【個人開発 #1-5】レコメンドシステムを作ってみた vol.5 〜処理の実装〜




作りたいシステム
忙しい人のためのギフト提案型 AI「AiSAP!(エイサップ)」
忙しい社会人のために、AI が可能な限り素早く(ASAP: As Soon As Possible)、最適なギフトを提案してくれる Web サービス。
今回は処理の実装について説明していきます。
今回で最終回となります。
フォルダ構成
前回作成したフォルダ構成は下記のようになっています。
.
├── app.py
├── recommender.py
└── data
├── item.csv
├── rating.csv
└── recipient.csv
データの作成(csv ファイルの作成)
まずはこちらで設計した、item, recipient, rating の 3 つのテーブルを csv ファイルで作成し、data フォルダ内に格納します。
下記リンク先の Github にサンプルを載せているのでダウンロードし、data フォルダ内に格納してください。
処理の実装
次はいよいよ処理の実装に入ります。
いくつかのステップに分けて説明していきます。
1. 検索ボタンをトリガーに設定(app.py)
検索ボタンを押下した時に、レコメンドシステムが動くように設定します。
下記のようにボタンを if 文の条件にして、中に処理を書くとボタンがトリガーとして設定されます。
処理の内容としては、get_recommendations 関数(自作関数)でおすすめ商品を検索し、
取得した結果を for 文でループさせて、上位 3 商品のリンクと価格を表示しています。
# 検索ボタン押下時の処理
if st.button("検索"):
# おすすめ商品を検索
recommended_items = get_recommendations(searchReqList)
# 取得した結果から上位3商品を表示
for index, item in enumerate(recommended_items):
link = f'[{index+1}.{item[0]}]({item[2]})'
st.markdown(link, unsafe_allow_html=True)
st.write(f'{item[1]}円')
また、get_recommendations 関数は recommender.py にて作成するので、app.py に import 文を書いておきます。
from recommender import get_recommendations
2. 受け取り手タイプを特定(recommender.py)
recommender.py を編集していきます。
まずはレコメンドを実行する get_recommendations 関数を定義して、引数に searchReqList を設定します。
これは、app.py から受け取る、画面で入力した検索条件が入ったリストです。
そして、入力した検索条件と合致する受け取り手タイプを recipient テーブル(ここでは csv ファイル)から探し、変数 recipient_type に格納します。
どんな相手に渡すのかを特定するわけです。
def get_recommendations(searchReqList):
# 受け取り手データの読み込み
recipient_data = pd.read_csv('./data/recipient.csv')
# 受け取り手タイプをチェックする
recipient_type = 0
for index, data in recipient_data.iterrows():
if searchReqList[0] == data["sex"] and searchReqList[1] == data["age_group"] and searchReqList[2] == data["relationship"] and searchReqList[3] == data["scene"]:
recipient_type = data["recipient_type"]
break
3. 評価行列を作成(recommender.py)
次は評価行列を作成します。
行に item_id、列に recipient_type を並べ、交わるところに評価値を埋めていきます。
「ネックレス は 、20 代女性の誕生日にあげるプレゼントとして、評価 5」といった感じです。
get_recommendations 関数の続きに書いていきます。
# 評価データの読み込み
rating_data = pd.read_csv('./data/rating.csv')
# item_id × recipient_typeの行列を作成(とりあえずゼロで埋める)
item_list = rating_data.sort_values('item_id').item_id.unique()
recipient_list = rating_data.sort_values('recipient_type').recipient_type.unique()
rating_matrix = np.zeros([len(item_list), len(recipient_list)])
# それぞれのitem_idとrecipient_typeの組み合わせの時の評価値を埋める
for item_id in range(1, len(item_list)+1):
recipient_list = rating_data[rating_data['item_id'] == item_id].sort_values('recipient_type').recipient_type.unique()
for type in recipient_list:
try:
rating = rating_data[(rating_data['item_id'] == item_id) & (rating_data['recipient_type'] == type)].loc[:, 'rating']
except:
rating = 0
rating_matrix[item_id-1, type-1] = rating
上記で作成した行列 rating_matrix を出力すると下記のようになります。
[[-5. -2. -2. ... 7. 5. 15.]
