【Python/セグメント分析の前処理】複数カラム間の条件分岐を満たす単一のカラムを生成する
やりたいこと
ユーザーが持つ複数の属性それぞれが、特定の行動にどれくらい影響を及しているのか確認したい場合があります。
例えば、属性A、B、Cがあり、ユーザーがある行動に至る(コンバージョンする)とき、属性Bよりも属性Aを持っている方がCVRが高いのか、もしくは属性A、B、C全て持っている方がCVRが高いのか、逆にどの属性も持っていない場合はCVRが予想通り低いのかなど、セグメント別にCVRを確認したいみたいなケースです。
実際にやってみる
まずは基本ライブラリのimportから。
import numpy as np
import pandas as pd
説明用のdataframeを作成。
各ユーザーに対して、属性A、B、Cを持つかどうかを判定するフラグを付与します。
df = pd.DataFrame(
{
'user_id': [100, 108, 107, 110, 113, 105, 101, 120, 106, 111],
'attribute_A_flg': [1, 0, 0, 1, 1, 1, 0, 0, 0, 1],
'attribute_B_flg': [1, 1, 0, 1, 0, 0, 0, 1, 0, 1],
'attribute_C_flg': [1, 0, 1, 0, 1, 0, 0, 1, 1, 1],
})
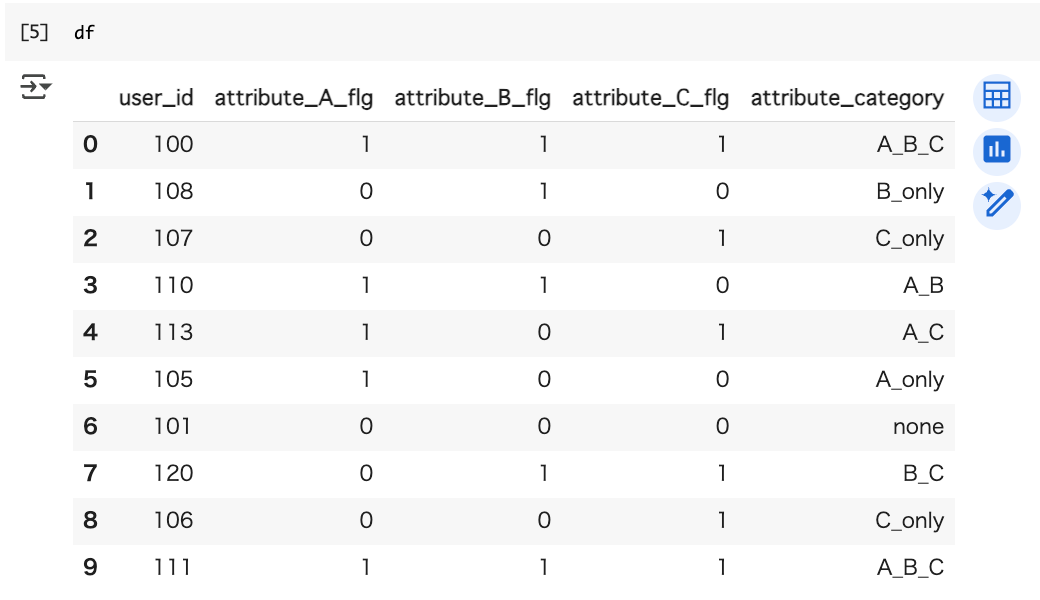
dfを呼び出すとこんなdataframeができました。

これに対して、先述したケースのように、実際にセグメントを分類してみます。
apply()メソッドの中のlambdaの指定では、通常は1カラムを指定することでそのカラムに対する条件分岐によって演算することができます。
※ 例えば、df['is_adult'] = df['age'].apply(lambda x: 1 if x>=20 else 0)のような処理によって、そのユーザーが成人かどうかを判定するカラムを作るときなど(上記のdataframeにはageというカラムはないですが、説明のため)。
しかし今回は同時に複数のカラムを指定して、それらについて演算処理をしたいです。
そこで、ここでは各行(row)を指定することで、一回の処理でdataframe内全てのカラムに対して柔軟に演算することが可能になります。
# 集計カテゴリを作成
df['attribute_category'] = df.apply(
lambda row:
'A_only' if row['attribute_A_flg']==1 and row['attribute_B_flg']==0 and row['attribute_C_flg']==0 else
'B_only' if row['attribute_A_flg']==0 and row['attribute_B_flg']==1 and row['attribute_C_flg']==0 else
'C_only' if row['attribute_A_flg']==0 and row['attribute_B_flg']==0 and row['attribute_C_flg']==1 else
'A_B' if row['attribute_A_flg']==1 and row['attribute_B_flg']==1 and row['attribute_C_flg']==0 else
'B_C' if row['attribute_A_flg']==0 and row['attribute_B_flg']==1 and row['attribute_C_flg']==1 else
