いつの間にか LangGraph Supervisor というものがリリースされていたのに気づきました。
ぱっと見た感じ、関数を1つ呼び出すだけで Supervisor 型(階層型)エージェントを容易に作成できるようです。
コードを見ていると create_react_agent のインタフェースがパブリッククラウドのエージェント系サービスや Mastra、Agno のように、今年話題になっているエージェントの基本的な構造を備えていたことや、API 提供される代表的なチャットモデルの初期化が簡略化されていたことなど、これまで見落としていた点が多々ありました。
そこで、この LangGraph Supervisor の基本的な動作を確認しつつ、現状の LangGraph の使い勝手を見てみたいと思います。
今回は、Supervisor を含む複数の AI エージェントをそれぞれ独立した Docker コンテナとして起動し、RemoteGraph を用いて連携させる構成を試します。
また、LangChain 陣営は基本的に LangGraph Cloud の利用を推奨しているようです。
そのため、LangGraph CLI を活用して LangGraph Platform 上での動作を前提としつつ、LangGraph Cloud へデプロイする代わりに、ローカルの Docker 環境でどの程度動作させられるのかも確認します。
LangServe はどうやら今後のサポート停止ですし。
プロジェクトのセットアップ
まず、LangGraph CLI を使用して、LangGraph プロジェクトの雛形を作成します。
今回は最小構成のプロジェクトから開始。
langgraph new
上記コマンドを実行すると、対話形式で設定項目を尋ねられるので、適宜設定します。
指定したディレクトリに必要なファイル群が生成されます。
ディレクトリ構成は以下のようにしました。
各エージェントを独立させられるかを確認することが主な目的であるため、それぞれが異なる LangGraph プロジェクトとして構成されていれば問題ありません。
.
├── researcher
│ ├── docker-compose.yaml
│ ├── langgraph.json
│ ├── pyproject.toml
│ └── src
│ └── agent
│ ├── __init__.py
│ └── graph.py
├── scheduler
│ ├── docker-compose.yaml
│ ├── langgraph.json
│ ├── pyproject.toml
│ └── src
│ └── agent
│ ├── __init__.py
│ └── graph.py
└── supervisor
├── docker-compose.yaml
├── langgraph.json
├── pyproject.toml
└── src
└── agent
├── __init__.py
└── graph.py
システム構成
今回試すシステムは、以下の3つのエージェントで構成される階層型エージェントアーキテクチャです。
- Supervisor エージェント (supervisor): 各エージェントの呼び出しや処理の振り分けを行う中心的な役割を担う。
- Web 検索エージェント (researcher_agent): Web 上の情報を検索する。
- スケジュール設定エージェント (scheduler_agent): Google カレンダーへのスケジュール登録する。
これらのエージェントは、それぞれ個別の Docker コンテナとして動作させます。
結果としては以下のようになりました。
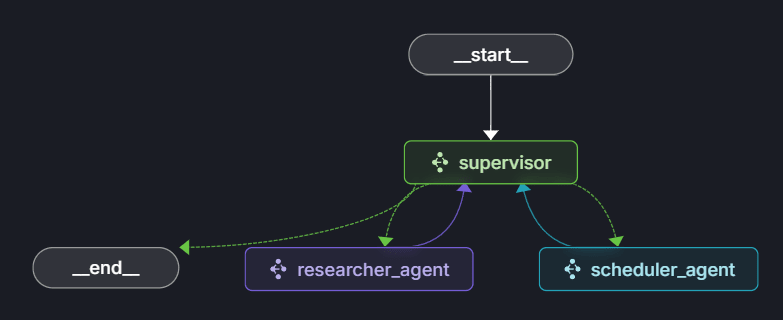
なんかAgentになってから複雑さがModelに押し付けられてフローがシンプルになってきたよね
エージェント間の連携は、LangGraph の RemoteGraph 機能を利用して実現します。
これは LangChain における RemoteRunnable に相当しますね。
これにより、各エージェントの独立性を保ちつつ協調動作させることが、フレームワークレベルでサポートされていると言えるでしょう。
Supervisorエージェントの実装
Supervisor エージェントは、冒頭で紹介した langgraph-supervisor の README をほぼそのまま採用しました。
他のエージェント(Web 検索エージェント、スケジュール設定エージェント)は RemoteGraph として定義し、それらを統括するエージェントとして指定します。
LangChain/Graph はやや複雑な印象がありますが、ヘルパー関数的なものがかなり充実していて、簡易的に組むだけであれば内部実装がうまく隠蔽され、優れた抽象化が提供されていると感じます。
また、簡単なツールとして現在時刻を取得する関数も用意します。
これを渡しておかないと、「今」や「明日」といった表現をエージェントが解釈できず、実用的ではありません。
システムプロンプトやユーザーメッセージに毎回固定でタイムスタンプを埋め込む方法もありますが、今回はエージェントくんに自ら時間を見てもらうことにします。
supervisor/src/agent/graph.py
import datetime
import os
