埋め込みデータの扱いと復元リスクへの対策
埋め込みは「安全」なのか?
これまで多くのシステムでは、「テキストを埋め込みベクトルに変換すれば、 元の内容は失われる=匿名化される」と考えられてきました。
しかし、これは 本当に安全と言えるのでしょうか。
2023年に発表された研究 “Text Embeddings Reveal (Almost) As Much As Text”(Vec2Text論文)では、 テキスト埋め込みから 元の文を高精度に再構成できる ことが示されました。著者らは Vec2Text という手法を提案し、32トークンの入力のうち最大で 約92%を完全一致で復元 する実験結果を報告しています。
つまり、埋め込みはもはや「不可逆的変換」ではなく、“圧縮された個人データ”に近い存在 として扱う必要があると考えられます。
⚠️ ベクトルから文が「戻る」
Vec2Textのような逆変換モデルは、埋め込みベクトルをトークン列(テキスト)へと再構成する “inversion model” を用いておりこの仕組みを使うと、例えば企業内の検索エンジンに保存された埋め込みから、元メールやチャットの内容をほぼ再生できる可能性があります。
特に、次のようなケースではリスクが顕著になります
- 個人名・住所・取引内容などが含まれる文をそのままベクトル化した場合
- 外部のクラウド環境でベクトルを保存・共有している場合
- 第三者モデルによる再学習や再利用を想定していない場合
これらは「生テキストの漏洩」と本質的に同義と扱う必要があります。
対策:埋め込みを“個人データ”として扱う
したがって、埋め込みも 生テキストと同等のセキュリティポリシー を適用すべきです。
運用上の推奨措置
- 保管時の暗号化:AES-256等の方式で静的データを暗号化する。
- 転送経路のTLS化:すべての通信経路でTLSを強制する。
- 保存期間の短縮:目的達成後は速やかに削除または再埋め込み。
- 用途限定の明示化:検索・類似度計算以外の二次利用を制限。
これにより、「ベクトルだから安全」という誤解を防ぎ、 再構成リスクを制度的にも技術的にも抑止できます。
さらに、埋め込みに 微小ノイズを加える ことで、
復元耐性を高めつつ検索品質を維持することができます。
推奨パラメータ
- ノイズ強度: λ ≈ 10⁻³ ~ 10⁻²
(例:e' = e + N(0, λ²)) - 検証指標:
- NDCG(検索精度)
- Reconstruction Robustness(復元耐性)
💡 ノイズ注入は「検索性能」と「プライバシー強度」のバランス設計を考える必要あり。
本番運用前に評価を行い、最適λを決定することが望ましいかも
Vec2Textの内部構造と逆変換プロセス
Vec2Textがなぜ高精度で復元できるのかを理解するには、
その内部モデル構成と逆変換メカニズムを知る必要があります。
モデル概要
| モデル名 | 入力 | 出力 | 役割/機能 |
|---|---|---|---|
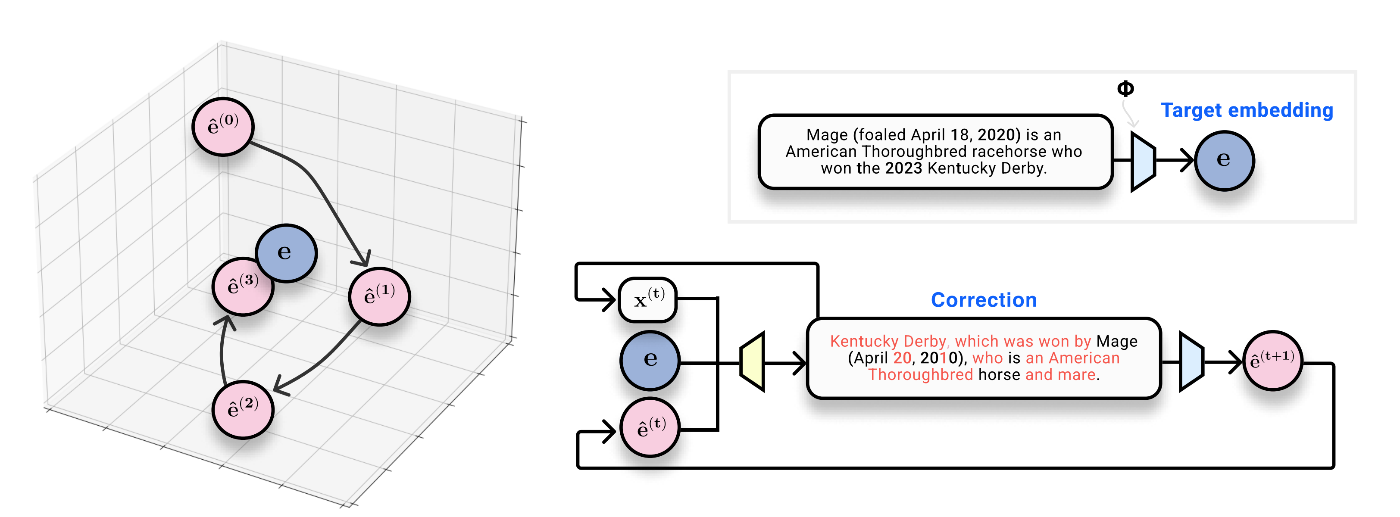
| InversionModel | 埋め込みベクトル ( e ) | 初期テキスト仮説 | 埋め込み → テキストへの一次逆変換を担うモデル。埋込ベクトルから直接出発して、ある程度“正しいトピック・語彙”を含む初期のテキストを生成する。 |
| CorrectorModel(反復補正モデル / CorrectorEncoderModel) | 真の埋め込みベクトル ( e )、仮説テキスト、仮説テキストを埋め込んだベクトル、その差分など | 次段階の仮説テキスト | 仮説テキストの誤りを“補正”して、より良いテキストに修正する。反復修正(iterative correction)のステップを担うモデル。 |
InversionModel(一次逆変換)
埋め込みベクトル(ある基準の埋め込み器を通したもの)を入力にして、
元のテキスト (x) を生成するように訓練します。
この段階では「Embedding を入力 → テキストを出力」という標準的な逆変換(inversion)モデルを構築。
基本モデル単体では BLEU ≈ 30 程度 と、完全復元には至らない精度です。
