Stable Diffusionをふんわり理解!The Illustrated Stable Diffusionの翻訳記事
以下はJay AlammarさんによるStable Diffusion解説記事「The Illustrated Stable Diffusion」の翻訳となります。Stable Diffusionを触ってみて、「仕組みを理解したい」という方は単体の論文やその解説記事を読みにいく前に、まずここから始めてみるのがおすすめです。記事の最終更新日時は2022年11月であるため情報が少し古いことに注意してください。
以下翻訳。
The Illustrated Stable Diffusion
AI画像生成は、人々(私も含め)の心を揺さぶる最新のAI能力です。テキスト記述から鮮やかなビジュアルを作成する能力には魔法のような質があり、人間がアートを作る方法における明確なシフトを示しています。Stable Diffusionのリリースは、高性能モデルを大衆に提供したという点で、この発展の明確なマイルストーンです(画像の質、速度、および比較的低いリソース/メモリ要件の観点からの性能)。
AI画像生成を実験した後、どのように機能するのか疑問に思うかもしれません。
これはStable Diffusionの仕組みについての易しい紹介です。

Stable Diffusionは、様々な方法で使用できます。まず最初にテキストのみからの画像生成(txt2img)に焦点を当てましょう。上の画像は、テキスト入力により画像が生成される様子を表しています。テキストから画像の生成以外に、画像を再生成することもStable Diffusionはできます(その際入力はテキスト+画像となります)。

それではStable Diffusionの内部を見てみましょう。そうすることで、内部のコンポーネントがどのようなもので、それらがどのような役割を持つかを知ることができ、画像生成時のオプションやパラメーターが何を意味するかを理解できるでしょう。
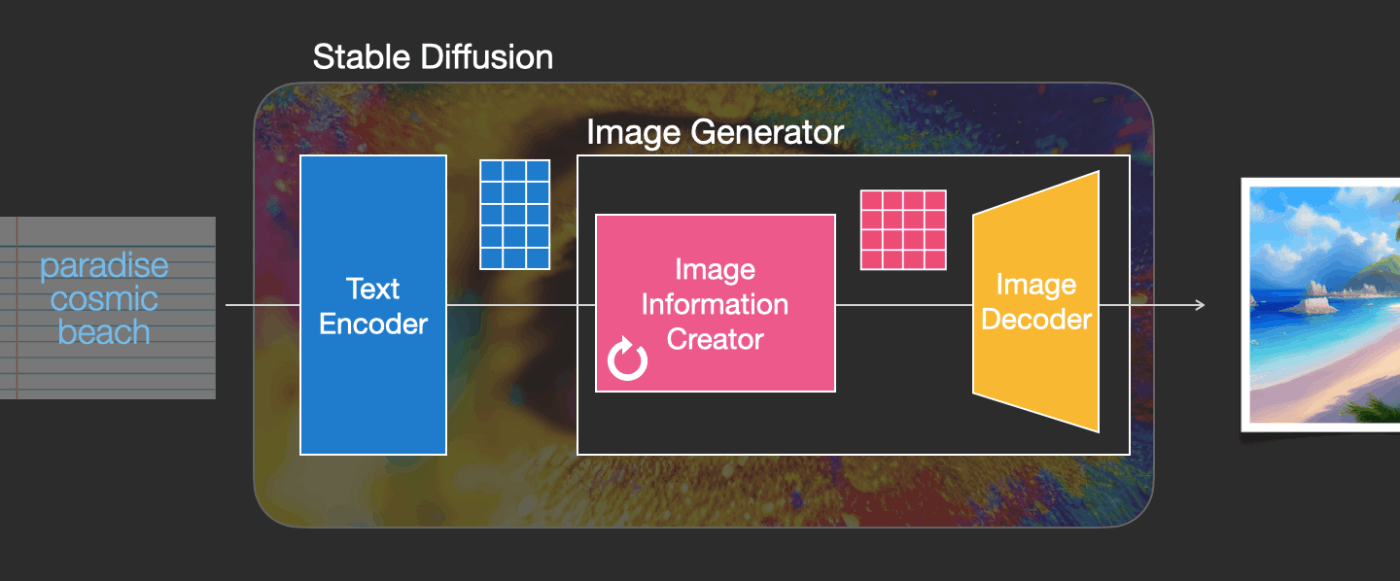
1. Stable Diffusionのコンポーネント
Stable Diffusionは、いくつかのコンポーネントとモデルで構成されたシステムです。つまり、一つの大きなモデルではないということです。
内部を見て最初に分かることは、テキストの内容を数値表現に変換するテキスト理解コンポーネント(Text Understander)があるということです。

まずはぼんやりとしたイメージから説明を始めて、この記事の後半でより機械学習の詳細に入ります。しかし敢えてここで少しだけ詳しい説明をすると、このテキスト理解コンポーネントは特別なTransformer系言語モデル(CLIPモデルのテキストエンコーダー)であると言えます。テキストエンコーダーは入力テキストを受け取り、テキスト内の各単語/トークンを表す数値のリスト(トークンごとにベクトルで表される)を出力します。
その情報は次に画像生成機(Image Generator)に渡されます。画像生成機自体もいくつかのコンポーネントで構成されています。

画像生成は次の2段階を経て行われます。
1.1. Image Information Generator: 画像情報作成者
このコンポーネントはStable Diffusionのキモとなる所で、Stable Diffusionが以前の画像生成モデルよりも優れた性能は発揮できているのはここの違いによるものが大きいです。
このコンポーネントは複数のステップを実行して画像情報を生成します。これはStable Diffusionインターフェースで見かけるstepsというパラメーターで、よくデフォルトで50または100に設定されています。
画像情報作成者は完全に画像情報空間(潜在空間、latent空間)で動作します。この意味については記事の後半で詳しく説明します。この特性により、ピクセル空間で動作した以前の拡散モデルよりも処理が速くなっています。技術的には、このコンポーネントはUNetニューラルネットワークとスケジューリングアルゴリズムで構成されています。
「拡散」という過程は、このコンポーネントの内部で起こります。拡散過程とは情報がステップバイステップで処理されるプロセスのことで、これを経た後に最終的に次のコンポーネント(画像デコーダー)によって高品質の画像が生成されます。
1.2. Image Decoder: 画像デコーダー
画像デコーダーは、情報作成者から得た情報で絵を描画します。画像生成プロセスの最後に一度だけ実行され、最終的なピクセル画像を生成します。

これにより、Stable Diffusionを構成する3つの主要コンポーネント(それぞれに独自のニューラルネットワークがあります)が見えてきます:
-
テキストエンコーディングのためのClipText。
入力:テキスト。
出力:768次元の77トークン埋め込みベクトル -
情報(潜在表現/latent)空間で情報を徐々に処理/拡散するためのUNet + スケジューラ。
入力:テキストの埋め込みベクトルと、ノイズで構成される多次元配列(数字の構造化リスト、テンソルとも呼ばれます)
出力:処理された情報配列 -
処理された情報配列を使用して最終画像を描画するオートエンコーダデコーダー。
入力:処理された情報配列(テンソルのサイズ:(4,64,64))
出力:結果の画像(テンソルのサイズ:(3, 512, 512)これは(RGB,幅,高さ)に対応)

2. 拡散過程とは何か?
