modALで能動学習の気持ちを理解する
能動学習のイメージ
以下の4ステップで効率的にラベリングを実施します。特に、pool-based samplingを想定しています。
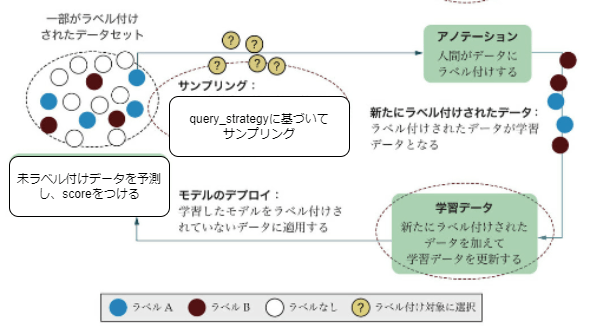 引用 「Human-in-the-Loop機械学習: 人間参加型AIのための能動学習とアノテーション」 p.33の画像を一部改変
引用 「Human-in-the-Loop機械学習: 人間参加型AIのための能動学習とアノテーション」 p.33の画像を一部改変
ラベリングがどの程度効率的になるかは、query_strategyにかかっています。
modAL
pythonでの能動学習のライブラリです。今回はこのライブラリのexampleを拡張していきました。
実験してみた
能動学習の気持ちを理解するために、上図のループが回っていく過程の可視化と、ランダムサンプリングとの比較を行いました。
実験設定
コードはこちらに格納しています。https://github.com/watanta/modAL_practice/tree/main/docs/source/content/examples
使用したデータはirisです。PCAで2次元に落としてプロットするとこんな感じです。
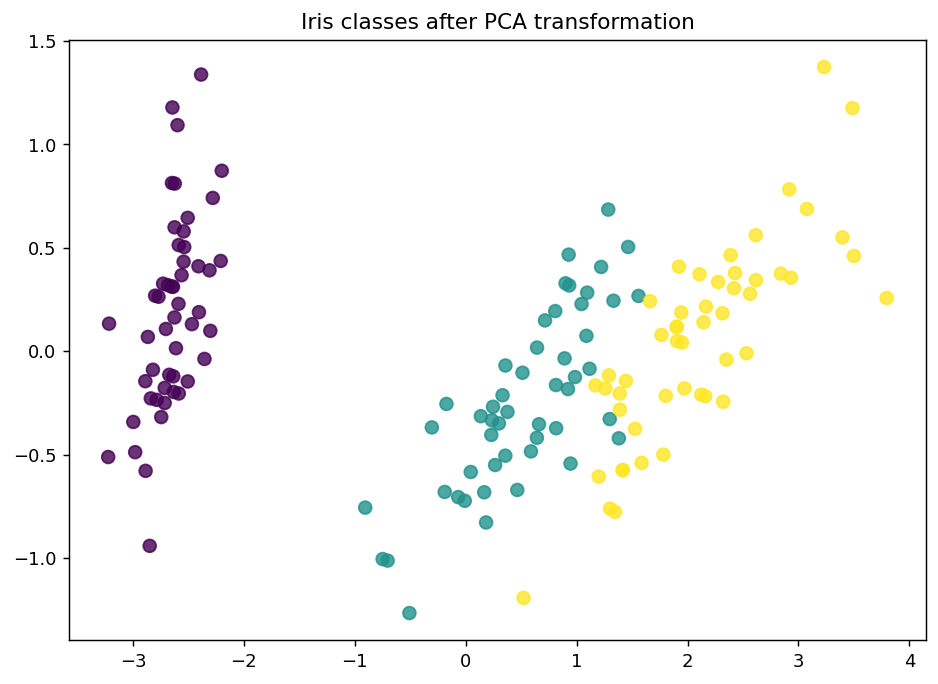
150サンプルが含まれているため、初期学習として3サンプルを使用し学習、その後1サンプルづつ能動学習のループを回してモデルの学習データに対する予測性能がどのように上がっていくかを調べました。
query_strategyとして不確実性サンプリングとランダムサンプリングでそれぞれ実験を行い、比較を行いました。以下のように、不確実性サンプリングのscoreは、1-(最も大きい予測確率)としています。つまり、「どのクラスかよくわからない」とモデルが予測しているサンプルが選ばれやすいということです。
def uncertainty_sampling_implementation(classifier: BaseEstimator, X_pool: np.ndarray, n_instances: int = 1):
"""
Selects the instances with the highest uncertainty from the pool.
