Detectron2で自作データを学習し物体検出をしてみた【インスタンスセグメンテーション】
インスタンスセグメンテーションってなんぞ?
みんなさ,一度は画像から物体を判別したいって思ったこと,あるじゃん?(ない)
そんな時に使えるのがインスタンスセグメンテーション。
インスタンスセグメンテーションは下の画像みたいに個々に物体をピクセル単位で検出できるものやねんな。
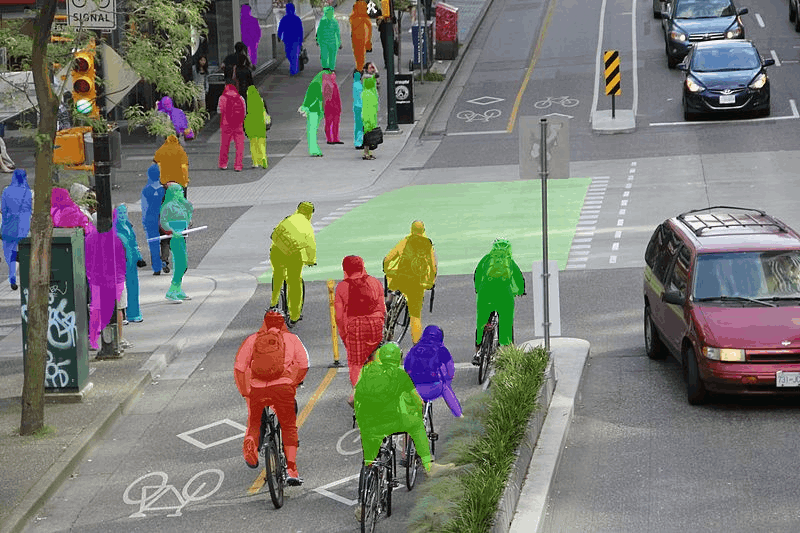
こちらの論文によると,インスタンスセグメンテーションとは個体ごとに領域分割する 隣接した 同種類の物体(例えば前の車と後ろの車)を区別できると説明されているねん。
セマンティックセグメンテーションも種類ごとに判別することができるけど,犬1と犬2を区別することができないのよね。なので種類だけでなく物体ごとに検出したい場合はインスタンスセグメンテーションが有効やねんな

Detectron2ってなんぞ?
Detectron2とはFacebook AIが開発した、PyTorchベースの物体検出のライブラリです。 様々なモデルとそのPre-Trainedモデルが実装されており、下記のように、Bounding boxやInstance Segmentation等の物体検出を簡単に実装することができます。
今回はこのDetectron2でインスタンスセグメンテーションを行っていくよ。
公式で用意されたGoogleColabratory上ではデータセットなどや基本的なコードがすべて用意されているため簡単にDetectron2のチュートリアルを行うことができます。
ブラウザでササっと試せるのがかなりありがたい!
今回のゴール
| 元画像 | 検出画像 |
|---|---|
 |
 |
今回のゴールは自分で用意した画像を学習させ,未知データを予測し葉っぱを検出すること!
環境構築が大変なのでGoogleColabratory上で行います。ローカルで動かすことができるとカメラをつなげたり様々なカスタマイズができるので良かったら試してみて下さい!
全体の流れ
- 画像データの用意
- アノテーション(学習データの作成)
- 学習
- 予測
画像データの用意

自分で撮影した植物の写真を学習用に10枚用意しました。(10枚でも精度がそこそこ良かった)
より増やせば精度の向上は,あると思います(天津木村)
アノテーション
アノテーションとは画像に「ここの部分は葉っぱやで」のようにデータ(今回は画像)に情報を付与することを指すよ。
今回は葉っぱ一枚一枚を検出したいため以下のようにアノテーションを行いました。
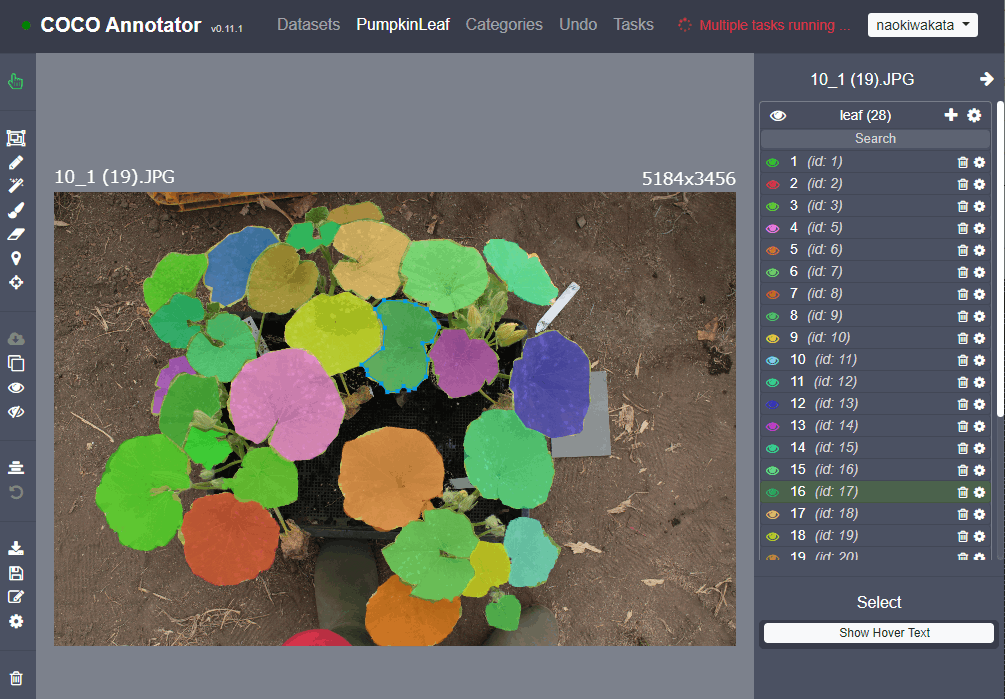
Detectron2ではCOCOフォーマットという形式をサポートしているのでアノテーションツールはcoco-anotatorというものを用いました。
こちらの導入にはDockerが必要で,その環境構築に手間取られました。
画像10枚のアノテーションが終わった後にCOCOフォーマットのjsonファイルをダウンロードすることができます。jsonファイルはあとで学習に用います。
有名なアノテーションツールのlabelmeではCOCOフォーマットに対応していないものの
labelmeからCOCOフォーマットに変換するものもあるみたいです。普段からlabelmeを使用している方は試してみてください!
参考記事
こちらの記事がとても参考になりました。
自作データでやりたい場合は,自分で用意した画像データとアノテーションで作成したjsonファイルを置き換えればできます!
訓練
データセットの登録
自分で作成したjsonファイルと画像フォルダを指定
from detectron2.data.datasets import register_coco_instances
register_coco_instances("leaf", {}, "-COCOフォーマットのjsonファイルのpath-", "-画像フォルダのpath-")
学習
設定を決めるがほとんどデフォルトで使用しています。
cfg.MODEL.ROI_HEADS.NUM_CLASSESはクラス数で,今回は葉の1クラスのみなので1と設定。
from detectron2.engine import DefaultTrainer