拡散過程は、ピンクの「画像情報作成者(Image Information Generator)」コンポーネント内で行われるプロセスです。入力テキストを表すトークンの埋め込みを持ち、ランダムな開始画像情報配列(これらも潜在表現/latentと呼ばれます)を持つプロセスは、画像デコーダーが最終画像を描くために使用する情報配列を生成します。

このプロセスはステップバイステップの方法で行われます。各ステップでは関連する情報がどんどん追加されます。プロセスが何を行っているか直感的に理解できるように、初期のランダム状態のlatent配列を取り出して変換してみると、それは視覚的には完全なノイズであることが見てとれます。ここで行ったlatent配列から画像への変換は、画像デコーダーを通すことで行われました。

拡散過程は複数のステップで行われ、各ステップはlatent配列を入力とし、それをもとに新たなlatent配列を生成します。新しく生成されたlatent配列は入力テキストとモデルが学習を経て学んだ画像の視覚的な情報をより適切に表すようになります。

これらのlatent配列を視覚化して、各ステップでどのような情報が追加されているかを見ることができます。
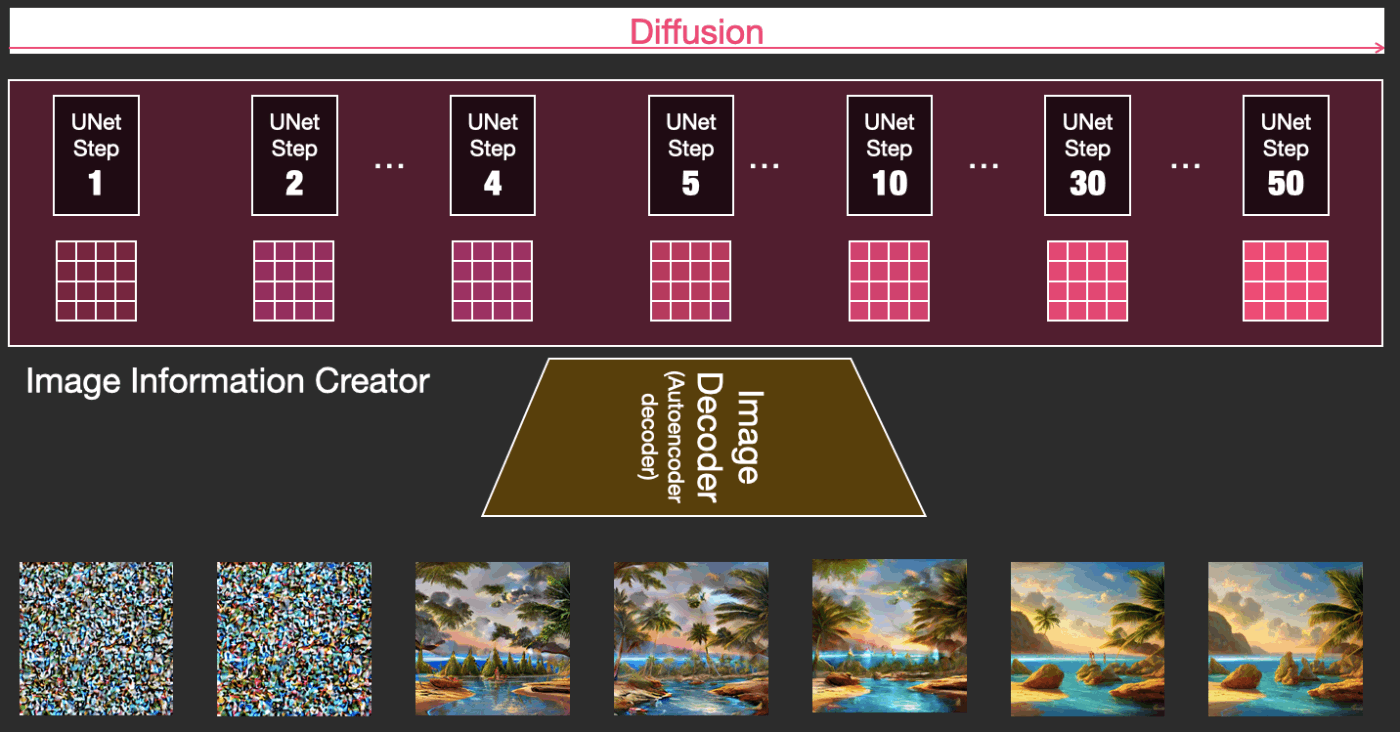
そのプロセスは見ていて感動を覚えます。
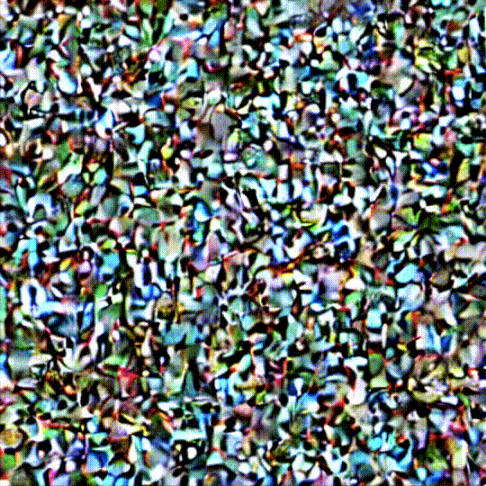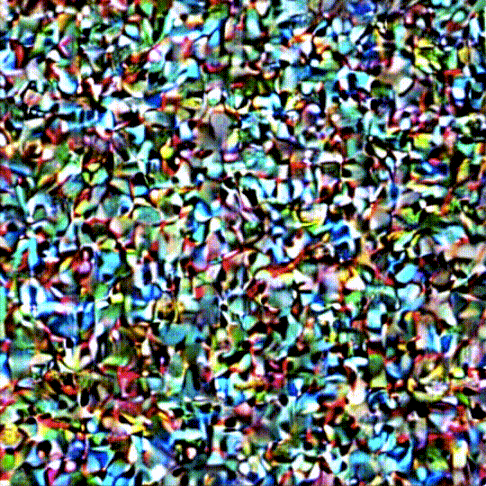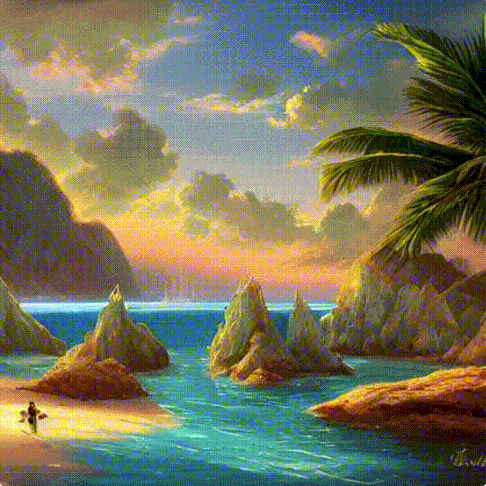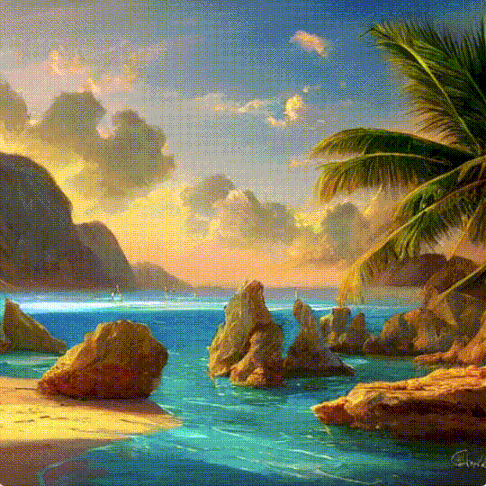
特に2から4ステップの間に何かが起こっています。まるで輪郭がノイズから浮かび上がるかのようです。
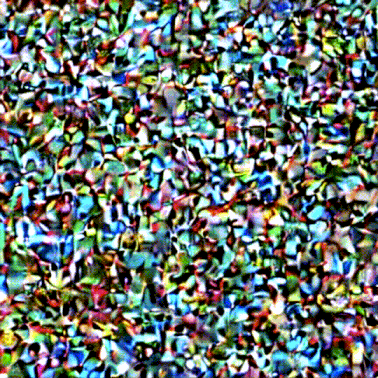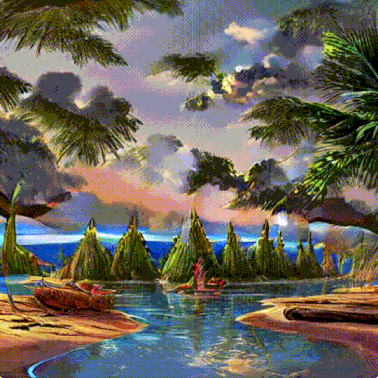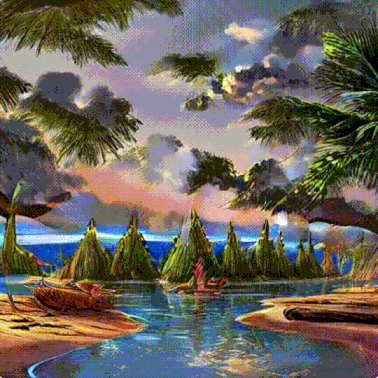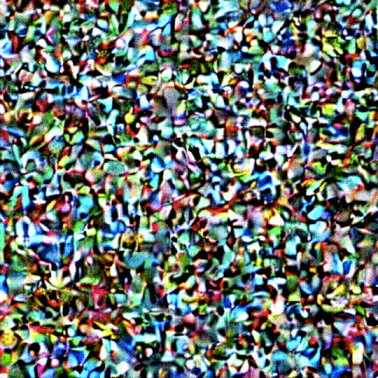