from langchain.chat_models import init_chat_model
from langgraph.pregel.remote import RemoteGraph
from langgraph_supervisor import create_supervisor
async def get_current_time() -> dict[str, str]:
"""現在時刻(ISO 8601形式の文字列)を返すTool.
Returns:
dict[str, str]:
- "current_time": 現在時刻(例: "2025-05-19T12:34:56.789123")
"""
now = datetime.datetime.now().isoformat()
return {"current_time": now}
model = init_chat_model(
os.getenv("MODEL_NAME"),
model_provider="openai",
base_url=os.getenv("OPENAI_BASE_URL"),
)
researcher_agent = RemoteGraph(
"agent", name="researcher_agent", url="http://host.docker.internal:8124"
)
scheduler_agent = RemoteGraph(
"agent", name="scheduler_agent", url="http://host.docker.internal:8125"
)
# Create supervisor workflow
workflow = create_supervisor(
agents=[researcher_agent, scheduler_agent],
model=model,
tools=[get_current_time],
prompt=(
"You are a team supervisor managing a research expert and a scheduling expert. "
"For current events, use research_agent. "
"For scheduling tasks, use scheduler_agent."
),
)
# Compile
graph = workflow.compile()
前述の通り、他のエージェントは RemoteGraph を使用してリモート接続します。
なお、おそらく LangGraph API が生えているエンドポイントに対して接続できるはずです。
今回はまず動作させることが目的だったため、ポート番号のみを変更して各コンテナを起動しました。
そのため、URL には host.docker.internal を使用し、Docker ホスト側で実行されている他のエージェントコンテナを指定しています。
ポート番号は後述する docker-compose.yaml で適宜設定します。
researcher_agent = RemoteGraph(
"agent", name="researcher_agent", url="http://host.docker.internal:8124"
)
scheduler_agent = RemoteGraph(
"agent", name="scheduler_agent", url="http://host.docker.internal:8125"
)
ところで LLM のモデルを読み込む以下の部分。
model = init_chat_model(
os.getenv("MODEL_NAME"),
model_provider="openai",
base_url=os.getenv("OPENAI_BASE_URL"),
)
最初に見たときは「ChatOpenAI や ChatBedrock ではないのか?」と思いましたが、どうやら litellm のように openai/gpt-4o といった指定から自動でモデルクラスを選択してくれるヘルパーのようです。
なお、私は litellm で手元の LLM 利用環境を統合し、OpenAI 互換 API で統一的に利用できるようにしているため、上記のように初期化しました。
Web検索エージェントの実装
Web 検索エージェントは、LangChain に統合されている TavilySearch を利用して実装します。
create_react_agent を使用して、ReAct フレームワークに基づいたエージェントを構築します。
researcher/src/agent/graph.py
import datetime
import os
from typing import Any, Optional, cast
from langchain.chat_models import init_chat_model
from langchain_tavily import TavilySearch
from langgraph.prebuilt import create_react_agent
async def search(query: str) -> Optional[dict[str, Any]]:
"""Search for general web results.
