地図上のマーカーをクラスター化する技術
はじめに
最近よく地図を使用した Web アプリを作っているのですが、内部で地図上に表示されたマーカーをクラスター化するために Mapbox 社が公開している supercluster というライブラリを使用しており、これがどういう仕組みで動いているのか気になったので調べてみました。
(宣伝) supercluster を使用してつくったサービスはこちら👇
クラスター化とは
そもそもクラスター化とは何かというと、地図上の近い距離に複数のマーカー等が存在するときにグルーピングして表示することで、単純に見やすくなったり余計なマーカーの描画を防ぐというものです。大量のマーカーやピンを表示するようなアプリではほぼ必須の機能と言えると思います。
また今回は supercluster の実装についてのみ言及しますが、supercluster は GoogleMap のライブラリ の中でも使われていたり、Leaflet のプラグイン も同じような方法で実装されているようなので、この実装が現状のデファクトスタンダートになっているみたいです。
クラスター化の仕組み
クラスター化の仕組みについてですが、ライブラリ作者様のわかりやすい解説記事があったのでこちらの内容をベースに説明します。
まず、クラスター化されたマーカーが画面に表示されるまでには大きく 2 つのステップが実行されています。
1 つ目のステップでは、すべてのポイントを探索して指定された半径以内に存在するポイントを 1 つのポイントにまとめて(クラスタリングして)いきます。この処理は最初にマーカーをロードしたタイミングで全てのズームレベルにおいて実行され、処理としては最も重い部分になります。
2 つ目のステップでは、現在画面で表示されているエリアの座標とズームレベルに対応するクラスターを探索します。こちらはすでに 1 つ目のステップでズームレベルごとにクラスタリングされているデータの中から探索するだけですが、ユーザー操作に応じてリアルタイムに実行される部分なのでパフォーマンスが重要な部分でもあります。
ざっくり説明すると上の2つのステップだけで完結するのですが、これらの処理は以下で説明するような方法で効率的に実行されています。
階層的な貪欲クラスタリング
指定された半径以内に存在するポイントをクラスタリングしていくにあたって、単純に全てのズームレベルで全てのポイントを探索すると効率が悪いので、階層的な貪欲クラスタリングという方法で探索します。
階層的な貪欲クラスタリングとは、基本的には貪欲法であるポイントから近いポイントの探索を繰り返すのですが、毎回全てのポイントを探索するのではなく、ズームレベルが大きい方から順にクラスタリング処理をしていくことで、より大きいズームレベルで既にクラスタリングされているポイントがあった場合、そのクラスタリングされている地点を 1 つのポイントとして見なしてクラスタリングを行うというものです。
下図を見るとわかるように、ズームレベルを小さくしていくとクラスター化されたものをさらにクラスター化するような形になっていくので、探索しなければいけないポイント数が指数関数的に減少させられていることがわかると思います。
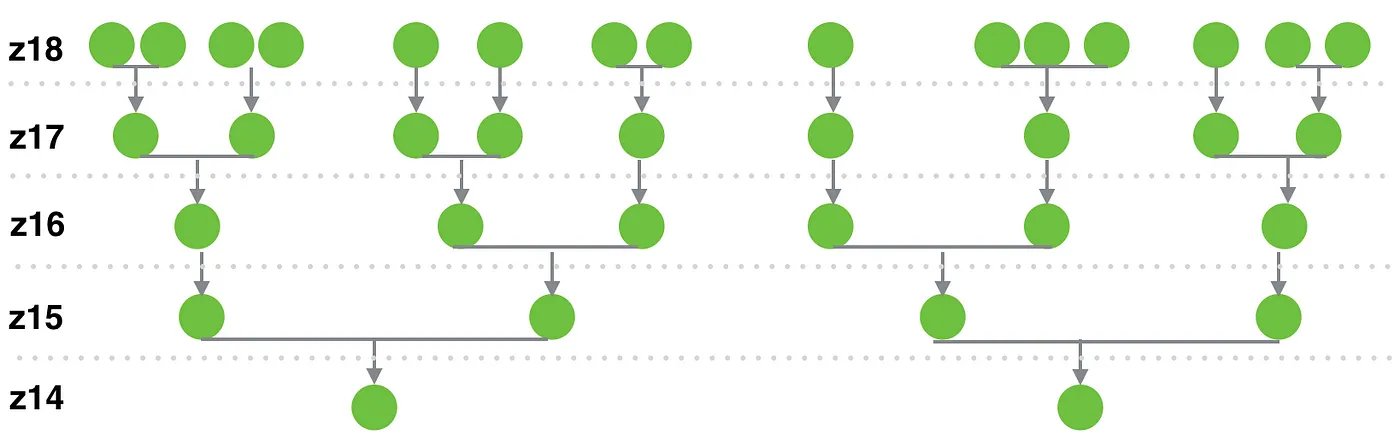
元記事 より引用
kd-tree を使用した近傍探索
階層的に実行することで計算量を減らせるとはいえ、必ずどこかのズームレベルでは各ポイントで近傍探索をする必要があり、これを大量のポイントで実行するのは直感的に重そうな処理だと感じると思います。
そこで、 supercluster では kd-tree というデータ構造を使用して探索を高速化しています。自分はアルゴリズム系よわよわなので詳しい説明は割愛しますが、一言で言うと 2 次元座標上に存在する点を x 軸方向と y 軸方向で分割していき、木構造を構築することで二分探索的に処理できるという感じらしいです。(間違ってたらツッコミください...)