Transformerへの入力構造の工夫
実際には、Transformerモデルは以下の構造を前提としています:
- 通常の入力は「トークン列(ID列) → Embedding層 → Hidden States」
- 各トークンに対応する
attention_maskを保持 - つまり、系列長(sequence length)軸 が必須
一方、単一のベクトル (e)(shape = (batch, embedding_dim))をそのままEncoderに流そうとすると、
「どのトークン位置として扱うか」の定義が失われます。
このため、Transformerが期待する構造を保つ工夫が必要になります。
ベクトル展開の仕組み(MLPによる仮想トークン化)
Vec2Textでは、MLP(多層パーセプトロン) によって
ベクトルを複数の仮想トークン位置に展開します。
- 各仮想トークンが自己注意(self-attention)で相互に情報交換できるようにする
-
attention_maskを付与して、すべての仮想トークン位置を有効化する - 結果として、Transformerが「文のような系列構造」として入力を処理できるようになる

ベクトルの動き(例)
設定例
- B = 2
- hidden_dim = 6
- num_repeat_tokens = 3
→ flattened_size = 18 = 6 × 3
これにより、単一ベクトルが3トークン相当の系列に展開され、Transformerが扱える形式となります。
CorrectorModel(反復補正モデル)
初期仮説(InversionModelで生成されたテキスト)を “仮説テキスト” とします。
これを再び埋め込みにしたとき、真の埋め込みとの差分を入力として、
「どう修正すれば再埋め込み後のベクトルが真の埋め込みに近づくか」を学習します。
この補正を行うTransformerベースのモジュールが、
iterative correction(反復修正) の中心となります。
結果として、
仮説 → 埋め込み → 差分 → 修正 → 新仮説 → … というループを回しながら精度を高めていく仕組みです。
一部では ビーム探索 によって候補文の多様性を担保する実装も見られます。
Vec2Textの実装・利用
パッケージ情報
- リポジトリ:vec2text/vec2text (GitHub)
-
PyPI配布:
pip install vec2textで導入可能 -
使用Embeddingモデル:
text-embedding-ada-002(OpenAI API)
Vec2TextはすでにPyPI上で公開されており、環境構築が容易。
GitHub版には学習・補正両フェーズを含む完全実装が提供されている
-
Embeddingモデル依存
- 反復補正フェーズでは「文章→ベクトル変換」に再度embeddingモデルを利用する。
- そのため、OpenAI APIキーの設定が必須。
- 元実装では
openai.api_keyを格納する必要あり。
-
日本語対応について
- 現状、Vec2Textは 英語コーパスでのみ学習。
-
text-embedding-ada-002も英語中心設計のため、
日本語テキストでは意味復元率が低下する傾向がある。 - 日本語向け利用を行う場合は、
日本語embeddingモデル(例:cl-tohoku/bert-base-japanese)で再学習が望ましい
実装調査メモ(InversionModel)
-
READMEに明確な記載がなかったため、コード解析で構造を把握。
-
Hugging Face上では
InversionModel単体を呼び出す事例があり、
本来は 個別利用(単体推論) の方が適切と思われる。 -
実装的には
corrector.inversion_trainer.callback_handler.model内に
InversionModelが存在しており、
vec2text全体を通すよりも分離利用のほうが制御しやすい場合がある。💻 Vec2Textの実装例(InversionModel)
Vec2Textは、PyPI版をインストールすれば 数行のPythonコードで逆変換(embedding→text)を実行 できます。
