はじめに
こんにちは。よこやんです。
株式会社バニッシュ・スタンダードという会社でサーバーサイドエンジニアをやっています。
前回はHuggingFaceのAIモデルで画像の特徴をテキスト化しようという業務外で勉強したことをブログのネタにさせていただきました。
今回も懲りずに生成AIネタでブログを書きたいと思います。
RAG(Retrieval Augmented Generation)とは?
RAGという言葉をきいたことはありますか?
生成AIに興味を持っているエンジニアであれば、小耳に挟んだことくらいはあると思います。
RAGは「検索拡張生成」という意味で、生成AIがより正確な回答をするための技術です。具体的には、AIが質問に答えるとき、まず外部のデータベースから必要な情報を探し出し、その情報を基にして新しい文章を作り出す仕組みです。
RAGの仕組み
RAGの働きは大きく分けて二つのステップから成り立っています。
- データ選択: ユーザーが質問すると、AIは外部のデータベースから関連する情報を探し出します。
- 情報生成: 選ばれた情報をもとに、新しい文章を生成します。
このプロセスによって、AIは大量の情報から必要なものを効率よく取り出し、正確な回答を提供できるようになります。
データ選択の際、質問に対する答えをデータベースから検索することになりますが、従来のリレーショナルデータベース(RDB)だと完全一致、または部分一致などの検索条件をあらかじめ決める必要があり、そこから外れる情報のアクセスは難しく、柔軟な検索が不得手となっております。
そこで登場するのがベクトルDBというものです。
こちらについては後述しますが、このような問題に対してより柔軟な検索が可能となります。
RAGの利点
RAGを使うことで得られる主なメリットは以下の通りです。
- 正確性の向上: AIが最新の情報や特定のデータに基づいて回答できるため、間違った情報(ハルシネーション)を減らすことができます。
- 幅広い情報の活用: ネット上にない社内データや特定の知識も利用できるため、より詳細で正確な内容を提供できます。
- 効率的な情報管理: ユーザー自身が必要なデータを登録できるので、情報の管理が簡単になります
具体的な活用例
例えば、自社サービスのFAQを読み込ませることで、自社サービスの説明に特化したチャットシステムの構築が可能です。
他には社内限定な情報をRAGに取り込むことで より業務に特化した回答を得ることができるサポートシステムなどを作ることができます。
ベクトルDBとは?
ベクトルDBは、テキストや画像などのデータを数値の列(ベクトル)に変換して保存する場所です。これにより、似ているデータを見つけることが簡単になります。例えば「犬」という言葉や「猫」という言葉は両者とも同じ動物の名前、ということで意味が似ているため、ベクトル空間では近い位置に配置されます。
このような単語の一致などではなく意味などからの類似性を測るにはコサイン類似度というものを検査することになります。
コサイン類似度とは
コサイン類似度は、二つのベクトルがどれだけ似ているかを測る方法で、具体的には、二つのベクトルがなす「角度」に基づいています。以下のように考えることができます:
ベクトル同士が直線的に近い(角度が小さい)ほど、類似度が高い。
コサイン類似度は0から1の値を取り、1に近いほど似ていることを示します。
例えば、次のような二次元空間で考えてみましょう:
ベクトルA = [1, 2]
ベクトルB = [3, 1]
ベクトルQ = [2, 2]
この場合、コサイン類似度を計算すると、ベクトルQと最も近いのはベクトルAになります。これは、QとAの間の角度が小さいからです。
具体的な実装はどう作るのか?
ではここから具体的にどのように作れば良いのかを解説します。
まず最初に断っておきますが、生成AI関連の技術は日進月歩で進化しており、今回紹介する方法も私が勉強し、理解することができた範疇での話なので、本記事執筆時点であってもすでに陳腐化している可能性もあります。
よって、あくまで一例としての参考にしてください。
今回完成版をgithubのrepositoryにあげておきました。
生成AI関連といえばPythonですが、今回のこれはGo言語で作っています。
なぜか?