kd-tree による近傍探索についての詳しい解説はこちらの記事などを参照ください。
自作してみた
クラスタリングの仕組みがわかったところで、自分でも勉強がてら実装してみました。(一部はほぼ元の実装をコピペしただけ + 対応しているのはズームレベルと表示領域からクラスター化された GeoJSON を返すメソッドのみですが)
本家ライブラリでは js で書かれており、データはフラットな配列で持たせてオフセットを使用してアクセスするような実装 (おそらく高速化のため) になっているのですが、今回は TypeScript を使用して各データはオブジェクトとして管理するようようにしました。
また、 kd-tree の部分を実装すると大変そうだったので kd-tree の威力を体感するため、今回はただの線形探索を使った実装にしました。(ちなみに本家 supercluster も kd-tree の部分は別パッケージとして提供されています)
GitHub Pages にデモアプリをデプロイしたのでこちらから試せます👇
コードはこちら👇
パフォーマンス計測
本家と自作でそれぞれマーカーをロードしてクラスタリング処理が完了するまでの時間を計測してみました。以下の表はランダムな座標にマーカーを配置し、各マーカー数ごとにクラスタリングにかかった時間を測定した結果です。(マーカーが同じ数でも配置位置によって結果は大きく変わるのであくまで参考結果としてご覧ください)
| マーカー数 | 本家 (kd-tree) Ave. | 自作 (線形探索) Ave. |
|---|---|---|
| 100 | 24 ms | 11 ms |
| 500 | 48 ms | 27 ms |
| 1,000 | 69 ms | 118 ms |
| 5,000 | 246 ms | 1,520 ms |
| 10,000 | 501 ms | 4,687 ms |
| 30,000 | 836 ms | 37,389 ms |
結果を見ると、マーカー数が 1000 以下程度であれば自作 (線形探索) でも十分速いですが、マーカー数が 5000 を超えてくると一気に性能が劣化しているのがわかります。自作ライブラリでマーカー 3 万個になると 30 秒以上かかるのに対し、kd-tree を使用した本家では 1 秒以内で終わるのを見るとアルゴリズムの偉大さを感じます。ちなみに 100 個や 500 個の時に自作の方が若干速いという結果は、本家側には kd-tree を構築する分のオーバーヘッドが存在する影響だと思います。
結論としてはマーカー数が 1000 個以下など局所的なユースケースであれば自作ライブラリも使えなくはなさそうといった感じでしょうか。(マーカーが少ない場合は kd-tree 構築のコストがない分むしろ線形探索の方が有利な場合もある)
おわりに
今回は supercluster というライブラリを参考に地図上のマーカーをクラスター化する技術について調べてみました。 supercluster の実装自体は小さなライブラリですが、あらかじめクラスタリング処理しておくことによる高速な表示、階層的に処理していくことで計算量の削減、高速な近傍探索アルゴリズムの使用など、様々な工夫がされていてとても勉強になりました。また、今回触れていない kd-tree の実装やサーバ側でのクラスタリング実行など、まだ気になる要素がいくつかあるのでその辺りも今後調べてみたいと思っています。
ここまで読んでいただきありがとうございました!
余談ですが、本家ライブラリのデモコードにめちゃくちゃ軽微なバグを見つけたので PR 出したら速攻でマージしてくれました🙌
Discussion