下記は基本的な呼び出し例です。
import vec2text
# 使用するembeddingモデル
EMBED_MODEL = "text-embedding-ada-002" # vec2textのプリトレ逆変換器がある前提
# 学習済みCorrector(補正器)をロード
corrector = vec2text.load_pretrained_corrector(EMBED_MODEL)
# 内部のInversionModelを取得
inverter = corrector.inversion_trainer.callback_handler.model # -> InversionModel
# 生成パラメータ設定
gen_kwargs = {
"max_new_tokens": 96, # 出力文を伸ばす
"min_new_tokens": 32, # 早期終了を防ぐ(版によっては "min_length")
"do_sample": True, # サンプリングON
"top_p": 0.9, # nucleus sampling
"temperature": 0.8, # 低めで暴走抑制
"repetition_penalty": 1.2, # 同語反復を防止(重要)
"no_repeat_ngram_size": 3, # n-gramの繰り返し禁止(T5等に有効)
"length_penalty": 1.0, # 出力長バランス。0.8〜1.0程度で調整
# "num_beams": 4, # 対応していれば有効化(ビーム探索)
}
# 埋め込み(emb)からテキストを生成
out_ids = inverter.generate(
inputs={"frozen_embeddings": emb},
generation_kwargs=gen_kwargs
)
# トークン列をテキストにデコード
texts = tokenizer.batch_decode(out_ids, skip_special_tokens=True)
print(texts[0])
埋め込みベクトルからの文章復元率の分析
元の文章と復元された文章を比較してみましょう。その精度の高さがよくわかります。
元の文章 (Original Text):
"A home robot that automatically manages medication for the elderly. It confirms via voice and prevents incorrect medication."日本語訳:
「高齢者の服薬を自動で管理する家庭用ロボット。音声で確認し、誤った服薬を防ぎます。」
復元された文章 (Reconstructed Text):
"A robotic that confirms and automates home care. It robologs for elderly and medical patients via voice. It prevents incorrect medication. The home ensures correct dosage."日本語訳:
「在宅ケアを確認し自動化するロボット。高齢者や医療患者のために音声で記録します。誤った服薬を防ぎ、家庭で正しい服用量を保証します。」
-
誰のためのものか:
elderly(高齢者)という最も重要なキーワードが完全に復元されています。 -
何をするか:
prevents incorrect medication(誤った服薬を防ぐ)という中核機能がそのまま再現されています。 -
どうやってやるか:
via voice(音声で)という手段も一致しています。 -
automatically manages medication(自動で服薬管理する)という表現が、automates home care(在宅ケアを自動化)やensures correct dosage(正しい服用量を保証)という、非常に近い意味の言葉で再構成されています。 -
単語が一致しているだけでなく、「高齢者向けの」「音声で確認する」「服薬支援ロボット」という全体の文脈やアイデアが、ほぼ完璧に保たれています🎉
埋め込み情報の追加実験:個人情報は復元できるのか?
