某N社のゲームソフトを検索できる機能を作ったハナシ
はじめに
- こういうモノを作りました
- 製作にあたって得られた知見等を書きます
- サービス公開までを振り返った記事になるためポエム要素と技術的要素入り混じる内容になっています
対象読者
- 個人開発初心者の思考が知りたい人
- Webサービス公開までどんな作業があるのかざっくり知りたい人
- dockerの構成に迷ってる人
マネタイズは一切狙ってません。売れるサービス作りという期待には添えませんので、ご了承ください。
以上、拙い筆致ですが最後までお付き合いください。
キッカケ
ゲーム雑誌ファミ通やニンテンドードリームがとある節目の際にN社が発売したゲームソフトまたは製品をまとめた冊子を付録していたことがありました。とても勉強になる、何回読み直しても読み応えのある愛読書でした。
ただ、本という媒体の都合上、一期一会のデータ閲覧には愛称が良いのですが、検索性には欠け、データの最新性も一切担保されません。真偽はともかく詳細情報はWikipediaなど、各種有志のファンサイトで読めるのですが、「この付録から直接Wiki飛べたらな〜・・・じゃあ、自分で検索システム作ろう」が発端です。自給自足。
そして、紆余曲折あり、数年前にWordPress上に検索システム(以降WordPress版)を作りました。
※現在は閉鎖済み
目標
今回の目標は至極シンプル
WordPress版からの脱却です。
脱却理由
脱却を考えた理由は大きく以下の3つになります。
- WordPress内でのメンテナンスに限界を感じていた
脱却を考えることになった一番の理由です。WordPress更新のたびにデザイン崩れがないか不安、崩れた際のメンテナンスがプライベートでの活動には割に合わない、モチベーションが保てなかったです。 - 共同運営ブログに勝手に個人的な趣味機能乗っけてた
実はWordPressは友達との共同運営です。そこに個人的な機能を包含していることに若干の罪悪感を感じていました。もっと大胆にWordPressを改築したいというメンバーがいた場合の足枷になっている可能性もあり、身を引くことにしました。 - 外に見せられる実績が欲しかった
転職活動を行った際に職務経歴書以外に見せられるネタが欲しいと感じました。
ただ、IT業界の面接官側がポートフォリオや自作サイトを何万回と見せられていることは想像に難くなく、正直うんざりするものだと思います。よほど何か秀でるものがない限り、職務経歴書を差し置いてプッシュすべきではないと考えてます。
そのため、転職活動は職務経歴書で勝負するつもりですが、それ以外を求められた場合や、もし今後趣味か何かで繋がった方からお誘いがあった場合などあくまで別軸としてのネタがあればいいなぁと。
要件
- WordPress版の最低限の機能(名称や発売日、ゲームハードで検索し、検索結果を閲覧できる)を有すること
- WordPress版のソースコード、データベースを流用し、リリースまでの時間を可能な限り短縮すること
- 出来合いのものを使用しなるべくデザイン面の工数を減らすこと(ページデザインなどそっちには精通してないので)
技術スタックの選定
まずはじめに完成版アーキテクチャ図をお見せします。

※図中のポート番号は全てデフォルトポートです。実際に構築する場合は別なポートを使用し、なるべく攻撃を受けないようにしましょう。
選定において重視した点
- なるべく既に習得済みであること
→職場で得たスキルは十分役に立ちます。可能な限り自分が既に持っているスキルを使い、要件にあるとおり、時間短縮を図ります。 - 新規習得の場合であっても学習コストが低いこと
→1点目と真逆ですが、触れたことのない技術の経験も欲しいので、可能な限り取り入れます。 - 今後もしばらくは廃れることのない技術であること
→メンテナンスする上で情報がないと個人開発では手詰まりになってしまいますので、今後もそれなりに盛り上がりを見せるあろう技術をなるべく選びます。
以降今回採用した技術をサラッと掲載します。
サーバー
nginx
職場ではapache、tomcatが主でしたが、個人開発ということでnginxに手を出してみました。
それぞれの違いは以下の解説が丁寧です。
バックエンド
PHP
サーバーサイドの言語は一番触れることになるであろう言語なので慎重に選定する必要があります。新しい技術を取り入れるには学習コストが高すぎるので、私の場合は職場で使用していたJavaかWordPress版の知見があるPHPです。
