実際に手を動かして学ぶアセンブリ入門
はじめに
最近、アセンブリ言語を学ぶ機会があったので、そのときに学んだことをここに書き留めていこうと思います。最初は「レジスタ?スタック?なにそれ…?」という状態でしたが、実際にコードを書いて動かしてみると意外と面白く感じました。普段、自分が書いたプログラムがどのように動作しているのか、その仕組みが以前よりもクリアに見えるようになり、理解が深まった気がします。
想定読者
- アセンブリ言語について知りたい人
- 低レイヤーを理解したいなどの好奇心を持っている人
- 実際に手を動かして、動くプログラムを作りながら学びたい人
この記事で得られること
- アセンブリ言語とは何かを理解できる
- 実際にアセンブリ言語を使って動かすことができる
アセンブリ言語について
アセンブリ言語(Assembly Language)は、コンピュータの命令セット(ISA)を人間が扱いやすい形にした、最も低レベルなプログラミング言語のひとつです。機械語の0と1の羅列をそのまま読むのは辛いですが、アセンブリではこれをmovやaddといったニーモニック(記憶しやすい略語)で表現します(こちらについては、後に説明します)。そのため、CPUが実際に実行する命令との対応が直感的で、C言語などの高水準言語に比べてハードウェアをより直接的に扱える点が特徴です。ただし、アセンブリ言語はそれぞれの命令セットに合わせて作られているため、異なるアーキテクチャ間での互換性はほとんどありません。実際にプログラムを実行する際は、アセンブラと呼ばれる専用のツールを使ってアセンブリ言語から機械語に変換する必要があります。
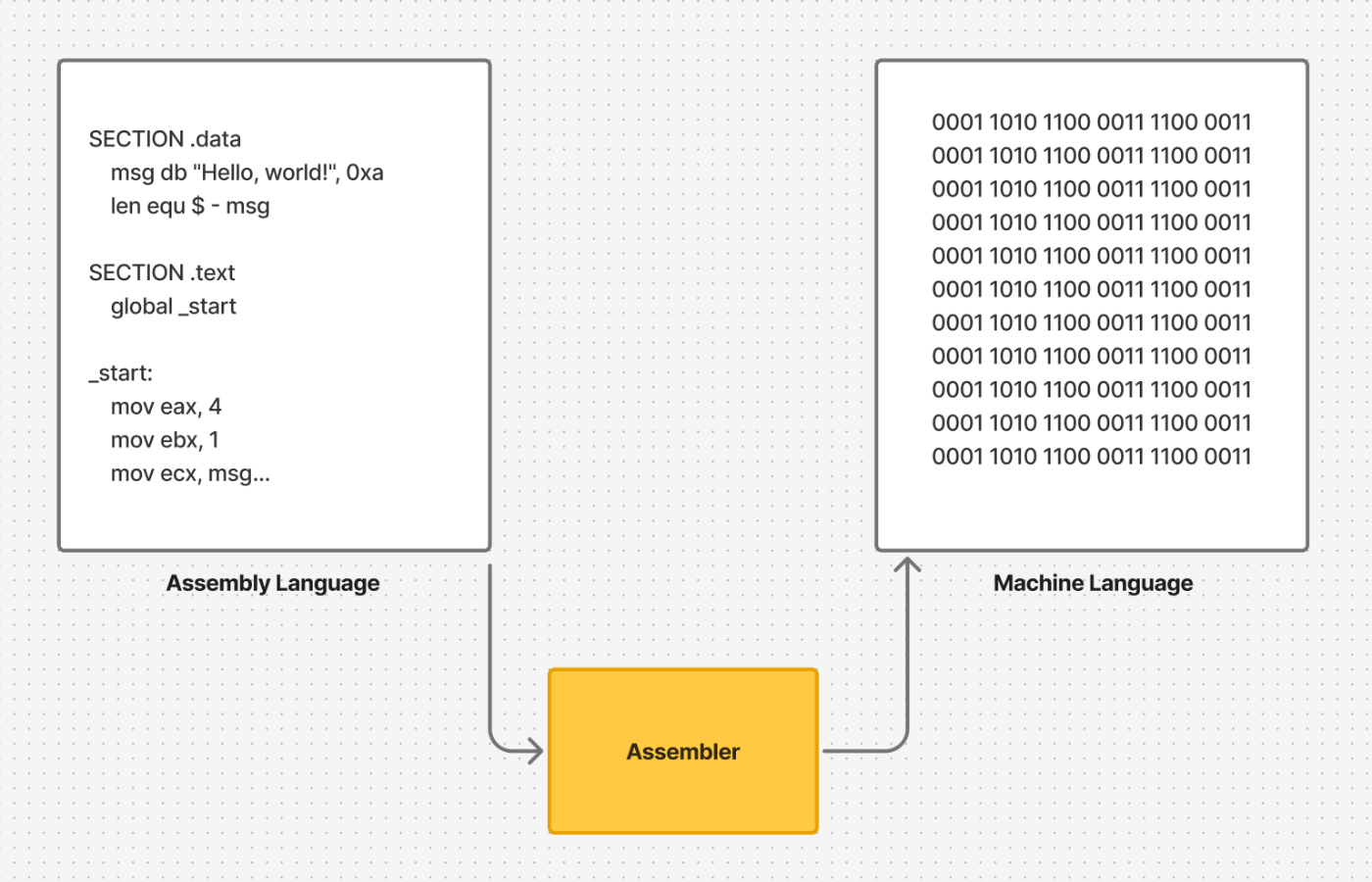
アセンブラ(Assembler)
アセンブリ言語で書かれたコードを機械語に変換して実行可能な形式(オブジェクトファイル、バイナリ)へとコンパイルするツールです。たとえばNASM、MASM、GASなどがあります。
機械語
コンピュータが実際に解釈・実行する0や1のビット列で表されます。人間には扱いづらい低レベルな形式ですが、CPUはこの機械語をもとに動作します。
実行環境と準備
今回の記事では、Intel系CPU向けのx86アセンブリ言語を取り上げ、アセンブラとしてNASMを使用します。x86アセンブリ言語は、Intelが開発したx86系アーキテクチャ向けの低水準プログラミング言語で、レジスタや命令を直接操作するため、ハードウェアに近いレベルでの制御が可能です。コードの実行には、オンライン実行環境であるgodboltを利用します。以下のリンクからアクセスできます。
アクセス後、アセンブラの指定についてNASM 2.16.01を選択してください。
Hello Assembler!!という文字列を出力してみる
以下コード全体になります。
global _start
section .data
msg db "Hello Assembler!!", 0Ah
len equ $ - msg
section .text
_start:
mov edx, len
mov ecx, msg
mov ebx, 1
mov eax, 4
int 0x80
mov ebx, 0
mov eax, 1
int 0x80
一つずつ解説していきます。
global _start
_や.からはじまるものはシンボルと呼び、32bitの値を持ちます。
シンボルの中でも:で終わるものはラベルと呼びます。この宣言によって、_startラベルを外部に公開し、プログラムの開始位置として使用できるようになります。
section .data