それはバニッシュ・スタンダードでは運営サービスのサーバーサイドをGo言語で実装しているからです。
生成AI関連では素直にPython使った方が楽な場面は多いのですが、この程度であればGo言語でもできますよ、という感じですね。
今回の構成
今回はGo言語のechoフレームワークを用いたAPIサーバーとなります。
よってUIは作りません。
次にベクトルDBですが、今回はQdrantというものを使ってみます。
これを選んだ理由ですが、dockerで簡単に作れて簡易なダッシュボードまで利用できるからです。

QdrantにはCollections、Points、Payloadという概念があります。
CollectionsはRDBでいうところのテーブル、Pointsはレコード、Payloadはベクトル情報以外のカラム、またはレコードコメント、のようなイメージです。
LLMについてはOpenAIのAPIを使用します。
では解説を始めます。
処理のフローについての説明
今回作るにあたって、以下のような操作を想定しました
手順1: 参考にしたいwebページのURLを登録。登録したデータは永続化する。
手順2: 登録したページに関連した質問を行い、答えられるようにする。
です。
LLMは最新の情報に基づいた質問の回答が難しい、
例えば、2024年11月10日現在、「第47代のアメリカ大統領は誰になりますか?」
という質問として素の状態でのLLMでは回答は難しいでしょう。
なぜなら決まったのはほんの1週間前だからです。
そこで、ニュースサイトのURLでも貼っておけばその情報をもとに「ドナルド・トランプ」と回答できるようなものを目指しました。
今回作成したサンプルのディレクトリ構成は以下のとおりです。
$ tree
.
├── Dockerfile
├── README.md
├── docker-compose.yml
├── go.mod
├── go.sum
├── internal
│ ├── domain
│ │ ├── model
│ │ │ └── article.go
│ │ ├── repository
│ │ │ └── article_repository.go
│ │ └── service
│ │ └── openai_service.go
│ ├── infrastructure
│ │ ├── openai
│ │ │ ├── openai_service.go
│ │ │ └── openai_service_test.go
│ │ ├── qdrant
│ │ │ └── client.go
│ │ ├── repository
│ │ │ ├── article_repository.go
│ │ │ ├── article_repository_test.go
│ │ │ └── testdata
│ │ │ └── fixtures
│ │ │ └── article
│ │ │ └── find
│ │ │ └── sample.json
│ │ └── webscraper
│ │ ├── scraper_service.go
│ │ └── scraper_service_test.go
│ ├── interface
│ │ └── controller
│ │ ├── article_controller.go
│ │ └── request.go
│ └── usecase
│ └── article_usecase.go
├── main.go
├── router
│ └── router.go
└── tmp
├── build-errors.log
└── main
レイヤーごとのテストを書きたかったので、オニオンアーキテクチャっぽくしましたが、依存性逆転の法則を意識しているわけではなく結構適当です。
手順1の操作で行う内部処理は具体的には以下のとおりです。
Step1-1: 指定したURLをスクレイピングし、文字列情報を取得する
Step1-2: 文字列情報を適切な長さに分割する。
Step1-3: 分割した文章ごとにベクトル化を行う。
Step1-4: ベクトル化した情報をベクトルDBに保存する。
Step1-1、Step1-2
Step1-1については普通のwebスクレイピングです。
Step1-2についても普通に句点での分割をしているだけです。
より効率を求める場合、「チャンク分割」というテクニックもあるようですが、今回はそこまでやっていません。
特に特筆すべきこともないのでこれらの説明は割愛します。
Step1-3
続いてStep1-3ですが、これを行なっているのは
internal/infrastructure/repository/article_repository.go
のSaveメソッドになります。
// テキストデータをベクトル化し、Qdrantに登録する
func (a *articleRepository) Save(texts *[]string) error {