Parameters:
- classifier: A trained classifier with a `predict_proba` method.
- X_pool: The pool of unlabeled instances.
- n_instances: The number of instances to query.
Returns:
- query_indices: The indices of the instances to query.
- query_instances: The instances to query.
"""
# Get the predicted probabilities for each instance in the pool
probas = classifier.predict_proba(X_pool)
# Calculate uncertainty as 1 minus the maximum probability for each instance
uncertainty = 1 - np.max(probas, axis=1)
# Get the indices of the instances with the highest uncertainty
query_indices = np.argsort(uncertainty)[-n_instances:]
# Get the instances to query
query_instances = X_pool[query_indices]
return query_indices, query_instances
モデル性能向上の過程
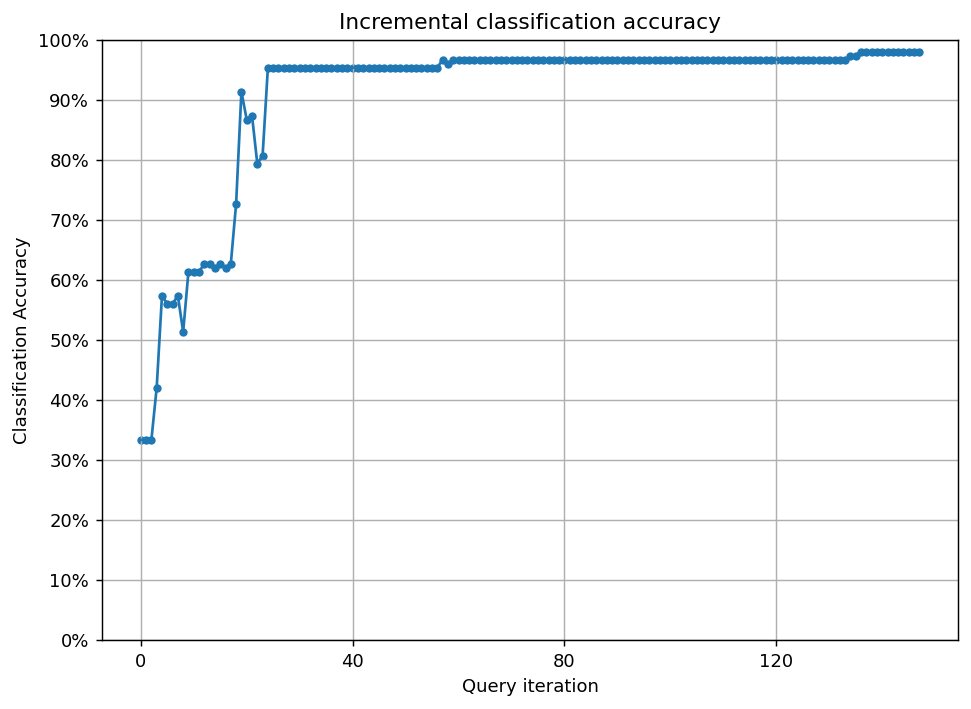
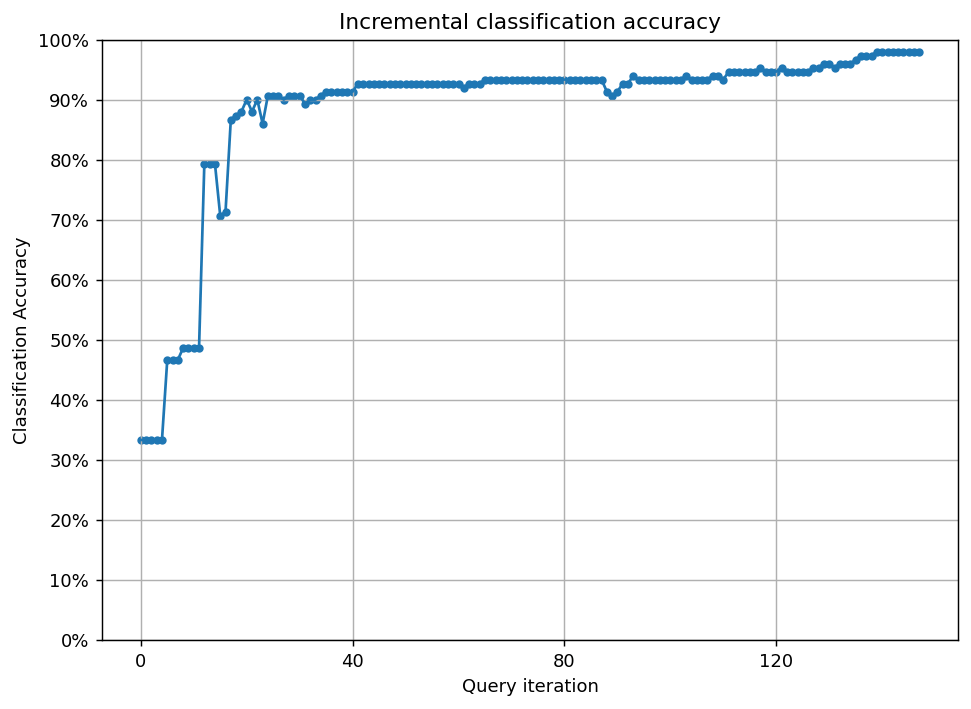
(恣意的な比較ですが)ランダムサンプリングでは95%の正解を達成するために127サンプルを要したことに対し、不確実性サンプリングでは24サンプルで達成できました。
不確実性サンプリング
ランダムサンプリング
サンプル対象決定の過程
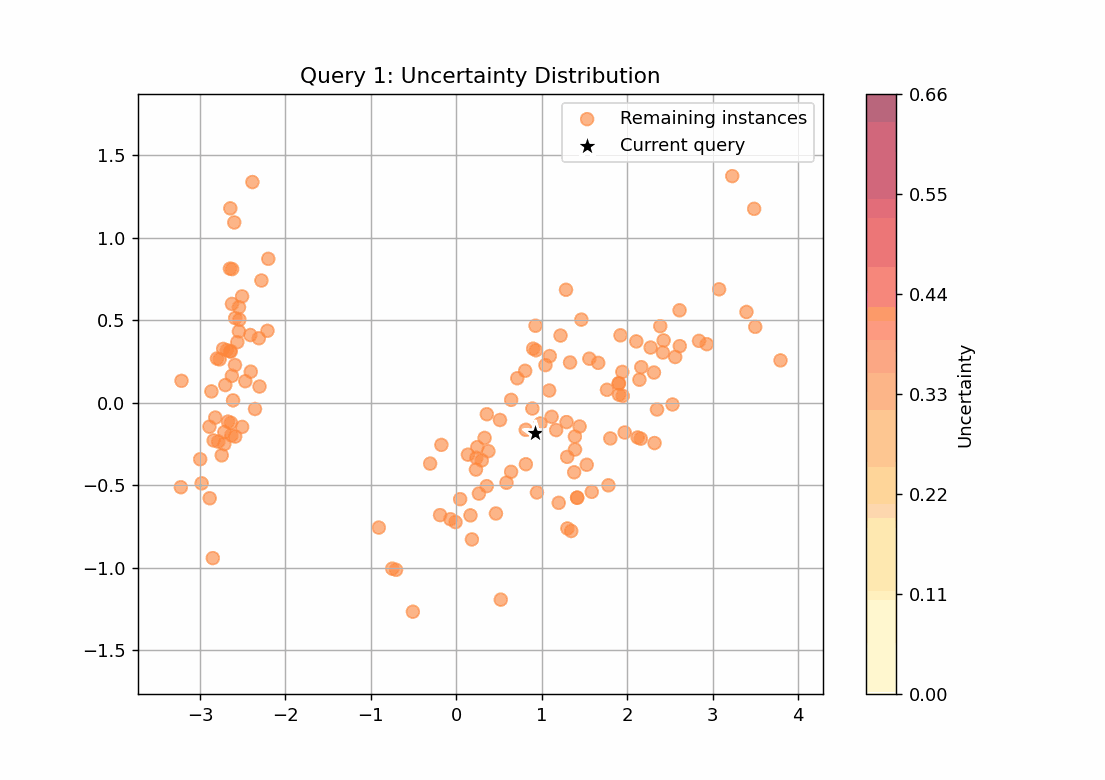