2.1. 拡散の仕組み
拡散モデルで画像を生成するという発想は、強力なコンピュータビジョンモデルの存在に依存しています。十分に大きなデータセットがあれば、拡散モデルは複雑な処理を学習することができます。拡散モデルは、画像の生成を次のようなタスクに落とし込むことで画像生成を実現します。
ある画像があるとします。ここで、ノイズを生成し、そのノイズを画像に追加します。
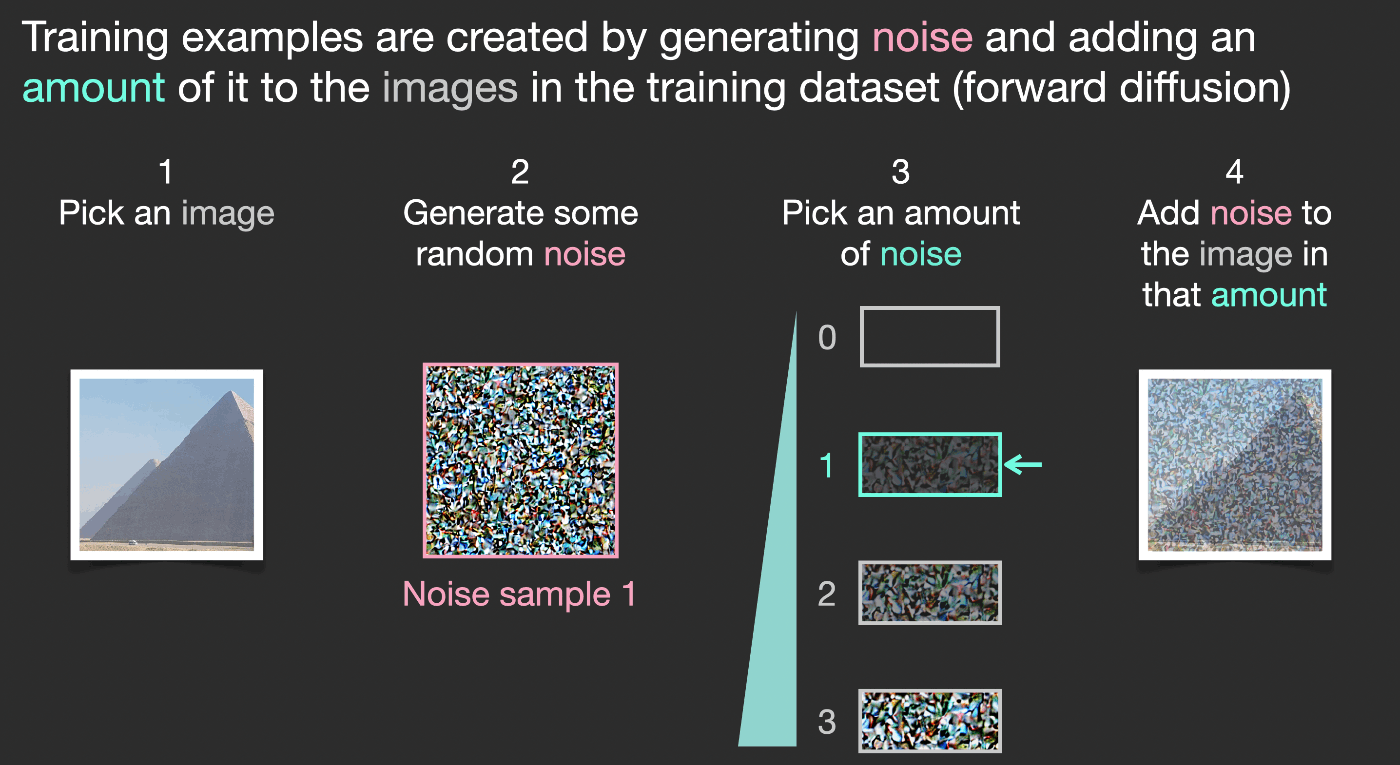
これは学習データと見なすことができます。同じ操作を繰り返して、画像生成モデルの主要コンポーネントを学習させるための学習データをたくさん作成することができます。
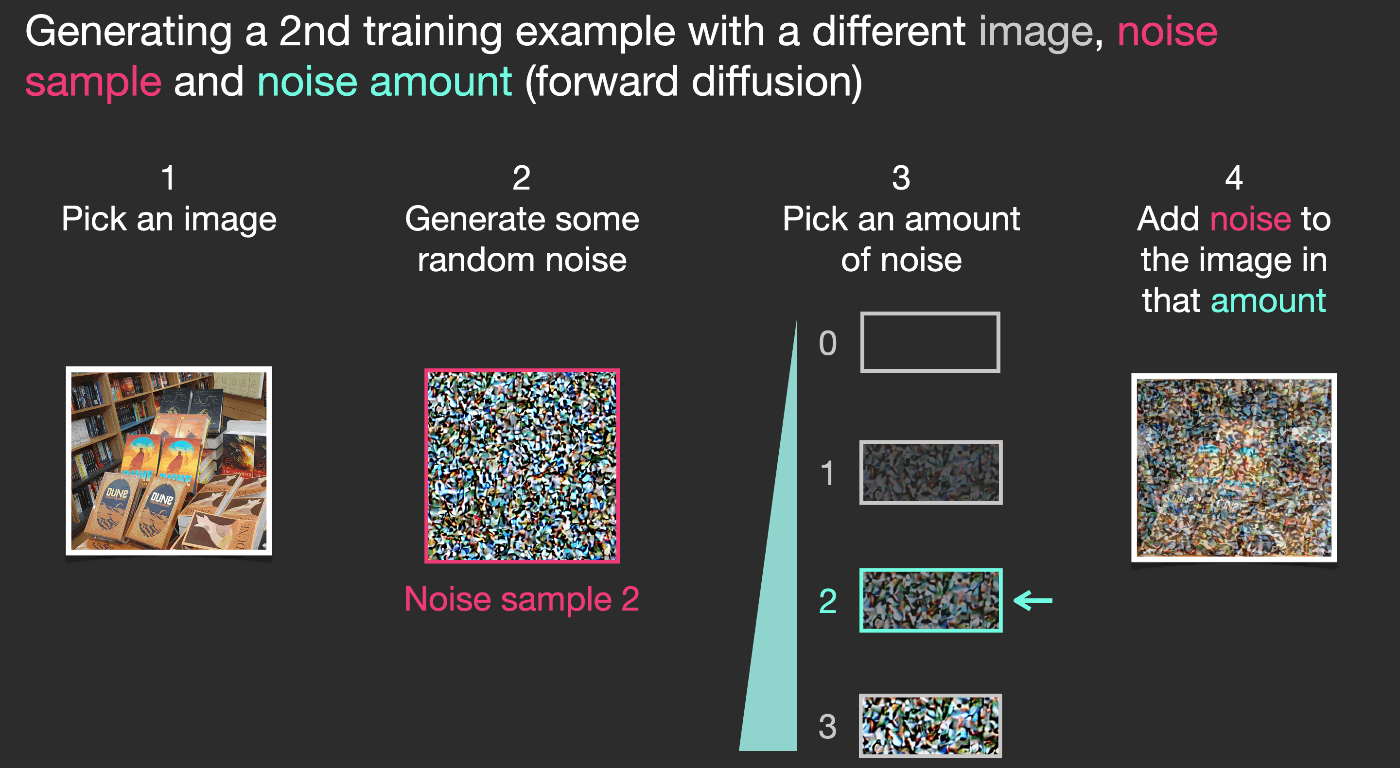
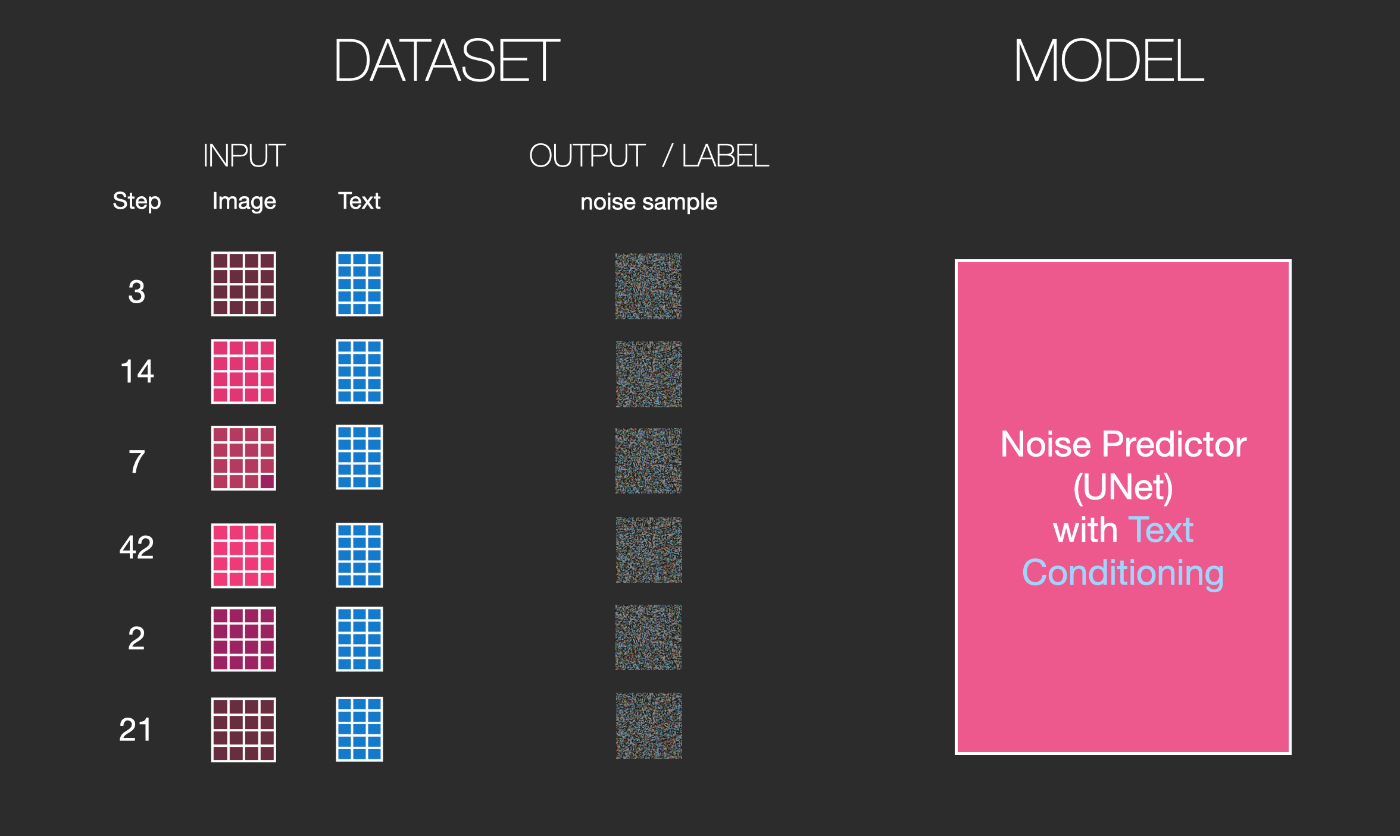
この例では、画像に加えるノイズの量を0(ノイズなし)から4(全ノイズ)の4段階で表していますが、画像に加えるノイズの量は簡単に制御できるため、数十の段階にわたって広げることができ、学習データセットのすべての画像ごとに数十の学習データを作成することができます。

このデータセットを使用して、ノイズ予測器を学習させ、優れたノイズ予測器を作ることができます。このノイズ予測機はある特別な方法で実行すると画像を生成することができます。機械学習に触れたことのある人なら、この学習ステップは見慣れているはずです。

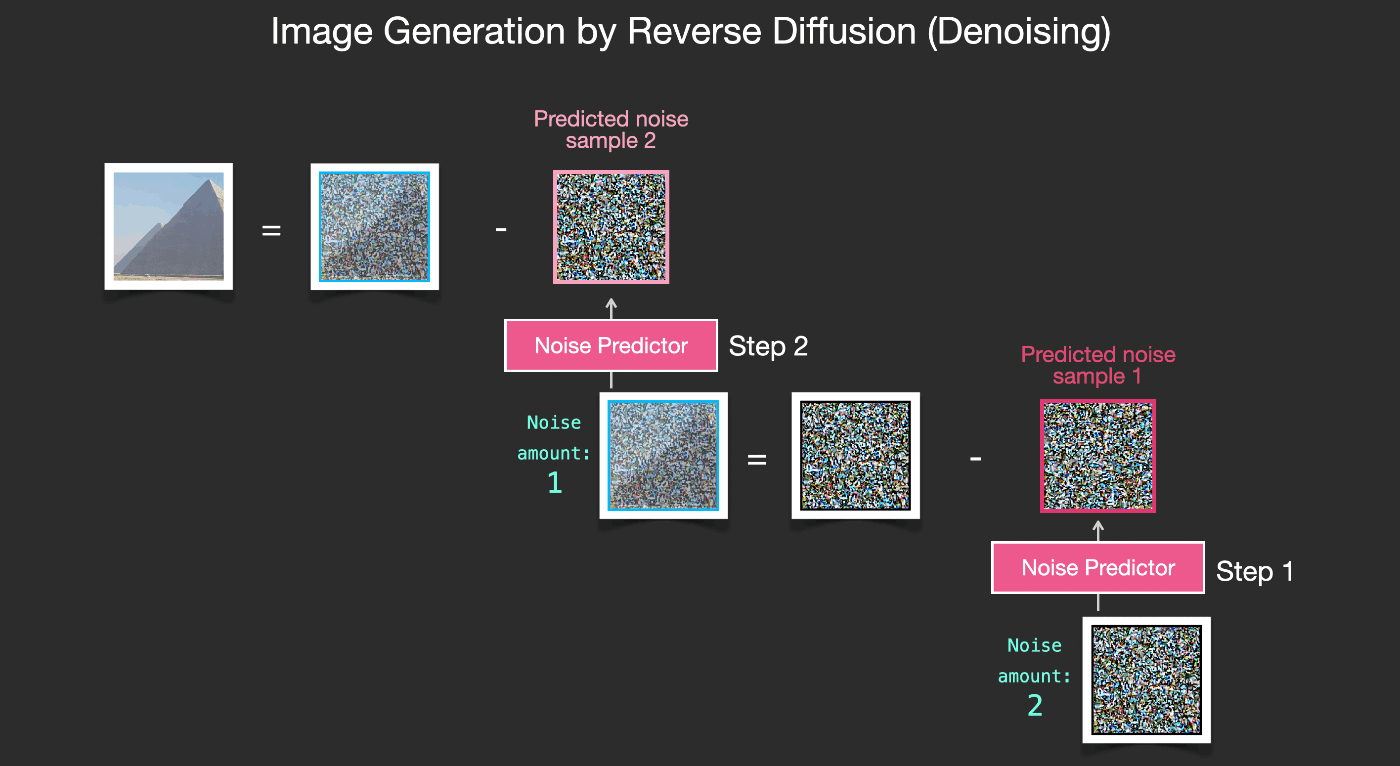
では、ノイズ予測器がどのように画像を生成するかを見てみましょう。
2.2. ノイズを除去して画像を描画
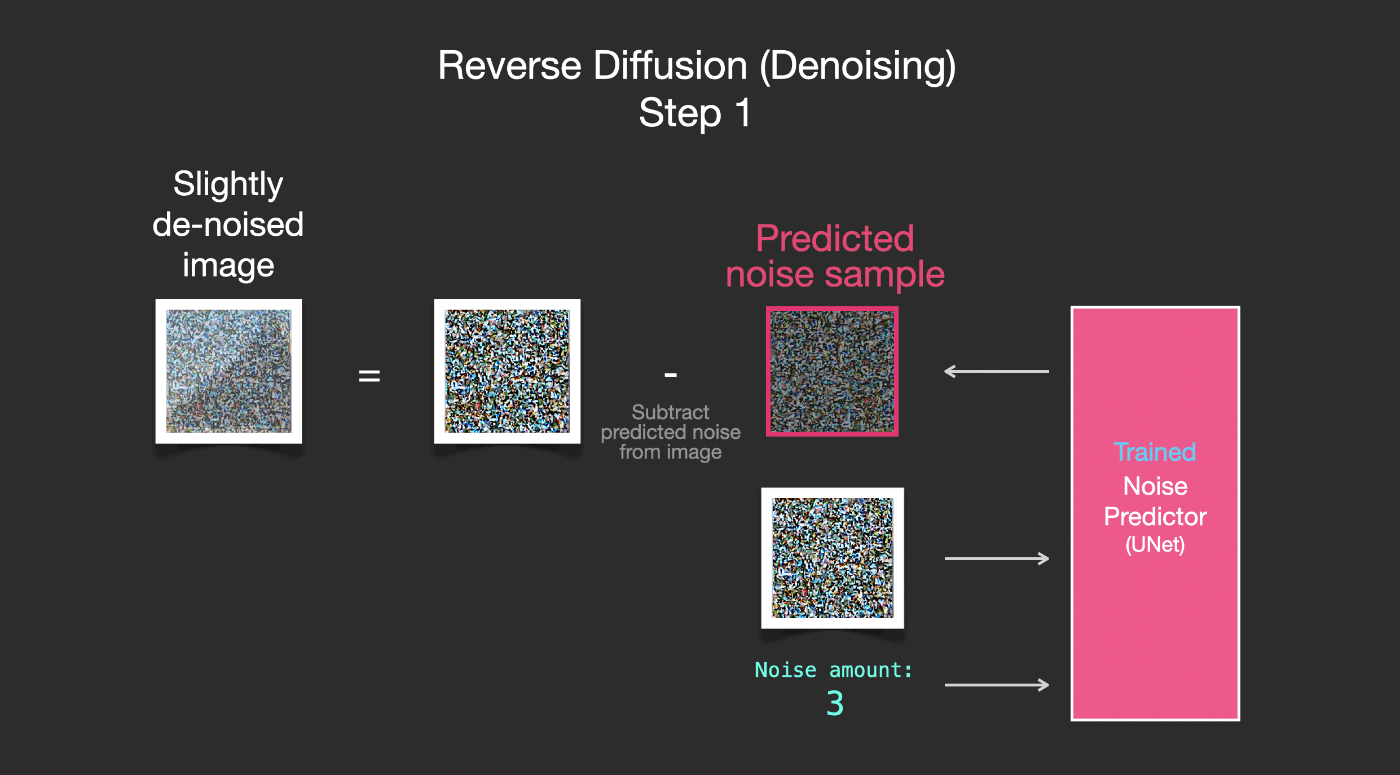
学習されたノイズ予測器は、ノイズの多い画像と、デノイジングステップの数が入力されると、ノイズのスライスを予測することができます。
