はじめに
近年、大規模言語モデル(LLM)と情報検索技術の融合によって、私たちのデータとの関わり方が大きく進化しています。その中でも「検索拡張生成(RAG:Retrieval-Augmented Generation)」は、従来アクセスが難しかったプライベート文書や非公開データに対して、外部知識を活用して自然言語で回答を生成する手法として注目を集めています。
しかし、従来のRAG、特にベクターRAGと呼ばれる方式には限界があります。たとえば:
- 「このデータセットの主なテーマは?」
- 「過去10年間の研究動向の傾向は?」
といったような、コーパス全体を見渡すグローバルな問いにはうまく対応できません。これらは検索というより、情報を統合・要約する「クエリ指向要約(Query-Focused Summarization:QFS)」の領域に近いタスクです。
一方、QFSの従来手法は、大量のテキストを対象とするRAGのような大規模なスケーリングには不向きであり、実運用では課題が残っていました。
そこで登場したのが、2024年2月にMicrosoftによって発表された新たなアプローチGraphRAGです。
GraphRAGは、LLMを活用してグラフ構造のインデックスを構築し、RAGとQFSの長所を統合することで巨大なテキストコーパスから「意味の全体像」を抽出できるように設計されています。
この記事でわかること
- 従来のRAG (ベクターRAG)の仕組みと課題
- GraphRAGの仕組み
- GraphRAGのパフォーマンス評価
- GraphRAGがもたらす実用上のインパクトと今後の可能性
本記事は以下の論文を参考にしています。
従来のRAG(ベクターRAG)の仕組みと課題
従来のRAGでは、質問文と外部のテキストデータをベクトル表現に変換し、質問文に意味的に近いテキストデータを検索します。そして、LLMは検索されたテキストデータを参照して回答を生成します。この手法は「特定の情報がどこに書かれているか」が明確な質問には有効ですが、「データ全体にまたがる傾向やつながり」を問う質問には不向きです。
このようなグローバルな質問に答えるには、個別のドキュメントではなく、コーパス全体の構造や関係性を捉える必要があります。
GraphRAGの仕組み
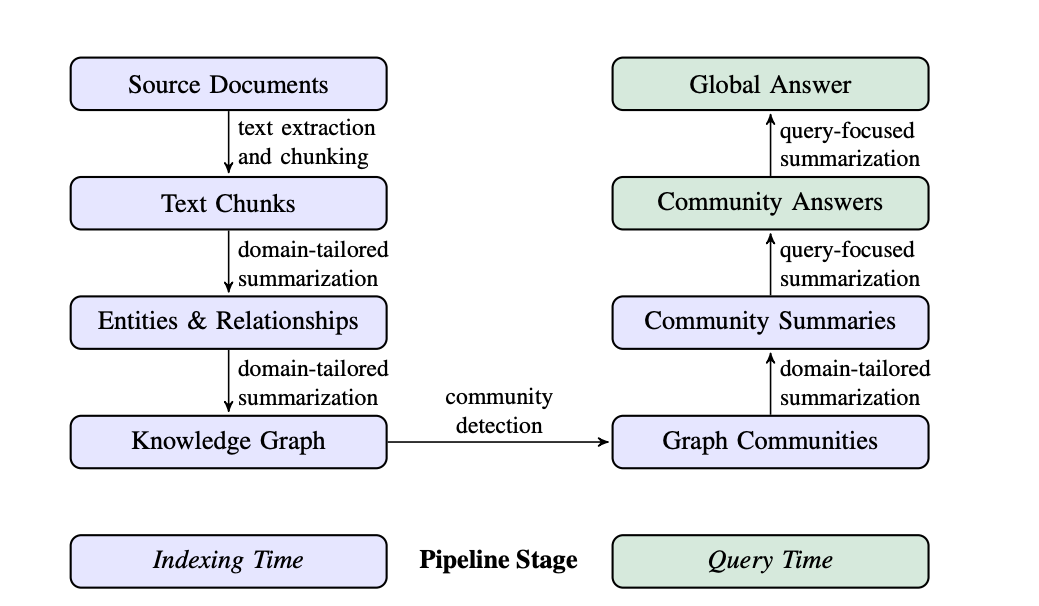
GraphRAGは、ドキュメント全体をグラフ構造で表現することにより、LLMがコーパス全体の知識をより有効に扱えるようにする仕組みです。GraphRAGの仕組みは、大きく分けてグラフインデックスの構築とクエリ処理の2つの段階から構成されます。
1. グラフインデックスの構築
文書から知識グラフを構築し、コミュニティとその要約を生成します。
1-1. ソース文書 → テキストチャンク
- 分析対象の文書コーパスを、テキストチャンクに分割
- チャンクのサイズは、LLMによる情報抽出の効率と情報の想起率のバランスを考慮して決定
- 短いチャンクは多くのLLM呼び出しを必要としますが、情報の想起率が高くなる傾向がある
- 長いチャンクはLLM呼び出し回数を減らせますが、チャンクの最初の方にある情報を見落とす可能性が高まる
1-2. テキストチャンク → エンティティと関係性
- LLMを用いて、チャンクから以下を抽出:
- エンティティ(人物・場所・トピックなど)
- 関係性
- (エンティティに関する)出来事
1-3. エンティティと関係性 → 知識グラフ
- LLMによって抽出されたエンティティと関係性から知識グラフを構築
- ノード:エンティティ
- エッジ:関係性(頻度を重みとして表現)、出来事
- 基本的に、異なる表現の同一エンティティの識別には、エンティティ名による厳密な文字列マッチングが使用されますが、より柔軟なマッチング手法も適用可能
1-4. 知識グラフ → グラフコミュニティ
- 知識グラフに対して、コミュニティ検出アルゴリズム(ex: Leidenアルゴリズム)を適用することで、”コミュニティ”と呼ばれる強く連結されたノードのグループに分割
