前回 vLLM V1の概要に触れましたが、その具体的な実装は見ませんでした。
C++/CUDA の実装まで踏み込むとなかなか大変ですので、Python の範囲で V1がどのような構成になっているかを追っていきます。
アーキテクチャ概要
vLLM の全体的なアーキテクチャはだいたいこんな感じになっています (適宜拡大してください)
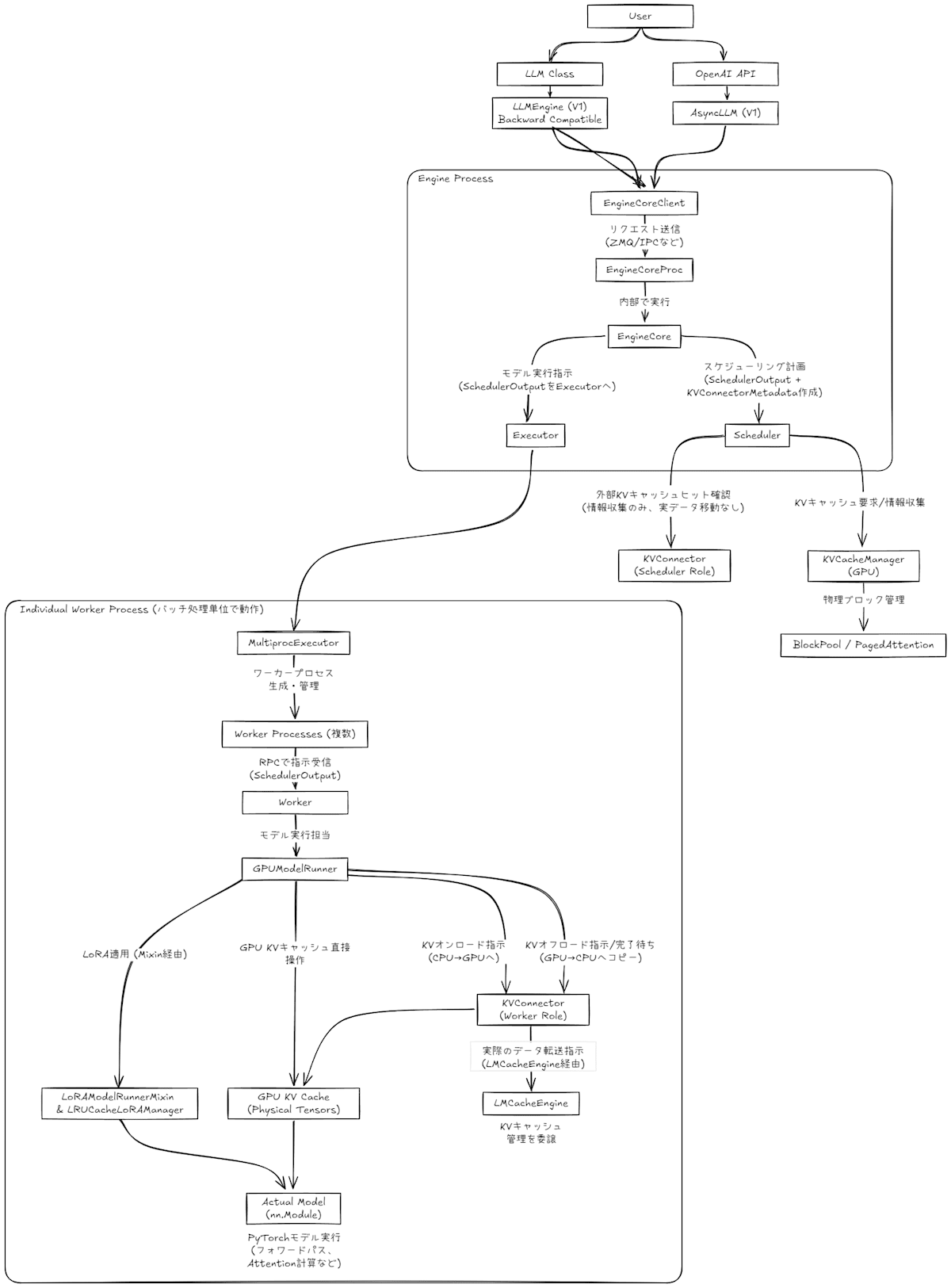
今回特に注目するのは、LLM クラスや OpenAI 互換 API といった vLLM の主要なエントリーポイントから呼び出され、最終的に V1のコア処理へと橋渡しする EngineCoreClient およびその関連コンポーネント群です。
具体的には以下の図で示される範囲が本記事のスコープとなります。
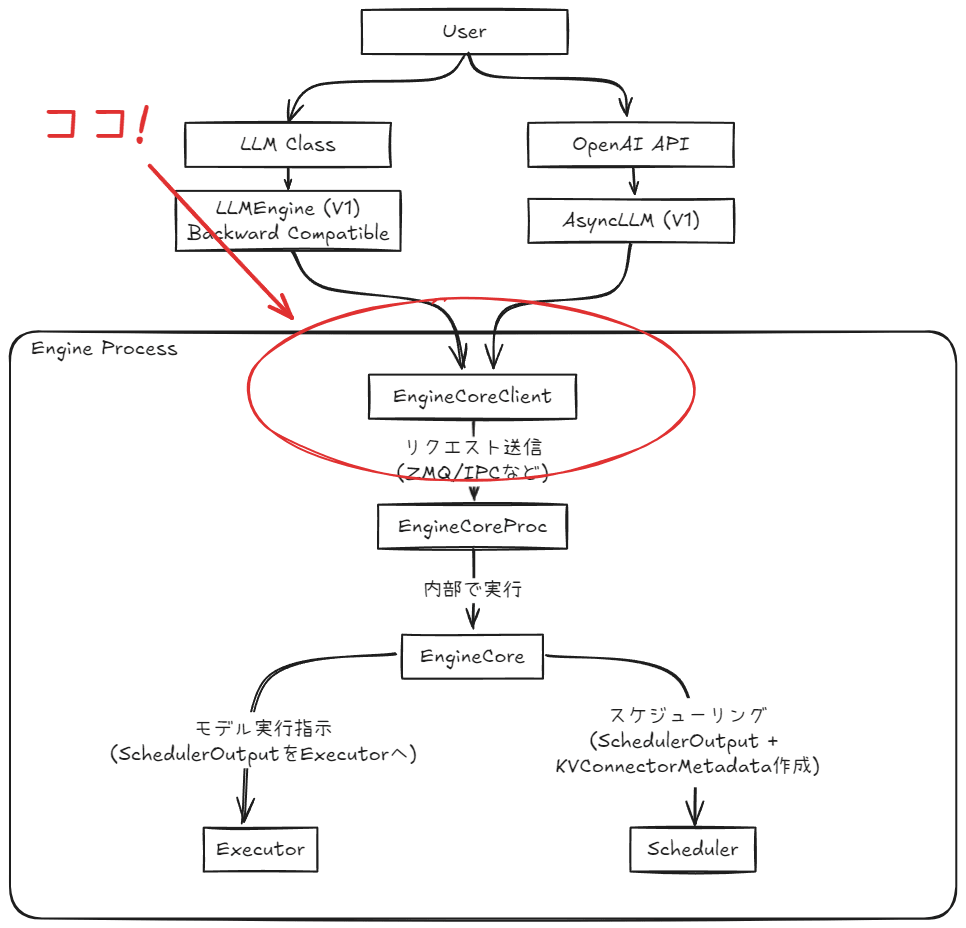
本記事で登場する主要コンポーネント
この記事では、以下のコンポーネントを中心に確認を進めます。
-
EngineCoreClient: 推論処理を管理する中核、EngineCoreへのアクセスインタフェースとなる抽象基底クラスです。 -
InprocClient:EngineCoreと同一プロセス内で同期的に直接通信するクライアントです。vLLM v0に近いシンプルな動作モデルを提供するとされています。 -
MPClient:EngineCoreを別プロセスで実行するための共通基盤を提供するクラスです。これ自体が直接利用されるのではなく、以下の派生クラスのベースとなります。-
SyncMPClient: マルチプロセス環境において、同期的な通信を実現するクライアントです。 -
AsyncMPClient: Python のasyncioを活用し、ノンブロッキングな非同期通信を実現するクライアントです。 -
DPAsyncMPClient: データ並列処理に対応し、複数のエンジンインスタンスにリクエストを分散する非同期クライアントです。
-
- プロセス間通信には ZMQ と Msgpack が利用され、エンジン実行プロセスの管理は
CoreEngineProcManagerが担います。
EngineCoreClient の役割
EngineCoreClient は、vLLM V1のエンジンコア (EngineCore) との通信するクライアントインタフェースの抽象基底クラスです。
このクラスの目的は、エンジンコアの具体的な実装詳細をカプセル化しつつ、様々な通信方式(同一プロセス/別プロセス、同期的/非同期的)でエンジンコアと対話するための統一的な手段を提供することにあります。
EngineCoreClient は、まずファクトリメソッド make_client を提供し、設定に応じた具象クライアントインスタンスを生成します。
class EngineCoreClient(ABC):
@staticmethod
def make_client(
multiprocess_mode: bool,
asyncio_mode: bool,
vllm_config: VllmConfig,
executor_class: Type[Executor],
log_stats: bool,
) -> "EngineCoreClient":
if asyncio_mode and not multiprocess_mode:
raise NotImplementedError(
"Running EngineCore in asyncio without multiprocessing "
"is not currently supported.")