[-3. -5. -1. ... 6. 6. 13.]
[ 0. 3. 4. ... -1. -1. 7.]
...
[-7. -7. -6. ... 11. 11. 8.]
[-8. -8. -7. ... 7. 7. 0.]
[-3. -3. -3. ... 6. 6. 14.]]
これを表にするとこんなイメージです。

4. 商品同士のコサイン類似度を計算(recommender.py)
ここまでで各商品がどんな受け取り手に喜ばれるのか/喜ばれないのかがわかりました。
これでいよいよ商品同士の類似度を計算して、レコメンドできるようになります。
今回は「コサイン類似度」を計算したいので、scikit-learn の pairwise_distance という関数を使いましょう。
この計算結果は、商品同士が似ていれば 1 に近づき、似ていなければ-1 に近づき、無関係であれば 0 に近づいていきます。
まずは下記の import 文を行頭に記載します。
import sklearn.metrics as skmt
そして、get_recommendations 関数の続きに計算処理を書きます。
ここで、同じ商品同士の類似度は 1 になってしまって 1 番におすすめされてしまうので、0 に書き換える処理も書いておきます。
# scikit-learnのpairwise_distancesを用いてコサイン類似度行列を計算
similarity_matrix = 1 - skmt.pairwise_distances(rating_matrix, metric='cosine')
# 対角成分の値はゼロにする
np.fill_diagonal(similarity_matrix, 0)
上記で作成した行列 similarity_matrix を出力すると下記のようになります。
[[0. 0.4437314 0.37590602 ... 0.64586167 0.5853507 0.65901553]
[0.4437314 0. 0.21627518 ... 0.65265878 0.59924339 0.69970742]
[0.37590602 0.21627518 0. ... 0.12124443 -0.0337501 0.09870698]
...
[0.64586167 0.65265878 0.12124443 ... 0. 0.66391971 0.83788756]
[0.5853507 0.59924339 -0.0337501 ... 0.66391971 0. 0.74424061]
[0.65901553 0.69970742 0.09870698 ... 0.83788756 0.74424061 0.]]
これを表にするとこんなイメージです。

5. 商品を評価(recommender.py)
商品同士の類似度がわかったら、あとは「各商品の他の商品との類似度」×「特定した受け取り手タイプの各商品への評価」を算出して合計します。
