はじめに
isuconの過去問をOpenTelemetryを使ってやってみました。
OpenTelemetryを使うと、各リクエストのトレースがわかるので遅い場所を特定するときに便利です。
やってみたのは12回予選で、aws-isuconに公開されているAMI(ami-073140ad092048333)を1台(c5.large)使いました。
使用言語はGoで、OpenTelemetryのバックエンドにはVaxilaを使用しました。
※ この記事では簡単のため試行錯誤部分は載せていません。また、清書のため2度解いていて、画像やコードは2回目のものです。
道具を用意する
インスタンスができて、コードを変更する準備ができたら、まずOpenTelemtryで計装します。
1. goのバージョンを変更
元々の実装ではgoが古くOpenTelemetryのモジュールが対応していないため、1.21のバージョンを使うようにします。
変更箇所はgo.modとDockerfileです
2. TracerProviderをインストールする
モジュールがダウンロードできたら、サーバー開始前にOpenTelemetryを呼び出します
var vaxilaToken = os.Getenv("VAXILA_TOKEN")
var tracer = otel.Tracer("echo-server")
func initTracerProvider(ctx context.Context) (func(context.Context) error, error) {
client := otlptracehttp.NewClient(
otlptracehttp.WithEndpoint("telemetry.vaxila-labs.com"),
otlptracehttp.WithHeaders(map[string]string{
"Accept": "*/*",
"X-Vaxila-Token": vaxilaToken,
}),
otlptracehttp.WithCompression(otlptracehttp.GzipCompression),
)
exporter, err := otlptrace.New(ctx, client)
if err != nil {
return nil, err
}
resources, err := resource.New(
ctx,
resource.WithProcessPID(),
resource.WithHost(),
resource.WithAttributes(
semconv.ServiceName("isucon"),
),
)
if err != nil {
return nil, err
}
tp := trace.NewTracerProvider(
trace.WithBatcher(exporter),
trace.WithResource(resources),
)
otel.SetTracerProvider(tp)
otel.SetTextMapPropagator(propagation.TraceContext{})
return tp.Shutdown, nil
}
// Run は cmd/isuports/main.go から呼ばれるエントリーポイントです
func Run() {
if vaxilaToken != "" {
shutdown, err := initTracerProvider(context.Background(), true)
if err != nil {
panic(err)
}
fmt.Println("start OpenTelemetry")
defer shutdown(context.Background())
} else {
// if true {
if false {
shutdown, err := initTracerProvider(context.Background(), false)
if err != nil {
panic(err)
}
defer shutdown(context.Background())
}
fmt.Println("no OpenTelemetry")
}
e := echo.New()
e.Debug = true
e.Logger.SetLevel(log.DEBUG)
...
3. echoに対応する
用意されているコードはechoを使っているので、echo用の計装(go.opentelemetry.io/contrib/instrumentation/github.com/labstack/echo/otelecho)を使います。
変更は2点です。
1つはミドルウェアを追加すること
func Run() {
...
defer sqlLogger.Close()
e.Use(otelecho.Middleware("")) // <- この行を追加
e.Use(middleware.Logger())
e.Use(middleware.Recover())
e.Use(SetCacheControlPrivate)
...
もう一つはエラーを記録するために、エラーハンドラー部分にOpenTelemetryのSpanにもエラーを記録するようにすることです。
func errorResponseHandler(err error, c echo.Context) {
c.Logger().Errorf("error at %s: %s", c.Path(), err.Error())
var he *echo.HTTPError
if errors.As(err, &he) {
c.JSON(he.Code, FailureResult{
Status: false,
})
return
}
span := otelTrace.SpanFromContext(c.Request().Context()) // <- この行を追加
span.RecordError(err) // <- この行を追加
c.JSON(http.StatusInternalServerError, FailureResult{
Status: false,
})
}
4. sqlxに対応する
実装がsqlxを使用しているのでsqlxに対応します(github.com/uptrace/opentelemetry-go-extra/otelsqlx)
幸いなことに、sqlの実行時にcontextを渡すように元々書かれているので以下の変更だけで済みます。
- mysqlとsqlite3の
sqlx.Open()部分をotelsqlx.Open()に変える - sqlxに渡すcontextをリクエストのcontextを渡すよう書き換える。(
context.Backend()部分をc.Request().Context()に変える)
5. 環境変数を準備する
サーバーはsystemdを経由してdocker-composeを実行するようになっているため、環境変数を設定するために以下のファイルを変更します。
- /etc/systemd/system/isuports.service
[Service]
Environment="VAXILA_TOKEN=xxxxx"
Type=simple
- ~/home/isucon/webapp/docker-compose-go.yml
services:
webapp:
build: ./go
environment:
...