# ... (クライアント選択ロジック) ...
return InprocClient(vllm_config, executor_class, log_stats) # デフォルトフォールバックなど
# ...
そして、サブクラスで実装されるべき多数の抽象メソッドを定義します。主要なものとして、リクエストの追加、結果の取得、シャットダウンなどがあります。
# class EngineCoreClient(ABC): (続き)
@abstractmethod
def shutdown(self):
raise NotImplementedError
def get_output(self) -> EngineCoreOutputs:
raise NotImplementedError
def add_request(self, request: EngineCoreRequest) -> None:
raise NotImplementedError
async def get_output_async(self) -> EngineCoreOutputs:
raise NotImplementedError
async def add_request_async(self, request: EngineCoreRequest) -> None:
raise NotImplementedError
# ... (その他多数の同期・非同期の抽象メソッド) ...
InprocClient: 同一プロセス内での直接通信
InprocClient は、エンジンコア (EngineCore) とクライアントが同一プロセス内で動作するシナリオのための実装です。コンストラクタで EngineCore のインスタンスを保持し、各メソッド呼び出しを直接委譲します。
class InprocClient(EngineCoreClient):
def __init__(self, *args, **kwargs): # vllm_config 等を受け取る
self.engine_core = EngineCore(*args, **kwargs)
def get_output(self) -> EngineCoreOutputs:
return self.engine_core.step()
def add_request(self, request: EngineCoreRequest) -> None:
self.engine_core.add_request(request)
# ... (他の同期メソッドも同様にEngineCoreに委譲) ...
この方式は、vLLM の docstring によれば「V0-style LLMEngine use」とされ、v0に近いシンプルな動作を提供します。EngineCoreClient の非同期 API(add_request_async など)はオーバーライドしておらず、呼び出すと NotImplementedError となります。
MPClient: マルチプロセス実行の共通基盤
MPClient は、エンジンコアを別プロセスで実行するための共通基盤を提供します。プロセス間通信には ZMQ と Msgpack を利用します。
- ZMQ (ZeroMQ): 高性能な非同期メッセージングライブラリです。詳細は公式サイトを参照してください。
- Msgpack: バイナリシリアライズフォーマットです。詳細は公式サイトを参照してください。
MPClient の __init__ では、これらのセットアップとエンジンプロセス管理の準備をします。
まず、基本的な設定とシリアライザを初期化します。
class MPClient(EngineCoreClient):
def __init__(
self,
asyncio_mode: bool,
vllm_config: VllmConfig,
executor_class: Type[Executor],
log_stats: bool,
):
self.vllm_config = vllm_config
self.encoder = MsgpackEncoder()
self.decoder = MsgpackDecoder(EngineCoreOutputs)
# ...
次に ZMQ コンテキストとリソース管理機構 (BackgroundResources, _finalizer) を設定します。
# class MPClient(EngineCoreClient): def __init__(...): (続き)
sync_ctx = zmq.Context(io_threads=2)
self.ctx = zmq.asyncio.Context(sync_ctx) if asyncio_mode else sync_ctx
self.resources = BackgroundResources(ctx=sync_ctx)
self._finalizer = weakref.finalize(self, self.resources)
# ...
データ並列設定に基づき管理対象の CoreEngine 情報を準備し (self.core_engines)、通信用アドレスを決定後、ZMQ ソケットを作成します。
# class MPClient(EngineCoreClient): def __init__(...): (続き)
try:
# ... (parallel_config に基づく self.core_engines の初期化) ...
# ... (_get_zmq_addresses による input_address, output_address の決定) ...
self.input_socket = self.resources.input_socket = make_zmq_socket(...)
self.resources.output_socket = make_zmq_socket(...)
