バニッシュ・スタンダードでアーキテクトやってる小林です。
Zoom会議で子供がやたらカットインすることがあってそれ以来「パパ」と呼ばれており、代表との1on1で「パパ活」とカレンダーのタイトルに入れられて社内が騒然としてましたが、普通に1on1です。
さて、とりあえず技術負債とか書いておけばある程度PV稼げそうってのを狙いつつ、その中でもパフォーマンス系の話を今回はしたいと思います。
サービス初期の頃はデータが少ないので、割とどんな作りでもそれなりのパフォーマンスが出ていたようですが、私の入社時点でも金の弾丸で回避してる部分もありましたが、さらにデータ量が増えてくると色々と無理が出てきて、金の弾丸ではなかなか難しいこともあり、各種改善したことを記述します。初歩的なものも結構ありますが、その辺は軽く読み流していただけると幸いです。SREチームでやっている取り組みで、みんながみんなこんなことをずっとやっているわけではないのでご安心ください。
スタッフ一覧APIでの最新コンテンツ順並べ替え
問題点
APIにアクセスの度にスタッフごとの最新コンテンツを取得して並べ替えるということをやっており、集計して並べ替えというRDBMS的にはあまり軽いとは言えない処理となっていました。
改善点
そもそもコンテンツを投稿したときにしか更新されないわけなので、コンテンツ更新時に最新のコンテンツのテーブルを作成し、そっちを参照することで改善しました。ただ、未来のコンテンツがあるので、公開日到達の時点で更新したいという要件もあるため、スケジュールでも発火可能ということでSidekiqで行っています。秒単位でシビアな要件なわけでもないのと、発火までのタイムラグより実行環境間の時刻の差が大きい場合に問題があるため、今となっては毎分対象探して実行するバッチでも良かったかなと思うところではあります。
コンテンツの検索
問題点
例えばコーディネートの場合、コーディネート検索といいつつ、コーディネートそのものの属性(メンズ/レディースとか投稿した店舗とか)だけではなく、投稿したスタッフの属性(身長、性別、体型など)、紐づいた商品の属性(商品のカテゴリーとか色とかサイズとか)、タグとかでも検索できるAPIになっていましたが、RDBMSで頑張っていたため、APIとして考えると非常に遅くなることがありました。
改善点
Elasticsearchを導入し、スタッフ一覧API改善で導入済みのSidekiqを用いて非同期で更新するようにしました。これで95パーセンタイルでレスポンスタイム100ms程度には収まるようになりました。
バッチの多重起動、依存関係のあるバッチ
問題点
定期的に実行しているバッチが、おそらく最初はこれぐらいで終わるだろうと見積もっていたのかもしれないけど、その時間には終わらなくて多重起動してより遅くなるという問題がありました。幸いデータ不整合がなかったとはいえ、あまり健全な状態とは言えませんでした。
また、依存関係のあるバッチも大体これぐらいで終わるだろうな時間で起動するという、よくあるといえばよくある形で、そもそもトータルの時間が無駄に長くなるのと、想定した時間で終わらないまま後続バッチが動いたため、再度後続バッチを手動実行するとか、その分さらに後ろにずらすという運用回避であったり、ずらす際にちょっと余裕を見て、とやるとまたトータルの実行時間が長く、というスパイラルに陥っていました。