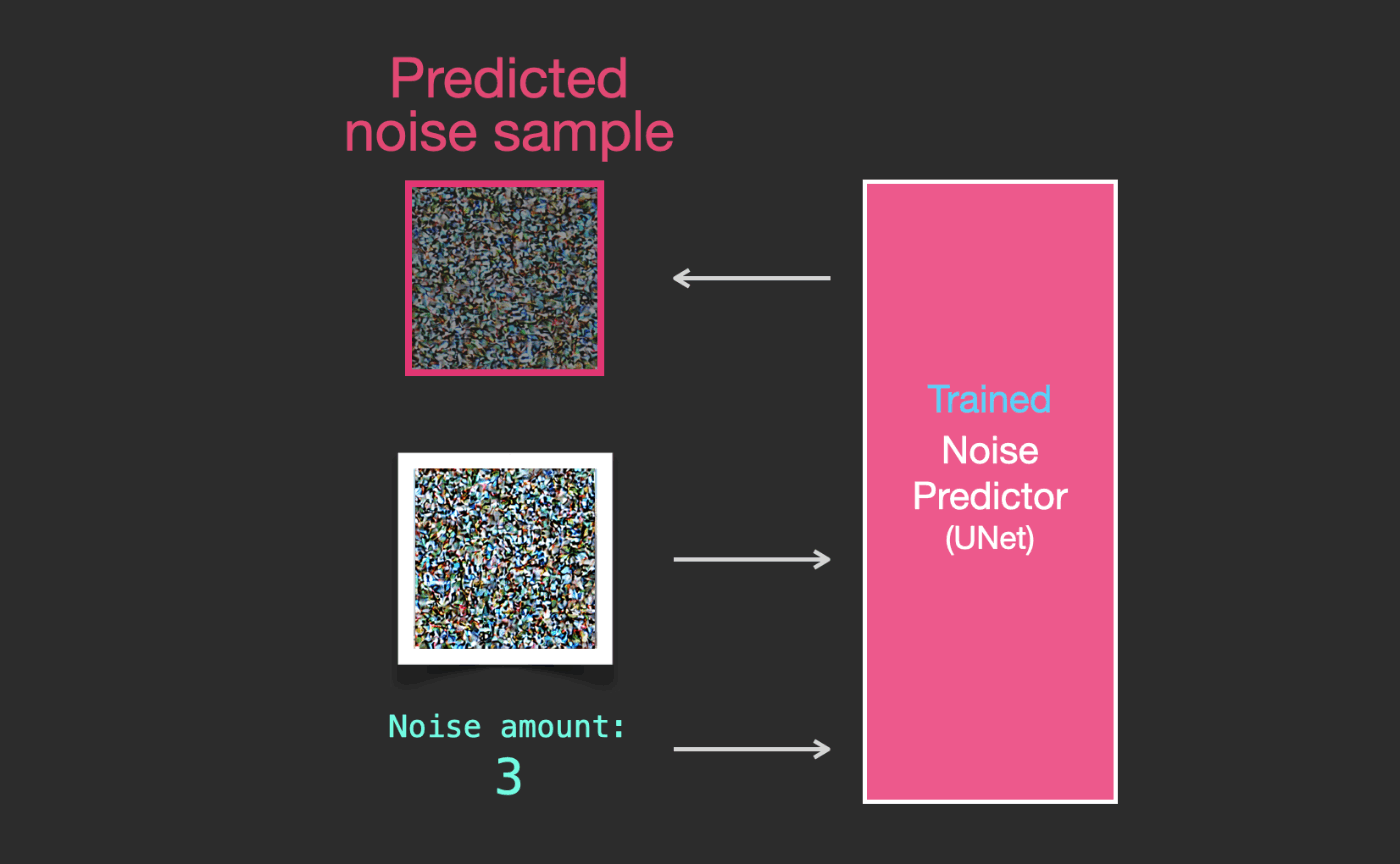
サンプリングされたノイズは、そのノイズを画像から引くとモデルが学習した画像に近い画像が得られるように予測されます(ここで得られた画像はデータセットに存在する特定の画像に近づくのではなく、分布が近づきます。 - 空だったら青く、地面の上に位置し、人だったら2つの目を持ち、猫だったら尖った耳と明らかに無関心な表情をしています)。
学習データセットが美的に魅力的な画像(例えば、Stable Diffusionが訓練されたLAION Aesthetics)の場合、結果の画像は美的に魅力的になる傾向があります。ロゴの画像で訓練すると、ロゴ生成モデルができます。
これで拡散モデルによる画像生成の説明を終えます。これが主にDenoising Diffusion Probabilistic Modelsで説明されているものです。これで拡散過程について直感的に理解することができたので、Stable DiffusionだけでなくDall-E 2やGoogleのImagenの主要コンポーネントについても理解したことになります。
ここまで説明した拡散過程は、テキストデータを使用せずに画像を生成します。したがって、このモデルを利用すると、素晴らしい画像を生成することができますが、それがピラミッドの画像であるか、猫の画像であるか、あるいは他の何かであるかをコントロールすることはできません。次のセクションでは、モデルが生成する画像をコントロールするために、これまで説明して画像生成プロセスにテキストがどのように組み込まれるかについて説明します。
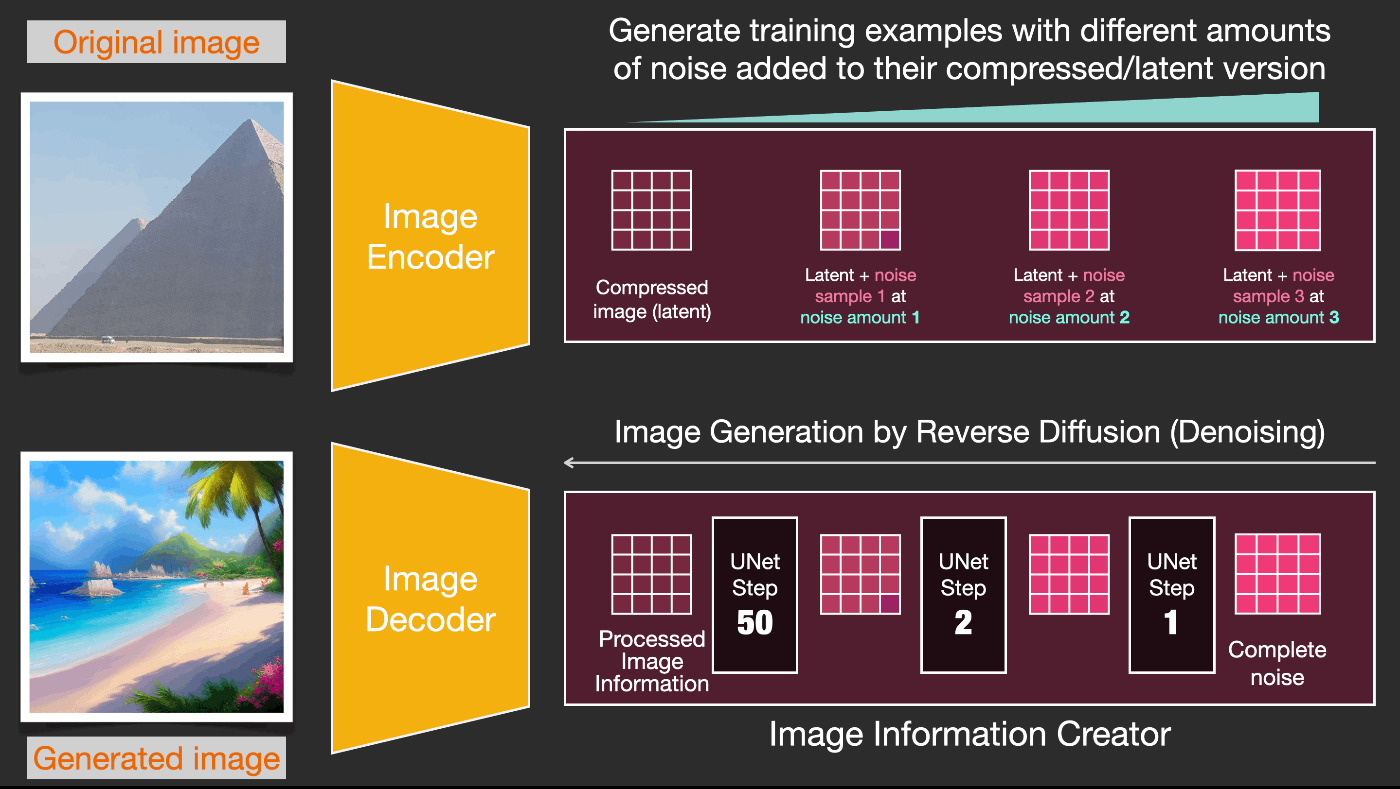
3. 速度向上:ピクセル画像ではなく圧縮(潜在)データ上での拡散
画像生成プロセスを高速化するために、Stable Diffusionの論文は、ピクセル画像自体ではなく、画像の圧縮バージョン上で拡散プロセスを実行します。論文ではこれを「潜在空間への出発」と呼んでいます。