ISUCON_DB_NAME: isuports
VAXILA_TOKEN: "${VAXILA_TOKEN}"
ここまでの変更をしたあとに再起動すると、OpenTelemetryが動いてVaxilaの画面から見れるようになります。
現状確認 (1)
OpenTelemetryの用意ができたら、benchを動かしてサーバーに送信します。
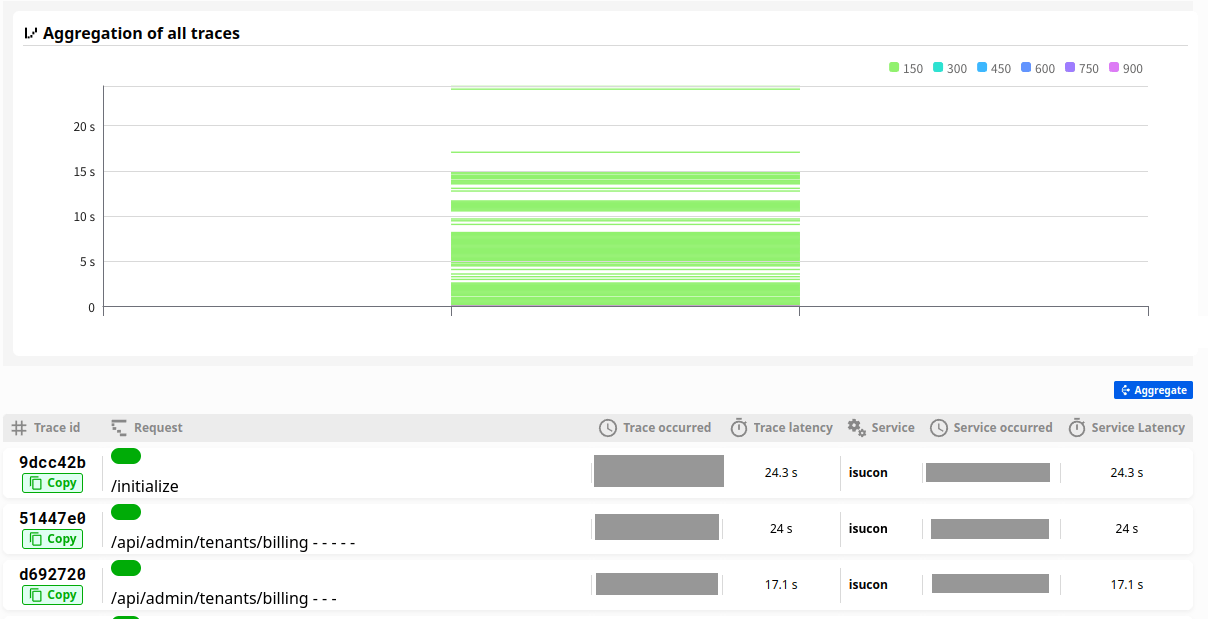
リクエストの実行時間順で見ると24秒をはじめかなり遅いリクエストがあることがわかります。
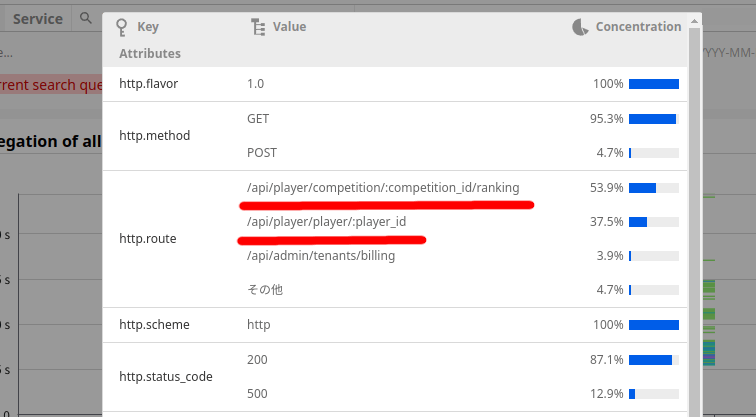
また、5秒以上のリクエストの分布を見ると/rankingと/player/:player_idがほとんどを占めていることがわかるのでこの2つを見てみます。
/rankingについて
/rankingのトレースをみると、ほぼ何もしていないとわかります。
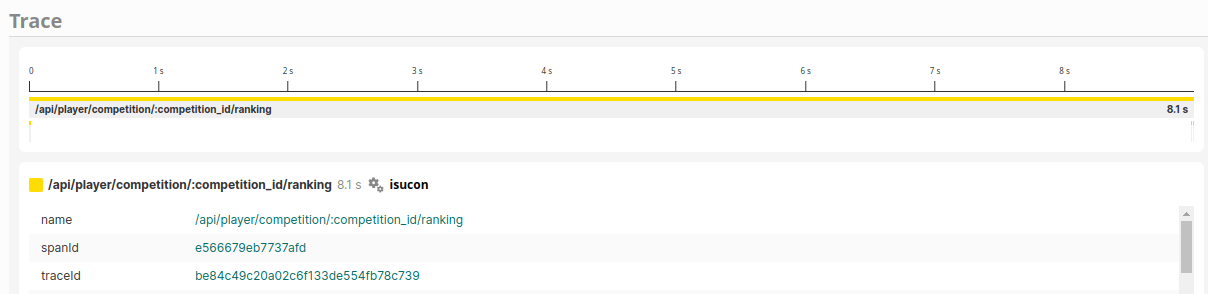
画像のトレースでは最初にINSERT INTO visit_historyのクエリを実行した後8秒近く待った後にSELECT * FROM player_scoreをしています。
これはかなり異常です。
コードを見るとflockByTenantID()という関数内でファイルロックがあることがわかります。
この部分で大量に時間を使っているのではと疑い、ロック待ちの部分とロック解放までの部分をspanに追加します。
具体的には以下の変更をしました。
- ロック取得部分
// 排他ロックする
