ジングル検出によるラジオのコーナー抽出
以前から録りためていたラジオのファイルから、あるコーナーの部分だけ抜き出したいと思ったのでRubyスクリプトを書いてみた。
そのコーナーははじめと終わりに決まったジングルが流れるので、それを検出できればコーナーのみの抽出ができる。
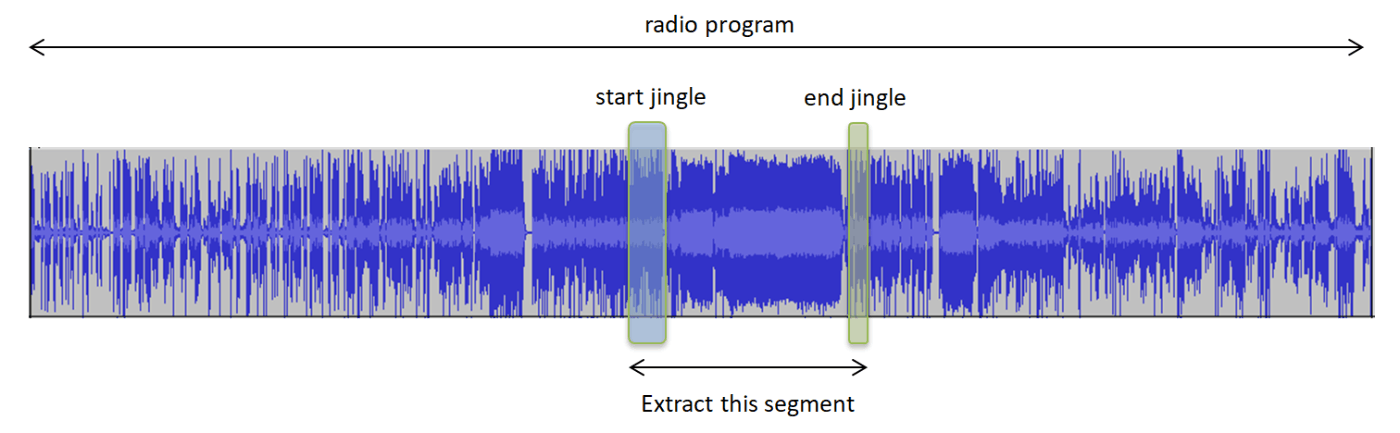
ただ、決まった音とは言っても毎回ビットレベルで一致しているわけではないだろうから、単純なビット比較で検出することはできない。
自分はサウンド処理の経験はほとんどないのでどうしようか考えていたが、似たようなことをやっている人は他にもいるだろうと思って調べてみたところ、まさに自分と同じことをやっている以下のブログが見つかった。
この記事ではジングル検出アルゴリズムをまずGNU Octave (or Matlab) で作り、動作が確認できたところでJavaで実装している。アルゴリズムをざっと見たところRubyでも作れそうなのでやってみた。
中身はどうでもいいからツールだけ使いたいという人はgithubからダウンロードして欲しい。使い方はREADME.mdにある。ラジオのコーナーで毎回決まった終了ジングルがあるのは少なそうだから使える場面は少ないかもしれないけど。
以下技術的な話。
準備
まずはジングル検出動作確認用のwavファイルを用意した。
- jingle.wav: ジングルのみを抽出したもの(約4秒)
- sample1.wav: ジングルを含む区間を抽出したもの(約8秒)
- sample2.wav: ジングルを含まない区間を抽出したもの(約8秒)
録音ファイルはMP3などの圧縮形式だろうからwavに変換する必要がある。ffmpegを使うのが手軽だと思う。Ubuntuならsudo apt install ffmpegでインストールできる。変換コマンドは以下のようにして16ビット・ステレオ・44100Hzのwavファイルを作る。
ffmpeg -i radio.mp3 -vn -ac 2 -ar 44100 -acodec pcm_s16le -f wav radio.wav
音声ファイルの一部を抽出するのは波形編集アプリを使う。無料で有名なのはAudacityというアプリで、自分もこれを使った。

Octave
では元ブログにあるOctaveのコードを試してみる(関数名が変わったなどの理由で元ブログとは少し異なっている)。このコードで2つのwavファイルの類似度を算出できる。見ての通り読み込んだwavファイルをxcorrという関数に入れているだけだ。
graphics_toolkit('gnuplot');
pkg load signal
jingle = audioread('jingle.wav')(:,1);
audio = audioread('sample1.wav')(:,1);
[R, lag] = xcorr(jingle, audio);
plot(R);
max(R)
同様にsample2.wavについても計算してそれぞれプロットすると以下のようになる。ジングルを含んでいるsample1.wavは値が高くなっているところがあり、ジングルを含まないsample2.wavはそういう箇所がない。xcorrという関数1つだけで判定できてしまうのは驚きだ。

xcorrとは何か
ではこの魔法の呪文xcorrが何をやっているのか? これについても元ブログに書かれているので引用させてもらう。
N = length(audio);
M = 2 ^ nextpow2(2 * N - 1);