今回はWordPress版のソースコードをそのまま流用することも視野に入れて、PHPとしました。
ちなみに、フレームワークはLaravel、デバッグはXdebug使用してます。
フロントエンド
JSライブラリ
jQueryを使用せず、素のJSとすることにしました。格好良く表現するとVanilla JSです。
jQueryは私が新人の頃に2,3件目の案件で触っていたことや、その時のOJTの先輩はとにかく手取り足取りとても丁寧に指導していただけたこともあって、思い出深い技術です。
ただ、いざ調べてみると「jQuery オワコン」なんてサジェストが出てしまったり、ReactやVueが台頭する現在、トレンドでは無いことを知ってしまいました。
結局のところ自身に合う技術かどうかが大事なのですが、今一度原点に立ち返り、Vanilla JSとすることにしたのでした。
CSS
職場ではBootstrapが主に使用されていましたが、今回改めて調査し、Tailwind CSSを採用しています。 Tailwindだけでも十分便利なのですが、Tailwindを使用した部品が既にできているPrelineも使用します。デザインの工数はこういった既存コンポートの使用で削減させてます。
データベース
MySQL
職場で主に使用していたのはMySQL、PostgreSQLでしたが、流用や移植を考え、WordPressでも採用されているMySQLを採用しています。
phpMyAdmin
同じくWordPress運用時に使用していたphpMyAdminですが、後述するデータベース操作ツールもあり、途中から不要になったため削除しました。
本番環境としてphpMyAdminも公開する場合はセキュリティ面やドメイン、証明書を考慮する必要があり、コストとリターンを考慮し、無くても問題ないと判断しました。
ホスティング
Xserver、ConoHa、さくらのレンタルサーバーなど大手VPSから選びました。
正直ここは好みの問題で、どれを採用しても特に問題ないと思います。
監視設定
zabbixを立てても良かったのですが、よほど盛り上がるサービスに成長しない限り、死活監視やリソース監視まで行う必要性は無いと判断し、AppmillではURL監視、証明書の期限監視を行っています。
開発環境
Windows10
11じゃないのかよ、と突っ込まれそうですがプライベートPCなので…。
WSL(Ubuntsu)
Dockerを使用しますが、Dockerは本来Linuxベースで動作する技術ですので、Windows上では仮想Linuxを立ち上げる必要があり、その際にWSLを使用します。WSL用のUbuntsuはMicrosoft Storeからインストール可能です。 Macを使用する場合、WSLは不要になります。
Docker for Desktop
コンテナが管理できるGUIツールです。WindowsやMacで開発するのであればほぼ必須です。
Docker(docker-compose)
コンテナ技術の解説は既に多く出回っている記事に任せます。
本体マシンに影響させたくないことや後々開発に協力してもらえる人を集うことを想定し、環境が配りやすいDockerを採用しました。
VScode
拡張機能でDockerやWSLへアクセスすることができるなど利便性から採用しています。
PHPや今回規模のフロントの開発であれば十分と思います。
VScode拡張機能
今回導入した拡張機能です。
- Dev Containers
- WSL
- Remote Development
- docker
- Git Graph
- GitLens
- Japanese Language Pack for Visual Studio Code
- PHP Debug
- Laravel Extention Pack
- Tailwind CSS IntelliSense
- Draw.io
- Markdown Table
git(GitHub)
ソース管理はGitHubを使用しています。
VScodeに拡張機能を導入することでVScodeからのアクセスや樹形図の確認も可能です。
A5 Mk-2(データベース操作ツール)
データベースに接続することができるツールです。
phpMyAdminを不採用としたのはこのツールがSSHトンネリングを使用したデータベースアクセスが可能なためです。
SSHトンネリングを使用した接続については後述します。
開発プロセス
開発の流れ
個人開発ですので、厳密に組む必要はないのですが、当てもなく取り掛かるのも無謀なので、大きく以下の順で進めました。