この圧縮処理(およびその後の解凍/描画処理)は、オートエンコーダーを介して行われます。オートエンコーダーは、エンコーダーを使用して画像を潜在空間に圧縮し、その後、圧縮された情報のみを使用してデコーダーを使用して画像を再構築します。

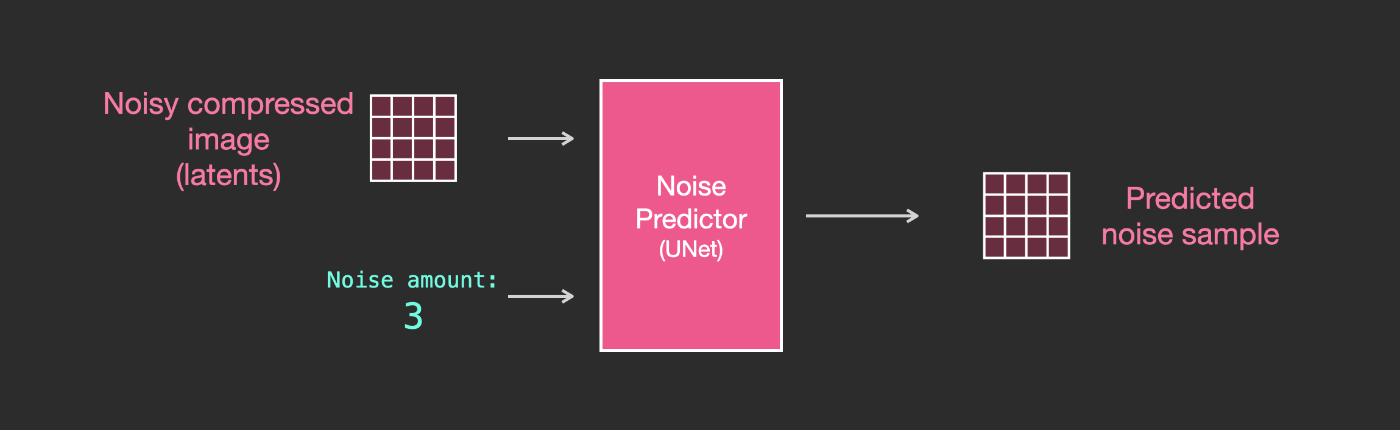
これで、圧縮された潜在空間での前方拡散プロセスが行われます。ノイズのスライスは、ピクセル画像ではなく、それらの潜在空間に適用されるノイズです。したがって、ノイズ予測器は実際には、圧縮された表現(潜在空間)のノイズを予測するようにトレーニングされています。

前方プロセス(オートエンコーダーのエンコーダーを使用)は、ノイズ予測器を学習させるためのデータを生成する方法です。学習が終了すると、逆プロセス(オートエンコーダーのデコーダーを使用)を実行することによって画像を生成することができます。
これら2つのフローは、LDM/Stable Diffusion論文の図3に示されています:
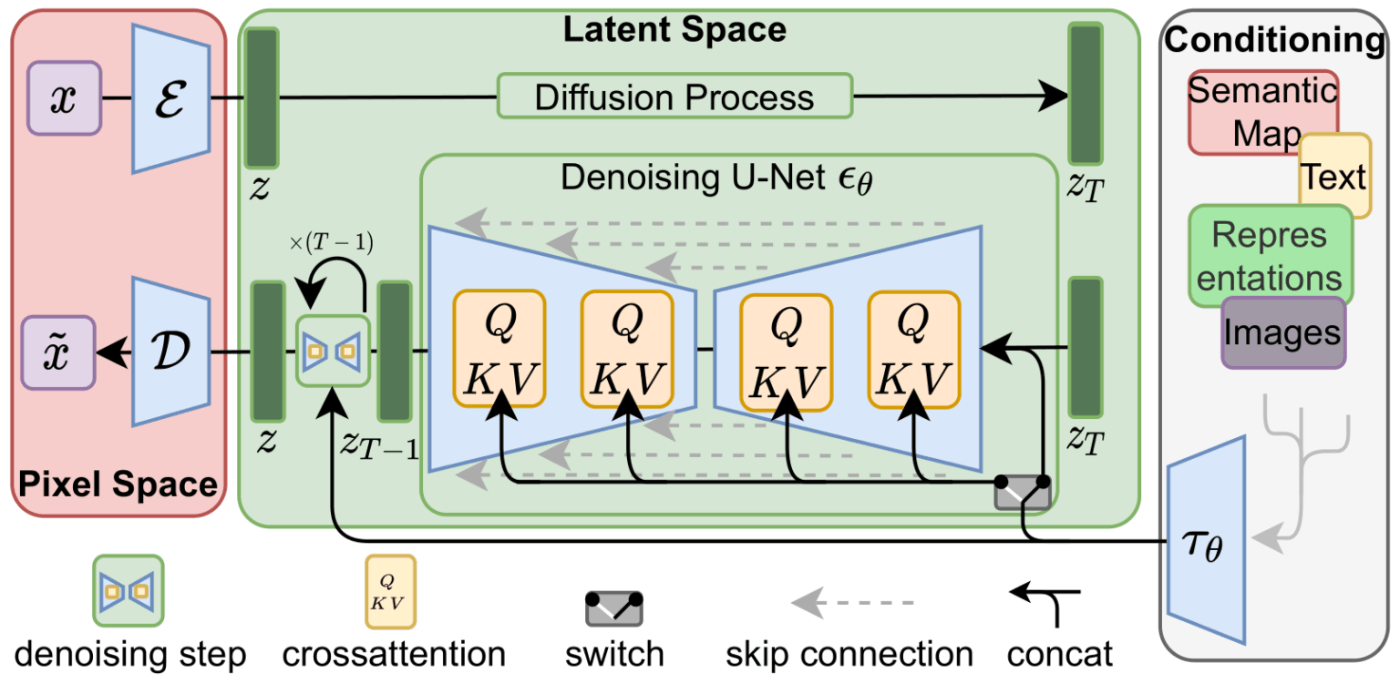
この図は、この場合、モデルが生成する画像を記述するテキストプロンプトである「条件付け」コンポーネントも示しています。では、テキストコンポーネントについて詳しく見ていきましょう。
3.1. テキストエンコーダー:Transformer系言語モデル
Transformer系言語モデルは、テキストプロンプトを受け取り、トークン埋め込みを生成する言語理解コンポーネントとして使用されます。リリースされたStable DiffusionモデルはClipText(GPTベースのモデル)を使用していますが、論文ではBERTが使用されています。
Imagenの論文で示されているように、言語モデルの選択は重要です。より大きな言語モデルに切り替えることは、より大きな画像生成コンポーネントよりも生成された画像の品質に大きな影響を与えました。
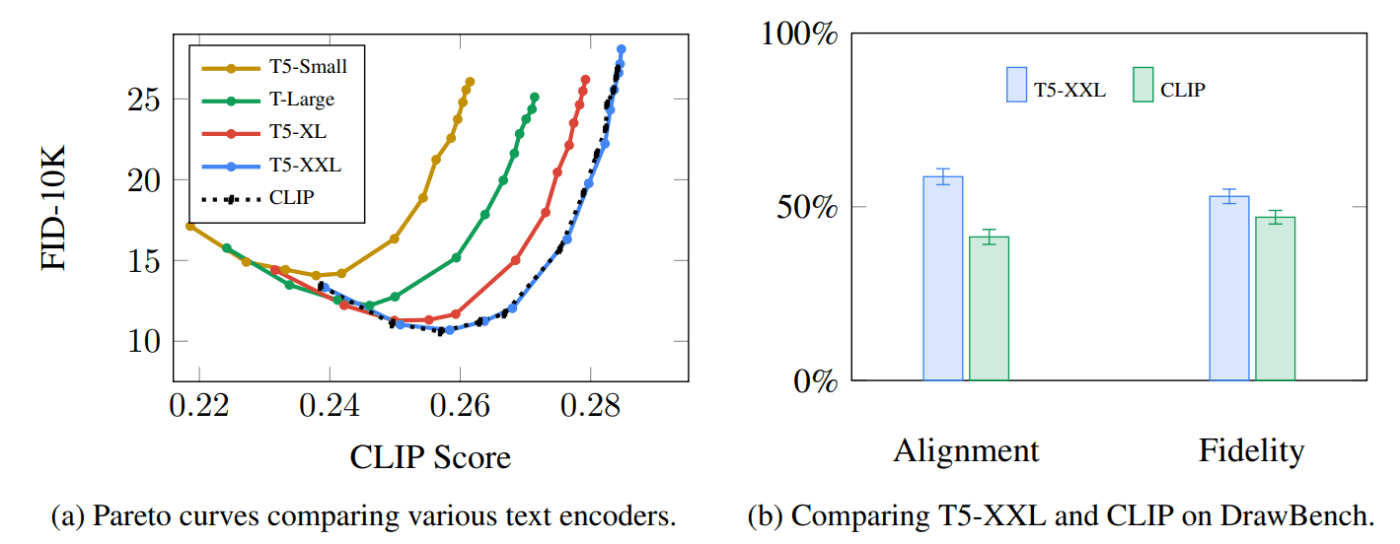
