BigQueryでRAGを構築してみた



マルチテナントでRAGを構築する方法があまり見つからなかったのでBigQueryで実現してみました
構築当初はBigQueryが何なのかよくわからず、難しそうで敬遠していたのですが、使ってみると意外と簡単だったのでその紹介です
やりたいこと
テナント別で高精度なRAGを構築したい
DBは分けるとメンテコストが掛かってしまうのでなるべくコストが掛からないような実装をする
最初はVertex AIのAgent Builderを使おうかと思っていたのですが、条件別での検索を実装するのが難しいと判断したのでBigQueryを使用しています
今回とは関係がないですが、マルチテナントでどのようにRAGを構築していいかわからなかったのでBigQueryを調べていました
実用に足るかはわからないですが、ヒントになった気がしています
(マルチテナントでRAGを構築するいいやり方を知っている方はコメントで教えて下さるととても助かります)
今回はBigQueryでセマンティック検索をするところを中心に取り上げます
RAGとは
Retrieval-Augmented Generation (RAG) は、関連するドキュメントを検索して活用することでLLMの回答精度を向上させる方法のことです
今回でいうと、reviewを検索してそれをLLMに提供することで精度を上げようという方法です
BigQueryとは
膨大なデータを格納できるデータの蓄積場所です
主にデータ分析で使われることが多いですね
RDBと比べてtransactionや制約などがないことが主な違いかと思います
BigQueryの料金について
オンデマンド課金が前提かつ条件によって異なるので正確な料金は以下の公式ページ参照
ざっくりの料金ですが、locationはusで(安いので)
クエリー料金: 1TiBあたり6.25$(最初の1TiBは無料)
ストレージ料金: 1GiBあたり$0.02(最初の10GiBは無料)
現在お試しで使っていますが、無料枠内で収まっているのでかなり安い印象です
データ量が増えてくるとパーティショニングだったりクラスタリングを使用してコストを意識しないといけなくなってくるので運用が安定したら考える必要がありそうですね
embeddingだったり、LLMのモデルの使用料金はそれぞれ別でかかるので注意が必要です
VertexAIのembedding modelやllmのmodelはVertexAIの料金を参照
準備
bigqueryでRAGを構築するために以下のものを構築します
- 外部接続
- エンベディングモデル
- データセット
- テーブル
外部接続
bigqueryでtext embeddingするためにVertex AIのモデルを使用します
BigQueryではVertex AIのモデルを使うためにconnectionを作成して、そのconnection経由でモデルを利用します
connectionは以下のコマンドで作成します
接続はGCPのリソース(Vertex AI)を使用するのでCLOUD_RESOURCEです
$ bq mk --connection \
--location='us' \
--project_id='YOUR_PROJECT_ID' \
--connection_type=CLOUD_RESOURCE \
test_bigquery_conn `
上記のコマンドを実行すると権限が足りないと言われるのでGoogle提供のサービスアカウントにVertex AIユーザーのロールを割り当てます

