Google Cloud Functions の PubSub トリガーで再帰的に呼び出して大量データを繰り返し処理する【Node.js】
Google Cloud Functions などの FaaS は、Google Cloud の他のサービスと連携して利用すると便利です。よくあるユースケースとして Cloud Storage にあるファイル一覧を取り出して何かする、であったり、BigQuery のAPIを呼んで繰り返しレコードを取得する、などがあります。
Cloud Storage にある大量のファイル、どう走査する?
このような処理でありがちなのが、SDK/API一回の呼び出しですべてのデータはとってこれないので、nextTokenを使ってして繰り返し取得するというパターンです。Cloud Storage のバケットにあるすべてのファイルパスを取得するコードは以下のようになります。
import { File, Storage } from '@google-cloud/storage';
const BucketName = process.env.BUCKET_NAME!;
const gcs = new Storage();
const imageBucket = gcs.bucket(BucketName);
/**
* CloudStorage上の全ファイルを取得します。
*/
async function getAllFiles(): Promise<strtopicg[]> {
const result = [];
let nextToken: string | undefined = undefined;
do {
// files 以外はドキュメントに明記されていない。型もany。
// 結果から2番目の戻り値に nextToken があると確認したのでそれを使っている。
let files: File[], query: any;
[files, query] = await imageBucket.getFiles({
autoPaginate: false,
prefix: '',
maxResults: 100,
pageToken: nextToken,
});
const chunk = await Promise.all(files.map((f) => f.name));
result.push(...chunk);
nextToken = query?.pageToken;
} while (nextToken);
return result;
}
getAllFiles().then(console.log);
maxResultsとpageTokenを使ってページングを行っていることがわかります。繰り返し取得して、最後に配列として返しています。
ファイル数がそんなに多くないときはこれでいいけど...
処理する内容にもよりますが、Cloud Functions は手軽に実行できる一方で制限もあります。今回のように Cloud Storage のファイルを一括で処理する場合、メモリと実行時間を気にしなければなりません。
- 関数の最大実行時間: 540秒
- 最大関数メモリ:8192MiB
なので、ファイルが数えられないくらい大量にあるときや、今後も増え続けるケースでは一括で処理する方法は課題が残ります。いつくか方法を考えてみましょう。
- ファンアウトで複数並列実行
- Cloud Tasks へタスクを分割して投入
- 再帰的呼び出し(今回やるやつ)
ファンアウト
大量のデータを分割して Cloud PubSub のトピックへ投入する関数がおり、投入データに対して処理を行う関数を別途用意するというものです。
全体が完了する実行時間を短くおさえたいときに有用です。同時実行数は多くなります。
こちらもご参照。
今回は見送った理由:
- 投入と処理する関数をふたつ用意しないといけないのが大変
- データが増え続けると総なめする投入側の処理時間を考慮しなければならなくなる
- 実行時間に厳しい要件があるわけではない
Cloud Tasks へタスクを分割して投入
大量のデータを分割して Cloud Tasks のタスクとして投入する関数がおり、投入タスクに対して処理を行う関数を別途用意する方針です。
同時実行数やリトライ回数などを細かく制御したい場合に有用です。
今回は見送った理由:
- 投入と処理する関数をふたつ用意しないといけないのが大変
- データが増え続けると総なめする投入側の処理時間を考慮しなければならなくなる
- 細かくタスクの実行頻度を制御したい要件はない
再帰的呼び出し
今回はこれを採用します。Cloud PubSub トピックへメッセージも投入するし、同じトピックをサブスクライブもします。
ご想像のとおり、気をつけて実装しないと無限ループします。
今回採用した理由:
- 関数がひとつで済みアーキテクチャがシンプル
- データが大量にあっても、全体の実行時間が延びるだけ。関数は毎回同じ量を処理するし、同時実行数も増えない
Cloud PubSub トリガー関数の再帰呼び出しを実装
処理の流れは以下のようなものです。
- gcloudコマンドや他のアプリケーションから初回のメッセージをトピックへ投入する
- 関数が起動する
- 関数は決められた範囲のファイルを Cloud Storage のバケットから取り出し、1件ずつ処理する
- バケットから取り出したとき、次のデータが存在する印、pageToken を確認する
- 存在する場合、PubSub トピックへ
nextToken=pageTokenを投入して終了 - 存在しない場合、なにもせずに終了