- 開発環境構築
- ルール整備
- 基本・詳細設計(画面設計、機能設計、DBテーブル設計)
- 開発
- テスト
- リリース
- 周知
- 次回以降の機能改善へ向けたメンバー募集
- アウトプット(イマココ!)
本記事はアウトプットフェーズにあたります。ようやく…
ルール整備
自分自身が忘れないためだけでなく、今後のメンバー募集を見据えて管理する上での管理資料や、ルール/思想を整備します。
スケジュール管理
VScodeにてマークダウン形式で表を作成し、git管理していましたが、今後開発人数が増えた場合にgitでの管理は現実的では無いので、途中からGoogleスプレッドシートに変更しています。
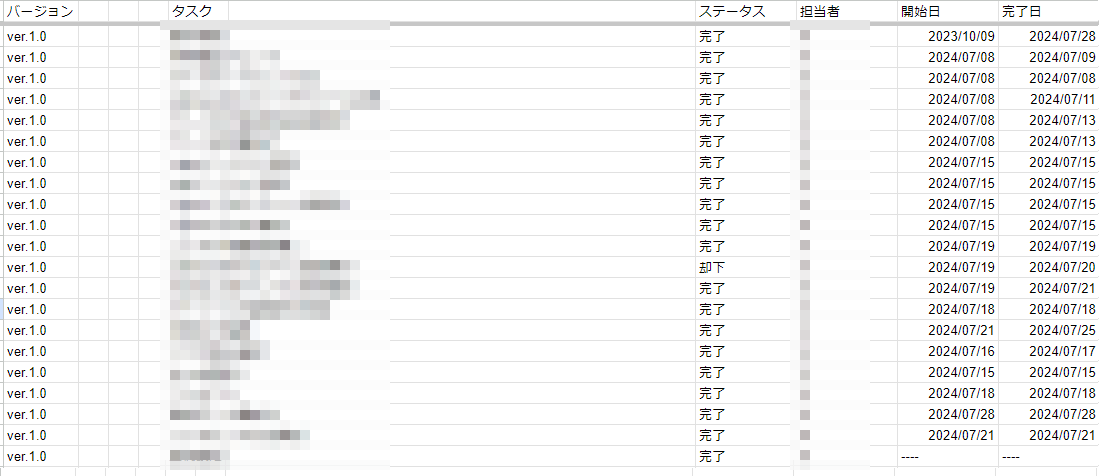
ステータスをプルダウン管理できたり、エクセルライクの使用感で、デスクワーク経験者なら違和感なく触れると思います。
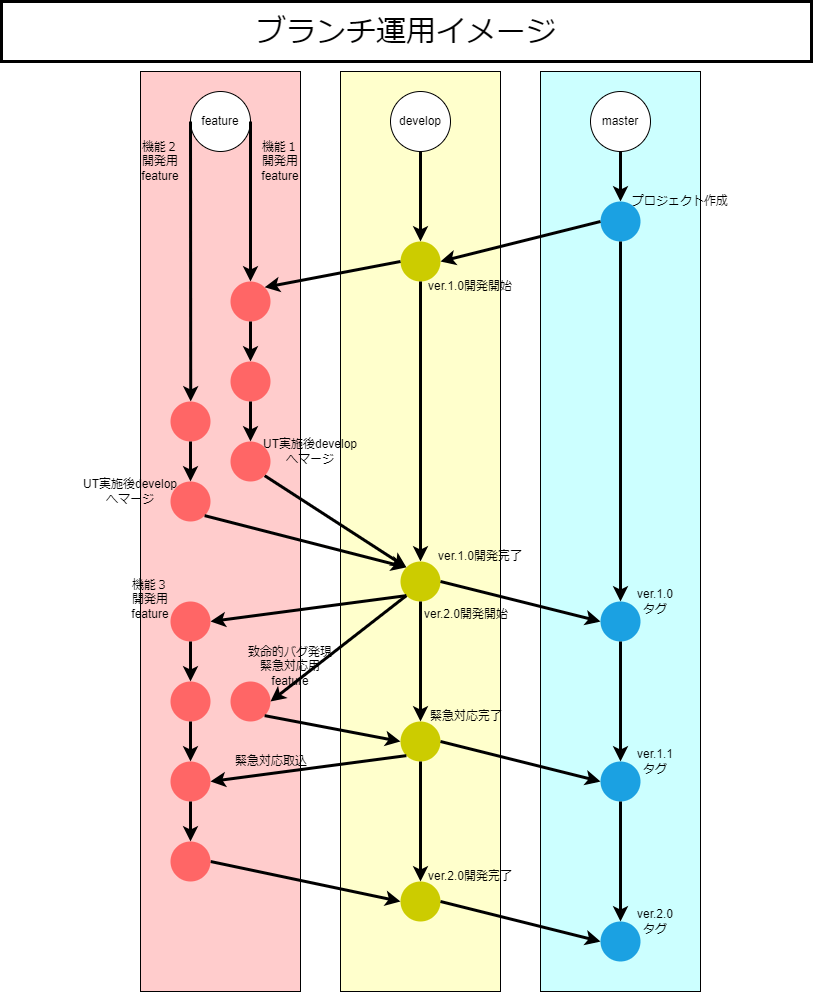
ブランチ戦略
ブランチの運用ルールの前にどんなブランチを用意し、どんな用途とするかを決めます。
既に先人に知恵からいくつか思想が用意されているため、これらから採用します。
職場では専らGit-flow型でしたが、今回の小規模な開発にはhotfixやreleaseブランチは不要と判断し、GitHub flow型を採用します。
GitHub flowより今回のプロジェクトでは以下のような運用とします。
テスト
工程として当然設けていましたが、個人開発でテスト仕様書なんてつまらなすぎて作成してられません。結果、メモ程度のパターンを用意し手動で結果を見ていました。
理想はCI/CDとして、GitHub Actionを使用し、自動テストをまわすことでしたが、これは次回開発以降の課題とします。
余談ですが、テスト技法はJSTQBのシラバスが参考になります。
次回以降の機能改善へ向けたメンバー募集
知らない人に募集をかけるわけにはいきませんので、前述した共同運営ブログのメンバーに声を掛けてみました。
少人数体制の仕事外での開発ということもあり、管理面では仕事とはまた別な考え方が必要になりそうです。また、環境構築など前提となる知識ドキュメントの整備、コーディング規約などルールの整備が急務で、個人開発が故にクオリティを捨てていた点が浮き彫りになりました。
やっぱり一人でもドキュメント整備はチャントシナイトネ…
知見と工夫
さて、技術記事の本題です。今回得られた知見や工夫を解説します。
テーブル設計(データの持たせ方)
可能な範囲で公開します。

主に使用しているのはproducts、softwares、sub_softwares、platformsの4つのテーブルになります。
productsテーブル
ゲームソフトは全てproductsテーブルに収録されており、検索もproductsテーブルに対して行います。今後ゲームソフト以外の検索も行えるようにするためこのような構成になっており、productsテーブルにはゲーム機(ゲームソフトではなくゲーム機自体)、玩具など同社が発売している他の分類の製品も収録する予定です。モザイクを掛けていないconsolesテーブルはその構想の一環です。
softwaresテーブル
produtcsテーブルのうち、ゲームソフトはsoftwaresテーブルに紐付けることで、ゲームソフトであることを判断します。また、platformsテーブルとも紐付け、そのゲームソフトがどのゲーム機(プラットフォーム)にてプレイできるソフトであるかの情報を付与します。
platformsテーブル
consolesテーブルがあるのにこのテーブルは必要?と思われるかもしれませんが、ゲーム機に直接紐付けられないゲームソフトも多々存在します。
例えば、WiiではWiiウェアというサービスが展開されていました。Wiiに直接紐付けてもいいのですが、より詳細に検索したいので、Wiiウェアに紐付けたいです。ただ、Wiiウェアはゲーム機ではありませんので、consolesテーブルに収録した場合、ゲーム機の検索を行った際にこれらのサービスもヒットしてしまいます。
より厳密にゲーム機のみ、ゲームプラットフォームのみに絞るためconsolesとplatformsを分けました。
consolesテーブル
現時点では使用していませんが、前述したとおり後々ゲーム機自体も検索できるようにする予定でその際に使用します。
sub_softwaresテーブル
さて、これが一番厄介です。