より大きく/優れた言語モデルは、画像生成モデルの品質に大きな影響を与える。出典:Saharia et al.によるGoogle Imagen論文.Figure A.5.
初期のStable Diffusionモデルは、OpenAIによってリリースされた事前学習済みのClipTextモデルをそのまま利用しています。将来的には、新しくリリースされたはるかに大きなOpenCLIPに切り替える可能性があります(2022年11月の更新:事実、Stable Diffusion V2はOpenClipを使用しています)。OpenClipには、ClipTextの6300万パラメータに対して、最大3億5400万パラメータのテキストモデルが含まれています。
3.1.1 CLIPのトレーニング方法
CLIPは、画像とそのキャプションのデータセットで学習されています。以下のような画像とそのキャプションのセットが400万あると考えてください。

画像とそのキャプションのデータセット
実際には、CLIPはWebからクロールされた画像とその「alt」タグでトレーニングされました。
CLIPは画像エンコーダーとテキストエンコーダーの組み合わせです。その学習プロセスは、画像とそのキャプションを取り、それぞれ画像とテキストエンコーダーでエンコードするということに単純化することができます。
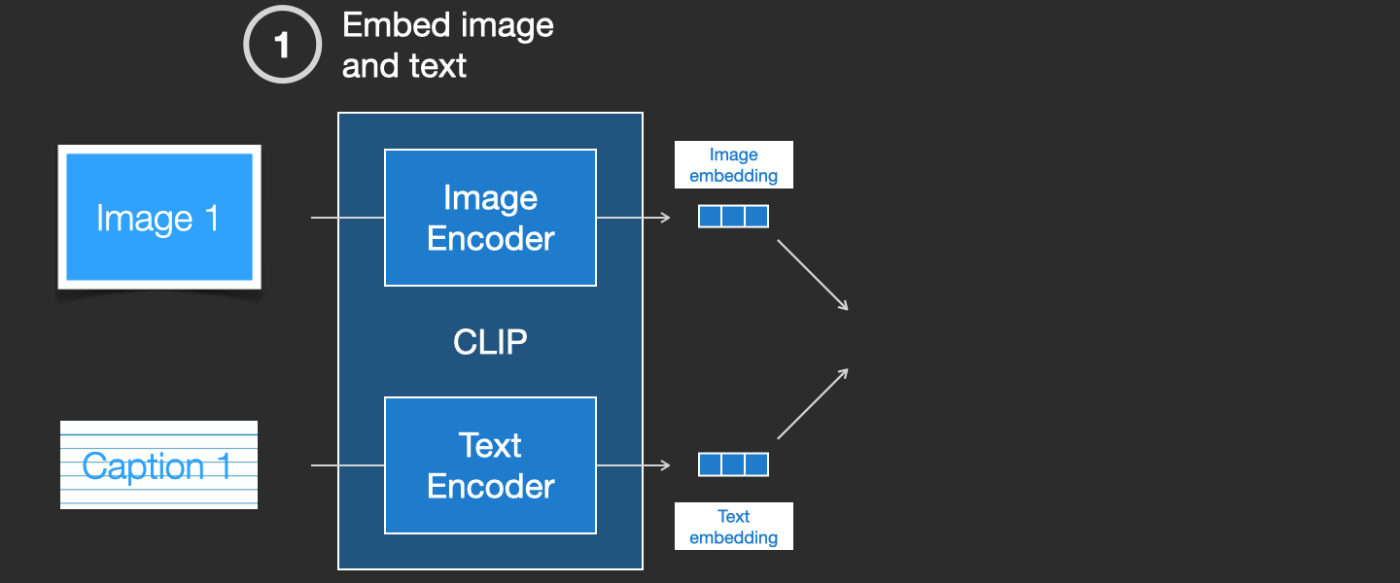
次に、コサイン類似度を使用して、得られた埋め込みを比較します。学習を初めたての頃は、テキストが画像を正しく記述していても、類似度は低いでしょう。
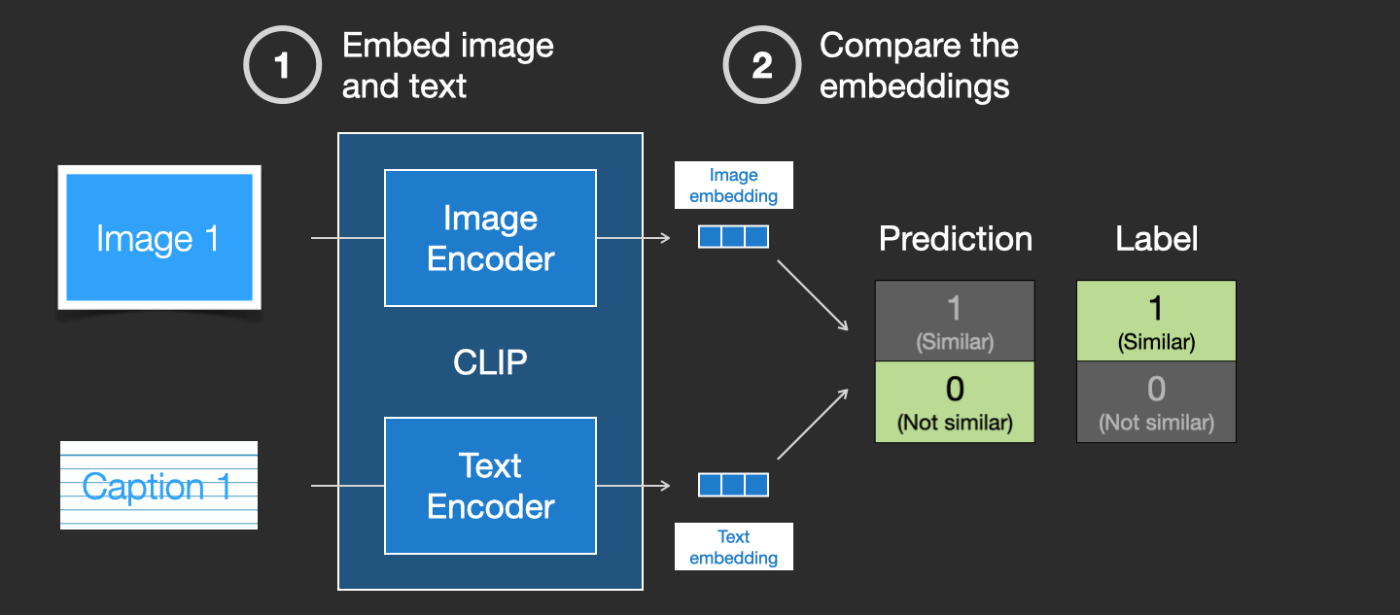
次に、2つのモデルを更新して、次に画像の埋め込みとテキストの埋め込みを作る際に、得られる埋め込みが類似しているようにします。
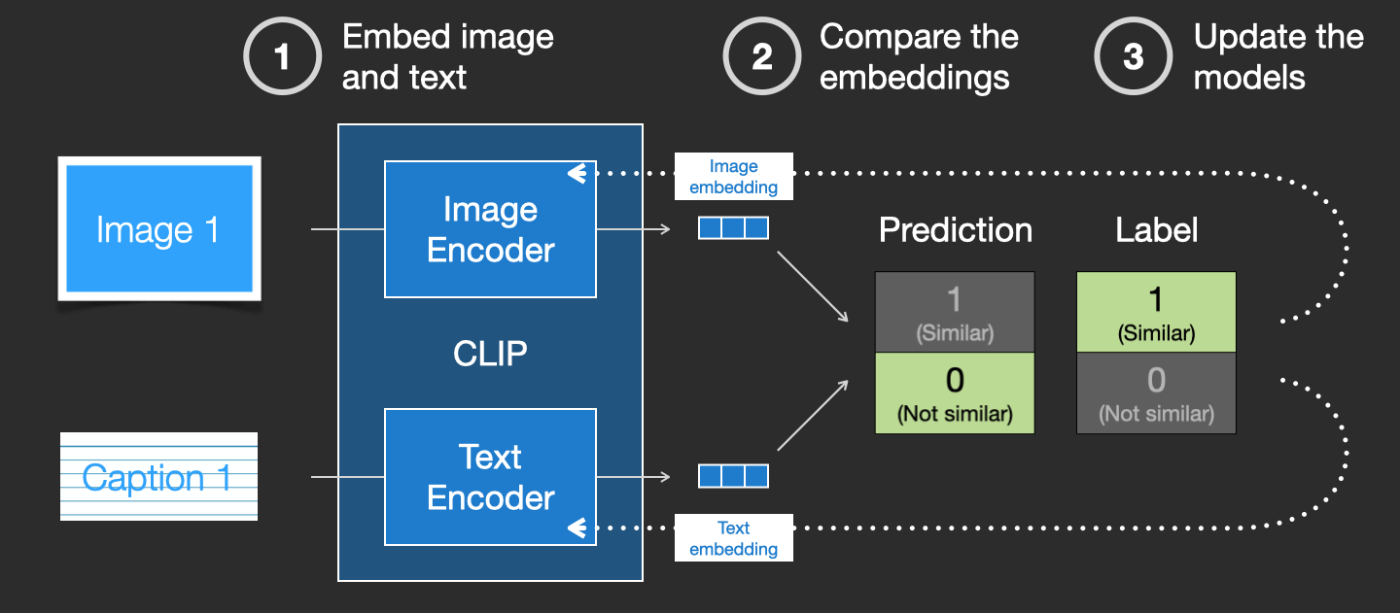