// コレクションの存在確認
// コレクションの存在をチェック
exists, err := collectionExists(a.client, a.collectionName)
if err != nil {
log.Fatalf("コレクションのチェックに失敗しました: %v", err)
}
if !exists {
// コレクションの作成
err := createCollection(a.client, a.collectionName)
if err != nil {
log.Fatalf("コレクションの作成に失敗しました: %v", err)
}
}
// 文章データの登録
err = a.insertTextData(a.client, a.collectionName, texts)
if err != nil {
log.Fatalf("データの挿入に失敗しました: %v", err)
}
return nil
}
func createCollection(client *qdrant.Client, collectionName string) error {
err := client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: collectionName,
VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{
Size: 1536, // ベクトルのサイズ(使用するモデルに応じて調整)
Distance: qdrant.Distance_Cosine,
}),
})
if err != nil {
return err
}
return nil
}
// 渡されたテキストデータをベクトル化してQdrantに登録する
func (a *articleRepository) insertTextData(client *qdrant.Client, collectionName string, texts *[]string) error {
points := make([]*qdrant.PointStruct, len(*texts))
for i, text := range *texts {
vedtor, err := a.openAIService.VectorizeText(text)
if err != nil {
return fmt.Errorf("文章のベクトル化に失敗しました: %w", err)
}
points[i] = &qdrant.PointStruct{
Id: qdrant.NewIDNum(uint64(i + 1)),
Vectors: qdrant.NewVectors(vedtor...),
Payload: qdrant.NewValueMap(map[string]any{"text": text}),
}
}
_, err := client.Upsert(context.Background(), &qdrant.UpsertPoints{
CollectionName: collectionName,
Points: points,
})
if err != nil {
return fmt.Errorf("データの挿入に失敗しました: %w", err)
}
return err
}
func collectionExists(client *qdrant.Client, collectionName string) (bool, error) {
// コレクションのリストを取得
collections, err := client.ListCollections(context.Background())
if err != nil {
return false, fmt.Errorf("コレクションリストの取得に失敗しました: %w", err)
}
// コレクション名が一致するものを探す
for _, collection := range collections {
if collection == collectionName {
return true, nil
}
}
return false, nil
}
ここでの大きな処理は二つ
- テキストデータのベクトル化
- ベクトル情報をQdrantに登録する
です。
テキストデータのベクトル化はOpenAIのAPIを利用して変換します。
vedtor, err := a.openAIService.VectorizeText(text
func (s *openAIService) VectorizeText(text string) ([]float32, error) {
resp, err := s.client.CreateEmbeddings(
context.Background(),
openai.EmbeddingRequest{