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.DATASETS.TRAIN = ("leaf",)
cfg.DATASETS.TEST = ()
cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml") # Let training initialize from model zoo
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025 # pick a good LR
cfg.SOLVER.MAX_ITER = 300 # 300 iterations seems good enough for this toy dataset; you will need to train longer for a practical dataset
cfg.SOLVER.STEPS = [] # do not decay learning rate
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # faster, and good enough for this toy dataset (default: 512)
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # 1クラスのみ
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()
学習が完了するとmodel_final.pthという学習モデルのファイルが保存されます。
これを予測の時に用います。
予測
予測器を作成
cfg.MODEL.WEIGHTSには先ほどの学習で作成したmodel_final.pathを使用します。
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # 1クラスのみ
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "/content/drive/MyDrive/PumpkinLeaf/model_final.pth")
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.6
cfg.MODEL.DEVICE = "cpu"
predictor = DefaultPredictor(cfg)
予測と表示
予測器を用いて未知の画像を判別させます
from detectron2.utils.visualizer import Visualizer
import cv2
imgPath = "未知画像のpath"
im = cv2.imread(imgPath)
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1],
metadata=leafs_metadata,
scale=1.0
)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(v.get_image()[:, :, ::-1])
結果
見事予測結果が表示されました!学習データが10枚でもかなりの高精度で検出できていたのでかなり使い勝手が良いなと感じました!
次回はReact側から画像を送ってFlask側で機械学習をするという記事を書こうと思います!
GoogleColabratory
僕が書いたDetectron2のコードです。参考になれば幸いです!
Discussion
こんにちは、興味深い記事をありがとうございます。
ColabのDetectron2コードが、Colab側のtorchバージョンアップに伴いdetectron2インストール
ができなくなっているようです。以下のコマンドでtouchのバージョンを下げるとインストールできるようです。コマンドを実行後、[ランタイム]→[ランタイムを再起動]をする必要があります。
ご参考まで。
ふじさわさん
情報ありがとうございます!
私もちょうど昨日detectron2を使おうとして、これで詰まってしまったので、教えていただきありがとうございます!!