pre = fft(postpad(prepad(jingle(:), length(jingle) + N - 1), M));
post = fft(postpad(audio(:), M));
cor = ifft(pre .* conj(post));
R = real(cor(1:2 * N));
高速フーリエ変換(fft)と逆フーリエ変換(ifft)の他いくつかの行列/数値計算関数が使われているが、どれも一般的なものだ。これなら他の言語で実装するのも難しくないはず。
この計算でなぜうまくいくのかという数学的な背景はさておき、ここまで分かればコーナーの抽出は難しくない。ラジオのファイル全体を細切れにして順にジングルとの類似度を計算し、値が高いところがあればそれがジングルがある場所だ。これをコーナー開始ジングル・終了ジングルそれぞれに対して行えばコーナーの始まりと終わりの場所が分かる。あとはその区間を取り出すだけだ。
Ruby実装のための材料
ではRuby実装のための材料を揃えよう。
行列演算とWavファイル読み込み
行列演算はNumo::NArrayを使った。また、Wavファイルの読み込みはwav-fileを使った。読んだデータをNumo::NArrayにするには以下のようにする。値を正規化して-1.0~1.0の間にしたかったのでSFloatにキャストして32768で割っている。
open("jingle.wav"){|f|
format = WavFile::readFormat(f)
dataChunk = WavFile::readDataChunk(f)
data = Numo::Int16::from_string(dataChunk.data).cast_to(Numo::SFloat) / 32768
}
FFT, IFFT
Numo::NArray用のFFT実装はいくつかあるようだが、今回はnumo-pocketfftを使った。
その他数値演算
conj(共役複素数)、real(複素数の実部を取得)などは同様のものがNumo::NArrayにもある。prepad, postpad, nextpow2は直接対応するものはないが、自作するのは難しくはない。
Wavファイル書き出し
wav-fileにも書き出し用のAPIがあるが、Numo::NArrayから作成するうまい方法が見当たらなかったのでwav-fileのソースを参考に自作した。といってもwavファイルの構造はシンプルなので難しくはなく、かなり短いコードで書ける。
Rubyスクリプト作成と動作確認
これで材料が揃ったので後はまとめるだけだ。作成したスクリプトはkarutaという名前でgithubに置いた。名前の由来は、このスクリプトを書いた目的が「伊集院光 深夜の馬鹿力」を録音したファイルから「新・勝ち抜きカルタ合戦・改」のコーナーを抜き出すことだから。
使い方はREADME.mdにも書いたが以下のとおり。
$ gem install wav-file numo-narray numo-pocketfft
$ ./karuta.rb jingle-start.wav jingle-end.wav radio.wav out.wav
49回分のファイルで試したところ、45回については正しくコーナーの部分のみ抽出され、4回は検出されなかったが、その4回はいずれもそのコーナーがなかった回だった。つまりいずれも正しく動作している。
実行時間は2時間のファイルからの抽出で3分くらい。それなりに時間がかかるので、もっと良いアルゴリズムがあったら教えてほしい。
Discussion