Model: openai.SmallEmbedding3,
Input: []string{text},
},
)
if err != nil {
return nil, err
}
return resp.Data[0].Embedding, nil
}
OpenAPI側で用意しているCreateEmbeddingsの処理を使うことで文章のベクトル化が行えます。
実行すると以下のようなデータが取得できます。
文章: 日本の首都は東京で、人口は約1,400万人です。
ベクトル:[
0.036486834, -0.023229655, 0.055188924, 0.08303492, -0.0031459907, 0.013597486, -0.044328693, 0.04708074, -0.017015353, -0.027476095, -0.016704638, 0.033409275, -0.002679918,
-0.029976612, -0.023185266, 0.0102314055, -0.053176675, -0.025981704, 0.042997055, -0.0274613, -0.006365961, -0.0152546335, 0.013013045, -0.00534504, 0.042168483, 0.0494185,
-0.029739877, -0.01805107, 0.033054173, -0.0068690237, 0.00721303, -0.0318409, -0.031515393, 0.0051489933, -0.027698034, -0.03719704, 0.015491368, -0.011755389, 0.020906689,
0.0091513, -0.00926227, -0.03240315, 0.035599075, 0.0494185, -0.016009226, 0.016098002, -0.026721502, -0.014647999, 0.001050513, 0.026529154, 0.0022526847, -0.00038284544,
-0.006181012, -0.025182722, -0.00094278, 0.005267361, 0.059538938, 0.040215414, -0.0016636206, -0.010919417, 0.046133798, 0.015054888, 0.0036952905, 0.056964442, 0.04817564,
0.011548245, 0.05474505, 0.0055743773, 0.03181131, 0.021291384, -0.02043322, 0.010667886, -0.022608224, -0.0013482817, -0.013937793, 0.012857688, -0.061965473, -0.06033792,,,,,]
このように文章の意味合いに応じた数値ベクトルデータが取得できます。
なお、変換に使うモデルによりベクトル値も次元数も違います。
今回使用しているtext-embedding-3-smallモデルでは1536次元となっております。
Step1-4
こうして取得したデータをQdrantに登録するわけですが、今回は同じCollectionsに全てのデータを登録します。その際、Collectionsがなかったら作成するようにします。
Collectionsのチェックが終わったらQdrantにPointsを登録します。
qdrant.ClientのUpsertメソッドで実行することができます。
これにより登録されるとQdrantの管理画面で登録内容を確認することができます。
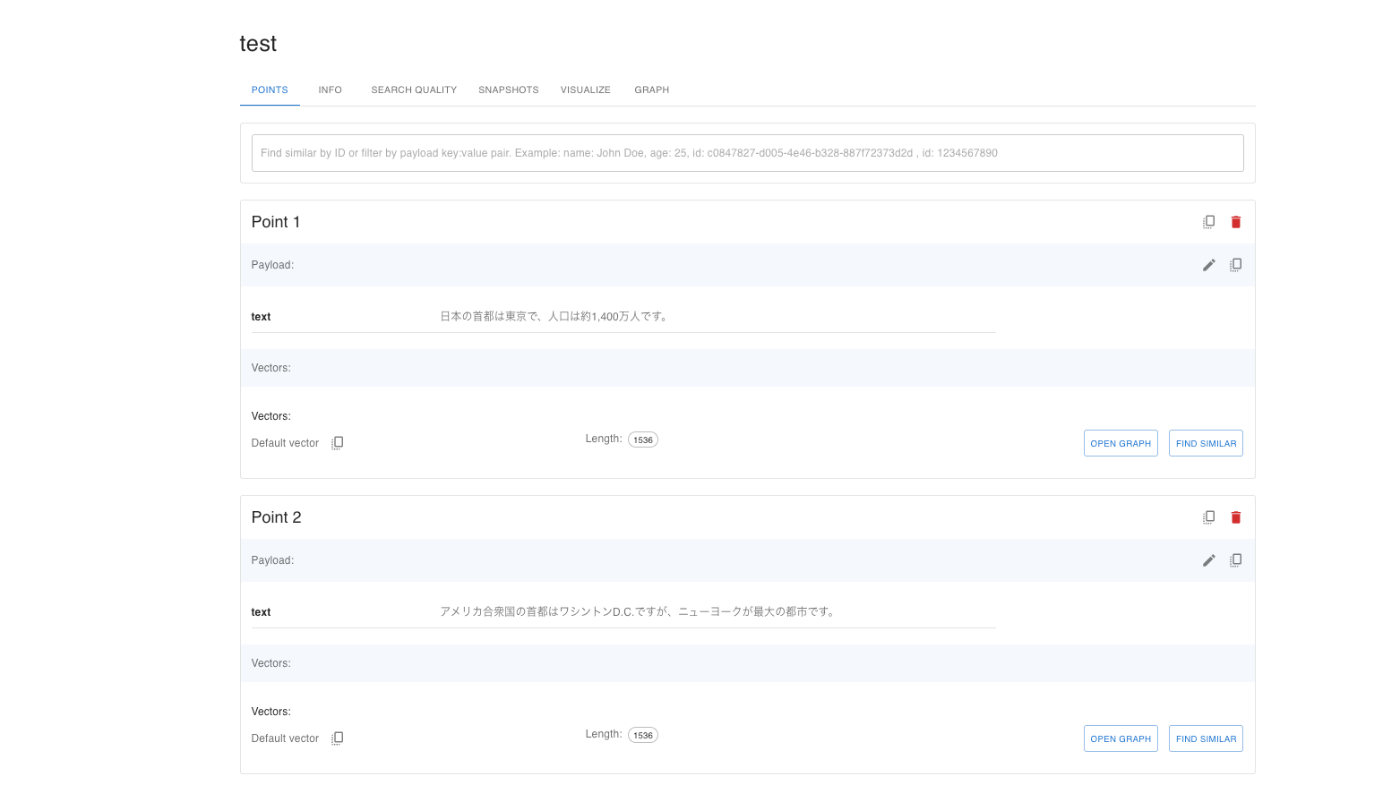
続いて手順2です。
手順2: 登録したページに関連した質問を行い、答えられるようにする。
手順2の操作で行う内部処理は具体的には以下のとおりです。
Step2-1: 質問文のベクトル化を行う。
Step2-2: 質問ベクトル情報を使い、ベクトルDBにて検索をかけてコサイン類似度の近いものを選出する
Step2-3: 取得した質問の回答に近い文章をプロンプトに含めてLLMにてテキスト生成を行う
になります。
Step2-1
質問文のベクトル化についてはStep1-3で行った処理とほぼ同じなので割愛します。
Step2-2
続いてStep2-2ですが、これを行なっているのは
internal/infrastructure/repository/article_repository.go
のFindSimilarTextsByTextメソッドになります。
// テキストデータをベクトル化し、それに近いデータをQdrantから取得する。
func (a *articleRepository) FindSimilarTextsByText(text string, limit uint64) (*[]string, error) {