- 存在する場合、PubSub トピックへ
オブジェクトのメタデータをログへ出力する関数
サンプル実装として、Google Cloud Storage のバケットにあるすべてのオブジェクトメタデータを Cloud Logging へ記録する関数を作ってみます。
import { File, Storage } from '@google-cloud/storage';
import { FileTypeResult } from 'file-type';
import { PubSub } from '@google-cloud/pubsub';
import { google } from '@google-cloud/pubsub/build/protos/protos';
import { Metadata } from '@google-cloud/common/build/src/service-object';
import PubsubMessage = google.pubsub.v1.PubsubMessage;
const BucketName = process.env.BUCKET_NAME!;
const gcs = new Storage();
const imageBucket = gcs.bucket(BucketName);
const pubsub = new PubSub();
// 自由に構造化できるPubSubメッセージ
// 次のCloudStorageファイルリストトークンと一度に取得するファイルリストの数をもたせます
type NextProps = {
nextToken?: string;
maxResults: number;
};
// 繰り返し処理でトピックへメッセージを投入するとき、トピック名がほしいのでコンテキストから取り出します
// https://cloud.google.com/functions/docs/writing/background#function_parameters
type PubSubContext = {
eventId: string;
timestamp: string;
eventType: string;
resource: {
service: string;
name: string;
};
};
/**
* PubSub経由で自分自身を呼び出す再帰関数です。
* NextProps で定められた範囲を処理し、次の処理は改めて自分自身を呼び出します。
* @param message PubSub から渡ってくるメッセージ
* @param context トリガーのコンテキスト。後続でさらにトピックへメッセージを送るのに使う
* */
export async function cloudStorageMetaDataLogging(
message: PubsubMessage,
context: PubSubContext
): Promise<void> {
// Base64エンコードされたメッセージボディは data に格納されており、万が一これがなければ終了
if (!message.data) {
return;
}
// NextProps をデコード
const props = JSON.parse(
Buffer.from(message.data as string, 'base64').toString()
) as NextProps;
// PubSubメッセージには処理するべき範囲の情報が入っている
// 定められた範囲のファイル名をCloudStorageから取得する
const [fileNames, nextToken] = await getImageFileNames(props);
// 担当ファイル分繰り返す
for (const gcsFilePath of fileNames) {
const remoteFile = imageBucket.file(gcsFilePath);
// Cloud Storage のオブジェクトメタデータ
// ref: https://cloud.google.com/storage/docs/viewing-editing-metadata#storage-set-object-metadata-nodejs
const [metadata] = await remoteFile.getMetadata();
await cloudLogging(
'INFO',
` ${gcsFilePath}のメタデータ`,
metadata,
);
}
// nextToken が存在する場合、次の関数を呼び出すためトピックへメッセージを送信する
// 存在しない場合はなにもしない(おわり)
if (nextToken) {
// 'projects/my-project/topics/cloud-storage-token-topic'
const topicName = context.resource.name;
const topic = pubsub.topic(topicName);
const messageObject: NextProps = {
nextToken,
maxResults: props.maxResults,
};
const messageBuffer = Buffer.from(JSON.stringify(messageObject), 'utf8');
await topic.publish(messageBuffer);
}