データセクションで、プログラム中で使う変数や定数、文字列などをまとめて定義するために利用します。ここに定義したデータは、プログラムが開始したときにメモリ上に配置され、読み書きが可能な状態になります。
msg db "Hello Assembler!!", 0Ah
len equ $ - msg
msgがラベルであり(変数名のようなもの)として扱われ、dbはDefine Byteの略で、1バイトごとにデータをメモリに格納する命令となります。0Ahは、16進数で0x0A、改行を表すバイト値になります。したがって17バイトの文字列("Hello Assembler!!")をmsgに格納しています。
次の行に関して、$はNASMでは現在のアドレスを表します。
equはNASMで使われる定数定義用のディレクティブです。
現在のアドレスからmsgのアドレスを引いた値をlenという名前の定数として定義します。
つまり、msgから現在のアセンブラの位置までのバイト数を計算しています。こうすることで文字列の長さを手動で数える必要がなくなります。
section .text
命令コードを書くセクションの宣言となります。
_start:
mov edx, len
mov ecx, msg
mov ebx, 1
mov eax, 4
int 0x80
画面に文字を表示するなどハードウェアに直接触れる操作はカーネルが管理しているため、通常のプログラムはシステムコールを通してOSに「この操作をやって」と依頼します。
今回のケースでは、sys_writeが該当します。sys_writeはLinuxで定義されているシステムコールの1つでファイルや標準出力にデータを書き込む時などに使用されます。32ビットLinuxでは、システムコール番号が4に割り当てられています。
以下が参考になります。
edx,ecx,ebx,eaxなど見慣れないものが出てきました。これらは汎用レジスタといってCPU内部にある高速な記憶領域で、命令の実行や演算結果の一時保存、アドレス計算などに使用されます。
以下表にしています。
| レジスタ名 | 説明 | 用途の例 |
|---|---|---|
| EAX | Accumulator Register | 演算結果の格納、累算(加算)など |
| EBX | Base Register | データのベースアドレス保持 |
| ECX | Counter Register | ループカウンタ、シフト回数など |
| EDX | Data Register | データの格納, 乗算・除算の補助 |
詳しくは以下を参考にしてみてください。(以下のページに行くと、Volume 1 (Basic Architecture)に記載されています。)
Linuxの32ビット環境では、int 0x80を使ってカーネルにシステムコールを呼び出します。その際に、レジスタにシステムコール番号や引数をセットしてあげる必要があります。
| レジスタ | 役割 | 例(sys_write の場合) |
|---|---|---|
| EAX | システムコール番号 | 4 (sys_write) |
| EBX | 第1引数 | ファイルディスクリプタ (1=stdout) |
| ECX | 第2引数 | データの先頭アドレス |
| EDX | 第3引数 | 書き込むバイト数 |
改めて今回の処理を確認してみます。
mov edx, len ; EDX ← 書き込むバイト数(lenはデータセクションで定義したバイト数)
mov ecx, msg ; ECX ← 書き込むデータのアドレスを指定
mov ebx, 1 ; EBX ← ファイルディスクリプタ (1=標準出力)