エンベディングモデル
embedding modelとは、文字をベクトルデータに変換するためのものです
ベクトルデータに変換することで、文字の意味的に類似しているかの判別がつくようになり、文字を意味から検索することができるようになります
例えば、検索キーワードとして果物を入力して検索するとりんごがヒットします
これは果物のベクトルとりんごのベクトルに付いて距離を算出して、距離が近いので意味的にも近いはずだという仕組みになっています
このように単語の意味で検索することをセマンティック検索といいます
セマンティック検索するためにembeddingを行うというわけですね
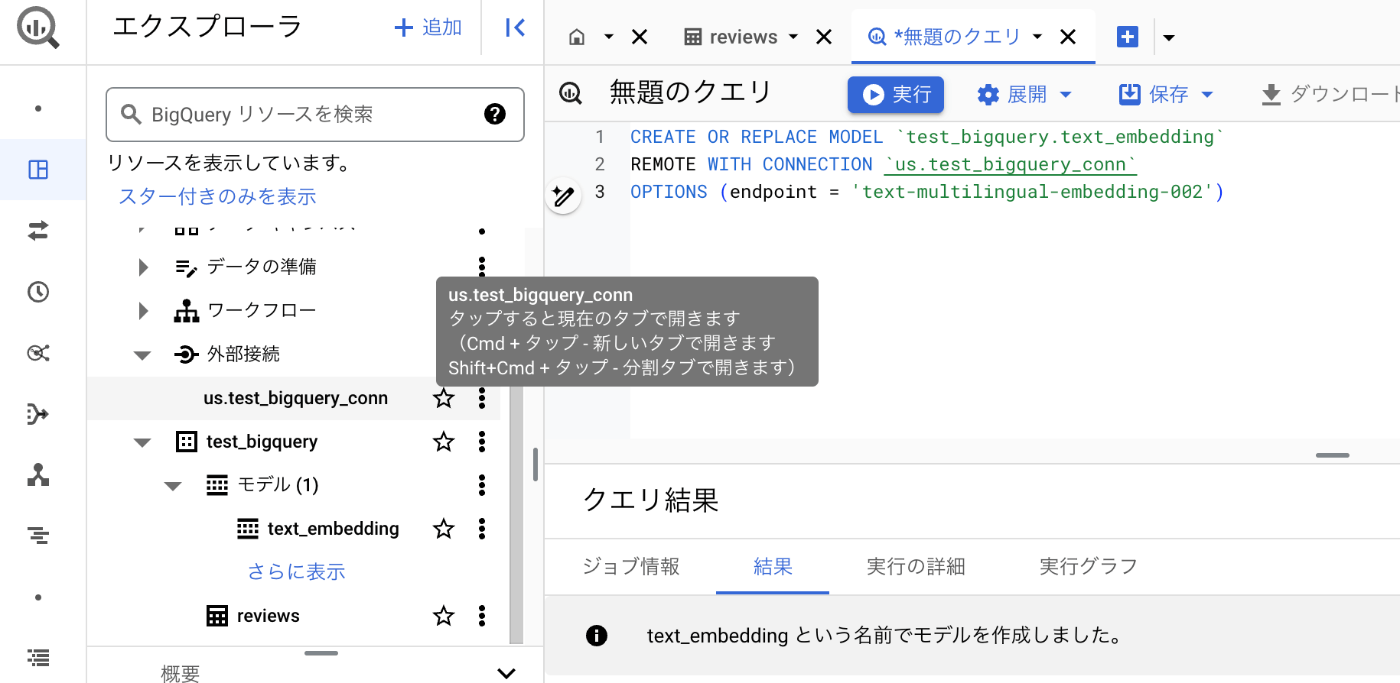
以下のSQLを実行してembeddingモデルを作成します
日本語をembeddingするので、モデルはmultilingualを使用します(英語だけであれば他のモデルでも良さそう)
CREATE OR REPLACE MODEL `test_bigquery.text_embedding`
REMOTE WITH CONNECTION `us.test_bigquery_conn`
OPTIONS (endpoint = 'text-multilingual-embedding-002')
データセット
データセットはテーブルなどを整理するための入れ物です
以下のコマンドを実行してデータセットを作成する
$ bq mk --dataset test_bigquery

テーブル
実際にデータを格納するテーブルを作成及びロードします
作成と読み込みは別々で行えますが、今回は面倒なのでまとめて実行しました
別々で実行する場合はschema定義などできます
source_formatは今回はCSVを選択しています
CSVの1行目はヘッダーになっていて、skipする必要があるのでskip_leading_rowsは1
カラムの自動判別機能を使うのでautodetectを有効にしています
$ bq load --source_format=CSV --skip_leading_rows 1 --autodetect \
test_bigquery.reviews \
gs://{YOUR_GS_BUCKET}/{PATH}/reviews.csv
テーブルのschemaは以下
| field_name | mode | type |
|---|---|---|
| review | REQUIRED | STRING |
| source | REQUIRED | STRING |
RAG構築
テーブルのembedding
準備ができたのでRAGを構築していきます
まずは検索対象のテーブルをembeddingしてtext_embeddedテーブルを作成します
以下のSQLを実行します
CREATE OR REPLACE TABLE `YOUR_PROJECT_ID.test_bigquery.embedded_data` AS (
SELECT * FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `YOUR_PROJECT_ID.test_bigquery.text_embedding`,
(
SELECT
review AS content,
source,
FROM `YOUR_PROJECT_ID.test_bigquery.reviews`),