}
PubSubメッセージをデコードして、そのパラメータを使ってバケットからリストを取得、リストを繰り返し処理した後次の関数へ処理を任せるべくトピックへメッセージを入れています。末尾の部分、if (nextToken) {に注目してください。「Cloud Storage からデータを取得したとき、次のトークンがもしあればトピックへメッセージを投入する」ということをやっています。ここが再帰ポイントです。トピック名はコンテキストから手に入ります。getImageFileNamesとcloudLoggingの実装は以下に載せておきます。
getImageFileNamesの実装
/**
* Cloud Storage から パラメータ範囲のファイル名リストを抽出します
* @returns [ファイル名の配列、次のトークン]
*/
async function getImageFileNames(
nextProps: NextProps
): Promise<[string[], string]> {
// files 以外はドキュメントに明記されていない。型もany。
// 実際に試した結果、2番目の戻り値に nextToken があると確認したのでそれを使う
let files: File[], query: any;
[files, query] = await imageBucket.getFiles({
autoPaginate: false,
prefix: '',
maxResults: nextProps.maxResults,
pageToken: nextProps.nextToken,
});
const fileNames = await Promise.all(files.map((f) => f.name));
return [fileNames, query?.pageToken];
}
cloudLoggingの実装
/**
* 構造化ログを出力します。
*/
async function cloudLogging(
severity: 'INFO' | 'WARNING',
text: string,
gcsMetadata: Metadata,
fileTypeResult?: FileTypeResult
): Promise<void> {
const {Logging} = require('@google-cloud/logging-min');
const projectId = process.env.GCP_PROJECT || 'my-project';
const logging = new Logging({projectId});
const logger = logging.logSync('cloud-storage-meta-data-logging');
const metadata = {
severity, // https://cloud.google.com/logging/docs/reference/v2/rest/v2/LogEntry#logseverity
resource: {type: 'cloud_function'}, // https://cloud.google.com/monitoring/api/resources#tag_cloud_function
};
const message = {
infoMessage: text,
gcsMetadata: gcsMetadata,
fileTypeResult: fileTypeResult,
};
// Prepares a log entry
const entry = logger.entry(metadata, message);
logger.write(entry);
}
デプロイ・実行
デプロイします。CloudFunctions をデプロイするとき、PubSub トリガーであることを示すオプションを含めればOKです。PubSub のトピックがなければ自動で作ってくれます。便利ですね。
#!/bin/bash
# myprojectにデプロイする
my_project=$MY_PROJECT
my_bucket=$MY_BUCKET
gcloud functions deploy cloudStorageMetaDataLogging \
--runtime=nodejs16 \
--source=.\
--region=asia-northeast1 \
--entry-point=cloudStorageMetaDataLogging \
--memory=512\
--timeout=300s\
--project=${my_project}\
--trigger-topic=cloud-storage-token-topic\
--set-env-vars=BUCKET_NAME=${my_bucket}
実行します。
MY_PROJECT=my-project-develop MY_BUCKET=uploads-dev ./deploy-logger.sh
Deploying function (may take a while - up to 2 minutes)...⠛
For Cloud Build Logs, visit: https://console.cloud.google.com/cloud-build/builds;region=asia-northeast1/
Deploying function (may take a while - up to 2 minutes)...done.