改善点
そもそも処理時間伸びている事自体の改善は別項目で。
多重起動については、データベース上にロック用のテーブルを作り、ロック中には実行しないようにしました。突然死してロックつかみっぱなしだとまずいので、一定時間以上ロックされてるとアラートするところまでをセットで。
依存関係のあるバッチについては、歴史的経緯で環境またがっているのもあるので単純にシェルスクリプトでつなげるわけにもいかなく、Step Functionsを導入して依存関係を定義して実行するようにしました。Step Functions自体の問題でFargateタスクの起動が失敗したり、最近はFargateタスクがタイミングによりCapacity不足で起動しなかったりというのが起こりがちなので再実行も仕込んだりという形になっています。
トラッキングデータの保存
問題点
改善前は受信時にRedisに投入して、そこからバッチ処理でDBにINSERTするようになっていましたが、バッチ内で1レコードごとに商品情報やコンテンツ情報を取得する作りになっており、データ量が多くなるとRDBMSとの通信が多くなり、処理時間が伸びていくようになりました。売上に対するPVを見てコンバージョンを立てるという仕組みで、Redis内データ取得時に時刻順であることが保証できない形式で、一揃いのデータであることを保証できている状態にして、コンバージョンを立てる処理をしないと、コンバージョンを立てる処理の途中に中途半端なデータが入ってくると集計が狂うことになるため、同じバッチ上で実行する必要がありました。そのため、1バッチの実行時間が長くなっていました。さらに処理時間が伸びるとその分未処理トラッキングデータが溜まってくるわけで、集計までのタイムラグが加速度的に伸びるという状況もありました。
改善点
ちょうど構成図があったので貼っておきます。
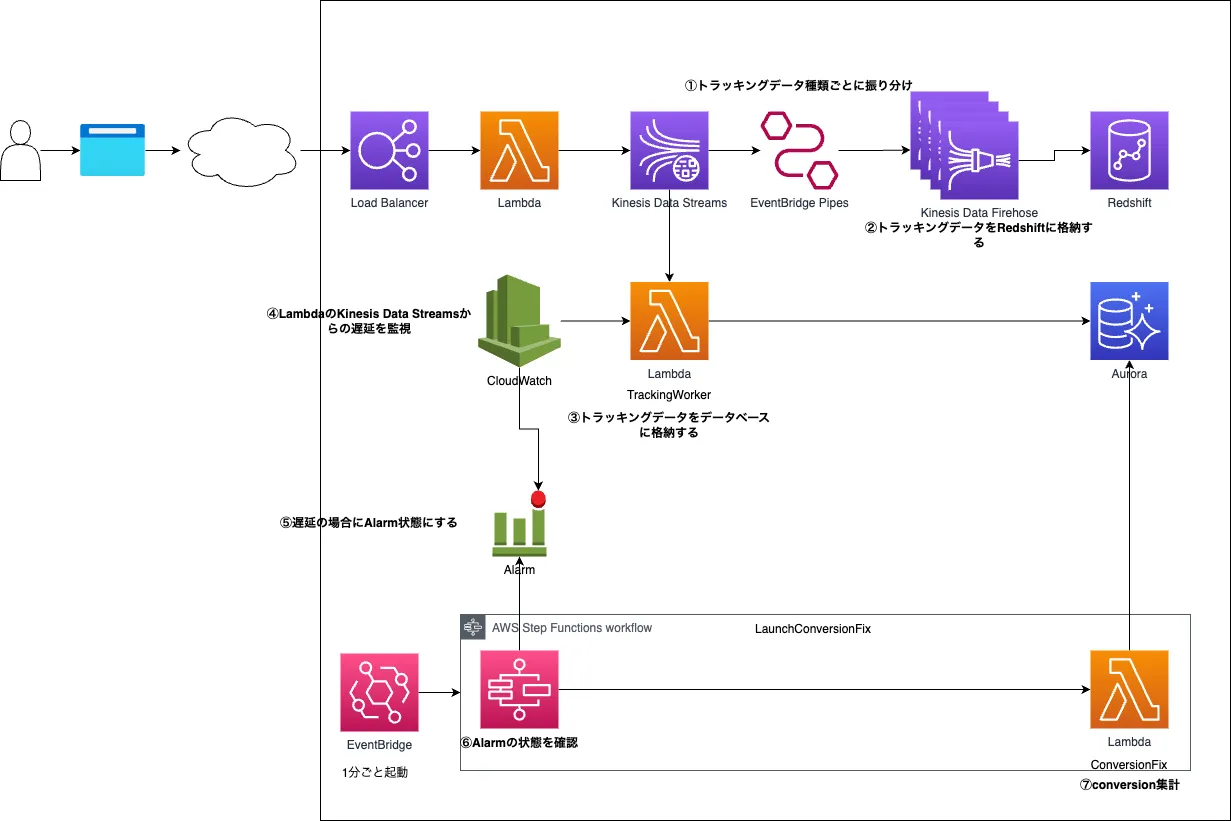
上記のような形でKinesis Data StreamsからLambda Functionを起動することで、一定間隔あるいは一定量溜まったら実行という形を実現し、極力リアルタイムで処理をしつつスパイクしないようにという作りにしています。処理が可能な量に対してデータが多い場合は若干の遅延が発生することになりますが、元の数時間レベルの遅延は起こらないようになりました。15分以上遅延すると通知するようにしていますが、今のところは当該通知を受け取ることは非常に稀です。さらに、中の処理についても1トラッキングレコードについて商品情報やコンテンツ情報をまとめて取得するような処理にすることでRDBMSとの通信回数を減らして遅延を少なくしています。これはRDBMSや、処理するLambda Functionの負荷をあげることにはなりますが、そもそも負荷自体はそこまでかかっておらず、遅延のみが目立っていたため、今回はまとめて処理するほうがメリットが大きいという判断です。
また、コンバージョンを立てる処理をトラッキングデータをDBにいれる処理とは別で実行することでもコンバージョンを立てる処理の遅延も小さくしています。さらにLambdaを使うことで二重起動することも防いでいます。
コンバージョンを立てる処理も非効率な部分が多かったり、ある程度並列処理が可能な部分もあるので、そのあたりの改善を現在進めているところです。