パッケージ版とダウンロード版の存在
ニンテンドー3DS以降、同ソフトに対して販売形態が大きく2つ採用されています。
困ったことに私自身がパッケージ版とダウンロード版も分けて検索したいので、productsテーブルもしくはsotwaresテーブルで実現するためにはフラグが必要になりそうです。
ですが、さらに困ったことにパッケージ版とダウンロード版で発売日が異なるパターンが稀に存在します。
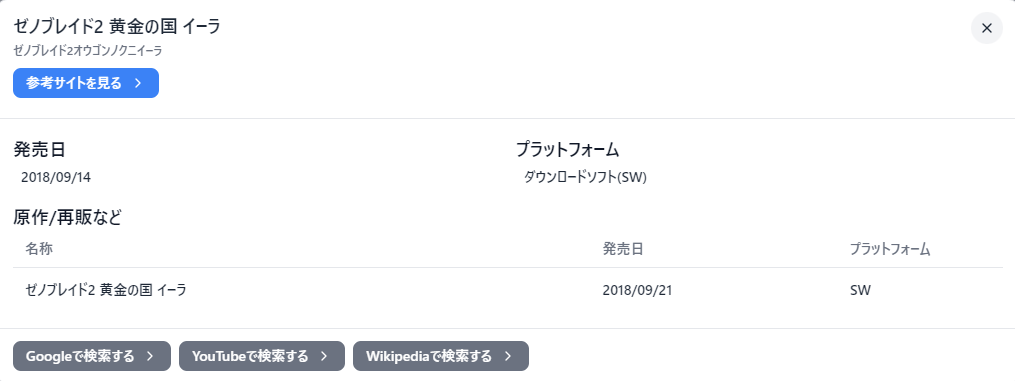
テトリス99やベヨネッタ、ゼノブレイド2 黄金の国イーラ、NewスーパールイージUなどなど

発売日が別である以上、別レコード管理が必須で、同じソフトであるにも関わらず、最低2レコードできあがってしまいます。
これらを別出し管理するために用意したのがsub_softwaresになります。
上記ゼノブレイド2 黄金の国イーラを例にすると
9/14発売のダウンロード版をsoftwares、9/21発売のパッケージ版をsub_softwaresに登録し、2つのデータを紐付けます。
この紐付きによって原作や再版を取得させます。↓実際の画面
パッケージ/ダウンロードを例に解説しましたが、この他にもバリューセレクション、ハッピープライスセレクションなどの再販系、バーチャルコンソールなどアーカイブ系も存在し、本テーブルの用途は多岐に渡ります。
さらなる懸念
実は今回用いた構成でもカバーできていないケースが1つ存在します。
それは前後編作品です。
ファミコン探偵倶楽部、ふぁみこんむかし話などディスクシステム時代に存在した、前編と後編で別々のゲームソフトして発売されたシリーズです。
これらは移植版が前後編として1本にまとめられているため、sub_softwaresのレコードに対してsoftwaresの前編と後編の両方を紐付けるのが理想ですが、現状の構成では1本しか紐付けられないため、前編を優先し紐付けています。
全てカバーしたつもりでいたのですが、データコンバート中に気付いてしまい、初期リリースでは対応を諦めています。
Docker
開発環境と本番環境で使用するdocker-composeを変更
docker-compose.ymlは必ずしも1つのファイルしか使用できないわけではなく、複数ファイル指定可能です。
起動の際はオプションfを使用します。
docker-compose -f <ファイル名> -f <ファイル名> up -d
ということで、docker-compose.ymlは以下の3種類準備しました。
- docker-compose.yml(開発、本番共通)
- docker-compose.dev.yml(開発)
- docker-compose.prod.yml(本番)
開発、本番で設定ファイルを別管理とすることができ、開発状態のまま本番リリースしてしまうことを防ぎます。
例に当てはめ、以下のようになります。
docker-compose -f docker-compose.yml -f docker-compose.dev.yml up -d
本番サーバーの場合は後半のdocker-compose.dev.ymlをdocker-compose.prod.ymlに置き換えて実行します。
コンテナ同士のネットワークの設定は最小限に留める
実際の業務ではアプリケーションサーバーとデータベースサーバーは分けることが多いです。
今回はそこまで大きなサービスではありませんし、個人開発なのでサーバー台数を増やすことも避けたいです。
そこで、今回はdocker内のカスタムネットワークを使用し、nginxとmysqlを別ネットワークとしました。
以下は設定例です。
# カスタムネットワーク
networks:
internal:
driver: bridge
external:
driver: bridge
externalネットワークにnginx/phpのコンテナ、internalにphp/mysqlのコンテナを接続することで、矢面に立つnginxコンテナが乗っ取られた場合でもmysqlに直接アクセスされることを防ぎます。
phpは両者と通信を行うため、どちらにも接続させます。
コンテナの実行ユーザーをroot以外に設定
ネットワークに関連し、ユーザーの設定も見直します。
まず、大前提としてコンテナ内のプロセスの実行ユーザーはrootがデフォルトとなります。もし、コンテナを乗っ取られた場合、rootユーザーを使用して良からぬことをされてしまう可能性があり非常に危険です。