- GraphRAGでは、このコミュニティ検出を階層的に行うことで、グローバルな要約を分割統治的に実現
- コミュニティ内でさらにサブコミュニティを再帰的に検出
- グラフのノードを相互に排他的かつ網羅的にカバーするコミュニティのパーティションを提供
1-5. グラフコミュニティ → コミュニティ要約
- 各コミュニティに対して、LLMで要約レポートを作成
- 上位コミュニティは下位コミュニティの要約を元に要約
- リーフレベルのコミュニティ: 要素を重要度(次数)順に追加し、トークン上限まで含める
- 上位レベルのコミュニティ: トークン制限内で可能な限り多くの下位要素要約を含め、収まらない場合は短い要約を優先
2. クエリ処理
この段階では、ユーザーの質問に基づいて、生成されたコミュニティ要約を利用して最終的な回答を生成します。
2-1. コミュニティ要約 → コミュニティ回答
- ユーザーからのクエリに基づき、各コミュニティ要約ごとにコミュニティ回答(中間回答)を生成
- LLMによって生成された回答の有用性を0 ~ 100で評価し、0のものを切り捨て
2-2. コミュニティ回答 → グローバル回答
- コミュニティ回答を有用性スコア順にソート
- トークン制限に達するまでコミュニティ回答を追加し、最終的なコンテキストの作成
- 最終的なコンテキストを使用して、LLMがユーザーにグローバル回答(最終回答)を提示
GraphRAGのパフォーマンス評価
2つの実世界データセット(ポッドキャストの文字起こし、ニュース記事)を用いた2つの実験による、GraphRAGと従来のRAGとの性能の差を紹介します
使用データセット
-
ポッドキャストの文字起こし
- 約100万トークン
- 1669チャンクに分割
-
ニュース記事
- 約170万トークン
- 3197チャンクに分割
評価対象
| 手法 | 内容 |
|---|---|
| C0, C1, C2, C3 | GraphRAG(知識グラフの4つの階層レベルでのコミュニティ要約) |
| TS | テキストチャンクに直接Map-Reduce要約を適用した手法 |
| SS | 意味的類似度に基づく標準的なベクターRAG |
実験1:テキスト要約の比較
評価方法
- 評価手法:LLM-as-a-Judge:LLM(GPT4)による定性的評価
-
評価基準
- 包括性(comprehensiveness)
- 多様性(diversity)
- エンパワーメント(empowerment:ユーザーの理解を助ける力)
- 直接性(directness)
スコア
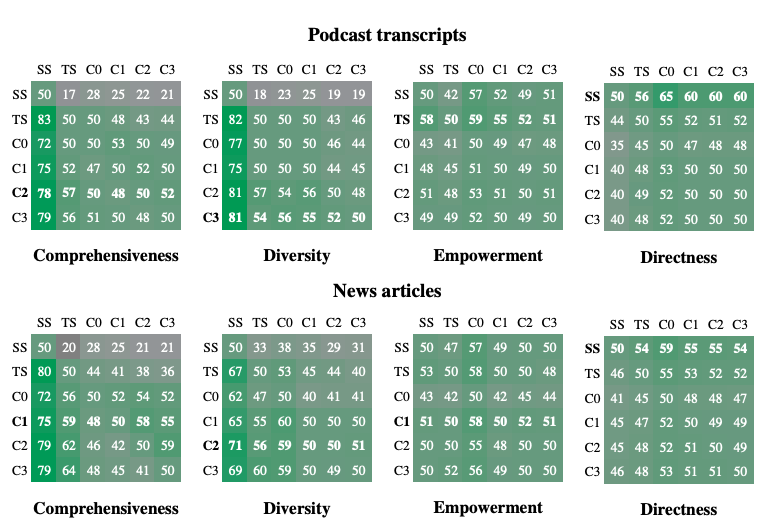
結果
- GraphRAG(C0〜C3)およびTSは、SSに対して包括性と多様性の両面で大きく優れていた
- C0(ルートレベル)は、トークン数の削減により効率性の面でTSよりも優れていた
実験2:テキスト要約の比較
評価方法
- 評価手法:Claimifyツールを用いて、各回答から事実主張を抽出
-
評価基準
- 包括性:抽出されたClaim(出来事)の数の平均
- 多様性:抽出されたClaim(出来事)をクラスタリングした際のクラスター数
スコア
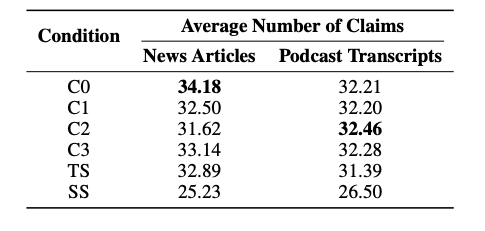

結果
- 全てのグローバル手法(C0〜C3、TS)は、SSより多くの主張を含み、包括性が高かった
- C0〜C3およびTS間での包括性・多様性には統計的な有意差はなかった
結論:GraphRAGは革新的
- グローバルな意味理解において、従来のベクターRAGに比べて包括性・多様性ともに大幅に優位
- TSと比べても、少ないトークンで同等またはそれ以上の性能を発揮し、効率面でも優秀
- 特にC0は、回答品質と効率性のバランスに優れ、実運用への応用可能性が高い
GraphRAGの将来:想定されるユースケース
GraphRAGは、従来のRAG(Retrieval-Augmented Generation)と同様に多様な業界に適用可能ですが、特にナレッジグラフと相性の良い分野において高い効果を発揮します。以下のような、特に複雑な関係性を持つデータを扱う分野での適用が有望です。
