😊
オンプレKubernetes環境でrook/cephクラスタを作る
構成
kubeadmで構築するいわゆるオンプレミスKubernetes環境
- fedora36 on Hyper-V
- Master1台
- Node3台
- 各Nodeにはデータボリュームとして、/dev/sdb相当の仮想ディスクをアタッチ。
- このデータボリュームは容量固定で作ったほうがたぶんいい
- 容量可変の場合、拡張する処理がハード側で入るためか、cephクラスタが組まれるタイミングの不一致などがあると、特定のノードが置いてきぼりになり、エラーになってしまう。(模様)
こちらの手順で構築
ハマりぽいんと
- ローカルクラスタでやったときは上手くいかなかった
- このような形で、blockpoolがProgressingのまま永遠に止まってしまった
- ただ、そのときは、StorageClassのファイルシステムを変更していなかったので、そこをちゃんと一致させればうまくいくかもしれない
k get cephblockpool -n rook-ceph NAME PHASE
replicapool Progressing
- 試したのは、kind,minikube,micro-k8s
- ちなみに、Ubuntu22.04&kindの組み合わせで検証していたら、OSファイルシステムが巻き沿いをくらってブートしてこなくなったということがあったので、コンテナではなく、仮想マシンを立てるとか完全に別環境のほうがいいと思われる
- たぶんなんですが、マニフェストファイルをデフォルトでそのままデプロイすると、空いているデバイスをデータボリュームとして初期化するような処理あるっぽくそれが原因っぽい
- ローカルクラスタがOS側の特定のボリュームをマウントしている場合、ローカルクラスタ側からは、空いているデバイスとみなされるんじゃないかなと思う
- Cephクラスタ内のリソースがおかしくなったら、とりあえずOperatorリソースを再起動させるとよいかも
- このOperatorリソースのログがかなりヒントになるので、とりあえずこのログを見るとよいかも
手順
手順自体は、QuickStartをそのままやる
rook/cephのデプロイ
リポジトリクローン
git clone --single-branch --branch v1.10.2 https://github.com/rook/rook.git
cd rook/deploy/examples
オペレータのデプロイ
kubectl apply -f crds.yaml -f common.yaml -f operator.yaml
クラスタのデプロイ
spec.storageの設定をいじる
- 特定のデバイス(ストレージ)を使ってほしいので、
useAllDevices: false - 各Nodeにsdbでストレージを追加しているので、
devices.nameでsdbを指定
storage: # cluster level storage configuration and selection
useAllNodes: true
# useAllDevices: true
useAllDevices: false
devices:
- name: "sdb"
#deviceFilter:
config:
kubectl apply -f cluster.yaml
確認
k get pod -n rook-ceph
きれいに起動するとこんな感じに鳴る
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-96zfx 2/2 Running 0 29m
csi-cephfsplugin-jjksr 2/2 Running 0 29m
csi-cephfsplugin-provisioner-5c788447dd-m2lgv 5/5 Running 0 29m
csi-cephfsplugin-provisioner-5c788447dd-sfnsn 5/5 Running 0 29m
csi-cephfsplugin-sd5wj 2/2 Running 0 29m
csi-rbdplugin-fpswq 2/2 Running 0 29m
csi-rbdplugin-mpqq9 2/2 Running 0 29m
csi-rbdplugin-provisioner-75885879dc-r56hg 5/5 Running 0 29m
csi-rbdplugin-provisioner-75885879dc-v8pgv 5/5 Running 0 29m
csi-rbdplugin-z6jrc 2/2 Running 0 29m
rook-ceph-crashcollector-ksk8sn01-6cc6c5c79-bw4vn 1/1 Running 0 27m
rook-ceph-crashcollector-ksk8sn02-df9595fd4-rvxc5 1/1 Running 0 27m
rook-ceph-crashcollector-ksk8sn03-56764797cc-c5m78 1/1 Running 0 28m
rook-ceph-mgr-a-6f796d9976-ksp8x 2/2 Running 0 28m
rook-ceph-mgr-b-865b8c99f6-dfncm 2/2 Running 0 28m
rook-ceph-mon-a-5ddd755f66-nddjn 1/1 Running 0 29m
rook-ceph-mon-b-5db479f9d7-7lxl6 1/1 Running 0 28m
rook-ceph-mon-c-697676cfff-vrq92 1/1 Running 0 28m
rook-ceph-operator-85748bbfc4-ngbb8 1/1 Running 0 29m