'A_C' if row['attribute_A_flg']==1 and row['attribute_B_flg']==0 and row['attribute_C_flg']==1 else
'A_B_C' if row['attribute_A_flg']==1 and row['attribute_B_flg']==1 and row['attribute_C_flg']==1 else
'none', axis=1)
dfを呼び出すと、こんなカラムが完成しました。
あとはここで作成した集計カテゴリに対して、groupby()などを使ってCVRなどを計算します。
ただ、この手法は条件分岐の可読性がメリットである一方で、パフォーマンス観点では良くないです。
apply()を使うと、仕組みについて詳しくはないですがPythonレベルで1行ずつ関数を呼び出してループが回るため、処理対象の行数が多くなると速度が遅くなります。
そこで、条件分岐を列演算(ベクトル化)してから、numpy関数に渡すことで、圧倒的に高速化するケースも記載しておきます。
# 条件分岐を列演算に置き換え(ベクトル化)
conditions = [
(df["attribute_A_flg"] == 1) & (df["attribute_B_flg"] == 0) & (df["attribute_C_flg"] == 0), # A only
(df["attribute_A_flg"] == 0) & (df["attribute_B_flg"] == 1) & (df["attribute_C_flg"] == 0), # B only
(df["attribute_A_flg"] == 0) & (df["attribute_B_flg"] == 0) & (df["attribute_C_flg"] == 1), # C only
(df["attribute_A_flg"] == 1) & (df["attribute_B_flg"] == 1) & (df["attribute_C_flg"] == 0), # A & B
(df["attribute_A_flg"] == 0) & (df["attribute_B_flg"] == 1) & (df["attribute_C_flg"] == 1), # B & C
(df["attribute_A_flg"] == 1) & (df["attribute_B_flg"] == 0) & (df["attribute_C_flg"] == 1), # A & C
(df["attribute_A_flg"] == 1) & (df["attribute_B_flg"] == 1) & (df["attribute_C_flg"] == 1), # A & B & C
(df["attribute_A_flg"] == 0) & (df["attribute_B_flg"] == 0) & (df["attribute_C_flg"] == 0), # none
]
# 各条件が真のときの値(順番対応)
choices = [
"A_only",
"B_only",
"C_only",
"A_B",
"B_C",
"A_C",
"A_B_C",
"none",
]
df["attribute_category"] = np.select(conditions, choices, default='other')
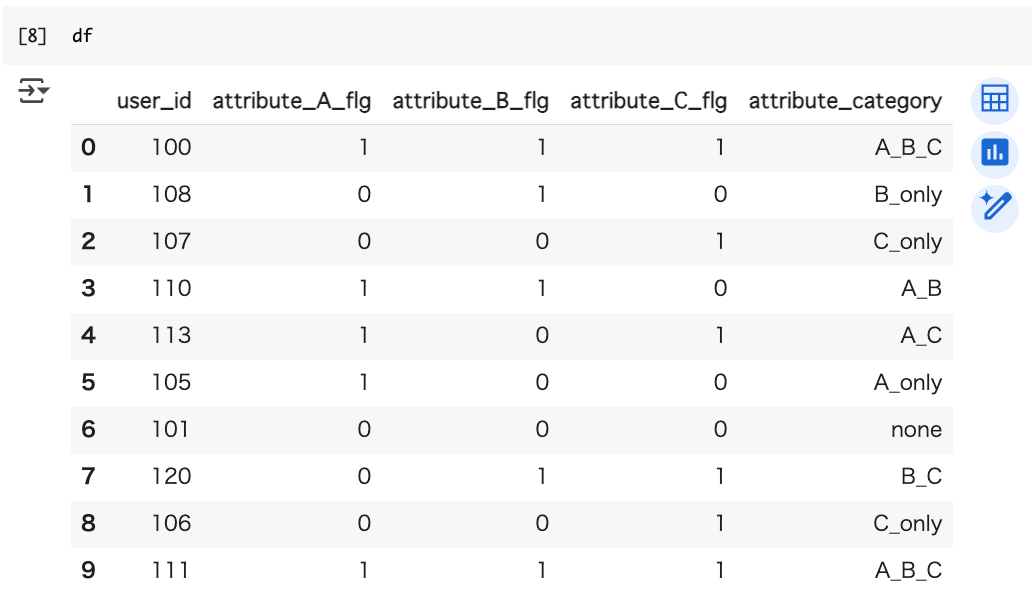
dfを呼び出すと、同じように欲しいカラムが完成しました。
Discussion