ランキング機能
問題点
ちょっとパフォーマンス改善とは話題が違いますが、PV順や売上順のランキングについて、もともとは値の上書きをしているため、処理中は微妙に順位がずれる状態でした。データ量が少ない場合には処理時間が短いのでそれほど問題にはなりにくいのと、そもそもリアルタイムに順位を調べて見比べるわけにもいかないので、問題が顕在化していませんでした。
改善点
処理中のPV/売上とソートに使うPV/売上の項目を分け、それらを切り替える形にすることで不整合が生じないようにしました。
項目名が迷うところでした。表裏なんでA面B面だからpv_aとpv_bって感じでいいだろうって思ったんですが、A面B面ってもう若者には通じないじゃないかと。結果pv_1とpv_2になったのがちょっとモヤモヤするところでした。
日毎のPV集計
問題点
PVの該当テーブルを集計したデータをSELECTして、それぞれの行に対して必要な付加情報をSELECTして取得しており、RDBMSとの通信回数が増え、処理時間が長くなっていました。
改善点
一旦今のデータ量だとJOINしてしまった方が速いのでJOINして取得する形に。この対応時にはなかったReshiftの環境が今はあるので、今のやり方で限界が来たらそっちに処理をさせるような形も今後考えたいです。
分析機能のランキングの母数集計
問題点
分析機能が別のRDBMSとAPIで管理されており(これはこれで改善の余地があるが)、店舗内のランキングなどを計算する際、コンテンツがあるユーザ数などを母数にしているのですが、元システムのバッチで店舗ごとに集計したデータを分析機能のAPIを呼び出して登録するようになっていました。つまり登録店舗数分呼び出しすることになり、非常に時間がかかっていました。
改善点
転送用データを入れる中間テーブルを作ってINSERTし、最後そのテーブルのデータを分析機能があるRDBMSに転送する形としました。割とあちこちに中間テーブルを作れば改善する箇所があるのですが、直接参照されないテーブルを作りたくないのかな?というシステムは本システムに限らず多いです。
まとめ
ここに記述したものは、まるっと作り直すようなことをしないといけなかったものだったりはします。初期の初期は当たるかどうかわからなくてとりあえず動くものを作りました、みたいなものは割とよくあると思います。とはいえもうちょいなんとかなっただろとかはあると思います。入社当初はちょいちょい苛つくぐらいでした。実は一番苦労したのが既存のコードを読み解くことだったりしてさらに苛つくみたいなこともありました。
が、今では新たな問題が見つかるとちょっとワクワクする部分が無くもないぐらいにはなりました。(でもたまに...)この手の活動って地味ではあるのですが、よくなることはあっても悪くなることってまずないので、そういう意味では気持ちが楽だったりします。
火がつきそうなものを優先的に対応してはいたものの、出火までに間に合わなかったりすることもありましたが、だいぶ改善できたかなと思います。さらにデータ量やアクセス量が増えてくると出てくる問題などもあるので、これからも改善の活動は欠かせません。こんな活動を手伝ってくれる人がもっと増えるといいなと願っています。
ここもうちょっと詳しく知りたい!みたいな意見があれば、細かいところも(差し支えない範囲で)説明したいと思います。

Discussion