rook-ceph-osd-0-768755cd67-vp8hl 1/1 Running 0 27m
rook-ceph-osd-1-67b498c7d8-vtmj9 1/1 Running 0 27m
rook-ceph-osd-2-58468b675b-6hctq 1/1 Running 0 27m
rook-ceph-osd-prepare-ksk8sn01-6nlr5 0/1 Completed 0 27m
rook-ceph-osd-prepare-ksk8sn02-2fgr5 0/1 Completed 0 27m
rook-ceph-osd-prepare-ksk8sn03-r5x4r 0/1 Completed 0 27m
rook-ceph-tools-79bc54b8d8-2z8gv 1/1 Running 0 26m
ヘルスチェックコマンド
kubectl -n rook-ceph get cephcluster
HEALTH_WARNと出てはいる
NAME DATADIRHOSTPATH MONCOUNT AGE PHASE MESSAGE HEALTH EXTERNAL
rook-ceph /var/lib/rook 3 9m58s Ready Cluster created successfully HEALTH_WARN
toolboxを使う
toolboxはCeph関連の便利コマンド一式が入っているPodのこと
とりあえずデプロイしておくとよい
kubectl create -f toolbox.yaml
kubectl exec -it deploy/rook-ceph-tools -n rook-ceph -- ceph status
ストレージの空き容量が少ないためのWARNな模様
ただ、仮想ディスクを容量可変で作っていて、IOがあったときにその分増えるのでそんな認識をしているのだと思う。
cluster:
id: fc21e1be-06db-49ef-8877-f7f5364353e8
health: HEALTH_WARN
mons a,b,c are low on available space
OSD count 0 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum a,b,c (age 9m)
mgr: a(active, since 8m), standbys: b
osd: 0 osds: 0 up, 0 in (since 9m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
StorageClassをデプロイ
ファイルシステムタイプを環境にあったもので指定する
csi.storage.k8s.io/fstype: xfs
今回の場合、OSファイルシステムがxfsだったのでそれに合わせた(もしかすると関係ないかも)
$ df -T
Filesystem Type 1K-blocks Used Available Use% Mounted on
devtmpfs devtmpfs 4096 0 4096 0% /dev
tmpfs tmpfs 8156560 0 8156560 0% /dev/shm
tmpfs tmpfs 3262624 3576 3259048 1% /run
tmpfs tmpfs 4096 0 4096 0% /sys/fs/cgroup
/dev/mapper/fedora_fedora-root xfs 15718400 12449324 3269076 80% /
tmpfs tmpfs 8156560 0 8156560 0% /tmp
/dev/sda2 xfs 1038336 243616 794720 24% /boot
/dev/sda1 vfat 613160 6308 606852
デプロイ
kubectl apply -f deploy/examples/csi/rbd/storageclass.yaml
cephblockpoolを確認してみるとPHASEが空白でスタックしている模様
kubectl get -n rook-ceph cephblockpool
NAME PHASE
replicapool
rook operatorのログを見る
k -n rook-ceph logs -f rook-ceph-operator-85748bbfc4-8jvbc
2022-09-28 22:02:45.924848 I | clusterdisruption-controller: creating the default pdb "rook-ceph-osd" with maxUnavailable=1 for all osd
2022-09-28 22:02:45.932693 I | clusterdisruption-controller: reconciling osd pdb reconciler as the allowed disruptions in default pdb is 0
2022-09-28 22:02:46.180891 I | clusterdisruption-controller: reconciling osd pdb reconciler as the allowed disruptions in default pdb is 0
2022-09-28 22:02:48.620161 I | cephclient: reconciling replicated pool replicapool succeeded
2022-09-28 22:02:48.972574 I | ceph-block-pool-controller: initializing pool "replicapool" for RBD use
