はじめに
こんにちは、Wanderlustの森安です。
近年、生成AIと情報検索の融合が急速に発展し、専門分野や社内ナレッジの活用がますます重要になっています。しかし、従来のRAGでは専門用語やドメイン特化情報、社内独自の知識を正しく検索・活用できないという課題がありました。
そこで、2024年夏に登場したのが「Golden-Retriever」です。従来のRAGに質問や知識ベースの前処理プロセスを追加することで、専門知識や社内文書の検索精度を大幅に向上させ、より正確で実用的な回答を提供できるようになりました。特に、検索前にクエリから専門用語を抽出し、専門用語辞書(Jargon Dictionary)による説明を加えることで、曖昧なクエリでも適切な情報を取得できる点が特長です。
企業のナレッジ管理から医療・法律・金融といった専門領域まで、幅広い分野での活用が進んでいます。
この記事でわかること
この記事では、専門用語を多く含むRAGにおいて、より正確な回答を引き出す技術「Golden-Retriever」について、以下の内容を紹介します。
- 従来のRAGとGolden-Retrieverの違い
- Golden-Retrieverのプロセス
- 実験での成果
本記事は以下の論文を参考にしています。
問題と解決策
従来のRAGは、LLMが知識ベースから検索した情報を活用して回答を生成する仕組みですが、検索精度の問題により適切な情報を取得できないケースがありました。特に以下の3点が課題となります。
- 専門用語や略語の誤解
例えば「AIモデルのCNNとは?」という質問に対し、本来の「Convolutional Neural Network」ではなく、「Cable News Network(CNN)」と誤解されることがある。 - 文脈不足による検索ミス
「Appleの最新情報は?」という質問が「Apple(企業)」なのか「りんご(果物)」なのか判別できず、意図しない分野の情報が検索される。 - 関連性の低いドキュメントの取得
ベクトル検索は表面的な類似性に基づくため、本質的に関連のない文書が検索されることがある。
Golden-Retrieverは、この問題を解決するために検索前のクエリ補強(query augmentation) を導入します。LLMを用いて質問内の専門用語を抽出し、専門用語辞書(Jargon Dictionary)を参照して補足することで、曖昧なクエリを明確化し、適切な文書を検索できるようにします。さらに、知識ベース自体もOCRによるテキスト抽出やLLMによる要約によって整理・最適化され、LLMがより正確で自然な回答を生成できるようになります。
方法
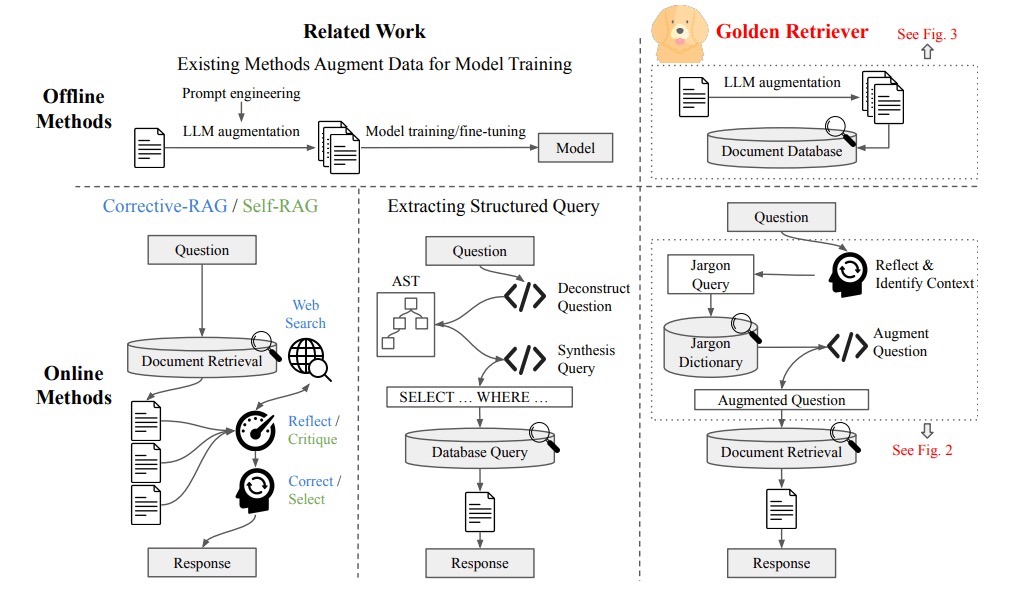
Golden-Retrieverのプロセスは、事前に行うオフラインプロセスと、ユーザーの質問に対してリアルタイムで行われるオンラインプロセスがあります。上図の右側がGolden-Retrieverで、従来のRAGやその他技術(Corrective RAGやSelf-RAG)と比較されています。これら2つのプロセスについて以下で説明します。
オフラインプロセス