func flockByTenantID(ctx context.Context, tenantID int64) (io.Closer, error) {
ctx, span := tracer.Start(ctx, "flockByTenantID") // <- この部分を追加
defer span.End() // <- この部分を追加
p := lockFilePath(tenantID)
fl := flock.New(p)
if err := fl.Lock(); err != nil {
return nil, fmt.Errorf("error flock.Lock: path=%s, %w", p, err)
}
return fl, nil
}
- ロックしている部分
// player_scoreを読んでいるときに更新が走ると不整合が起こるのでロックを取得する
fl, err := flockByTenantID(ctx, v.tenantID)
if err != nil {
return fmt.Errorf("error flockByTenantID: %w", err)
}
defer fl.Close()
ctx, flockSpan := tracer.Start(ctx, "flocking") // <- この部分を追加
defer flockSpan.End() // <- この部分を追加
...
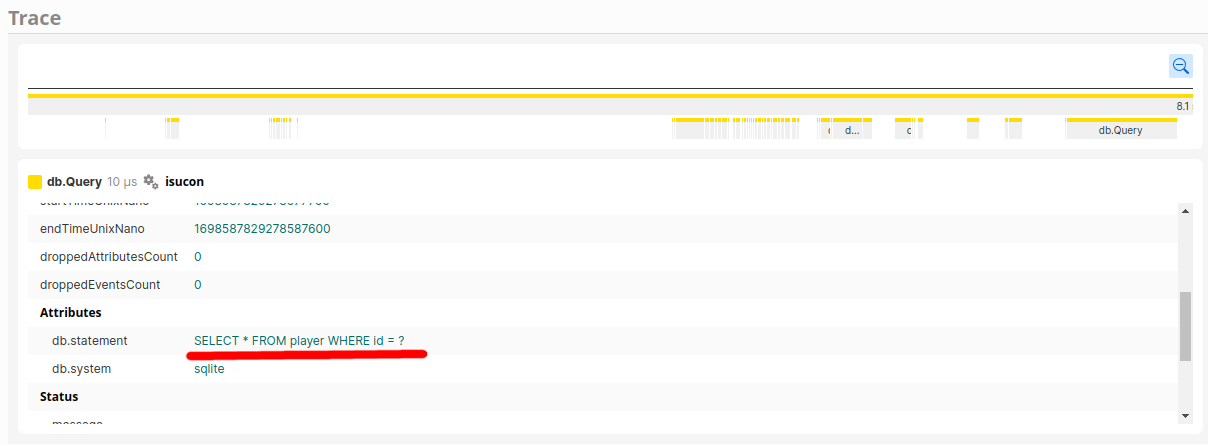
また、ロック以降の処理を拡大すると、明らかにN+1が発生していることもわかります。
ロック取得待ちで遅くなっている場合、ロック中の処理を速くする必要があるので、N+1をついでに潰します。