// テキストのベクトル化
queryVector, err := a.openAIService.VectorizeText(text)
if err != nil {
return nil, fmt.Errorf("文章のベクトル化に失敗しました: %w", err)
}
// ベクトルの検索
queryParams := &qdrant.QueryPoints{
CollectionName: a.collectionName,
Query: qdrant.NewQuery(queryVector...),
Limit: &limit,
WithPayload: &qdrant.WithPayloadSelector{
SelectorOptions: &qdrant.WithPayloadSelector_Enable{
Enable: true,
},
},
}
searchResults, err := a.client.Query(context.Background(), queryParams)
if err != nil {
return nil, fmt.Errorf("検索に失敗しました: %w", err)
}
results := make([]SearchResult, 0, len(searchResults))
for _, point := range searchResults {
payload, ok := point.Payload["text"]
if !ok {
continue
}
text, ok := payload.GetKind().(*qdrant.Value_StringValue)
if !ok {
continue
}
results = append(results, SearchResult{
Text: text.StringValue,
Score: point.Score,
})
}
texts := make([]string, 0, len(results))
for _, result := range results {
texts = append(texts, result.Text)
}
return &texts, nil
}
ベクトルDBへの検索条件を組み立て、*qdrant.ClientのQueryメソッドで取得する、という感じですね。
Step2-3
取得した質問の回答に近い文章をプロンプトに含めてLLMにてテキスト生成を行う
これを行っているのは
internal/usecase/article_usecase.go
のAnswerQuestionになります。
// 質問に対する参照情報をQdrantから取得
referenceTexts, err := uc.articleRepository.FindSimilarTextsByText(question, 5)
if err != nil {
return "", err
}
// 取得した参照情報を改行区切りで整形
referenceText := ""
for _, text := range *referenceTexts {
referenceText += text + "\n"
}
// 参照情報を元に質問に対する回答をOpenAIに問い合わせ
prompt := `
以下の質問に対し、下記の参照情報をもとに回答を生成してください。
[質問]
` + question + `
[参照情報]
` + referenceText + `
`
// fmt.Println("prompt: ", prompt)
answer, err := uc.openAIService.GenerateText(prompt)
if err != nil {
return "", err
}
return answer, nil
}
Step2-2で取得した質問文の関連文章をプロンプトに含めてLLMに渡す感じですね。
ここでのプロンプトはこのように組み立てれます。
prompt:
以下の質問に対し、下記の情報をもとに回答を生成してください。
[質問]
日本について教えてください
[参照情報]
日本の教育制度は、小学校から中学校までが義務教育です。
日本の伝統文化には茶道や華道があり、海外でも注目されています。
日本の電車は時間に正確で、鉄道ネットワークが非常に発達しています。
日本の伝統的な服装である着物は、特別な行事で着られることが多いです。
日本の首都は東京で、人口は約1,400万人です。
これにより、前提情報ありのテキスト生成が行えることになります。
実際に動かしてみましょう。
では実際にこれらの仕組みが機能しているか、確認してみましょう。
質問はこちらを用意しました。
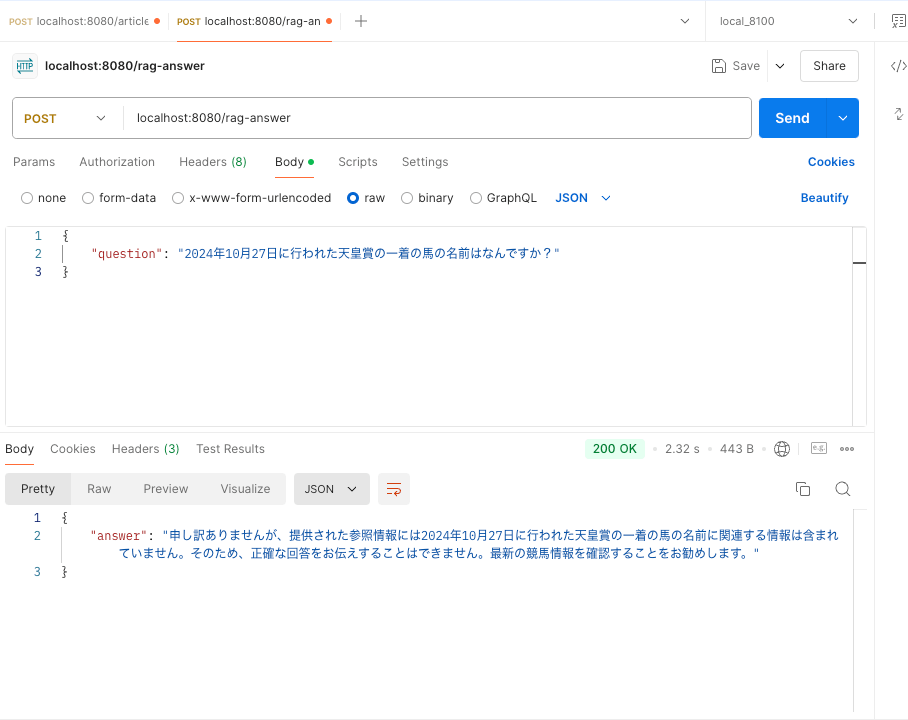
2024年10月27日に行われた天皇賞の一着の馬の名前はなんですか?