nginxの場合、ユーザーはdocker-compose.yml内で以下のように指定します。(www-dataも可)
user:
"nginx"
他のサービスコンテナも同様にrootの次にマスタープロセスを持つべきユーザーがコンテナの実行ユーザーとなるように設定します。
ホストマシンへのボリュームマウントを行っていない場合はこれで起動可能です。
ただ、nginxの場合、ホストマシン側で設定ファイルを持ち、コンテナから設定ファイルをマウントする構成が一般的だと思いますので、この指定だけでは起動できません。
ホストマシン側にある設定ファイルの権限をコンテナ側のユーザーが持っていないためです。
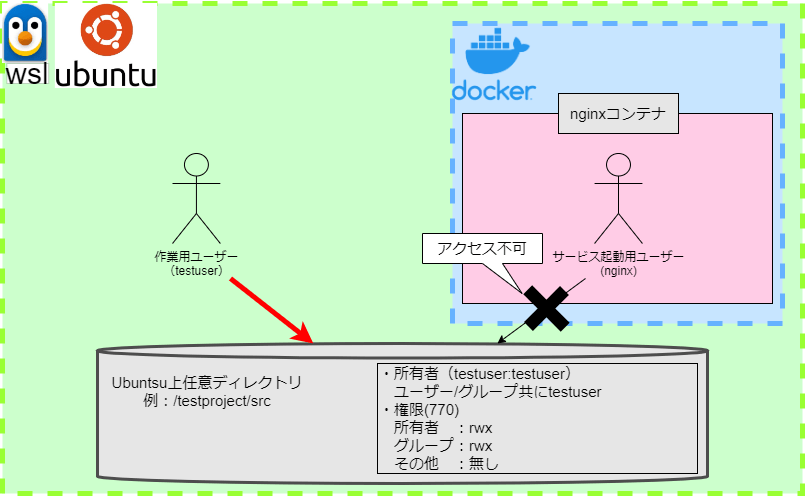
そこで、ホストマシン、コンテナ双方でユーザーIDと名前が同じとなるユーザーを作成しました。下図のdockeruserが当該ユーザーとなります。
そして、ホストマシン、コンテナそれぞれの作業ユーザー、実行ユーザーをdockeruserと同じグループに所属させ、触りたいファイルの権限をグループユーザーも触れるよう設定します。
実行権限まで付与するかは対象ファイル次第ですが、開発環境での作業であれば所有者、グループユーザー共に同じ権限で問題ないと思います。本番では見直しましょう。
以上の設定を反映した図が下図になります。
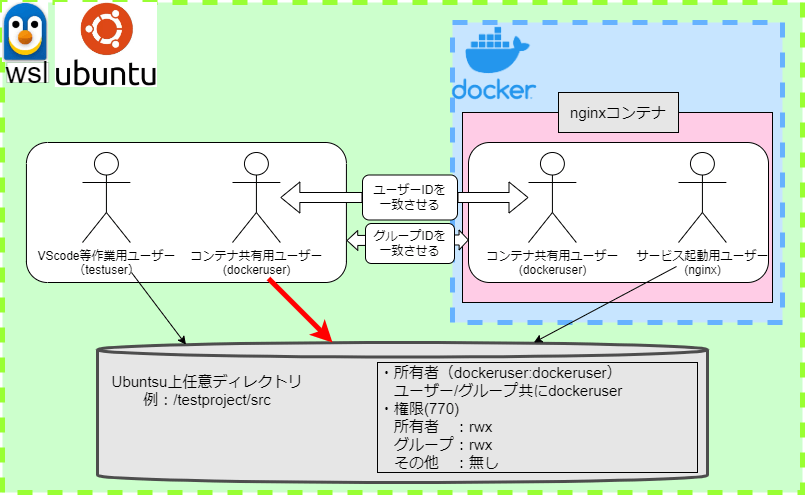
ちなみに、設定後コンテナにログインし、ps -auxなどでプロセスを確認すると以下のようになります。
master processがrootから任意のユーザーに切り替わっていれば成功です。

PHP
使用バージョンの隠蔽
使用バージョンはブラウザの開発者ツールやChromeの拡張機能「Wappalyzer」を使用すると簡単に閲覧できます。攻撃者の足がかりになるので、隠しましょう。
今回のような構成(nginx + php-fpm構成)の場合はnginx側でバージョンの隠蔽を行います。
default.confやnginx.confなどnginxの設定ファイルに以下の設定を差し込みます。
server{
location / {
fastcgi_hide_header X-Powered-By;
}
}
HTML
OGPタグの準備
WEB業界の方なら聴き馴染みがあると思いますが、聞き慣れない方も多いかもしれません。
SNSなどで共有する際にURLを入力すると表示される画像やタイトル、詳細情報を指します。
headタグ内にog:XXXとして指定することで表示可能です。

DB
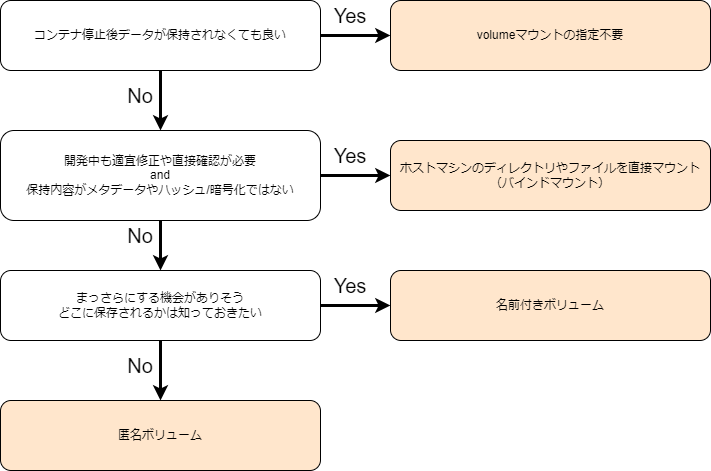
データの永続化
dockerはコンテナを削除するとデータも合わせて消えてしまいます。
そこで、ホストマシン上の特定のディレクトリやファイル、docker管理下のストレージ領域のどちらかにマウントすることで、データを永続化することができます。
また、docker管理下ストレージ領域は名前付きボリューム、匿名ボリュームのどちらかを選択することができます。
私は以下のような判断の仕方をしていました。フローチャート作ってみたので、ご参考までに。
docker-compose.yml上の記述は以下のようになります。
services:
db:
container_name: "mysql"
# ボリュームを設定する(名前付きボリューム:コンテナ側ボリュームの場所)
volumes:
- db_data:/var/lib/mysql
php:
container_name: "php"
# ボリュームを設定する(未指定(匿名ボリューム):コンテナ側ボリュームの場所)
volumes:
- /src/vendor
nginx:
container_name: "nginx"
# ボリュームを設定する(ホスト側ディレクトリ:コンテナ側ボリュームの場所)
volumes:
- ./src:/var/www
# 名前付きボリューム
volumes:
db_data:
nginx
return 444
nginxに触れて初めて知ったリターンコードです。nginx独自のリターンコードだそうです。
接続を切断するリターンコードで、相手側には接続結果やリターンコード自体表示されず、サーバーまで到達したのかさえ伝わらないため、一切の情報を与えずに済みます。
例えば、同じ400系の404が返ってしまうとページはないもののサーバーの存在自体は相手には伝わってしまうため、他の手段でのアクセスを試みられる可能性があります。
