GCPの料金削減をしたい
はじめに
Google Cloud Platform(GCP)はその柔軟性、スケーラビリティ、強力なクラウドサービスのラインナップで、企業や開発者から高い支持を受けています。しかし、少しの油断で予想外の高額請求に直面することもあります。多くの人がGCPの料金に関して、何百万円もの損失を経験した話を聞いたことがあるでしょう。
今回はVoicyで行ったコスト削減の取り組みについて紹介します。
削減の流れ
- 分析と方針の決定
- BigQueryの使用料金内訳確認←今回の記事はここまで
- BigQueryのコスト削減
- 定期実行頻度の見直し
- コストのアラートと上限設定
- 結果
- 今後の改善に向けて
分析と方針の決定
まず、現在のGCPの使用状況を徹底的に分析しました。どのサービスにどれだけの費用がかかっているか、使用率はどれくらいか、そして不要なリソースがないか等を確認しました。この分析を基に、コスト削減のための具体的な方針を決定しました。
こちらが実際に使用している内訳です。
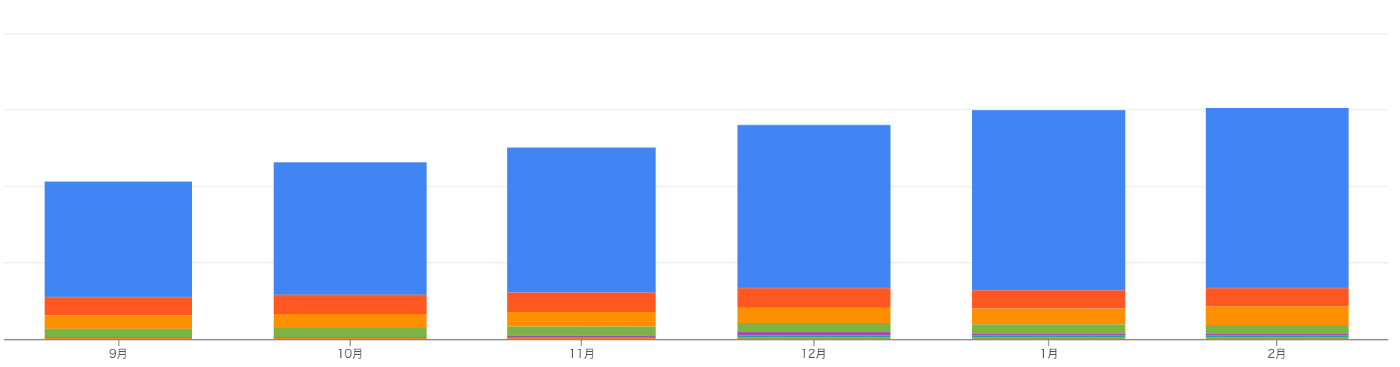
画像の説明:
青:BigQuery
橙:Cloud Composer
黄:Cloud Storage
その他:…
BigQueryの使用料金が目立って高いことが分かります。全体の約77%がBigQueryに関連するコストです。
これにはいくつかの理由がありますが、主なものは以下の通りです。
- Voicyには数百万の会員がおり、非会員のWebユーザーも含めると、アクセスログの数が多くなります。
- アプリの各行動に対して詳細にログを取得しているため、一般的なWebサイト分析と比べて1ユーザーあたりのレコード数が数倍になります。
- 社内分析やパーソナリティ向けのデータ提供など、定期的に実行される処理が多いです。
- SQLの積極的な利用を社内で推奨した結果、長期にわたり高額なSQLクエリが作成されてしまっています。
BigQueryの使用料金内訳確認
BigQueryが主要なコスト要因であることが分かったため、詳細な分析を進めました。Cloud Functions、Cloud Scheduler、Pub/Subを使用して、実際に利用されたリソースをSQL単位で記録しました。
実装コード
Cloud Schedulerを用いて、以下のコードを毎日1回実行し、前日に使用したリソースを把握します。GCPの料金については、公式ドキュメントを参照してください。
from google.cloud import bigquery
from google.api_core.exceptions import NotFound
import pytz
from datetime import datetime, timedelta, timezone
def hello_world(event, context):
client = bigquery.Client()
yesterday = datetime.now(timezone.utc) - timedelta(days=1)
yesterday_start = datetime(yesterday.year, yesterday.month, yesterday.day, 0, 0, 0, 0, timezone.utc)
yesterday_end = datetime(yesterday.year, yesterday.month, yesterday.day, 23, 59, 59, 999999, timezone.utc)
def list_jobs(client):
return client.list_jobs(max_results=1000000, min_creation_time=yesterday_start, max_creation_time=yesterday_end, all_users=True, state_filter="done")
records = list_jobs(client)
def build_records(jobs):
ja_timezone = pytz.timezone('Asia/Tokyo')
RATE = 6.25 * 148 #現在のドル円為替を入れてください
BYTES2TiB = 1099511627776
mylist = []
for job in jobs:
try:
# クエリジョブであるかどうかをチェック
if hasattr(job, 'total_bytes_billed') and job.total_bytes_billed is not None and job.total_bytes_billed > 0:
alls = [
job.user_email,
job.job_id,
job.total_bytes_billed,
job.total_bytes_billed * RATE / BYTES2TiB, #料金設定に応じて設定してください
job.created,
job.query if hasattr(job, 'query') else 'N/A',
job.project
]
mylist.append(alls)
except Exception as e:
print(f"Error processing job {getattr(job, 'job_id', 'Unknown Job ID')}: {e}")
return mylist
df = build_records(records)
schema = [
bigquery.SchemaField("user_email", "STRING", mode="NULLABLE"),
bigquery.SchemaField("jobid", "STRING", mode="NULLABLE"),
bigquery.SchemaField("total_byte", "INT64", mode="NULLABLE"),
bigquery.SchemaField("prices", "FLOAT64", mode="NULLABLE"),
bigquery.SchemaField("time", "TIMESTAMP", mode="NULLABLE"),
bigquery.SchemaField("query", "STRING", mode="NULLABLE"),
bigquery.SchemaField("project_id", "STRING", mode="NULLABLE"),
]
dt_string = yesterday_start.strftime("%Y%m%d")
table_id = "project-id.dataset-name.bigquery_cost_" + dt_string
try:
table = client.get_table(table_id)
except NotFound:
table = bigquery.Table(table_id, schema=schema)
table = client.create_table(table)
print(f"Created table {table_id}")
# データをバッチで挿入する
batch_size = 500
for i in range(0, len(df), batch_size):
batch = df[i:i+batch_size]
errors = client.insert_rows(table, batch)
if errors:
print(f"Data insertion errors: {errors}")
else:
print(f"Batch {i // batch_size + 1} inserted successfully.")
bigquery
Credentials
datetime
slackweb
実行結果として得られるテーブルは、次のようになります。

このテーブルを基にした分析から、以下のような内訳が明らかになりました。
- 定期実行処理:80%
- データチームが想定していなかった長期間のSQL実行:10%
- その他の通常BIツール利用:10%
一部の長期実行SQLでは、1回あたり数千円のコストが発生していることも分かりました。
この問題の原因は、データの民主化を推進する際にMetabaseというBIツールを導入したことにあります。Metabaseでは、ユーザーごとに実行を追跡できるものの、すべての実行が単一のアカウントに紐づいているため、料金をBIツールの利用ユーザー単位で制限することができませんでした。また、料金の監視を全体的にしか行っていなかったため、この問題が発生しました。
料金の内訳を把握できたため、次の記事では具体的な削減方法について紹介します。
Discussion