こちらのレースが行われたのは先々週です。
LLMにもデータは入っていないでしょう。(素のLLMに過去の競馬データ入っているかは知りませんが。。。)
この質問を行うと当然こうなります。
では事前情報の登録を行いましょう。
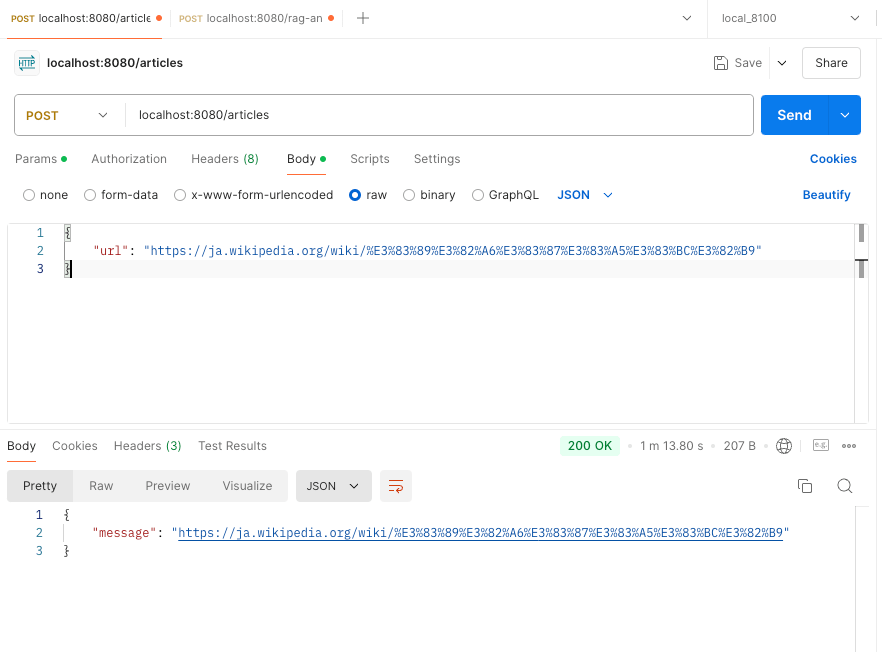
登録するページはこちら
APIを実行したところ、このように処理が成功しました。
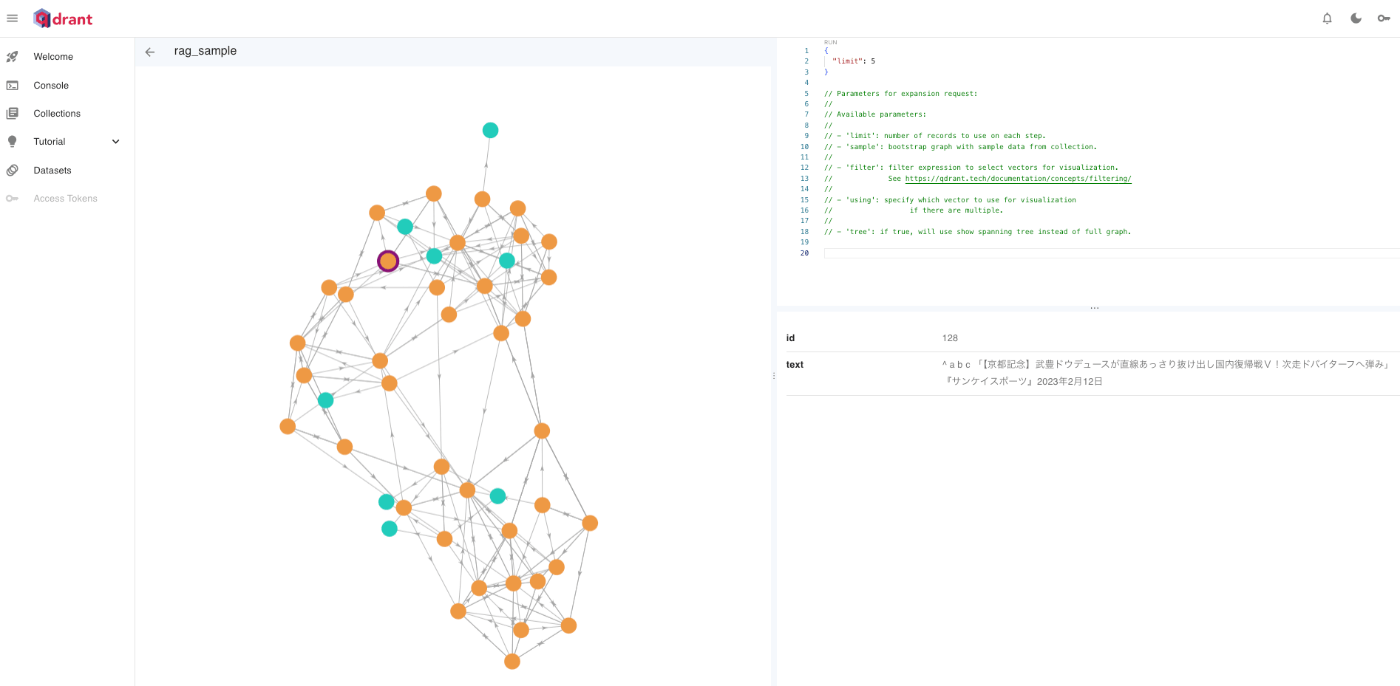
ベクトルDBにもこのようにお馬様のデータは登録されました。

ではこの状態で再度質問してみましょう。
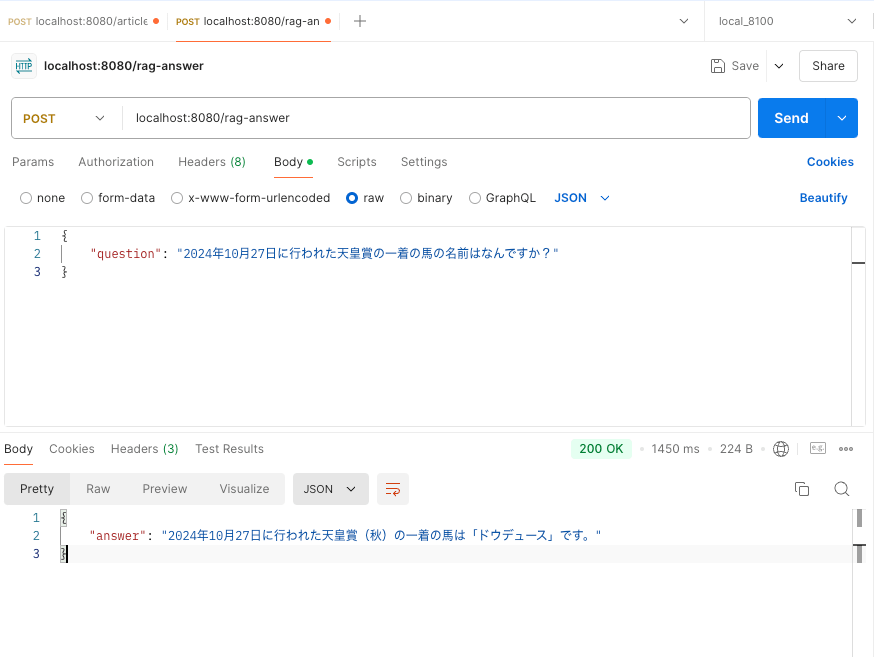
今度はバッチリですね。(流石やで、、、タッケ・・・買わなかったけど・・・)
今回のプロダクトの課題点
今回、駆け足でデータ登録 -> 出力までできるRAGシステムを作りましたが、作ってわかる、色々な問題点もあります。
ベクトルDBに登録する際に元ネタの文章量に比例して時間がかかる
やはり外部APIを使用するとそれなりに時間がかかります。
当初は検証にドナルド・トランプ氏のwikiの記事を使用しようと思ったのですが、あまりに長すぎてAPIレスポンスが全然帰ってきてくれませんでした。
あと、一応ですがこちらもお金がかかります。
こちらの記事によると、今回使用したモデルはtext-embedding-3-smallで
1M tokensあたり$0.020(約3円)となります。大体日本語は1文字1トークンです。
上記したトランプ氏の記事だと17万文字程度なので、まぁ1円以下かな。
こっちは運用によってはそこまで痛手ではないかもですね。
やはり時間。。
もし運用するなら並列&非同期でぶん回してステータス管理するなどの対応が必要でしょう。