This function performs a search using the Tavily search engine, which is designed
to provide comprehensive, accurate, and trusted results. It's particularly useful
for answering questions about current events.
"""
wrapped = TavilySearch(max_results=10)
return cast(dict[str, Any], await wrapped.ainvoke({"query": query}))
async def get_current_time() -> dict[str, str]:
"""現在時刻(ISO 8601形式の文字列)を返すTool.
Returns:
dict[str, str]:
- "current_time": 現在時刻(例: "2025-05-19T12:34:56.789123")
"""
now = datetime.datetime.now().isoformat()
return {"current_time": now}
model = init_chat_model(
os.getenv("MODEL_NAME"),
model_provider="openai",
base_url=os.getenv("OPENAI_BASE_URL"),
)
prompt = """
You are a world class researcher with access to web search.
You are given a question and you need to answer it.
You can use the web search tool to find information.
"""
research_agent = create_react_agent(
model=model,
tools=[search, get_current_time],
name="research_expert",
prompt=prompt,
)
今回の検証では、エージェントが外部ツールを利用して情報収集することという基本的な動作を確認できれば十分であり、検索結果の品質については深く追求しないため、これで問題ありません。
Supervisor エージェントで述べたように、ここでも時刻取得ツールを渡しておきます。
スケジュール設定エージェントの実装
スケジュール設定エージェントは、Google カレンダーとの連携を実現するために、オープンソースの fastmcp-gsuite を利用しました。
Google アカウントに接続する MCP はいくつか候補がありましたが、安定動作し、かつコンテナ化しやすかったこちらを選択しました。
FastMCP は最近 Streamable HTTP に対応したため、transport は stdio ではなくそちらを利用するように改変しました。
これを Docker コンテナとして起動し、langchain-mcp-adapters 経由で接続することで、スケジュール登録機能を実現します。
なお、MCP を利用したのは単なる興味で記事の主題ではないため、このような OSS をベースにコンテナを準備し LangGraph エージェントから利用した、という程度の紹介に留めます。
scheduler/src/agent/graph.py
import datetime
import os
from langchain.chat_models import init_chat_model
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.graph.graph import CompiledGraph
from langgraph.prebuilt import create_react_agent
async def get_current_time() -> dict[str, str]:
"""現在時刻(ISO 8601形式の文字列)を返すTool.
Returns:
dict[str, str]:
- "current_time": 現在時刻(例: "2025-05-19T12:34:56.789123")
"""
now = datetime.datetime.now().isoformat()
return {"current_time": now}
async def make_graph() -> CompiledGraph:
"""Create and compile a StateGraph for the agent's reasoning and tool use.
Returns:
The compiled StateGraph object representing the agent's workflow.
"""
# Define the two nodes we will cycle between
client = MultiServerMCPClient(
{
"google-gsuite": {
"url": "http://host.docker.internal:8000/mcp", # fastmcp-gsuiteコンテナのURL
"transport": "streamable_http",
},
}
)
tools = await client.get_tools()
tools = tools + [get_current_time] # get_current_timeツールも追加
model = init_chat_model(
os.getenv("MODEL_NAME"),
model_provider="openai",
base_url=os.getenv("OPENAI_BASE_URL"),
)
prompt = """
You are a personal scheduler agent.
You are given a task and you need to schedule it.
You must use time zone of JST (UTC+9).