SELECT * FROM player WHERE id = ?が圧倒的なので、retrievePlayerが大量に呼ばれているとわかります。
/player/:player_idについて
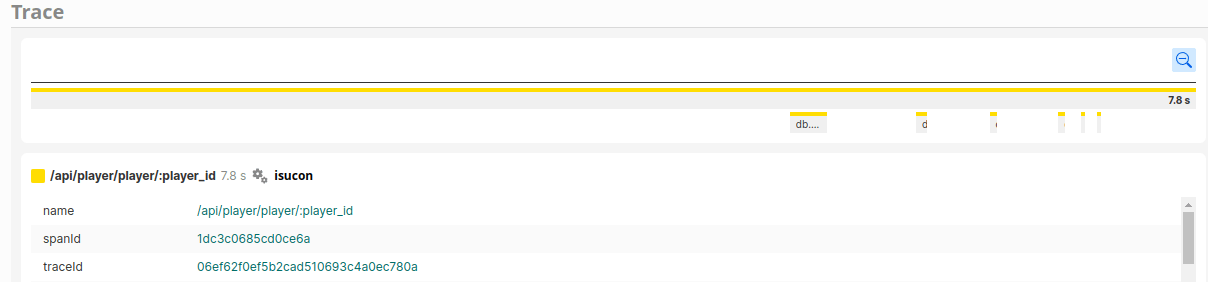
/player/:player_idでも長い空白の後N+1が起きていることがわかります。
が、SELECT * FROM player_score WHERE tenant_id = ? AND competition_id = ? AND player_id = ? ORDER BY row_num DESC LIMIT 1というクエリからN+1をなくすにはサブクエリが必要で大変そうなのでとりあえず後回しにしてbenchを回します。
現状確認 (2)
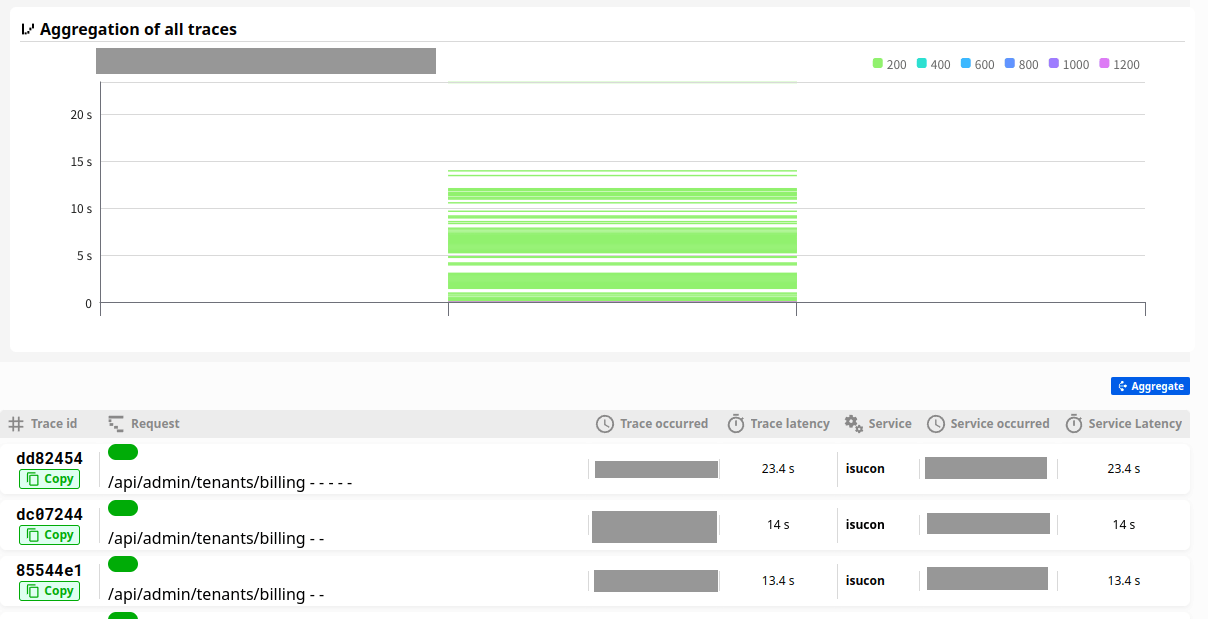
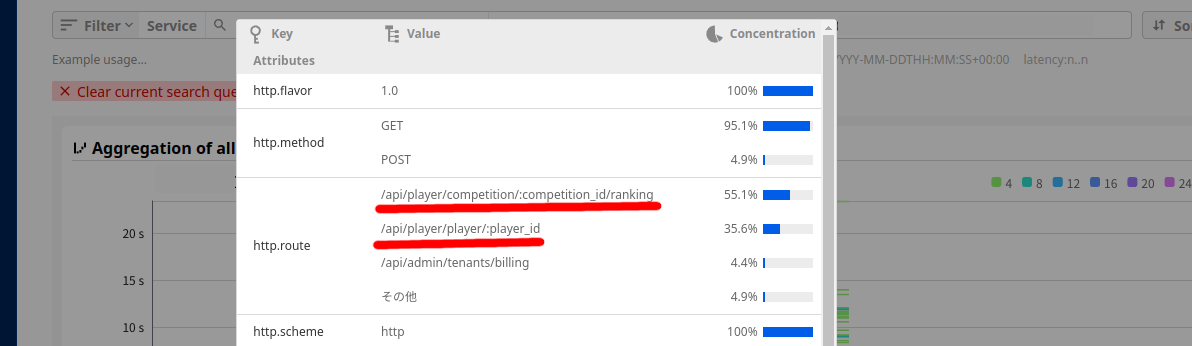
benchを回したところ、スコアが少し上がってrankingが速くなったものの遅いリクエストの傾向は変わりませんでした。
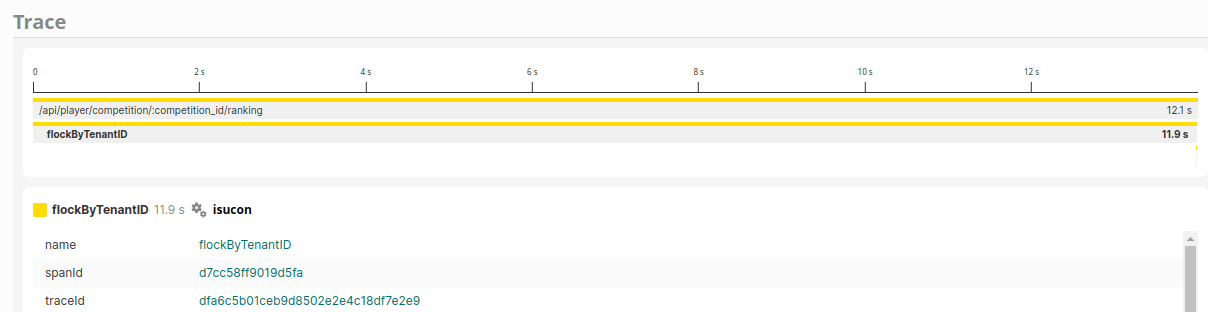
しかし、/rankingのトレースを見るとflockByTenantIDが支配的なことが明確になりました。
なので、flock部分を見てみます。
すると、flock取得部分のコードには「// player_scoreを読んでいるときに更新が走ると不整合が起こるのでロックを取得する」とありますが、
player_scoreを更新しているのは1つのエンドポイント(/api/organizer/competition/:competition_id/score)だけです。