- 文書をOCR技術でテキスト化し、意味のまとまりを考慮しながらチャンクに分割する。
- 各チャンクに対して、LLMを用いて検索精度を高めるための要約を作成し、文脈を整理する。
- チャンクごとに専門分野や用語情報を含むメタデータを付与し、検索時の関連性を向上させる。

上図は、このオフラインプロセスで使用されるプロンプトの一例です。従来のRAGでは、文書を一定のルールで分割し、そのまま格納するのが一般的でした。しかし、Golden-Retrieverでは、文脈を考慮したチャンク化、LLMによる要約、専門分野に応じたメタデータの付与を行うことで、検索時の情報の関連性を大幅に向上させています。
この最適化により、専門用語の曖昧な解釈による誤検索やノイズの影響を抑え、より適切な情報を的確に取得できるようになります。従来のRAGと比べ、Golden-Retrieverは検索と生成の精度を高め、より信頼性の高い回答を提供できるようになっています。
オンラインプロセス
- クエリに含まれる専門用語や略語をLLMで抽出する。
- 抽出された専門用語を専門用語辞書と照合し、定義や関連情報を取得する。
- LLMが取得した専門用語の定義をもとに、質問の文脈を特定し、曖昧な表現を明確化する。
- 得られた文脈情報と専門用語の定義を統合し、新たな「明確化された質問」を作成する。
- この新たな質問をRAGのretrieverに入力し、適切な文書を検索する。
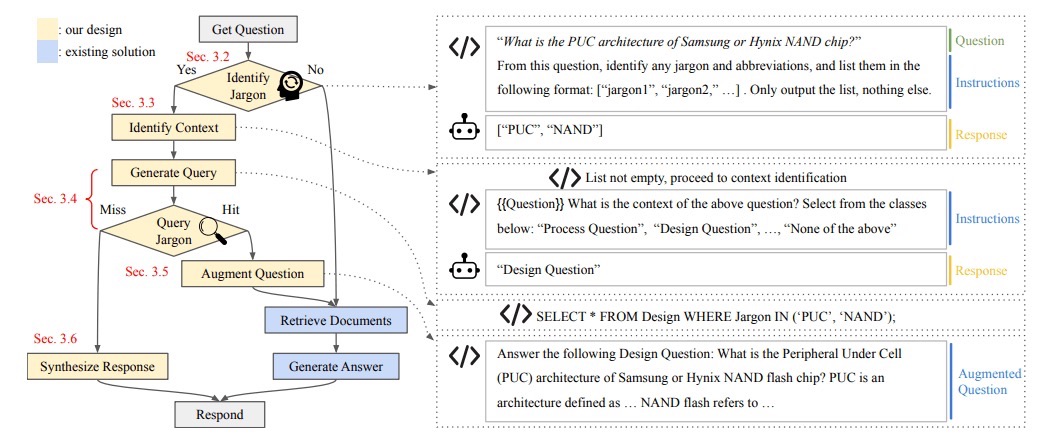
従来のCorrective RAGやSelf-RAGは、最終的な回答に対して修正を加えるアプローチを取っていました。これに対し、Golden-Retrieverは検索前の段階で質問自体を明確にすることで、検索の精度を向上させるというアプローチを採用しています。
上図のように、Golden RetrieverはまずLLMを活用して質問内の専門用語を抽出し、それらを 専門用語辞書と照合 することで、定義や関連情報を取得します。その後、得られた情報をもとに LLMが質問の文脈を特定し、曖昧さを取り除いた明確な質問を作成。この質問をRAGのretrieverに入力することで、より関連性の高い情報を取得できるようになります。
これらのプロセスによって、従来のRAGでは専門用語の曖昧さによって適切な情報を取得できなかったケースでも、専門用語辞書を活用した質問の明確化を通じて、検索精度と回答の正確性を向上させることが可能になります。
実装
以下に簡易的にGolden-Retrieverを実装する例を示します。
# ===== オフラインプロセス:知識ベースの構築 =====
jargon_dict = {
"Apple": "Apple Inc. (Technology Company)",
"Mac": "Macintosh Computer (Produced by Apple Inc.)"
}
documents = [
"Apple Inc. is one of the leading technology companies in the world.",