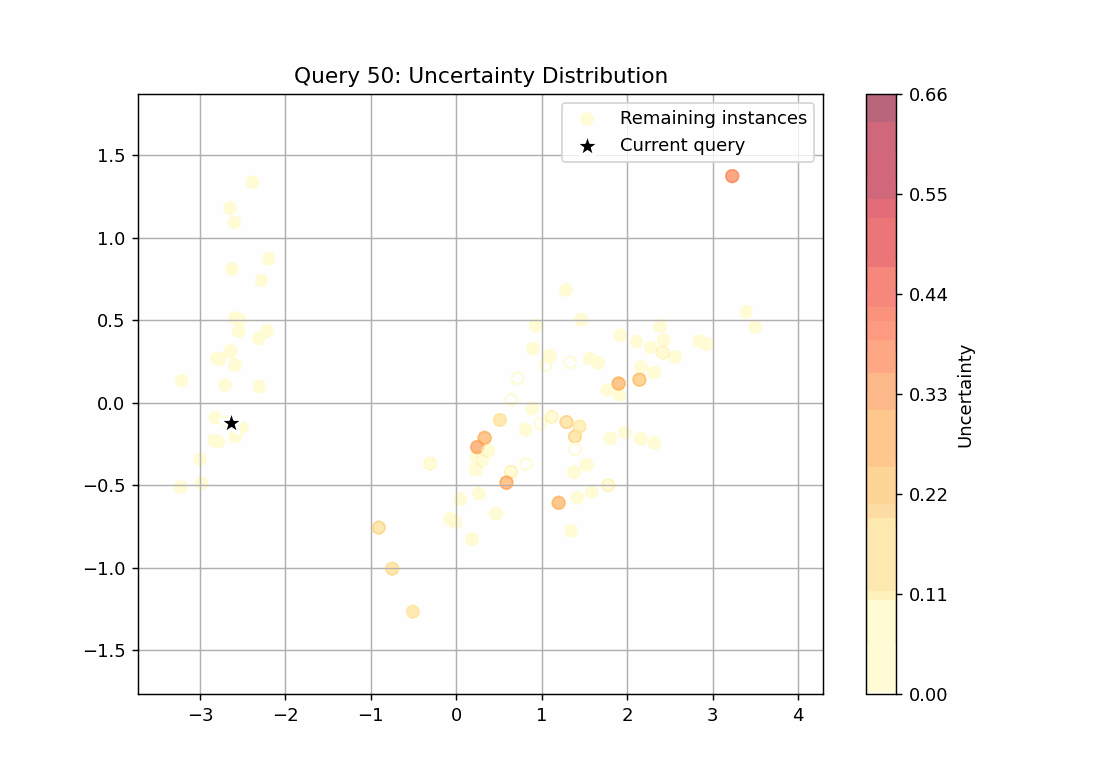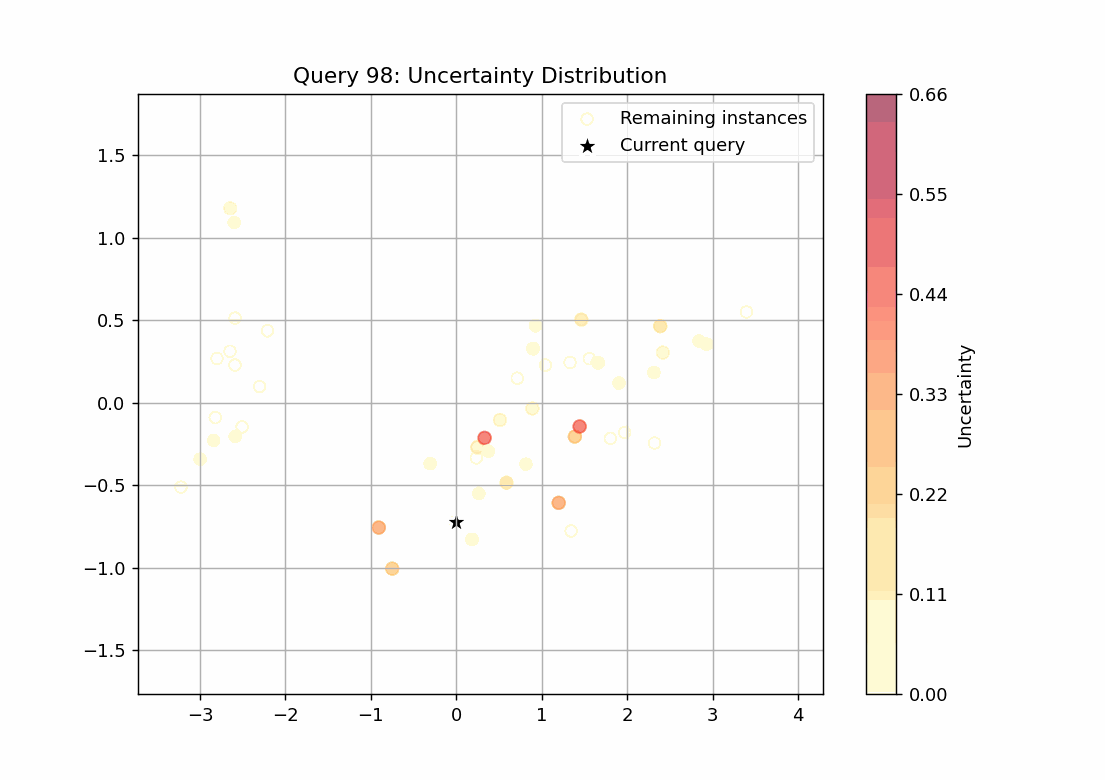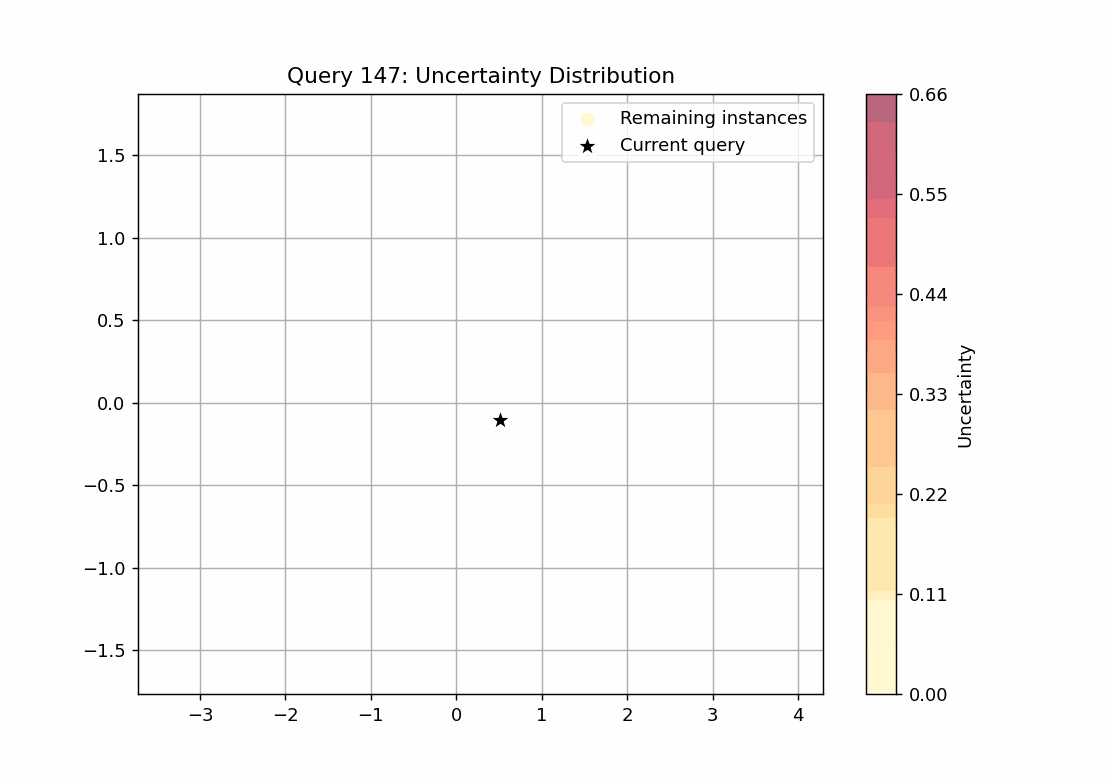
147回のループをgifで可視化しました。scoreを点の色の濃淡で表し、query_strategyで選ばれたサンプルを★で表しています。
不確実性サンプリング
scoreが最も高いサンプルを選ぶquery_strategyとなっていることが確認できます。