なので、その部分の更新ではトランザクションをかけるようにし、flockを消します
現状確認 (3)
ロックを外したところ、以下のようなエラーが大量に発生しました。
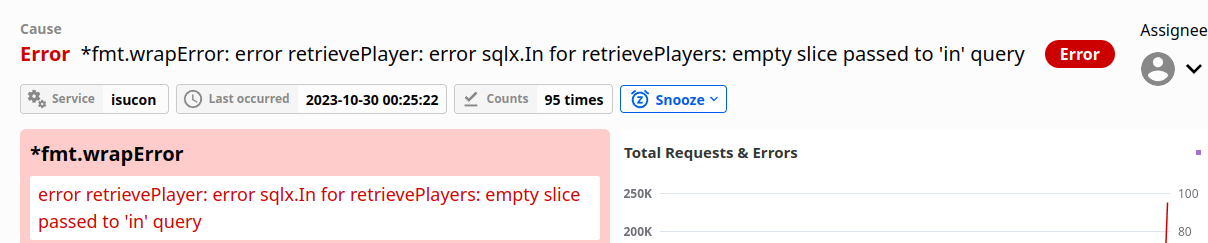
エラーメッセージからわかるように、sqlx.In部分が空になったのが問題でした。
修正してもう一度benchします。
現状確認 (4)
エラーを直したところ、benchが通り、スコアは1000近く上がりました。
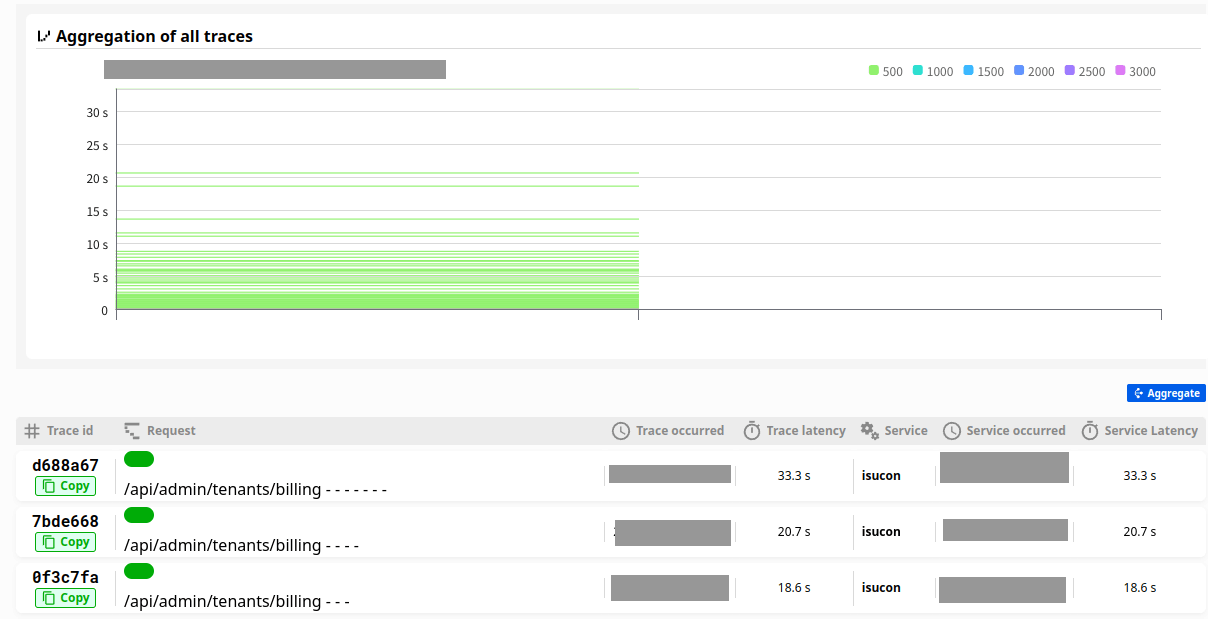
トレースを見てみると、全体のトレースの傾向が大きく変わったことがわかります。
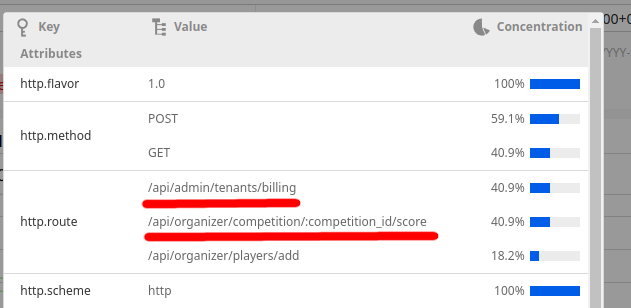
また、5秒以上のリクエストの分布を見ると今まで少なかった/billingと/scoreの割合が大きくなっているのがわかります。
なので、/billingと/scoreをみます。また、更新時のflockが消せたので他の部分からも消せるところは消していきます。
/billingについて
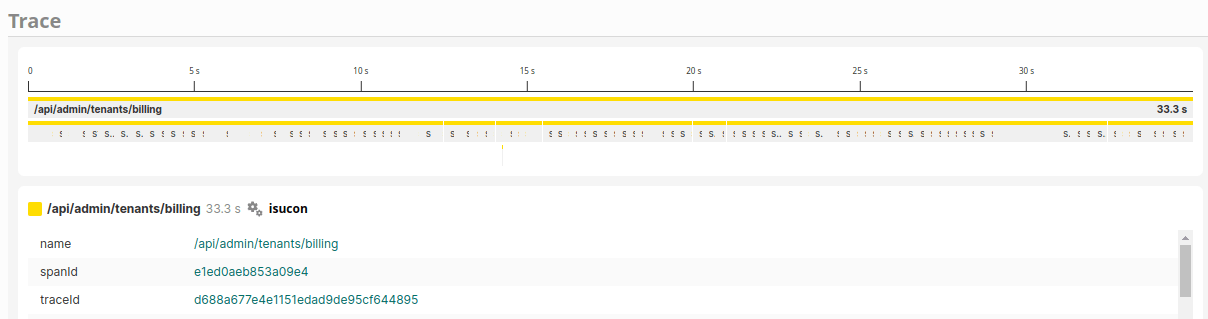
/bilingを見るとN+1が盛大にあることがわかります。
中を見ると、色々やっていて、「大変そうだなぁ」とひよります。
ここで、メタ読みみたくなりますが、/billingのエンドポイントについて、isuconのレギュレーションに「以下のエンドポイントは上記APIの情報の反映まで、レスポンスを返してから3秒の猶予が許容されます」と書かれています。