"""
scheduler_agent = create_react_agent(
model=model,
tools=tools,
name="scheduler_agent",
prompt=prompt,
)
return scheduler_agent
MCP 接続もこれだけで Tool として読み取れるため簡単ですね。
# Define the two nodes we will cycle between
client = MultiServerMCPClient(
{
"google-gsuite": {
"url": "http://host.docker.internal:8000/mcp", # fastmcp-gsuiteコンテナのURL
"transport": "streamable_http",
},
}
)
tools = await client.get_tools()
tools = tools + [get_current_time] # get_current_timeツールも追加
ただ、闇雲に連携する MCP を増やすと際限なくツールが増えてしまいます。実用性やエージェントの商用利用においては、連携上限を設けたりリクエスト時のツール binding を選択的にするなど、細かな調整が必要になると思われます。
一方で、最近のモデルは高性能なため、とりあえず全てのツールを提供しても問題なく機能するのではないかという気もしますが、実際はどうなんでしょうかね。
LangGraph CLI と Standalone Container による実行
各エージェントは、LangGraph CLI を利用して LangGraph Platform 上で動作するコンテナとしてビルドできます。
具体的には、LangGraph が提供する Standalone Container をデプロイ形式として選択し、ローカルの Docker 環境で各エージェントを起動する形になります。
以下の手順で起動すると、上でも少し触れた LangGraph API によってエージェントがサービングされます。
まず、各エージェントのディレクトリ(supervisor, researcher, scheduler)で、それぞれ以下のコマンドを実行して Docker イメージをビルドします。
イメージ名は任意です。
# supervisorディレクトリに移動して
langgraph build -t supervisor-agent
# researcherディレクトリに移動して
langgraph build -t researcher-agent
# schedulerディレクトリに移動して
langgraph build -t scheduler-agent
次に、これらのコンテナと LangGraph が必要とする Redis および PostgreSQL をまとめて起動するために、docker-compose.yaml を作成します。
参考までに supervisor のものを掲載しますが、他のエージェントについては langgraph-api で使用するコンテナ名と全体的なポート番号を空いているものに変更すれば、同様に設定できました。
docker-compose.yaml
volumes:
langgraph-data:
driver: local
services:
langgraph-redis:
image: redis:6
healthcheck:
test: redis-cli ping
interval: 5s
timeout: 1s
retries: 5
langgraph-postgres:
image: postgres:16
ports:
- "5436:5432"
environment:
POSTGRES_DB: postgres
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
volumes:
- langgraph-data:/var/lib/postgresql/data
healthcheck:
test: pg_isready -U postgres
start_period: 10s
timeout: 1s
retries: 5
interval: 5s
langgraph-api:
image: langgraph-supervisor
ports:
- "8126:8000"
depends_on:
langgraph-redis:
condition: service_healthy
langgraph-postgres:
condition: service_healthy
env_file:
- .env
environment:
REDIS_URI: redis://langgraph-redis:6379
LANGSMITH_API_KEY: ${LANGSMITH_API_KEY}
POSTGRES_URI: postgres://postgres:postgres@langgraph-postgres:5432/postgres?sslmode=disable
.env ファイルには、今回の実装では MODEL_NAME、OPENAI_BASE_URL、そして LANGSMITH_API_KEY を定義しておきます。
残念ながら、この仕組み(LangGraph Platform、LangGraph API によるサービング)を利用するには Standalone Container であったとしてもライセンスが必要なようで、検証目的であっても最低限 LangSmith への認証が必須となるようでした。
そのため、動作確認には LangSmith の API キーが必要です。
ただし、これはあくまで起動時の認証と LangSmith が紐づいているがための仕様であり、LANGSMITH_TRACING=false を設定しておけばトレーシング自体は無効化できるように見えています。
Self-Hosted Lite¶
The Self-Hosted Lite version is a limited version of LangGraph Platform that you can run locally or in a self-hosted manner (up to 1 million nodes executed).When using the Self-Hosted Lite version, you authenticate with a LangSmith API key.