「テキスト→ベクトル→テキスト」という変換を何度も繰り返すと、情報はどのように変化するのかみていきましょう!
現代で最も有名な人物の一人であるイーロン・マスクの架空の個人情報を使って、5サイクルの変換実験を行いました。情報が綺麗に消えるのか、それとも予期せぬ変化が起きるのでしょうか。
実験のセットアップ
以下の、著名な人物名と現実の地名を含むデータを初期値として設定しました。
初期データ (Cycle 0):
"Elon Musk, residing at 1 Tesla Road, Austin, TX 78725, has an order for a smartwatch (Customer ID X-AE-A-12) scheduled for delivery."日本語訳:
「イーロン・マスク(住所:テキサス州オースティン、テスラロード1番地)は、スマートウォッチ(顧客ID X-AE-A-12)の注文を配送予定です。」
サイクルごとの情報の変化
サイクル 1:名前は消え、属性が残る
出力:
"Austin, Texas-based X-Men CEO Xander Taylor has ordered a watch, which is scheduled for delivery at 1 XYZ Drive, #AXXX2 in XyZ."
わずか1回の変換で、「Elon Musk」という固有名詞は完全に消失しました。しかし、面白いことに職業属性(CEO)は引き継がれ、「Xander Taylor」という新しい人物が創造されています。
住所の詳細は失われましたが、地名「Austin, Texas」は正確に維持されました。また、顧客IDの「X」という文字がトリガーとなり、「X-Men」「Xander」「XYZ」といった単語を誘発している様子が見られます。
サイクル 2〜5:別の物語への「変容」
サイクル 3 出力:
"Austin, Texas-based Watchmatex Productions, the parent company of the TXT movie, ordered X2 by Wingman Productions and we will hear from Austin."
サイクル 5 出力:
"XT Productions, the Austin-based production company, according to Media Matters, is produced by WXT 2 and will be producing XMT 2 by Matthew Randall."
サイクルが進むにつれて、「オースティンを拠点とする制作会社(Production company)の映画発注ニュース」へと変貌しました。AIは自らが生み出した「Watch」や「X」といった断片から連想を広げ、別の物語を構築してしまったようです。
元の「イーロン・マスクの個人的な注文」は跡形もなく消えましたが、最後まで「オースティン(Austin)」という地名だけは残り続けました。
まとめ
-
「Elon Musk」という非常に有名な名前でさえ1サイクルで消失した一方で、「Austin, Texas」という一般的な地名は5回のサイクルを生き残りました。モデルにとって、広く知られた情報ほどベクトル空間内で安定していることを示唆しています。
-
情報の断片が「幻覚」のトリガーになる
元のIDに含まれていた「X」という一文字がトリガーとなり、「X-Men」から「XT Productions」へと至る連鎖を引き起こしました。微小な情報の断片が、全く異なる文脈を生成する起点となりえました。
今回の汎用的なモデルでは、元の個人情報を復元することは困難でした。しかし、例えば、特定のデータセット(社内文書や顧客情報など)で追加学習(ファインチューニング)されたモデルであれば、この変容のパターンを学習し、劣化したベクトルからでも元の情報を類推・復元する能力を獲得する可能性が考えられます。
したがって、「一般的なモデルでは読めなくなったから大丈夫」と安心するのではなく、埋め込みベクトルは依然として元の情報の痕跡を保持するリスクのあるデータとして、慎重に取り扱うべきであると言えます。

Discussion