2022-09-28 22:03:16.176714 I | clusterdisruption-controller: all "host" failure domains: []. osd is down in failure domain: "". active node drains: false. pg health: "cluster is not fully clean. PGs: [{StateName:unknown Count:1}]"
2022-09-28 22:03:16.183544 I | clusterdisruption-controller: reconciling osd pdb reconciler as the allowed disruptions in default pdb is 0
2022-09-28 22:03:46.401401 I | clusterdisruption-controller: all "host" failure domains: []. osd is down in failure domain: "". active node drains: false. pg health: "cluster is not fully clean. PGs: [{StateName:unknown Count:1}]"
2022-09-28 22:03:46.405714 I | clusterdisruption-controller: reconciling osd pdb reconciler as the allowed disruptions in default pdb is 0
2022-09-28 22:04:16.630550 I | clusterdisruption-controller: all "host" failure domains: []. osd is down in failure domain: "". active node drains: false. pg health: "cluster is not fully clean. PGs: [{StateName:unknown Count:1}]"
2022-09-28 22:04:16.634945 I | clusterdisruption-controller: reconciling osd pdb reconciler as the allowed disruptions in default pdb is 0
operatorを再起動する
PhaseがProgressにはなるが、永遠にProgress
k -n rook-ceph delete pod rook-ceph-operator-85748bbfc4-8jvbc
ここで、データボリュームを固定容量で作り直して再アタッチする。
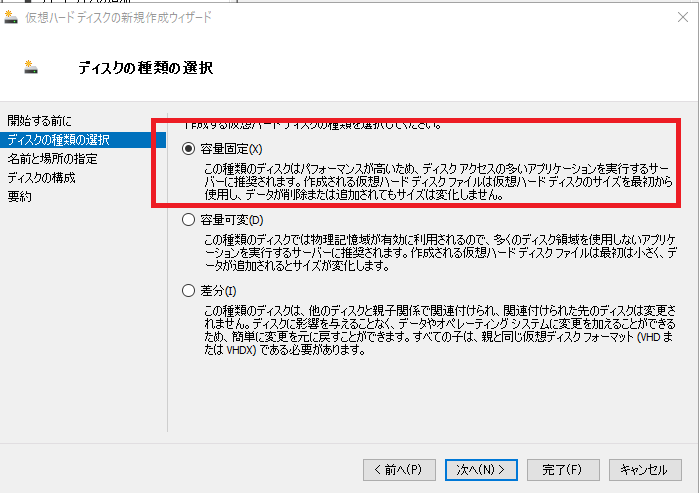
100GBを確保 * 3台。
その後、下のディスククリーンアップをする。
その後、再度クラスタ作り直すすとReadyになった。
NAME PHASE
replicapool Ready
動作確認
cephストレージのscから起動されるPVCが予めセットされているサンプルをデプロイする
kubectl apply -f deploy/examples/mysql.yaml
pvc
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-pv-claim Bound pvc-0150862e-16c0-47fb-bf03-4b094b6d0221 20Gi RWO rook-ceph-block 4m33s
pod
kubectl get pod
NAME READY STATUS RESTARTS AGE
wordpress-mysql-776b4f56c4-pjvzw 1/1 Running 0 5m26s
大丈夫そう。
リセット
備忘録的な。
cephクラスタのDeleteがうまくいかないときは、クラスタをふっ飛ばしたほうが多分きれいに戻ると思います。
Kubernetesクラスタをリセットする
kubeadm reset
rm -fr /var/lib/rook
ディスクをクリーンアップ
DISK="/dev/sdb"
# Zap the disk to a fresh, usable state (zap-all is important, b/c MBR has to be clean)
sgdisk --zap-all $DISK
# Wipe a large portion of the beginning of the disk to remove more LVM metadata that may be present
dd if=/dev/zero of="$DISK" bs=1M count=100 oflag=direct,dsync
# SSDs may be better cleaned with blkdiscard instead of dd
blkdiscard $DISK
# Inform the OS of partition table changes
partprobe $DISK
reboot
# master
kubeadm init --apiserver-advertise-address=192.168.11.51 --pod-network-cidr=10.0.0.0/16 --cri-socket=unix:///var/run/crio/crio.sock
# node
kubeadm join 192.168.11.51:6443 --token kj2nid.fvqh9oeyw21s32q5 \
--discovery-token-ca-cert-hash sha256:014fb4ce81f5fa910dfe8449a521859ce0d2ed2f592e5618a2748cb695f575d3
参考
Discussion