"Apples (fruit) are rich in fiber and vitamins.",
"Mac (Macintosh Computer) is a product developed by Apple Inc.",
]
docs = [Document(page_content=text) for text in documents]
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
db = FAISS.from_documents(docs, embedding_model)
# ===== オンラインプロセス:クエリ補強 & 検索 =====
def augment_query(query):
for term in jargon_dict.keys():
if term in query:
query = query.replace(term, f"{term} ({jargon_dict[term]})")
return query
query = "What is Apple known for?"
augmented_query = augment_query(query)
retriever = db.as_retriever(search_kwargs={"k": 3})
retrieved_docs = retriever.invoke(augmented_query)
# ===== 回答生成 =====
llm = ChatOpenAI(model="gpt-4", openai_api_key=openai_api_key)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=retriever)
answer = qa_chain.invoke(augmented_query)
# ===== 結果の表示 =====
print("Original Query:", query)
print("Augmented Query:", augmented_query)
print("\nRetrieved Documents:")
for doc in retrieved_docs:
print("-", doc.page_content)
print("\nAnswer:", answer)
これに対する出力は以下のようになります。
Original Query: What is Apple known for?
Augmented Query: What is Apple (Apple Inc. (Technology Company)) known for?
Retrieved Documents:
- Apple Inc. is one of the leading technology companies in the world.
- Mac (Macintosh Computer) is a product developed by Apple Inc.
- Apples (fruit) are rich in fiber and vitamins.