27回目のqueryでscoreの高いサンプルがなくなっていることから、学習すべきデータはこの時点で学習できてしまっていることが推察できます。
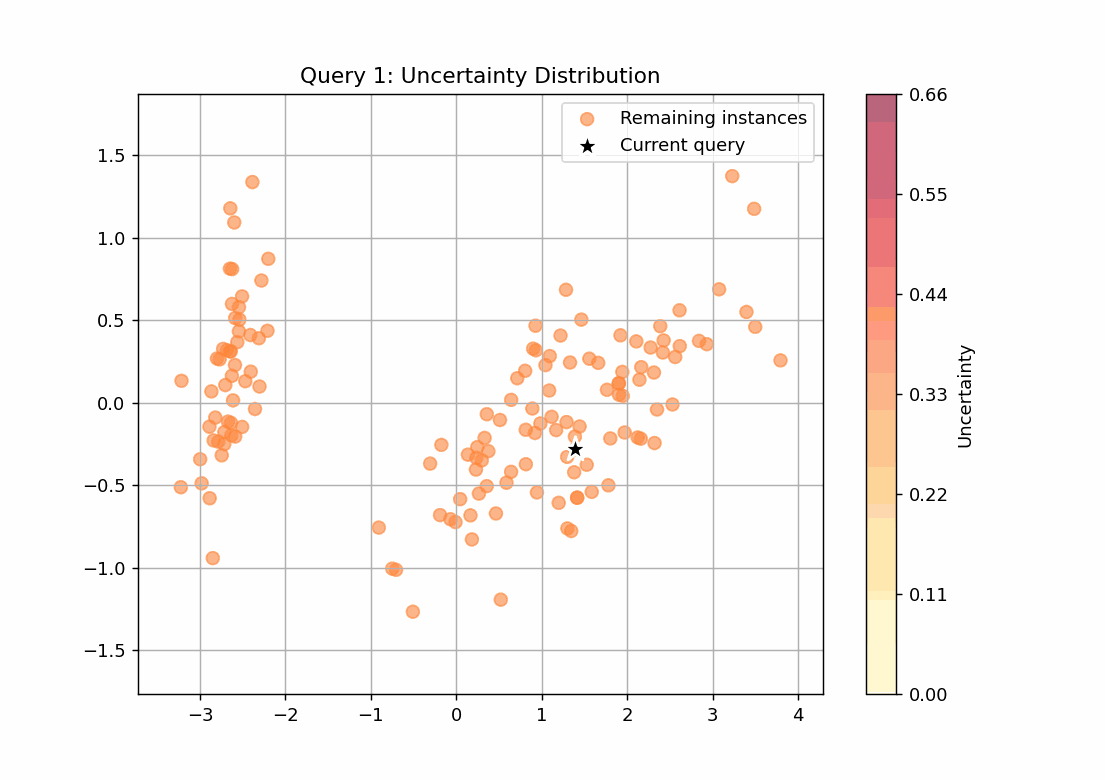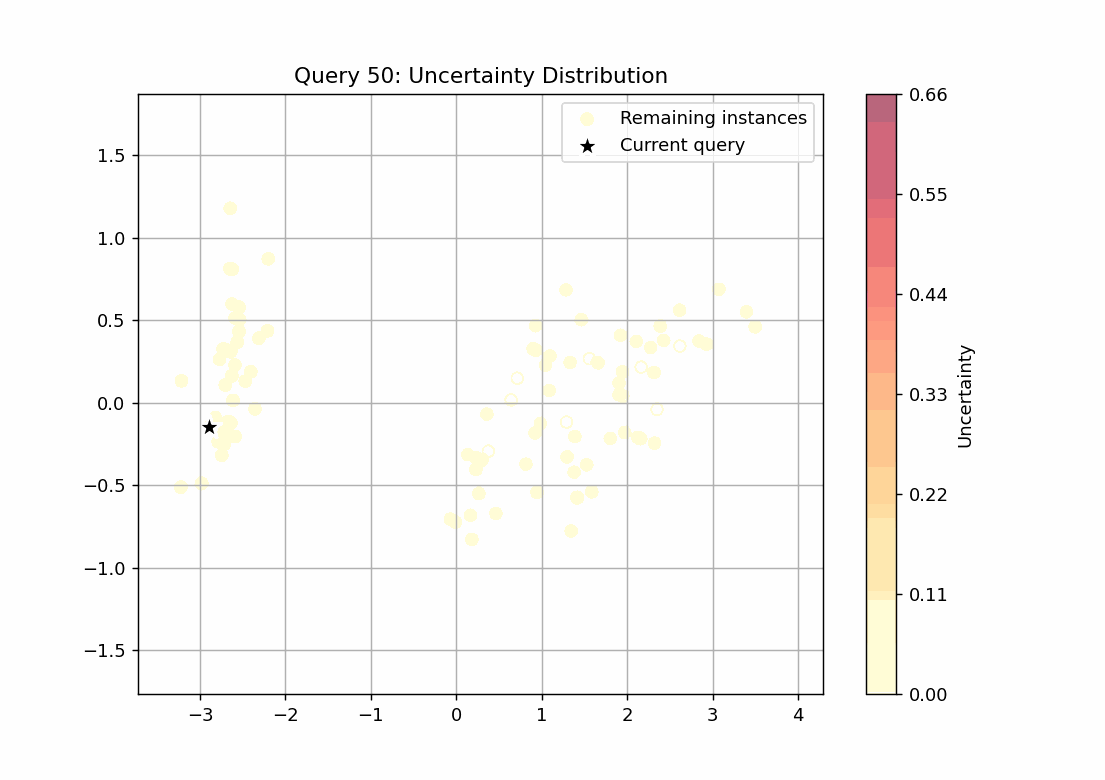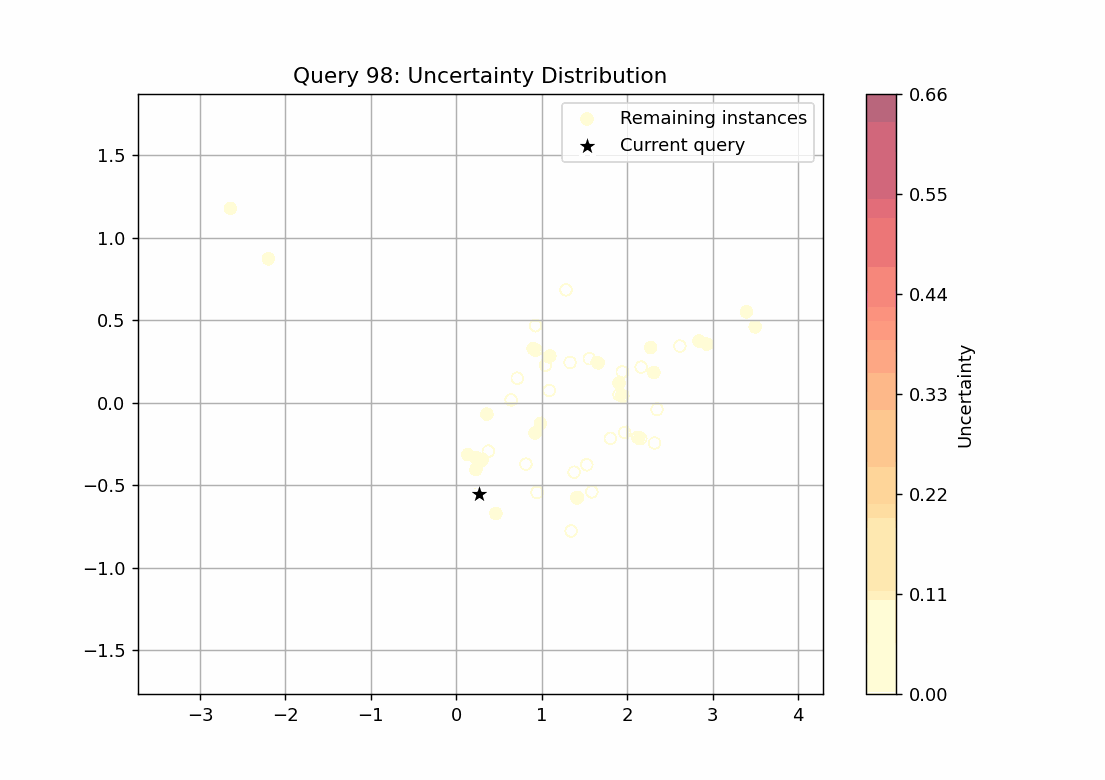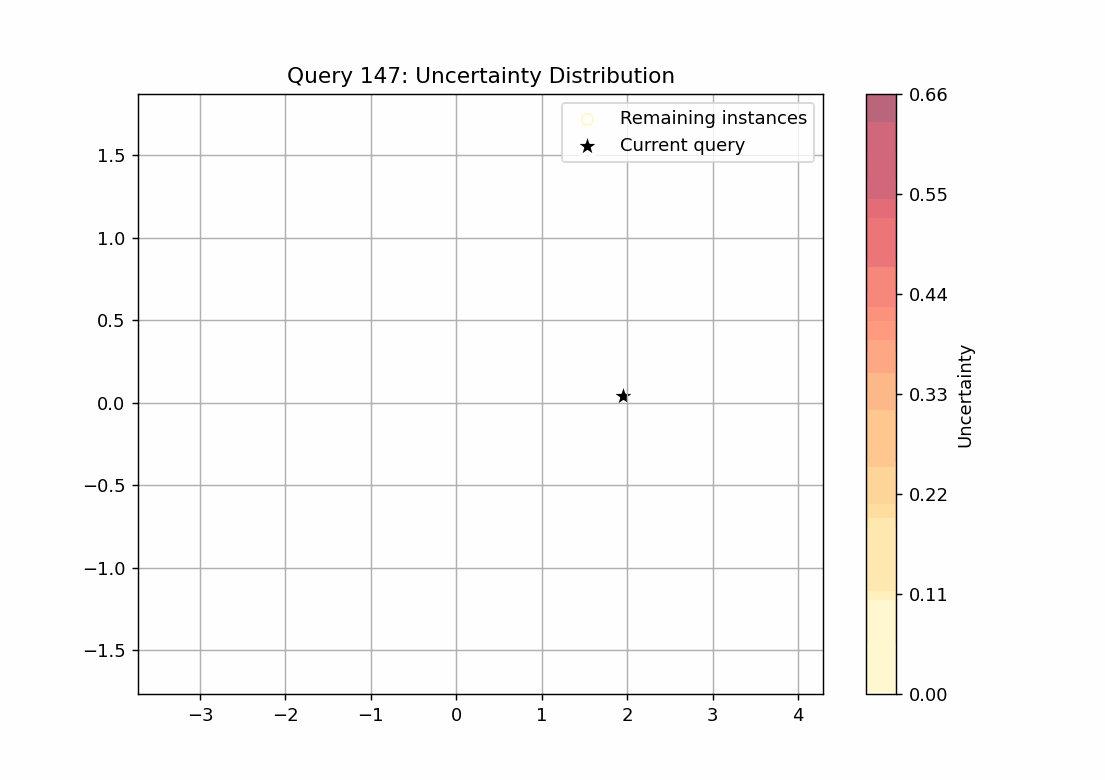
ランダムサンプリング
ランダムサンプリングのため、scoreの高さとは無関係のサンプルが選ばれていることがわかります。後半の方までscoreが高いサンプルが残り続けており、学習すべきデータにすぐにたどり着けていないことがわかります。
まとめ
不確実性サンプリングはランダムサンプリングと比べて、正解率を向上させるための効率的なラベリング付けができていそうであることを確認しました。他の問題設定(物体検知)であったり、他のquery_strategyだとどうなるか、どのようなデータならより効果が出そうかなど検証を続けていきたいです。
Discussion