すると、「高評価の商品に似ている商品」と「低評価の商品に似ていない商品」は高順位となります。
get_recommendations 関数の続きに下記処理を書きます。
# 対象の受け取り手タイプの評価値を抜き出し、「類似度×評価点」を算出
rating_matrix_recipient = rating_matrix[:, recipient_type - 1]
pred_rating = similarity_matrix * rating_matrix_recipient
# 商品(行)ごとに「類似度×評価点」を合計
pred_rating_sum = pred_rating.sum(axis=1)
6. 商品情報を抽出・出力(recommender.py)
今回は上位 3 商品を出力したいので、item_id を取得し、それをもとに item.csv から商品情報を取得して app.py に返します。
get_recommendations 関数の続きに計算処理を書きます。
# 上位3商品のitem_idをレコメンドリストに格納
recommend_list = np.argsort(pred_rating_sum)[::-1][:3] + 1
# 商品情報を取得する
item_data = pd.read_csv('./data/item.csv')
index_1 = recommend_list[0] - 1
index_2 = recommend_list[1] - 1
index_3 = recommend_list[2] - 1
item_1 = [item_data.iloc[index_1,1], item_data.iloc[index_1,3], item_data.iloc[index_1,4]]
item_2 = [item_data.iloc[index_2,1], item_data.iloc[index_2,3], item_data.iloc[index_2,4]]
item_3 = [item_data.iloc[index_3,1], item_data.iloc[index_3,3], item_data.iloc[index_3,4]]
recommended_items = [item_1, item_2, item_3]
return recommended_items
以上で実装は完了です。
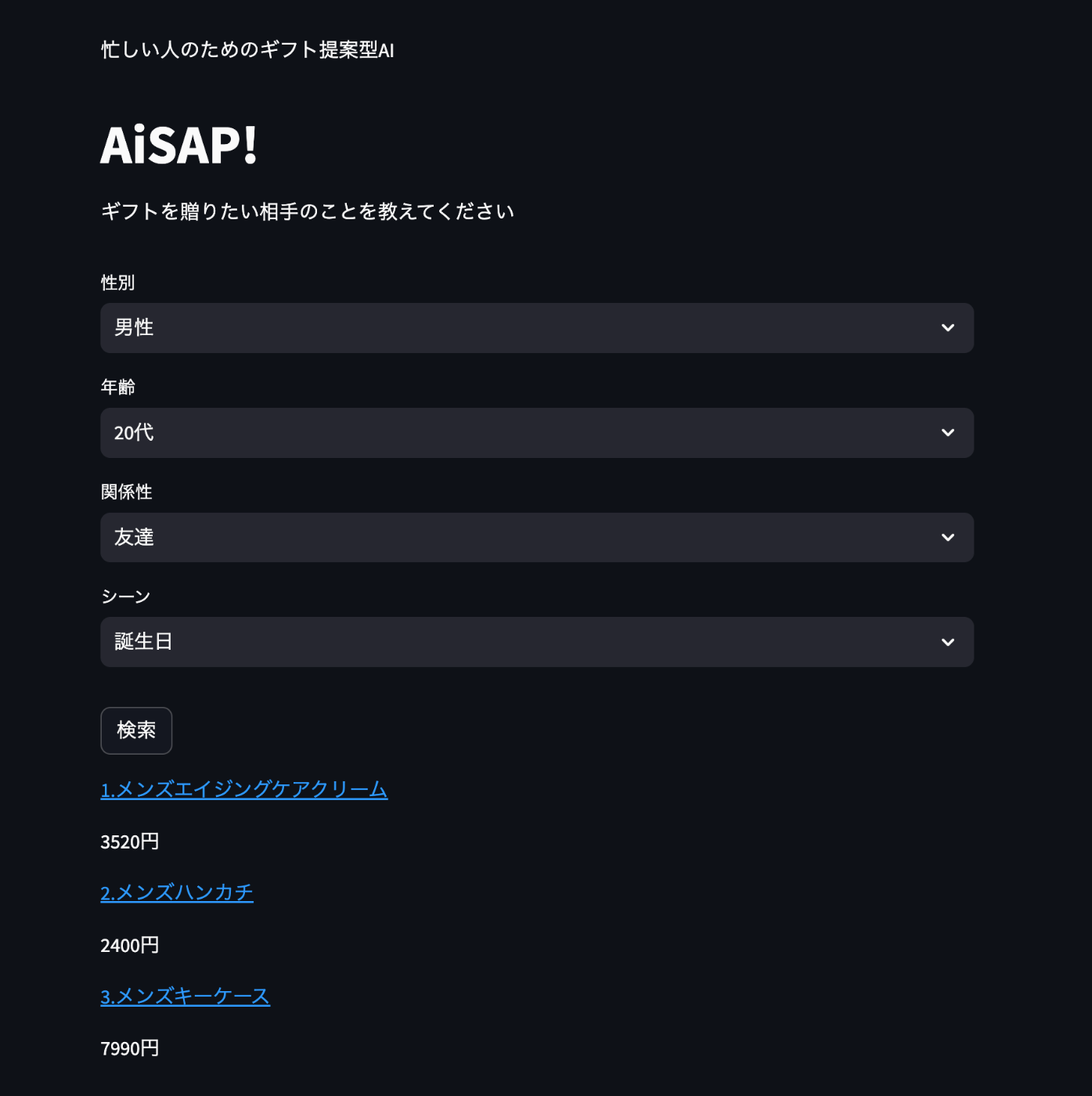
実行結果は下記のようになります。
※Github に公開するにあたって商品の URL や画像等のデータは削除したので、適宜追加して動かしてみてください。
ソースコードは下記を参照してください。
まとめ
形にはしてみましたが、サービスと呼ぶには程遠いです。
正確なおすすめを出すことがいかに難しいかがわかりました。
ただ、推薦システムについて少しでも知れたことは良かったと思います。
参考文献
Discussion