よって、今回はローカルでの動作確認が目的であり、LangGraph Cloud への本格的なデプロイは行いませんが、起動用に LangSmith の API キーを設定しておきます。
docker-compose up コマンドで、定義した全てのサービスを起動します。
動作確認
構築したシステムの動作確認は、以下のフロントエンド UI を利用して対話形式で行いました。
(リポジトリ: https://github.com/langchain-ai/agent-chat-ui)
この UI の接続先を、ローカルで起動した Supervisor エージェントの URL に設定します。
UI を通じて Supervisor エージェントに指示を出し、各エージェントの動作や連携の様子を確認します。

万博で祝うほどの世界ミツバチの日
確かに、検索してカレンダーに登録するところまで、Supervisor くんが仲介してくれました。
エージェントが言うように、正しく登録されているかカレンダーも確認してみます。
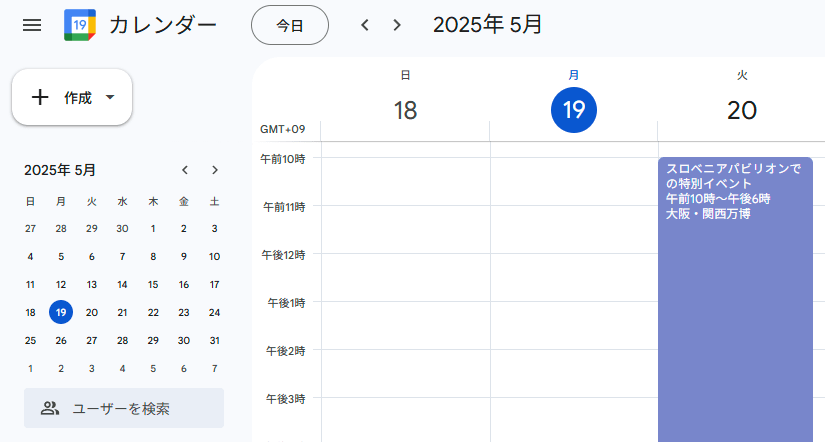
しっかり登録された世界ミツバチの日
なるほど、正しく登録されていますね。
チャット全体は折りたたんで以下に掲載します。
チャット全体
localhostにあるエージェントを会話の対象に指定


感想
Supervisor、Web 検索、スケジュール設定という3つの異なる機能を持つエージェントをそれぞれ独立した Docker コンテナとして起動し、RemoteGraph を介して連携させることが確認できました。
また、Supervisor 型エージェント自体は関数を1つ呼び出すだけで作成できるため、動作検証だけであれば簡単に構築できますね。
RemoteGraph によるエージェント呼び出し部分は、まさに Google が提唱する A2A のコンセプトが具体的に活かされる箇所でしょう。
LangGraph は独自のプロトコルを採用していますが、各エージェントが標準化されたインタフェースを通じて通信することで、よりモジュール化された柔軟なエージェントシステムの構築が進むのではないかと期待されます。
MCP や A2A は、現時点では世間の注目度ほどエンタープライズ要件で利用するには成熟しきっていない印象ですので、注視していきたいところです。
一方で、A2A や MCP には留意すべき点もあると考えています。
MCP や A2A といった仕組みは、あくまでエージェント間の「通信プロトコル」や「連携方法」を定義するものであって、これらの技術を採用したからといって LLM そのものの能力が向上したり、これまでできなかったタスクが解決されたりするわけではありません。
本質的には、個々のエージェントが持つ能力(利用するツールやモデルの性能)に依存するという点は、冷静に認識しておく必要があるでしょうね。
巷じゃなんだか「MCP でできることが増える!」みたいな言い方されてるように感じますが、だって、実態はただの tool call じゃん? みたいなね。
もちろん、そのフォーマットを統一しようという試みはすごいことですし、統一されることで機能追加が容易になり、間接的にできることは増えると思いますが。
おわりに
LangGraph Supervisor と RemoteGraph を用いることで、マルチエージェントシステム、特に階層型アーキテクチャの構築が容易に実現できることが分かりました。
商用ケースにおいては別途考える部分もあると思いますが個人のツールや社内の業務改善程度であれば十分に使えると感じます。

Discussion