こういうことが書かれている場合、たいていキャッシュできるので、N+1を解消するのではなくキャッシュできるかを考えます。
その上で/billingの中身を読むとbillingReportByCompetition()という関数の結果が重要で、visit_historyとplayer_scoreのデータを基にデータを作っていることがわかります。
しかも終了前の大会は0固定です。
つまり、この関数の結果は大会終了後にplayer_scoreが更新されたときに変動します。
なので、この関数の結果をキャッシュして、player_score更新時にキャッシュを消すようにします。
また、同時に大会終了前は色々計算しないですぐに0を返すようにします。
/scoreについて
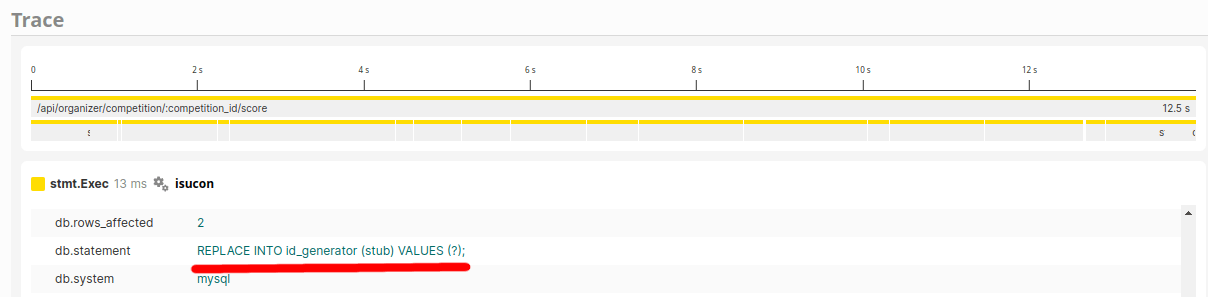
/scoreを見ると、ここにもクエリが盛大にあることがわかります。
あまりにも多すぎて、トレースでは一本の線かと思うほどです。 (画像では分かりづらいですが、拡大すると大量の細い線の集合だということがわかります)
ただ、クエリを見ると、この部分はN+1らしくなくREPLACE INTO id_generator (stub) VALUES (?);というSQLです。
コードを見ると一意なIDを発行するための採番のようです。
「こういうのはUUIDでいいのでは?」と思うものです。戻り値もstringなので、UUID的なもので良さそうです。速度を求めるコードということで、xidで採番することにします。
flockの削除
flock部分を見ると全部SELECTしかしていなかったので、flock部分を全て削除します。
現状確認 (5)
