。
会議を待たずに論文やコードを公開してくれている著者もたくさんいます。
個人的に面白いと感じた論文をテンポよく紹介していきます。
論文紹介
1. AuraFusion360: Augmented Unseen Region Alignment for Reference-based 360° Unbounded Scene Inpainting
[arXiv] [Project Page]
360度の境界のないシーンにおけるオブジェクトの除去と補完ができるインペインティング手法.
複数のカメラ視点のRGB画像と物体のマスクを入力とし,物体を除去した未知の視点も含めた360°でのシーン修復が可能.

2. Omni-RGPT: Unifying Image and Video Region-level Understanding via Token Marks
[arXiv] [Project Page]
画像とビデオの入力全体にわたって領域レベルの理解を可能にするマルチモーダルLLM.
ユーザーが指定した領域と,対応するテキストプロンプト(質問文)を与えると,画像とビデオの両方で視覚的な背景を考慮してテキストで応答を生成してくれる.

3. CTRL-D: Controllable Dynamic 3D Scene Editing with Personalized 2D Diffusion
[arXiv] [Project Page]
従来手法であるNeural Radiance Fields や 3D Gaussian Splatting によって自由な視点での合成が大幅に改善された一方,動的な3Dシーンでの編集は一貫性や制御性の制限が生じている。
そこで、動的な3Dシーンで一貫性のある編集を実現。

4. AIpparel: A Large Multimodal Foundational Model for Digital Garments
[arXiv] [Project Page]
衣服の作成プロセスを簡素化するために、縫製パターンの生成と編集のための大規模なマルチモーダルモデルであるAppparelを導入。
画像からの縫製パターンの再構築、テキストからの縫製パターン生成、テキストの指示による縫製パターン編集が可能。