一応ライブラリなどを組み込んで、自前でベクトル化することもできそうではありますが、、、開発コストかかるだろうな。。費用面考えても運用でカバーできそうな部分なので、もし自分で作るなら、その選択はないかな・・・
認証が必要なURLの対応
こちらも当然の話ですが、社内用のドキュメントなどでは基本的にログイン等の認証処理が必要です。
今回のようにURLを直接入力する方式だと一緒にID、パスワードも入力させる??・・・ちょいと面倒ですね。
検索用のアカウントを作ってシステム内部にログイン情報を組み込み、クローラーみたいにして自動で最新情報を取得しにいく、などの方式の方が良さそうです。
あと、人によって見せて良い情報、見せてはいけない情報などもあるでしょう。そういったセンシティブな情報の管理なども必要です。
パッと思いつくのは登録するcollectionを分けるとかですかね?
画像データなどの情報が反映されない
今回の対応はあくまでテキストデータのみです。
よって記事中に含まれる画像などからの情報取得はありません。
例えば、あまりにも複雑で文章での説明を放棄し、画像や動画データで説明している資料などからは情報の取得ができません。
画像情報のテキストデータ抽出は以前の記事でチャレンジしましたが、あまり芳しい成果は得られませんでした。が、全く可能性ゼロと言うわけでもなさそうなので頑張ればなんとかできそうな気はします。
他にも画像情報自体のベクトル化もできるので、やりようによっては対応可能かもしれませんが、今回は試していません。
あと表などの情報も検索ロジック(コサイン類似性)を考えると苦手かもしれませんね。
ガセネタの対応
これはLLMそのものにも言えるかもしれませんが、登録した記事が古くて使えない、そもそも間違っている、などの情報であっても、システムはベクトル化して登録してしまいます。
そしてテキスト生成ではそれらのガセ情報を優先度の高い情報として採用してしまいます。