よって、接続を拒否する場合にはreturn 444を設定するのが適切になります。
80→443リダイレクト設定
http→httpsへのリダイレクトを施し、予期せぬhttpアクセスを防ぎます。
server {
listen <http受付ポート>;
server_name <サイトURL>;
return 301 https://$host$request_uri; #リダイレクト設定
}
IPアドレス直打ちのアクセス拒否
攻撃者はbotでIPアドレスでのアクセスを試みるケースも多いらしいので塞ぎます。
一般の方がIPアドレスでアクセスしてくることはほぼ無いので、拒否してしまっても困らないでしょう。
server {
listen <http/https受付ポート> default_server;
server_name <サーバーのグローバルIP>;
return 444;
}
使用バージョンの隠蔽
PHPと同様にサーバーバージョンを隠蔽します。
クリックジャッキング対策
nginxの設定ファイルに以下の記述を追加します。
add_header X-Frame-Options SAMEORIGIN;
ログローテーション
今回はコンテナ内でのローテーション、ホストマシンでのローテーションの二段構えとしてます。
コンテナ内でのローテーション
docker-compose.yml内でログローテーションの設定を行うことで、コンテナ内でのログの肥大化を防ぎます。
この設定をしていない場合、コンテナ起動中のログが蓄積され続けてしまいます。
nginx:
container_name: "nginx"
# ログの設定
logging:
driver: "local"
options:
max-size: "10m" #10MBになったら退避
max-file: "3" #最大3ファイルまで保持
本来であれば肥大化の防止、世代管理を実現する機能なのですが、世代管理は次項ホストマシンでのローテーションにて実現できているため、実質肥大化を防止するためだけの設定になります。そのため、max-fileは1としても問題ないのですが、念のため3世代残しています。
ホストマシンでのローテーション
PHPやMySQL、nginxなど名の知れたサービスはほぼ確実に公式のコンテナイメージが用意されています。
この公式イメージを使用している場合、コンテナのログはシンボリックリンクで標準出力へ流されているケースがほとんどです。

標準出力へ流されている場合、以下のコマンドにてホストマシン側からログを確認することができます。
docker logs <コンテナ名>
ただ、毎回dockerコマンドで確認するのは面倒。かといってコンテナにログインにして確認するのも面倒です。
そこで、ホストマシン側で管理すべく、docker logsコマンドを使用して、出力内容を6時間おきに差分だけ抽出することにしました。
まずは、差分を出力するシェルを作成します。
#!/bin/bash
CONTAINER_NAME=${1}
# 引数未指定の場合
if [ "$CONTAINER_NAME" = "" ]; then
echo "コンテナ名を指定してください"
exit 1
fi
LOG_DIR="/var/log/dockerapp"
LOG_FILE="$LOG_DIR"'/'"$CONTAINER_NAME"'.log'
TMP_FILE="$LOG_DIR"'/'"$CONTAINER_NAME"'_tmp_logs.log'
LAST_LOG_FILE="$LOG_DIR"'/'"$CONTAINER_NAME"'_last_logs.log'
# Dockerコンテナが起動しているか確認
if ! docker ps --format '{{.Names}}' | grep -q "^${CONTAINER_NAME}$"; then
echo "$(date) - 対象コンテナが起動していないため、出力をスキップします" >> $LOG_FILE
exit 0
fi
# Dockerコンテナのログを一時ファイルに出力
docker logs --since "$(date --date='12 hours ago' +%Y-%m-%dT%H:%M:%S)" $CONTAINER_NAME > $TMP_FILE
# LAST_LOG_FILEが存在しない場合は作成
if [ ! -f $LAST_LOG_FILE ]; then
touch $LAST_LOG_FILE