mov eax, 4 ; EAX ← sys_write (システムコール番号4)
int 0x80 ; 割り込みでカーネルに処理を渡す
このようにデータセクションで定義したlenやmsgを使用して、書き込むバイト数やデータのアドレスを指定し、それらをカーネルに渡します。
mov ebx, 0
mov eax, 1
int 0x80
最後は、プログラムの終了です。
終了用システムコールはsys_exitで番号は1となります。
ebxに終了コード(ここでは0が正常終了)をセットして int 0x80を呼び出します。
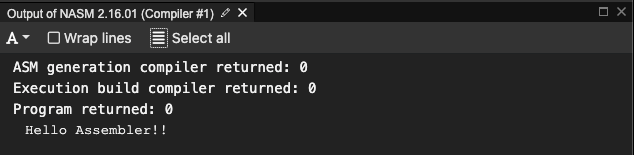
確認
以下ちゃんとHello Assembler!!と表示されています。これらの値をカーネルが読み取り、指定どおりの処理(文字列を表示)を行ってくれていることを確認できます。
アセンブラの種類
簡単なプログラムを書くことができました。少し踏み込むとアセンブラにはいくつか種類があり、ユースケースに合わせて使い分けると効率的にコードを書くことができます。
マクロアセンブラ
マクロアセンブラでは、よく使う命令列をマクロとしてまとめておき、呼び出すだけで展開できるのが特徴です。今回の例ではHELLOマクロを定義し、文字列Hello Assembler!!を表示するためのレジスタ設定(edxに文字数、ecxに文字列アドレス、ebxに標準出力、eaxにsys_write)とint 0x80の呼び出しを一括で行っています。メインコードではマクロ名HELLOを書くだけで、その命令列が展開されて文字列が表示されます。最後にebx=0とeax=1を設定して再びint 0x80を呼び出し、sys_exitによりプログラムを終了します。こうしたマクロ化により、コードの保守や再利用が簡単になるのが大きな利点です。
%macro HELLO 0
mov edx, len
mov ecx, msg
mov ebx, 1
mov eax, 4
int 0x80
%endmacro
section .data
msg db "Hello Assembler!!", 0Ah
len equ $ - msg
section .text
global _start
_start:
HELLO ; マクロ呼び出し → 上の命令がそのまま展開される
mov ebx, 0
mov eax, 1
int 0x80
クロスアセンブラ
開発するコンピュータと、実際に動作させるコンピュータが異なる場合に使われるアセンブラです。
たとえば、パソコン上で組み込み機器向けのプログラムを作る場合、組み込み機器には開発環境がないため、パソコン上でコードを作ってから転送する必要があります。このとき、クロスアセンブラを使うと、ターゲットとなる機器用の機械語に変換してくれます。変換後のデータは、ROMや、シリアル通信などを使ってターゲット機器に書き込みます。
高水準アセンブラ
通常のアセンブラは、シンプルな命令の組み合わせですが、高水準アセンブラはよりプログラムらしい書き方ができるのが特徴です。例えば、C言語のようにif文やcase文などの制御構造を使えたり、構造体やクラスのような高水準なデータ型をサポートしていたりします。アセンブリ言語の見た目はそのままに、もっと書きやすくしたものとなります。
マイクロアセンブラ
マイクロアセンブラは、ファームウェアを用いてコンピュータの低レベル動作を制御するためのプログラムです。これは通常のアセンブラがプロセッサ用の命令コードを組み立てるのと同様に、マイクロコードを組み立てます。マイクロプログラムはハードウェアの指令セットを実装するためのもので、ハードウェアの設計ミスを修正したり、同じハードウェアで異なる命令セットを実行できるようにするなどの利点があります。より低レベルで動作を制御したいときに便利です。