| ユースケース | 説明 | 質問例 |
|---|---|---|
| 医療診断と治療提案 | 症状、疾病、治療法の関係を含む医療ナレッジグラフと統合することで、診断支援や治療計画の最適化に貢献できます。 類似患者の治療履歴を基にした推奨や、疾病拡散経路の解析が可能です。 |
- 「この症状の患者には過去にどのような治療が成功しているか?」 - 「糖尿病患者に最適な治療法は何か?」 - 「この薬の副作用リスクを低減する方法は?」 |
| 法律文書の解析と判例検索 | 大量の法律文書を分析し、関連する判例や法的先例を検索できます。 複雑な法的関係を可視化し、弁護士や法務担当者が迅速に必要な情報を取得可能にします。 |
- 「過去の判例でこのケースと類似したものはあるか?」 - 「この法律の適用範囲を示す判例は?」 - 「知的財産権に関する最新の重要判例は?」 |
| 金融リスク管理と不正検出 | トランザクションデータや顧客情報をグラフ構造として扱い、不正検出やリスク管理を強化できます。 クラスタリング技術や中心性測定を活用し、不審な取引パターンを特定します。 |
- 「最近増加している不正取引のパターンは?」 - 「この顧客の取引履歴に異常な点はあるか?」 - 「過去のデータから高リスクな取引の特徴を抽出できるか?」 |
| 科学研究データの解析 | 気象データの解析や生命科学における代謝経路・タンパク質相互作用ネットワークの分析など、複雑なデータ構造を扱う科学研究分野での活用が期待されます。 | - 「過去50年間の気象データから異常気象のパターンを特定できるか?」 - 「この遺伝子と関連するタンパク質ネットワークを可視化できるか?」 - 「異なる気候モデルの予測結果の相違点は?」 |
おわりに
GraphRAGは、従来のRAGアプローチの限界を克服し、より意味的に豊かで包括的な情報抽出を可能にする革新的な手法です。意味の近接性だけに依存するベクトル検索の課題に対して、知識間の構造的な関係性をグラフとして捉え、階層的に要約された「コミュニティ」を活用することで、複雑なグローバルな問いに対する深い洞察を提供します。
実験結果からも明らかなように、GraphRAGは従来のVector RAG(SS)と比較して、包括性(comprehensiveness) および 多様性(diversity) において顕著な向上を示し、またトークン効率の面でもスケーラブルな利点を持つことが確認されました。
今後は、GraphRAGの枠組みを活かしつつ、他の技術――たとえばキーワード検索との組み合わせによるHybrid-RAG、専門領域ごとの知識構造に最適化されたドメイン特化型GraphRAGなど――との統合が進むと予想されます。また、生成AIとのインタラクションを深めるRAGアーキテクチャの進化により、情報の正確性・網羅性・透明性をさらに高めることができるでしょう。
RAG技術の多様化と構造化が進む中で、GraphRAGはその中核を担う存在として、知識に基づいたAIの未来を切り開く重要なステップになると考えられます。
エンジニア採用
株式会社Wanderlustは、東京大学・松尾研発のグローバルAIスタートアップです。
実務経験を積みたいエンジニアを広く募集しています。気軽にご応募ください。
【応募概要】
- 時給: 1,500円-6,000円
- 職種: AI/LLMエンジニア、AI/画像認識エンジニア、バックエンドエンジニア、クラウドエンジニア
- 勤務地: 神保町/リモートワーク可
- 歓迎要件: 英語ネイティブ、Atcoder/Kaggle経験者、フルコミット可能な学生(休学者歓迎)、海外大学院進学志望者
- 必要開発経験: 未経験可(ただしその場合、相当量のコミットメントを求めます)
【インターン詳細】
https://maddening-conga-35e.notion.site/We-are-hiring-8956d0b3e0ab447eadb4d2a69342a47b?pvs=74
【応募フォーム】
参考

Discussion