fi
# 差分のみを取得しログファイルに追記
diff $LAST_LOG_FILE $TMP_FILE | grep "^> " | sed 's/^> //' >> $LOG_FILE
# 一時ファイルを最新のログファイルとして保存
mv $TMP_FILE $LAST_LOG_FILE
log_extraction.sh nginxなどコンテナ名を引数として与えることで、そのコンテナのログを前回取得分からの差分のみ抽出してくれます。
これを6時間毎に実行するようcronを設定すれば完了です。nginx、phpコンテナのログを残すようにしてみました。
0 */6 * * * <任意のディレクトリ>/log_extraction.sh nginx
1 0,6,12,18 * * * <任意のディレクトリ>/log_extraction.sh php
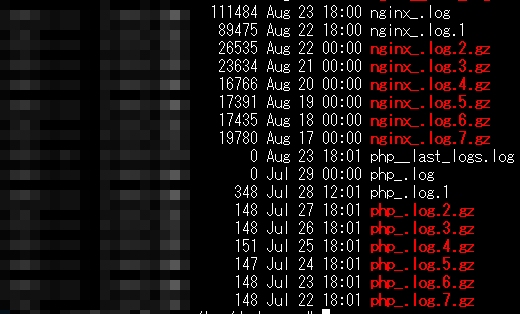
世代管理は/etc/logrotate.dにdockerappなど任意の設定ファイルを作成します。
cd /etc/logrotate.d/
vi dockerapp
/var/log/dockerapp/*.log {
daily
rotate 7
compress
delaycompress
missingok
notifempty
create 0640 root utmp
sharedscripts
postrotate
/usr/bin/systemctl reload docker > /dev/null 2>&1 || true
endscript
}
7世代分のログが保持されるようになりました。
メンテナンスモードへの切り替え
PHPに対して追加機能を反映する間、開発者の自宅からのアクセスを除いた全てのアクセスをメンテナンスページへ流すことで、利用者にメンテ中であることを周知します。
今回はメンテナンスページ(maintenance.html)の有無に合わせて切り替わるように設定しました。以下の通りです。
# 接続許可IP
geo $access_from {
default external;
<自宅環境のグローバルIP> internal;
}
error_page 503 @maintenance;
set $maintenance false;
# メンテナンスファイル存在確認
if (-e <rootディレクトリ>maintenance.html) {
set $maintenance true;
}
if ($access_from !~ external) {
set $maintenance false;
}
if ($maintenance = true) {
return 503;
}
location @maintenance {
root <rootディレクトリ>;
rewrite ^(.*)$ /maintenance.html break; #全てのURLをメンテナンスページへ誘導
}
これでmaintenance.htmlが存在する場合はメンテナンスページが表示されます。
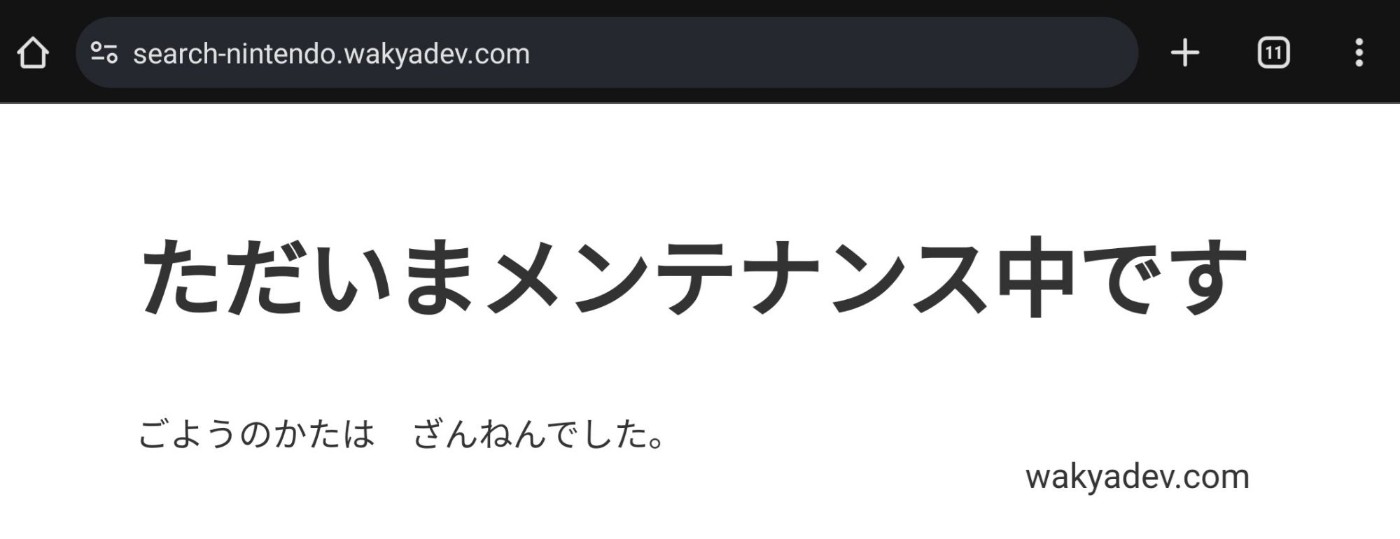
メンテナンス解除はmaintenance.htmlのファイル自体をリネームしてしまえばmaintenance.htmlが存在しないと判断され利用者も通常ページへアクセス可能になります。
VPS
SSH接続
VPS側で用意しているWebブラウザ上のコンソールを使用しても良いのですが、今回は開発端末からteratermでSSH接続します。
サーバーコンソールから以下のファイルを開き設定変更を行っていきます。
vi /etc/ssh/sshd_config
設定は以下の記事のSSHサーバの設定の項を参考にさせていただきました。記事の内容の通りに鍵を作成するところまで進めます。Ubuntsu、VPSのファイアウォールも適宜変更してください。
また、adminユーザとなっている箇所は任意のユーザを指定してください。
完了後、作成した鍵を使用してteratermで接続します。


ログインできれば成功です。
SSHトンネリングでDBに接続
SSH接続を確立できたので、SSHトンネリング(ポートフォワード)を使用してDBへのアクセスも試みます。前述の通りA5 Mk-2に備え付けられている機能を使用します。
まずは基本タブよりデータベースの情報を入力します。