これでbenchを回しましたが、スコアはあまり変わりませんでした。ただ、flockを消す前には良いスコアが出ていたので、もやもやします。
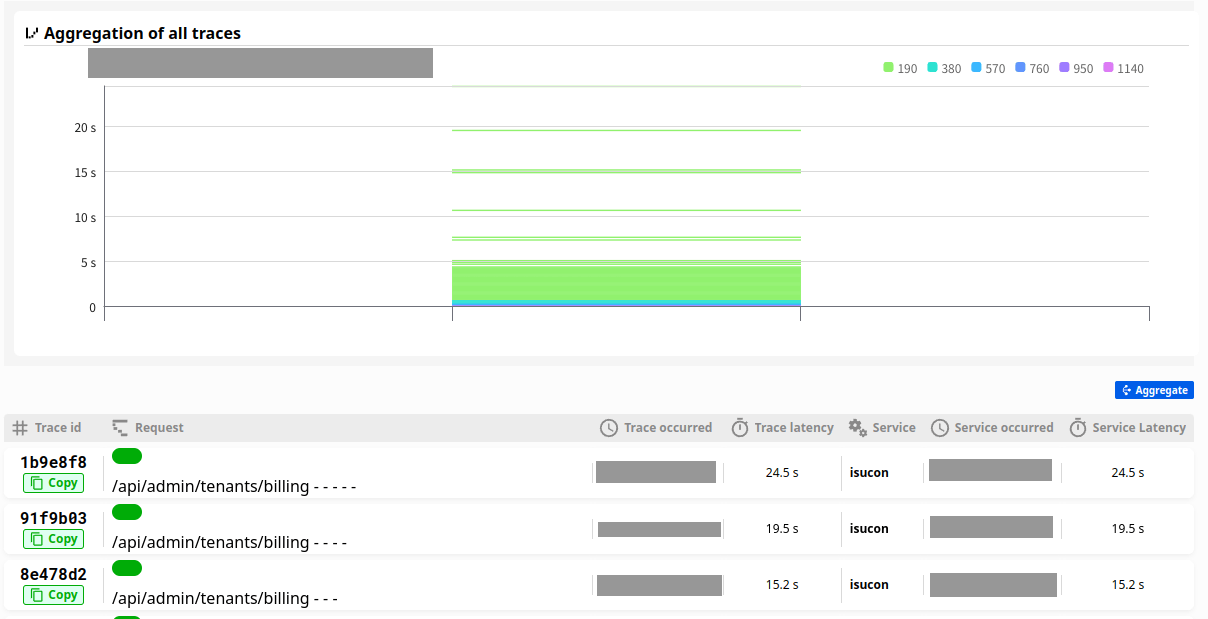
トレースを見る分には明らかに良くなっていて、5秒以上かかっていたリクエストが激減しています。
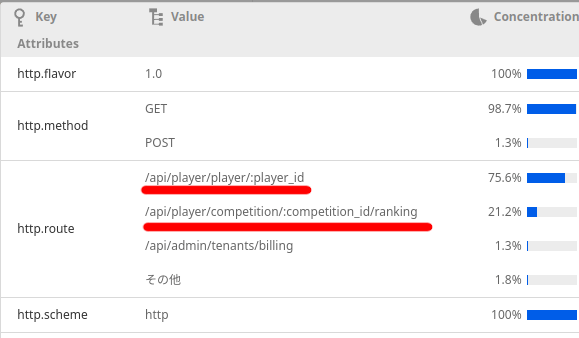
遅いトレースが少なくなったので、確認するURL分布の範囲を「1秒以上のリクエスト」に拡大しました。
すると/player/:player_idが圧倒的なので、これを狙います。ついでに次点の/rankingも見てみます。
/player/:player_idについて
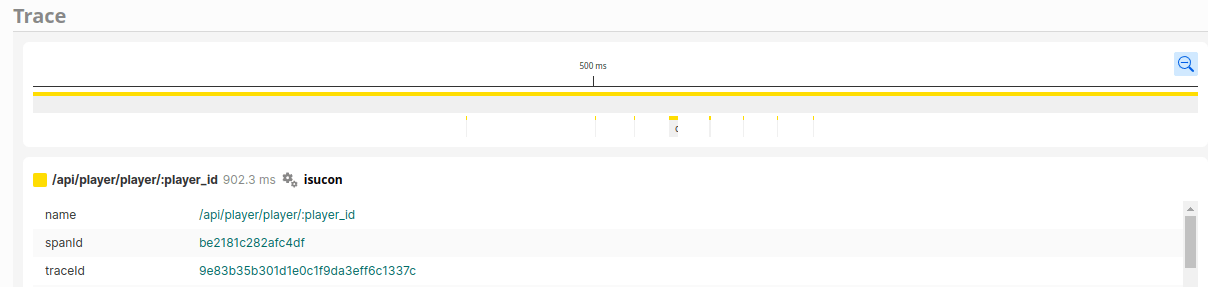
/:player_idにもN+1があるので潰します。
この部分にも「以下のエンドポイントは上記APIの情報の反映まで、レスポンスを返してから3秒の猶予が許容されます」とあり結果をキャッシュをしようかなと思いましたが、「プレイヤーごとに保存して大会が終わった都度プレイヤー分全部消す」というキャッシュは条件が大変そうなので、N+1の削除を選びました。
ついでにインデックスも追加しますcreate index idx on player_score (tenant_id, competition_id, player_id)
/rankingについて
rankingにもキャッシュできそうなポイントがあったのでランキングをキャッシュします。
現状確認 (6)
ここでスコアが大きく上がりました。
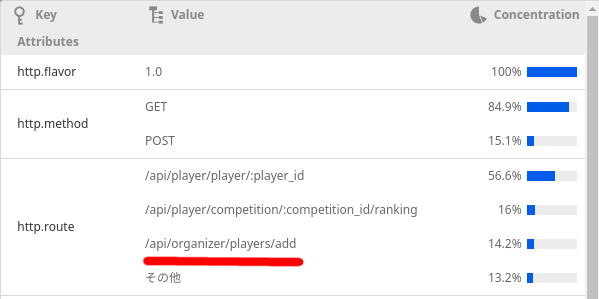