# ...
ローカルエンジンプロセスを CoreEngineProcManager で起動し、初期同期 (_wait_for_engine_startup) を行います。
# class MPClient(EngineCoreClient): def __init__(...): (続き)
if local_engine_count > 0: # parallel_config から導出
self.resources.local_engine_manager = CoreEngineProcManager(
EngineCoreProc.run_engine_core, ...)
self.core_engine = self.core_engines[0] # デフォルトエンジン
self._wait_for_engine_startup(output_address, parallel_config)
self.utility_results: dict[int, AnyFuture] = {}
self.pending_messages: deque[tuple[zmq.MessageTracker, Any]] = deque()
success = True
finally:
if not success: self._finalizer()
MPClient が提供する共通処理(初期設定、アドレス解決、リソース管理、状態監視、メモリ管理)により、サブクラスは通信ロジックに専念できます。
様々な実行形態への対応: MPClient の派生クラス群
MPClient を基底として、具体的な実行ニーズに合わせたクライアント実装が提供されています。
SyncMPClient: 同期マルチプロセスクライアント
SyncMPClient は EngineCoreClient の同期 API を実装します。__init__ で MPClient を asyncio_mode=False で初期化し、出力受信用に queue.Queue とバックグラウンドスレッドを準備します。
class SyncMPClient(MPClient):
def __init__(self, vllm_config: VllmConfig, executor_class: Type[Executor],
log_stats: bool):
super().__init__(asyncio_mode=False, vllm_config=vllm_config, /* ... */)
self.outputs_queue: queue.Queue[Union[EngineCoreOutputs, Exception]] = queue.Queue()
# バックグラウンドスレッド(self.output_queue_thread)で出力ソケットを処理する
# process_outputs_socket (ローカル関数) を起動
# ...
get_output はキューから同期的に結果を取得し、add_request は内部の _send_input を介してエンジンにリクエストを同期送信します。ユーティリティ機能は call_utility で実行されます。
# class SyncMPClient(MPClient): (続き)
def get_output(self) -> EngineCoreOutputs:
outputs = self.outputs_queue.get() # ブロックして結果取得
# ... (エラー処理) ...
return outputs
def add_request(self, request: EngineCoreRequest) -> None:
self._send_input(EngineCoreRequestType.ADD, request) # _send_inputで同期送信
def call_utility(self, method: str, *args) -> Any:
# ... (Futureとutility_resultsで結果を同期的に待つ) ...
pass
AsyncMPClient: 非同期マルチプロセスクライアント
AsyncMPClient は EngineCoreClient の非同期 API を実装します。__init__ で MPClient を asyncio_mode=True で初期化し、出力受信用に asyncio.Queue と非同期タスクを準備します。
class AsyncMPClient(MPClient):
def __init__(self, vllm_config: VllmConfig, executor_class: Type[Executor],
log_stats: bool):
super().__init__(asyncio_mode=True, vllm_config=vllm_config, /* ... */)
self.outputs_queue: asyncio.Queue[Union[EngineCoreOutputs, Exception]] = asyncio.Queue()
# _ensure_output_queue_task で出力ソケットを処理する
# process_outputs_socket (ローカル非同期関数) を非同期タスクとして起動
# ...
get_output_async は asyncio.Queue から非同期に結果を取得し、add_request_async は内部の _send_input (または _send_input_message) を介してエンジンにリクエストを非同期送信します。ユーティリティ機能は call_utility_async で実行されます。
# class AsyncMPClient(MPClient): (続き)
async def get_output_async(self) -> EngineCoreOutputs:
self._ensure_output_queue_task()
outputs = await self.outputs_queue.get() # 非同期に結果取得
# ... (エラー処理) ...
return outputs
async def add_request_async(self, request: EngineCoreRequest) -> None:
await self._send_input(EngineCoreRequestType.ADD, request) # _send_inputで非同期送信
self._ensure_output_queue_task()
async def call_utility_async(self, method: str, *args) -> Any:
# ... (asyncio.Futureとutility_resultsで結果を非同期に待つ) ...
pass
DPAsyncMPClient: データ並列対応 非同期マルチプロセスクライアント
DPAsyncMPClient は AsyncMPClient を拡張し、複数のエンジンインスタンスへのリクエスト分散とウェーブ同期を行います。
class DPAsyncMPClient(AsyncMPClient):
def __init__(self, vllm_config: VllmConfig, executor_class: Type[Executor],
log_stats: bool):
self.current_wave = 0
self.engines_running = False
self.reqs_in_flight: dict[str, CoreEngine] = {}
super().__init__(vllm_config, executor_class, log_stats)
assert len(self.core_engines) > 1
# ...
add_request_async では、get_core_engine_for_request でエンジンを選択し、 _start_wave_coros で他エンジンにウェーブ開始を通知します。
# class DPAsyncMPClient(AsyncMPClient): (続き)
async def add_request_async(self, request: EngineCoreRequest) -> None:
request.current_wave = self.current_wave
chosen_engine = self.get_core_engine_for_request()
# ... (reqs_in_flight, num_reqs_in_flight の更新) ...
to_await = self._send_input(EngineCoreRequestType.ADD, request, chosen_engine)
if not self.engines_running:
self.engines_running = True
to_await = asyncio.gather(to_await, *self._start_wave_coros(...))
await to_await
self._ensure_output_queue_task()
def get_core_engine_for_request(self) -> CoreEngine:
return min(self.core_engines, key=lambda e: e.num_reqs_in_flight)
# ...
エンジンからの出力はスタティックメソッド process_engine_outputs で処理され、ウェーブ状態が管理されます。
# class DPAsyncMPClient(AsyncMPClient): (続き)
@staticmethod
async def process_engine_outputs(self: "DPAsyncMPClient", outputs: EngineCoreOutputs):
# ... (reqs_in_flight の更新) ...
if outputs.wave_complete is not None:
# ... (ウェーブ完了時の処理) ...
pass
elif outputs.start_wave is not None: # and 条件 ...
# ... (エンジンが新しいウェーブを開始した場合の処理と _start_wave_coros の呼び出し) ...
pass
これらのクライアント実装の比較を以下に示します。
| クライアント | 通信方法 | 主な特徴 | データ並列 |
|---|---|---|---|
InprocClient |
同期 | 同一プロセス内で直接呼び出し、低オーバーヘッド | 非対応 |
SyncMPClient |
同期 | 別プロセスとZMQ通信、ブロッキング処理、スレッドベースの出力ハンドリング | 非対応 |
AsyncMPClient |
非同期 | 別プロセスとZMQ通信、ノンブロッキング処理、asyncio タスクベースの出力ハンドリング |
非対応 |
DPAsyncMPClient |
非同期 |
AsyncMPClient に加え、複数エンジンへのリクエスト分散、ウェーブ管理 |
対応 |
EngineCoreClient が示すアーキテクチャ特性とv0からの変化
EngineCoreClient とその多様なサブクラス群は、vLLM V1アーキテクチャが持ついくつかの重要な特性を示しています。
- 疎結合性:
EngineCoreの実装とクライアント側の実装は、インタフェースおよびプロトコルによって明確に分離されています。 - 柔軟性: 同一プロセス/別プロセス、同期/非同期、シングルエンジン/データ並列など、多様な実行モデルを選択可能です。
- スケーラビリティ:
AsyncMPClientやDPAsyncMPClientは高スループットやスケールアウトの基盤を提供します。
これらのクライアントクラス群は、推論エンジン本体を制御・管理するマネージャー的な役割を担います。
vLLM のコードベースから、v0と比較して v1では以下の点が強化されたと見受けられます。
- プロセスモデルの多様化:
InprocClientの「V0-style」記述に対し、MPClient系は別プロセス実行モデルを強化しています。 - 非同期処理の拡充:
AsyncMPClient系の導入によりasyncioベースの非同期処理を広範にサポートしています。 - データ並列処理の明示的なサポート:
DPAsyncMPClientによる複数エンジン管理とウェーブ同期が実現されています。 - 通信メカニズムの標準化の進展: ZMQ と Msgpack の採用による堅牢な分散推論基盤が構築されています。
所感として、かなり商用構成を見越した設計になっている印象を受けます。ただ動かすだけでなく、スケールアウトや高スループットを意識した設計をしたいという意図が感じられ、やはり vLLM はただの推論ライブラリではなく、サービスのバックエンドとして安定して動作することを目指している…ような気がします。
おわりに
vLLM V1におけるエンジンクライアント EngineCoreClient とその多様なサブクラスの役割、構造、連携の仕組みを追ってみました。内部構造や設計思想に関心を持つ読者にとって、理解の一助となれば良いなと思います。

Discussion