メタアセンブラ
通常のアセンブラは、ある特定のCPU向けのプログラムを作るためのものですが、メタアセンブラは、アセンブラそのものを作るためのアセンブラです。例えば、新しいCPU向けのアセンブラが必要になったとき、ゼロから作るのは大変です。そこで、メタアセンブラを使えば、そのCPUに合ったアセンブラを自動生成できます。これは、ちょうどプログラミング言語を作るためのプログラム(コンパイラ)を作るようなものです。
インラインアセンブラ
これは、C言語やPythonのような高水準言語の中にアセンブリ言語を直接書くための仕組みです。
以下は、GCCの拡張構文(__asm__)を使ったインラインアセンブラの例です。
C言語の関数内で__asm__("int $0x80" ... )と書くことで、レジスタに引数をセットして割り込み命令を呼び出すコードをインラインで挿入しています。
extern int errno;
int syscall3(int num, int arg1, int arg2, int arg3)
{
int res;
__asm__ (
"int $0x80" /* make the request to the OS */
: "=a" (res), /* return result in eax ("a") */
"+b" (arg1), /* pass arg1 in ebx ("b") [as a "+" output because the syscall may change it] */
"+c" (arg2), /* pass arg2 in ecx ("c") [ditto] */
"+d" (arg3) /* pass arg3 in edx ("d") [ditto] */
: "a" (num) /* pass system call number in eax ("a") */
: "memory", "cc", /* announce to the compiler that the memory and condition codes have been modified */
"esi", "edi", "ebp"); /* these are clobbered too */
/* The operating system will return a negative value on error;
* wrappers return -1 on error and set the errno global variable */
if (-125 <= res && res < 0) {
errno = -res;
res = -1;
}
return res;
}
参考: https://codedocs.org/what-is/inline-assembler
このように、プログラムの一部分だけをアセンブリで書くことができます。これは主に、ハードウェアに直接アクセスする必要がある場面で使われます。
まとめ
普段プログラムを書いている時は、抽象化され簡略化したものを普段扱っているんだと実感します。裏側でさまざまな処理が行われ、固定の文字列を表示するだけでもメモリを意識したりCPUに命令コードを読んだりとさまざまな手順を要します。最適化された物を普段使っているとは思いますが、メモリに優しいコードをより意識しようと思いました。今回はかなり簡単な例だったので、もう少し高レベルなデータ構造を構築するためのプログラムなどを書いてみようと思います。
参考
Discussion