分布を見るとまだ/:playerがおおいですが、/players/addというのも出てきたので見てみます。また、数は少ないものの、/billingが実行時間の最上位に居続けるので見てみます。
/players/addについて
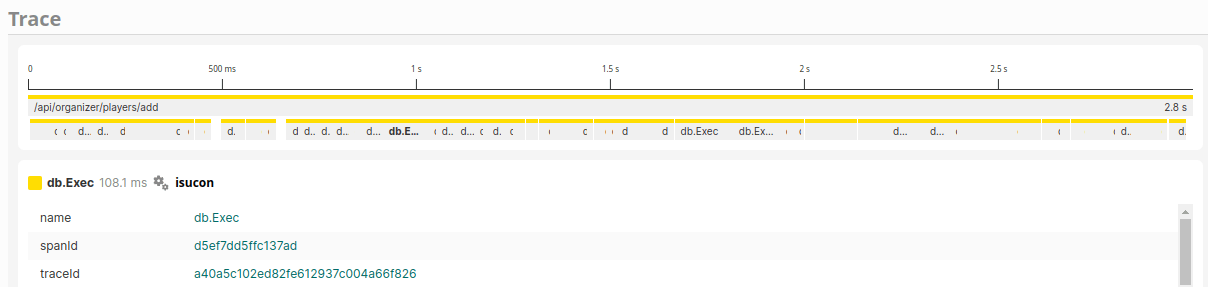
INSERT がものすごい数あるとわかるので潰します。
/billingについて
N+1は起きているものの「キャッシュするようにしたので各1回しか起きないから平気だろう」と思い、それほど気にしていませんでしたが、SELECT player_id, MIN(created_at) AS min_created_at FROM visit_history WHERE tenant_id = ? AND competition_id = ? GROUP BY player_idにインデックスが無いことに気づいたのでインデックスを追加しました
現状確認(7)
このあたりでスコアが2万を安定して超えるようになりました。
この段階で「使っていないからやらなくていいのでは?」と気になっていたinsertを潰して、2万5千をこえるようになり、改善をやめました。
終わりに
ここまでやってみて、Ruby等と違いGoはOpenTelemetryを入れるのに少し手間がかかるのですが、それが入ったら後はなんとかなるなという印象でした。
最後に、ISUCON12 予選問題の解説と講評を読むと、「visit_historyの初期データはほとんど削除できて集計する必要もなくなる」というのが書いてあって「なるほど」と思ったりもしました。
以上、OpenTelemetryを使ってのisuconの過去問に挑戦した記録でした。

Discussion