この問題の対処には登録したあとに誤った情報・古い情報であると発覚した場合は削除して正しく登録し直す機能が必要です。
ベクトルデータを登録する際にpayloadで例えば元ネタURLや登録日時などを登録することで後で一括して取得・削除することが可能です。
必要に応じてこういった対応も必要でしょう。
これらの問題の解決もRAGシステム構築にあたっての腕の見せ所かもしれませんね。
まとめ
今回紹介した方法は処理の流れや概念がわかりやすく、勉強した元ネタではPythonでしたが、特別なライブラリなども使用していなかったのでGo言語でも書くことができました。
LangChainなどを使えばより簡単に、より精度高いものが作れるかもしれませんが、こういう基礎的な部分が頭に入っていると便利ライブラリ使う時にもより上手く使うことができるようになると思います。
生成AIがどんどん便利になり、すぐアンサーが得られる時代においても急がば回れというのは案外大切なのかもしれません。
最後に
皆さん、この記事を最後まで読んでいただき、ありがとうございます。私たちのプロジェクトや技術的な挑戦に興味を持っていただけたなら、さらに嬉しい限りです。そして、この機会に弊社「株式会社バニッシュ・スタンダード」では現在エンジニア、デザイナーを積極的に探していることをお伝えしたいと思います。
私たちは会社のミッションである「つまらない常識を革めるプロダクトを開発し、おもしろく生きる人で世界をいっぱいにする。」を実現するため、この理念に共感してくれる新たな仲間を求めています。
私たちと一緒に、技術の最前線で働き、新しい未来を創造していきませんか?あなたの才能と情熱を、私たちのチームで発揮してください。興味のある方は、ぜひお問い合わせください。私たちはあなたからの応募を心からお待ちしています。

Discussion