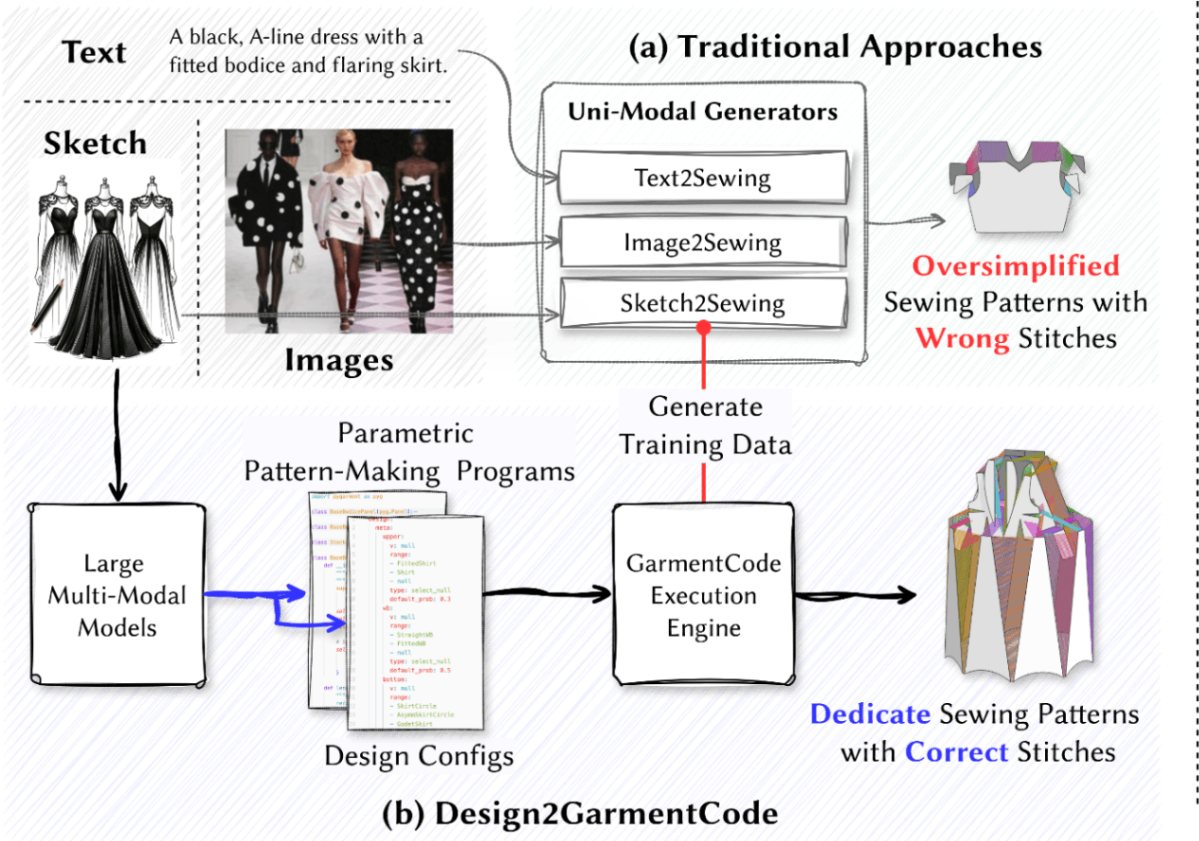
5. Design2GarmentCode: Turning Design Concepts to Tangible Garments Through Program Synthes
[arXiv] [Project Page]
既存の単一モーダルによる縫製パターン生成モデルは、マルチモーダルな性質を持つデザインのコンセプトや複雑さと、幾何学的な構造を持つ縫製パターンと創刊させることが難しい。
そこで、マルチモーダル(テキスト、スケッチ、画像)を入力として縫製パターンを生成する手法であるDesign2GarmentCodeを提案。
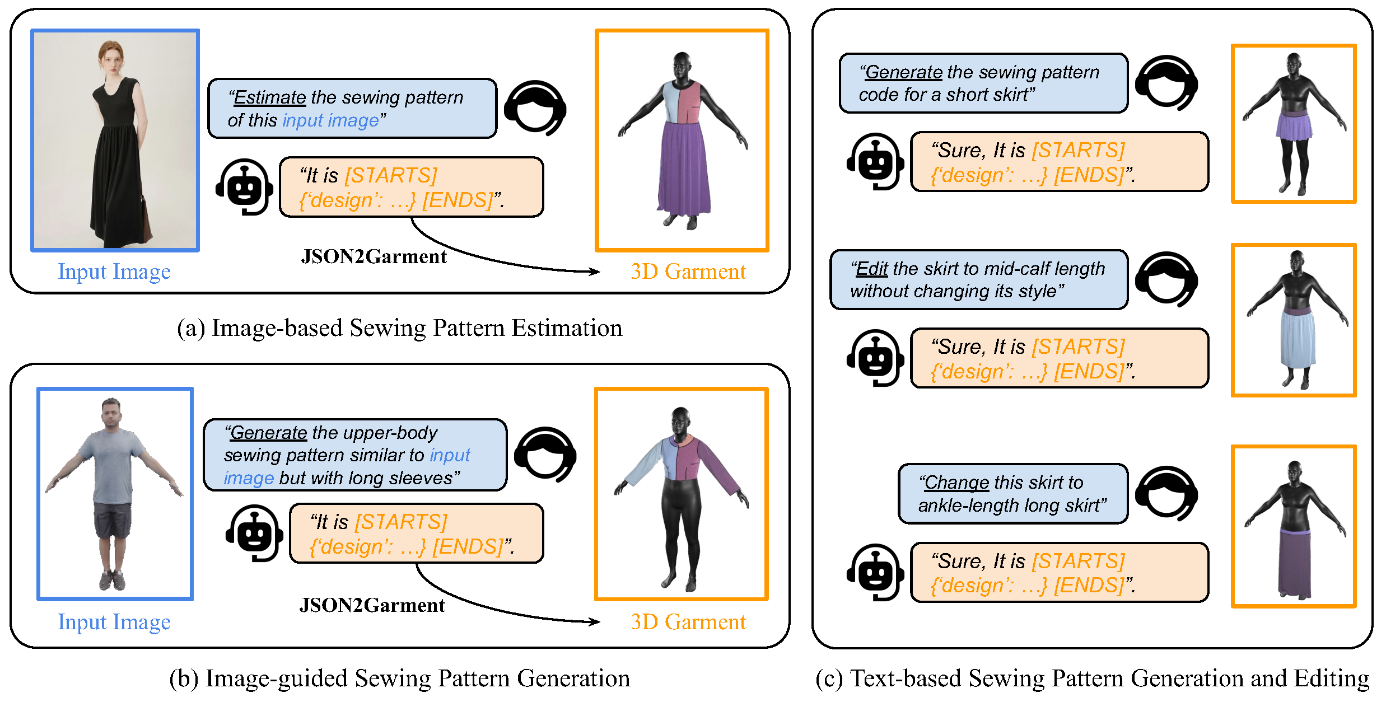
6. ChatGarment: Garment Estimation, Generation and Editing via Large Language Models
[arXiv] [Code] [Project Page]
従来手法では、インタラクティブな(相互作用がある、往復のやり取りがあるような)編集機能に欠けている。
提案手法であるChatGarmentは、インタラクティブな対話を通して、実際の画像やスケッチから縫製パターンを推定し、テキストの説明から生成し、ユーザーの指示に基づいて衣服を編集できる。
7. Feat2GS: Probing Visual Foundation Models with Gaussian Splatting
[arXiv] [Code] [Demo] [Project Page]
視覚的な基盤モデルは3Dをどのくらい認識しているのか?という疑問から始まった研究。しかし現在のモデルでは3Dの正解値が必要という制約がある。
そこで、正解値を必要としないNovel View Synthesisを用いてこの問題を解決できないかと考え、視覚基盤モデルの「テクスチャとジオメトリの認識」を調査するためのフレームワークであるFeat2GSを提案。