このプロセスをデータセット全体で、大きなバッチサイズで繰り返すことにより、犬の画像と「犬の写真」という文が類似しているような埋め込みを生成できるようにエンコーダーを得ることができます。word2vecと同様に、学習プロセスには、一致しない画像とキャプションの否定例も含める必要があり、モデルはそれらに低い類似度スコアを割り当てる必要があります。
4. 画像生成プロセスにテキスト情報をフィードする
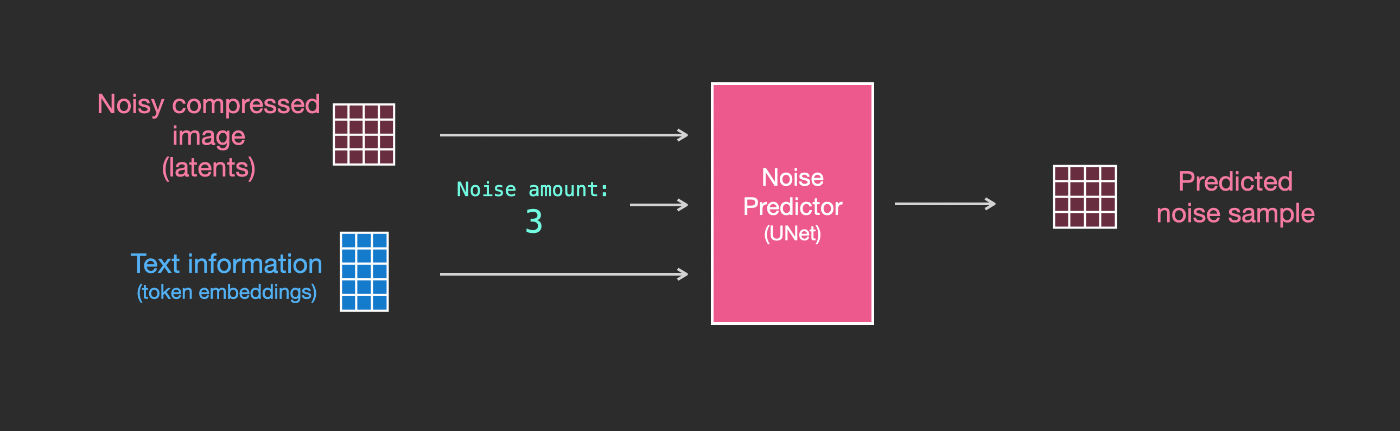
テキストを画像生成プロセスの一部とするためには、テキストを入力として使用できるようにノイズ予測器を調整する必要があります。
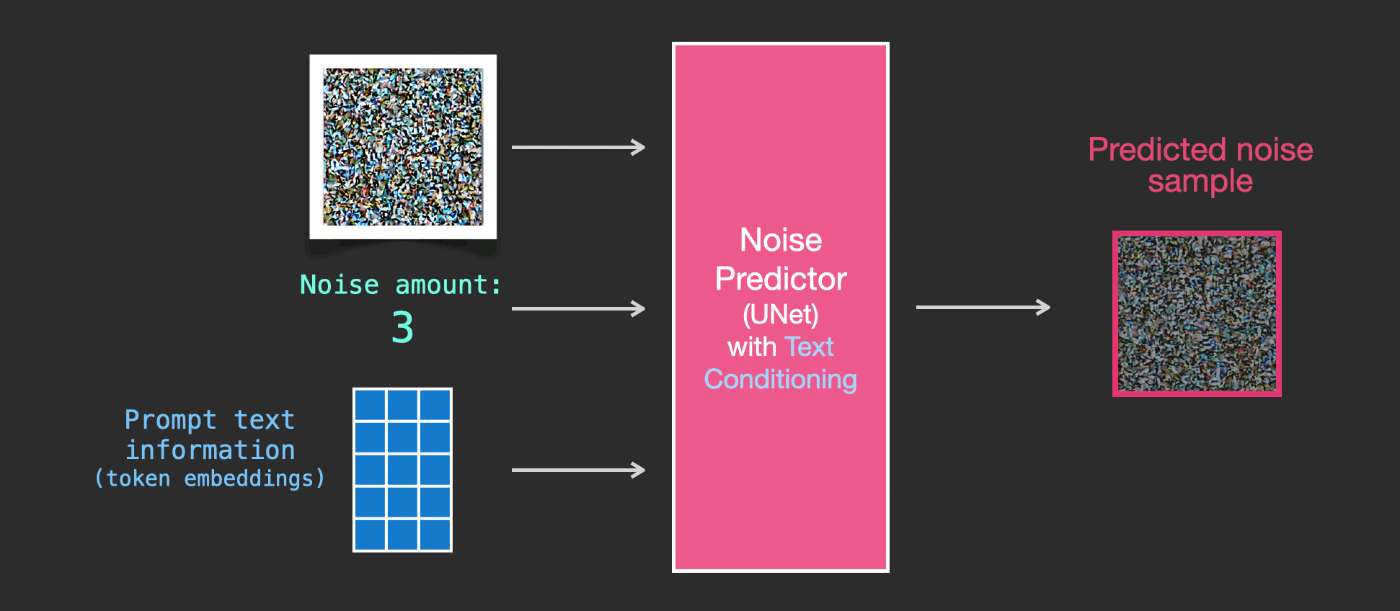
私たちのデータセットには、エンコードされたテキストが含まれています。潜在空間で操作しているため、入力画像と予測されたノイズはどちらも潜在空間にあります。
Unet内部でテキストトークンがどのように使用されるかをよりよく理解するために、Unetの内部構造をより詳細を見てみましょう。
4.1. Unetノイズ予測器のレイヤー(テキストなし)
まず、テキストを使用しないdiffusion Unetについて見てみましょう。その入出力は以下のようになります。
内部では、以下のことがわかります:
- Unetは、latents配列を変換するレイヤーの塊である
- 各レイヤーは前のレイヤーの出力に処理を施す
- 出力の一部は(residual connectionsを介して)ネットワーク内の後の処理に供給される
- タイムステップはタイムステップ埋め込みベクトルに変換され、それがレイヤーで使用される
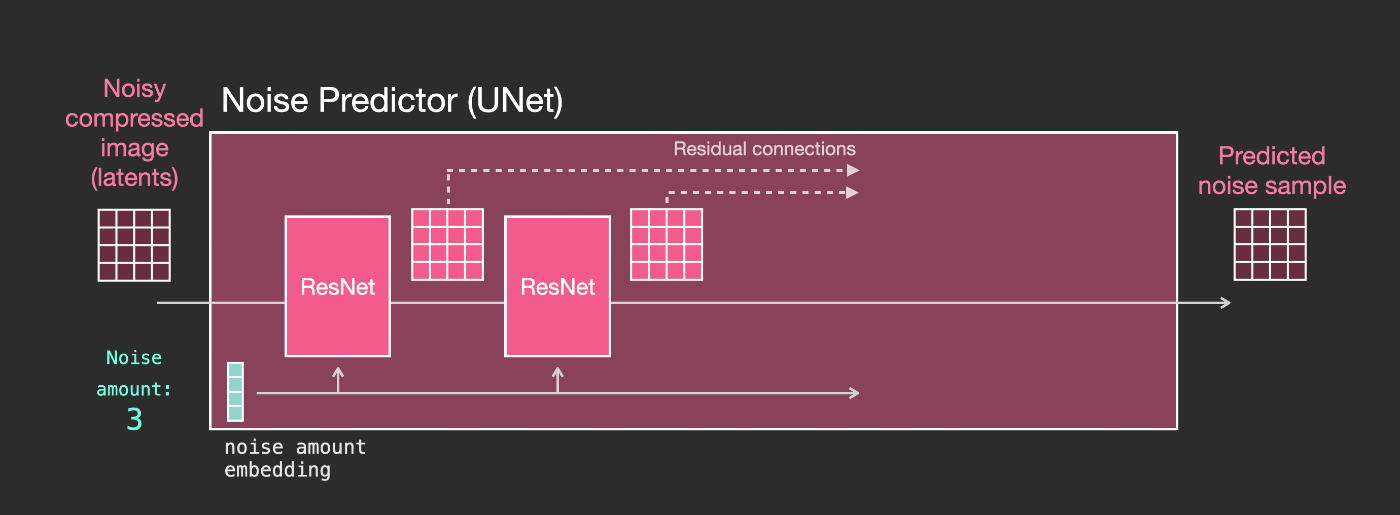
4.2. Unetノイズ予測器のレイヤー(テキストあり)
次に、このシステムをテキスト情報を受け取れるように変更する方法を見てみましょう。
テキスト入力(テキスト条件付け)を受け取れるようにするために必要な主な変更は、ResNetブロックの間にAttention層を追加することです。
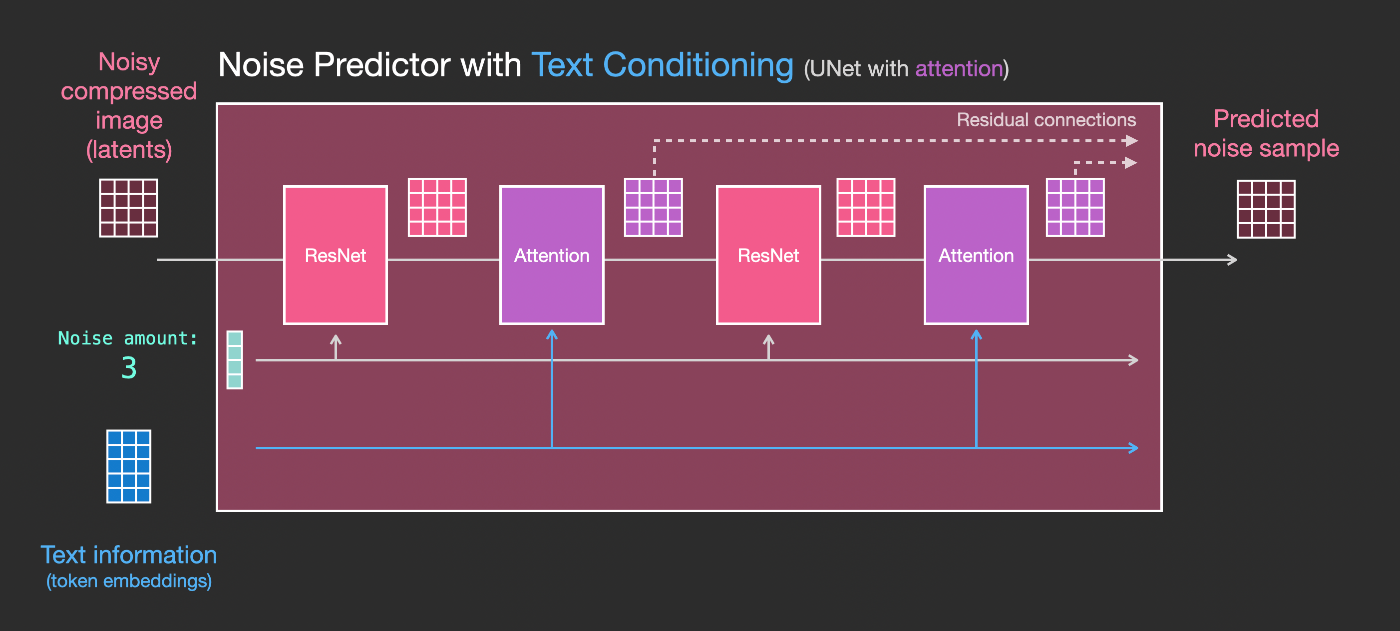