この時入力する情報はSSHで対象サーバーにログイン後のデータベースへの接続になるため、ホスト名、ポート番号はローカルを想定して入力してください。
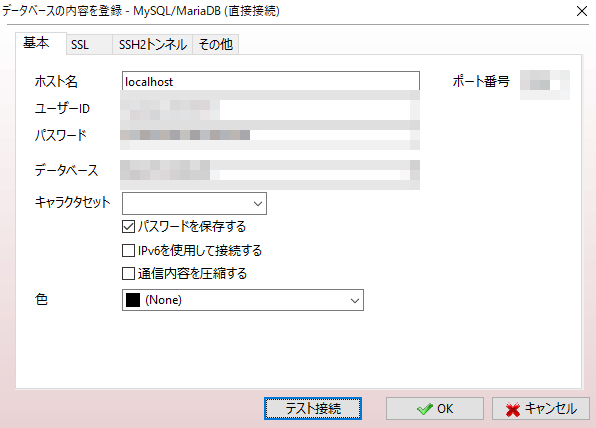
ホスト名:localhost
ポート番号:3306(変更している場合は任意のmysql用ポート)
ユーザーID:作成したmysqlログイン用ユーザー
パスワード:mysqlログイン用ユーザーのパスワード
そして、SSH2トンネルタブよりSSH接続に使用する情報を入力します。こちらはローカルではなく、外部からの接続になります。

SSH2ホスト名:レンタルサーバーより与えられているホスト名
ポート番号:22(変更している場合は任意のSSH用ポート)
ユーザーID:SSH接続用ユーザー
パスフレーズ:秘密鍵ファイルに設定したパスフレーズ(ユーザーのパスワードでは無いことに注意)
秘密鍵ファイル:作成した秘密鍵ファイルを指定
以上の設定でホストマシンからSSH接続を行い、接続先サーバー内でSSHポートからMySQL用ポートへポートフォワードが行われ目的のデータベースへ接続されます。
証明書
無料証明書のLet's Encryptを使用しています。有効期限は90日間になりますが、個人開発には何より無料がありがたいので、選択肢はほぼありません。
証明書の発行は以下の記事を参考にしました。
発行後、nginxに対して証明書を適用する必要があります。
4つ発行されますが、nginxの場合はfullchain.pem、privkey.pemを適用すれば問題ありません。
コンテナを停止してもデータが削除されない場所に移動するか、自動作成されるletsencryptフォルダを匿名ボリュームと紐づけましょう。
server {
listen <任意のhttpsポート> ssl;
server_name search-nintendo.wakyadev.com
~中略~
# SSL証明書
ssl_certificate /etc/letsencrypt/<任意ドメイン>/live/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/<任意ドメイン>/live/privkey.pem;
~中略~
}
発行後は期限となる90日後までに証明書を更新する必要があります。
上述したAppmillを導入している場合、期限の1ヶ月前にメールで通知がきます。

更新については、下記記事をご覧ください。 完全自動化とまではいきませんが、簡略化はできています。
その他
AIを使おう
ありがたいことに現職ではAI(ChatGPT)をどんどん使おうの方針で、日頃から使用しています。
これは今回の開発にも言えることで、個人開発で詰まるポイントは調べても解消法に辿り着けないケースも珍しくなく、ChatGPTには非常に助けられました。
実は今回のアウトプット記事の構成もChatGPTに考えてもらったものです。
こんなフワッとした指示でもしっかりとカタチにして返してくれるので、何から手を付けたらいいか分からない、何が分からないのか分からない状態でも足掛かりにはなり、今ではなくてはならない存在です。

さいごに
今回の計画の作業開始は2023年10月頃で、当初はお正月明けまでの完成を目指していました。
…が、タスクを洗い出したり技術調査をしているとどう考えても現実的ではなく、2024年秋まで期間を延ばしています。結果的にサービス公開は7月下旬で開発期間は約10ヶ月となり、前倒しで完了できました。
これは、区切りの良いところまで進めようと思った結果、止め時が見えず、日々それなりの時間を掛けてしまった結果だと思ってます。
個人開発は納期や監視の目がなく、ダラダラと進めてしまうことになります。
そもそも実績の無い個人が作成するサービスの公開を待ちわびている人なんて自分1人しかいないわけで、他者からの期待など背中を押してくれる要素もなく、サボったりしてしまって当然です。
サボってしまうからこそ、どんなに簡単なアプリでもそれなりに自分にムチを打つ必要があり、やはり気合いは必要だと思いました。
この記事の通り個人開発は考えることが多岐に渡るため、とても勉強になります。
機能改修は続けていこうと思っているので、温かく見守っていただければと思います。
改めてこちらです。
以上です。長文にお付き合いいただきありがとうございました。
参考
技術選定や環境構築にあたり、以下の記事を参考としました。ほかにも色々調べながら進めましたが、特に何周も読み直した以下の記事は本当にお世話になりました。
Discussion