最初の起動だけは能動的にPubSubへデータ投入
ドミノ倒しみたいですね。Cloud Shell から gcloud コマンドで呼び出してみます。
DATA=$(printf '{ "maxResults": 50 }'|base64)
gcloud functions call cloudStorageMetaDataLogging --region asia-northeast1 --data '{"data":"'$DATA'"}'
maxResultsを50と指定し、バケットにあるオブジェクト50件ごと処理するようにメッセージを送ります。バケットには約300のオブジェクトがある状況です。
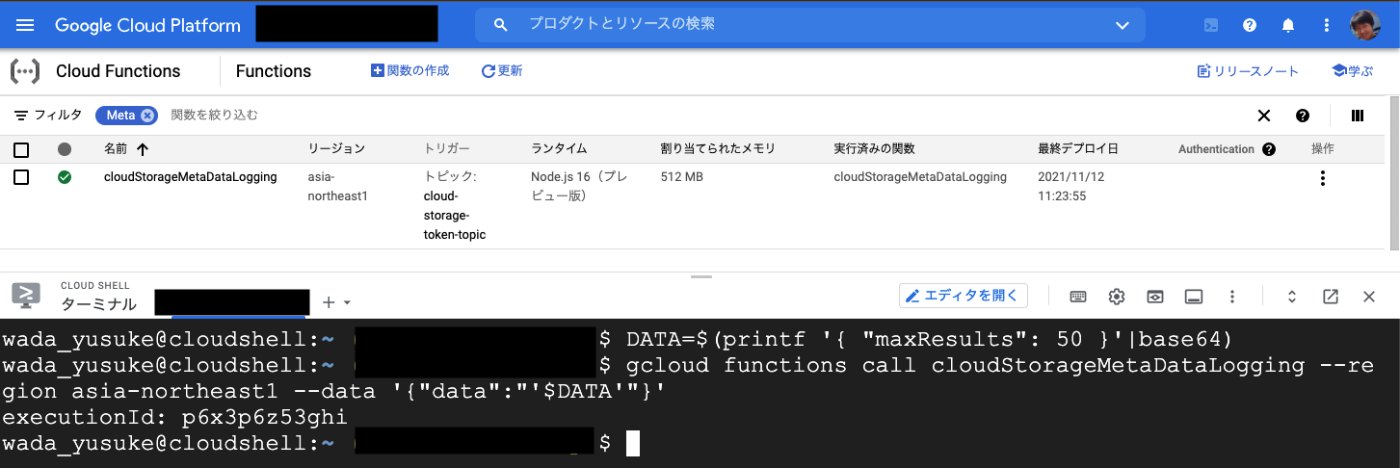
実行するとわりとすぐ結果が返ってきました。この実行コマンドは初回の Cloud Functions を実行するコマンドなので、再帰的に実行される分についてはバックグラウンドで処理が走ります。Cloud Logging へログが出力されているか見てみましょう。
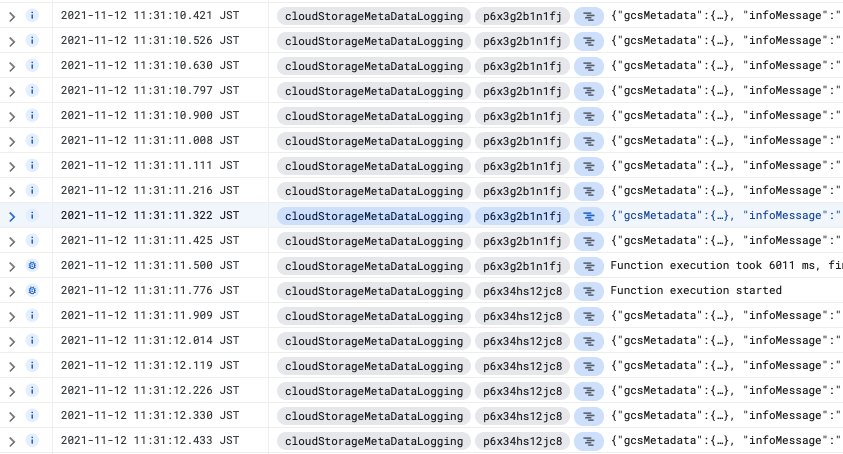
実装どおりメタデータが出力されています。途中で実行IDが変わっていることから、再帰実行により担当するCloudFunctionsが別のものになっていますね。意図どおりです。
おわりに
全体の実行時間がそれほど厳しくない要件では、CloudFunctionsのPubSUbトリガーで再帰実行する方法がれることを示しました。一度に処理する数さえ気をつければ、メモリ不足や関数あたりの実行時間を気にすることもありません。似たような状況に遭遇した場合はお試しください。ソースコードはGitHubで公開しています。
参考文献
Discussion