ResNetブロックが直接テキストを見るわけではないことに注意してください。しかし、Attention層はテキスト表現をlatentsに統合します。そして、次のResNetはその組み込まれたテキスト情報を処理に利用できます。
5. 結論
これがStable Diffusionの仕組みに関する良い最初の直感を与えることを願っています。他にも多くの概念が関わっていますが、上記の基本構成要素に慣れていれば理解が容易になると思います。以下のリソースは、私が役立つと感じた次のステップです。Twitterでの訂正やフィードバックについては、私に連絡してください。
6. リソース
- Dream Studio を使いStable Diffusionで画像を生成する1分間のYoutube動画
- Stable Diffusion with 🧨 Diffusers
- The Annotated Diffusion Model
- How does Stable Diffusion work? – Latent Diffusion Models EXPLAINED [Video]
- Stable Diffusion - What, Why, How? [Video]
- High-Resolution Image Synthesis with Latent Diffusion Models [The Stable Diffusion paper]
- アルゴリズムと数学についてもっと深く知りたい場合: Lilian Wengの What are Diffusion Models?
- fast.ai による Stable Diffusion に関する動画
@misc{alammar2022diffusion,
title={The Illustrated Stable Diffusion},
author={Alammar, J},
year={2022},
url={https://jalammar.github.io/illustrated-stable-diffusion/}
}
Discussion