Answer: {'query': 'What is Apple (Apple Inc. (Technology Company)) known for?', 'result': 'Apple Inc., the technology company, is known for developing innovative electronic gadgets and software services. Some of its prominent products include the iPhone, iPad, and Mac computers. They are also known for software services like the iOS, iTunes, and iCloud.'}
Retrieved Documentsでは類似度検索によって取得されたDocumentsの要素が、そのスコア順に並んでいます。Jargon DictによってQueryのAppleという単語が企業名であることを説明しているため、類似度検索の結果ではフルーツのAppleに関するドキュメントが3番目になっています。これにより、AnswerではApple Incに関して正しい回答を得ることができました。
実験結果
今回参考にしている論文では、専門用語や略語が入った質問文とその選択肢を与え、そのスコアを比較するという実験が行われていました。対象は、標準的なLLM(Vanilla LLM)、標準的なRAG(Vanilla RAG)、Golden-Retrieverを用いたRAGの3つです。これらに対して3つのLLMモデルをテストしました。
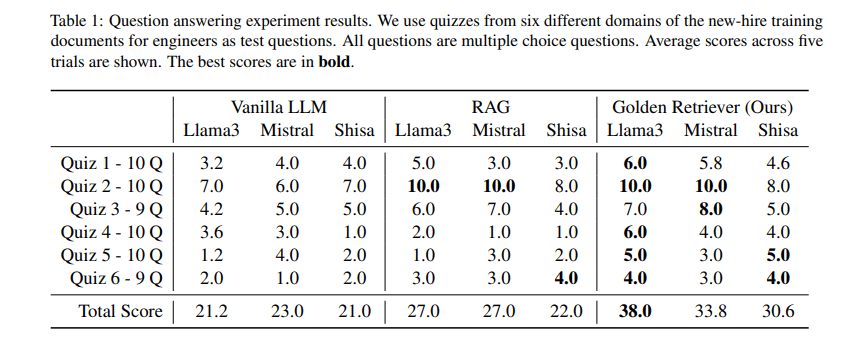
本実験では、質問応答の正答数を評価指標として用いており、各 LLM がクイズ形式の問題に対してどれだけ正しく回答できたかを測定しました。また、5 回の試行で平均スコアを算出し、手法ごとの比較を行いました。さらに、Vanilla LLM および Vanilla RAG に対するスコアの改善率(%)を計算し、それぞれの手法がどれだけ性能向上に寄与したかを示しています。
主な結果は以下の通りです。
- Meta-Llama-3-70Bのスコアは、Vanilla LLMに対し79.2%、Vanilla RAGに対し40.7%向上
- 3 つの LLM において、スコアの平均値は Vanilla LLM に対して 57.3%、Vanilla RAG に対して 35.0% 向上
以上のことから、Golden-Retrieverが曖昧な用語が含まれる質問に対する回答精度の向上に貢献することが分かります。
まとめと展望
Golden-Retriever は、従来のRAGにおける検索精度の課題を克服し、専門用語や略語を含む質問に対してより正確な回答を導き出す革新的な手法です。検索前のクエリ補強(query augmentation)によって曖昧な質問を明確化し、知識ベースの最適化と組み合わせることで、従来のRAGを大幅に上回る検索精度を実現しました。実験結果からも、その有効性が証明されており、特に医療、法律、金融、技術分野など、専門的な知識を必要とする領域での活用が期待されます。
一方で、専門用語や社内知識を活用するRAGの技術はさらに進化を遂げつつあります。例えば、Graph-RAGは文書間の関係性をグラフ構造として捉え、専門知識がネットワーク的に結びつく領域での検索精度を向上させる手法として注目されています。また、Hybrid-RAGのようにベクトル検索とキーワード検索を組み合わせるアプローチもあり、曖昧な用語を含む検索クエリに対して、より柔軟な情報取得を可能にする可能性があります。
このように、専門領域向けRAGの発展はGolden-Retrieverだけにとどまらず、検索手法の多様化が進んでいることがわかります。今後は、それぞれの手法の特性を活かした適用領域の最適化や、異なる技術を組み合わせたハイブリッドなアプローチが求められるでしょう。
エンジニア採用
株式会社Wanderlustは、東京大学・松尾研発のグローバルAIスタートアップです。
実務経験を積みたいエンジニアを広く募集しています。気軽にご応募ください。
【応募概要】
- 時給: 1,500円-6,000円
- 職種: AI/LLMエンジニア、AI/画像認識エンジニア、バックエンドエンジニア、クラウドエンジニア
- 勤務地: 神保町/リモートワーク可
- 歓迎要件: 英語ネイティブ、Atcoder/Kaggle経験者、フルコミット可能な学生(休学者歓迎)、海外大学院進学志望者
- 必要開発経験: 未経験可(ただしその場合、相当量のコミットメントを求めます)
【インターン詳細】
https://maddening-conga-35e.notion.site/We-are-hiring-8956d0b3e0ab447eadb4d2a69342a47b?pvs=74
【応募フォーム】

Discussion