STRUCT(TRUE AS flatten_json_output)
)
);
embedded_dataというテーブルを作成します
ML.GENERATE_TEXT_EMBEDDINGという関数を使って作成します
第一引数には作成したtext_embeddingというモデルを指定します
第二引数にはreviewsのreviewとsourceを取ってきてテーブルを作成するというquery_statementを渡します
ベクトル化するカラムはcontentという名前にする必要があるので review AS contentとしています
実行すると数百次元のベクトルデータが作成されます(具体的な次元数は忘れました)
これで検索する準備はできました
あとは検索するだけです
検索
以下のSQLを実行することで検索できます
RAGと記載していますが、今回はLLMに回答を作成させていないのでセマンティック検索になります
この検索結果をLLMに提供することでLLMの生成する回答の精度が上がることが期待できます
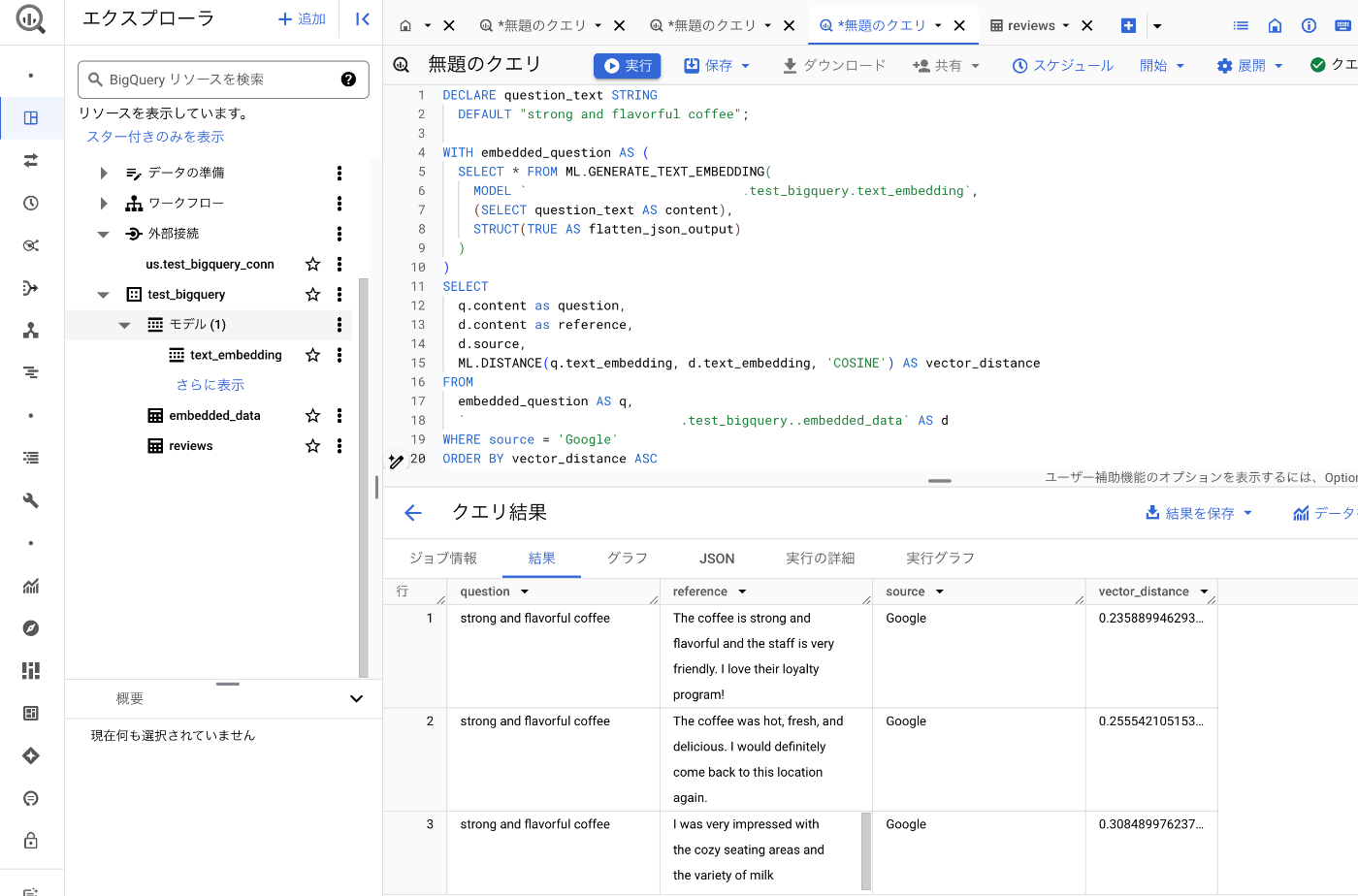
DECLARE question_text STRING
DEFAULT "most delicious coffee";
WITH embedded_question AS (
SELECT * FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `YOUR_PROJECT_ID.test_bigquery.text_embedding`,
(SELECT question_text AS content),
STRUCT(TRUE AS flatten_json_output)
)
)
SELECT
q.content as question,
d.content as reference,
d.source,
ML.DISTANCE(q.text_embedding, d.text_embedding, 'COSINE') AS vector_distance
FROM
embedded_question AS q,
`YOUR_PROJECT_ID.test_bigquery.embedded_data` AS d
WHERE source = 'Google'
LIMIT 10
ORDER BY vector_distance ASC
まずは質問文をembeddingするところからです
ML.GENERATE_TEXT_EMBEDDING関数を使ってembeddingし、embedded_questionに格納します
その後、ML.DISTANCE関数を使って質問文とreviewのテキストの意味的な近さをvector_distanceとして格納します
vector_distanceでソートすることで、意味的に近い順に並べ替えることができます
これで類似した文章を抽出することができます
質問文が"strong and flavorful coffee"なのに対して、質問文を含んだreviewのテキストが1番上に来るのはもちろん、"fresh and delicious"など意味的に似ている文章も抽出できています
今回は英語のデータを使いましたが、日本語のデータでも問題なく動作します
ちなみにクエリ実行前にDRY RUNすることで大まかなコストがわかります
コンソールであれば画面右上のこちらをマウスオーバーするとわかります
Discussion