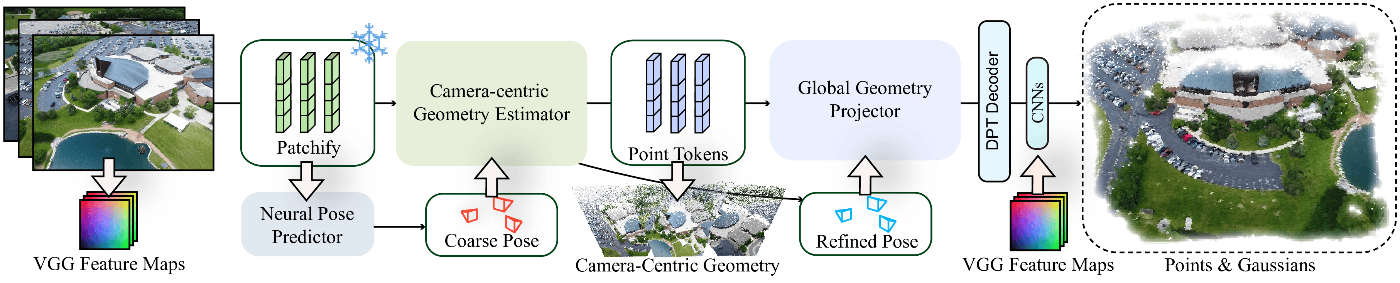
8. FLARE: Feed-forward Geometry, Appearance and Camera Estimation from Uncalibrated Sparse Views
[arXiv] [Code] [Project Page]
キャリブレーションされていない2-8枚程度の少ない画像から、カメラポーズと3Dジオメトリを推定するFLAREを提案。
9. EgoLife: Towards Egocentric Life Assistant
[Code] [Paper] [Project Page]
AI搭載のウェアラブルグラスを通じて、一人称視点での生活アシストを開発するプロジェクト。構築されたEgoLifeデータセットには、ディスカッション、ショッピング、料理、社交、エンタメなどの日常活動が継続的に記録されている。
広範囲な時間情報に対する長いコンテキストの質問応答をアシストするという技術的課題に対処するためEgoBulterを提案。
EgoBulterは、一人称視点の視覚言語モデルのEgoGPTと、かなり長いコンテキストの質問への回答をサポートする検索ベースのEgoRAGで構成される。

10. Dataset Distillation with Neural Characteristic Function: A Minmax Perspective
実データと合成データの両方について、複素平面における神経特徴の位相と振幅情報を整合させ、現実感と多様性のバランスを実現するニューラル特性関数マッチング (NCFM) を導入。
(正直いうと、この論文は難しくてよく分かっていません。解説してくださる方いたらぜひ)

11. Generative Photography: Scene-Consistent Camera Control for Realistic Text-to-Image Synthesis
[arXiv] [Code] [Project Page]
画像生成で、テキストプロンプトからリアルな画像を生成できる一方、24mmレンズと70mmレンズを使用し異なる視野を作成するなど、特定のカメラ設定を要求しても、一貫性のある生成は難しい。
そこで、コンテンツ生成中にカメラの固定設定を制御するように設計されたフレームワークであるGenerative Photographyを提案。

12. Conditional Balance: Improving Multi-Conditioning Trade-Offs in Image Generation
[arXiv] [Project Page]
画像生成において、画像のスタイルとコンテンツの両方を保持するのは難しい。この二つのトレードオフを分析することで、条件付き入力に対するモデルの生成プロセスの感度を調査する方法を提案。
画像生成のスタイルとコンテンツの保持問題はかなり前から注目されていたトピックなので、CVPR2025でもそれに関連した内容が出てきていて面白いです。
Discussion