Count.co × Python × OpenAI
This article is an English translation of the following article.
Greetings
Hello! This is Inami from Acompany.
This article is from Day 3 of Acompany's 5th Anniversary Advent Calendar.
In this article, I summarize what Count is and how to use it, as I usually use Count in my practical work.
Please read to the end because Count has become increasingly easy to use with the release that came out just as I was about to write Count as a theme for the Advent Calendar.
What is Count?
Count is a data analysis tool similar to Figma's UI, which is starting to become a hot topic.
In addition to the stylish UI, it allows you to organize requirements, prototype, query, model data, visualize, report, and document all on a single whiteboard.
You can connect directly to BigQuery, etc. and write SQL directly as well, and it would be easy to represent SQL data flow.
Although still in beta, we at Acompany use it for organizing complex pipelines, decision making, business side dashboards, demos, etc.
Personally, I feel it is also similar to a mix of no-code tools and BI tools such as retool.
Compared to other tools, I think Count's ease of writing SQL from CSV upload to charts and dashboards is Count's strength that other tools don't have.
With the 5/31/2023 release, Python is also available.
The tool is attractive even with what I have described so far, but a shocking release flew in on 5/31/2023.
It is now possible to represent Python as a cell!
The best part is that it can convert between pandas data frames and SQL on DuckDB.
I think this will allow us to process a variety of data seamlessly.
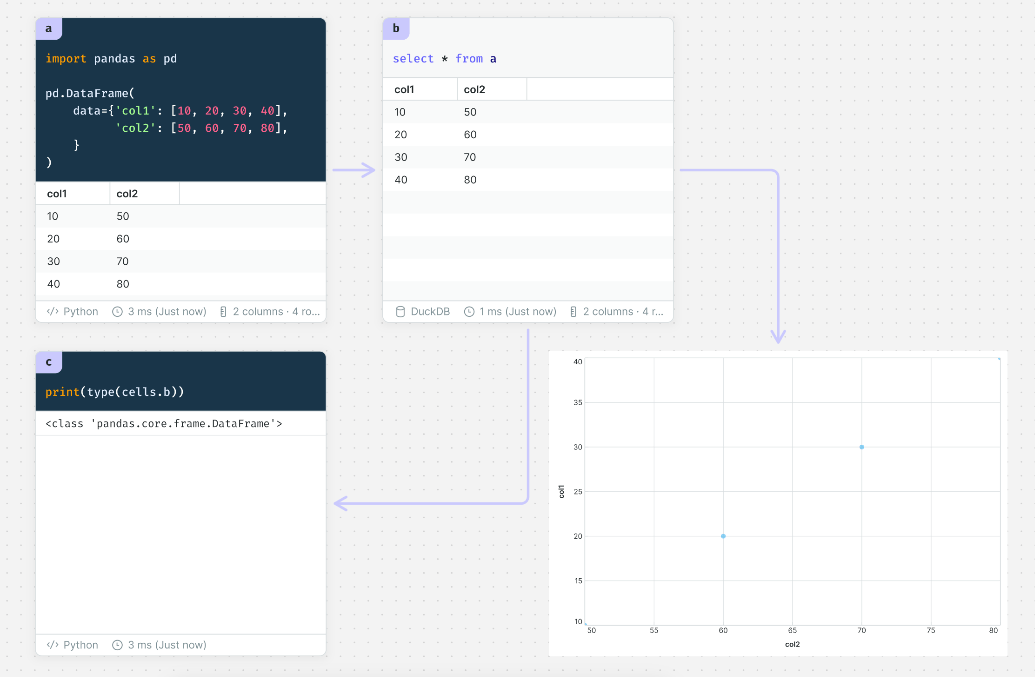
Let's use the trendy OpenAI and Count together!
I made a small tutorial on Count, which is very easy to use even at this stage and has great potential for the future.
Let's make a request to the popular OpenAI API from Count!
Canvas open to the public
If you would like to see the finished product, please click here.
OpenAI Preparation
First, let's get an API Key to make a request to OpenAI API.
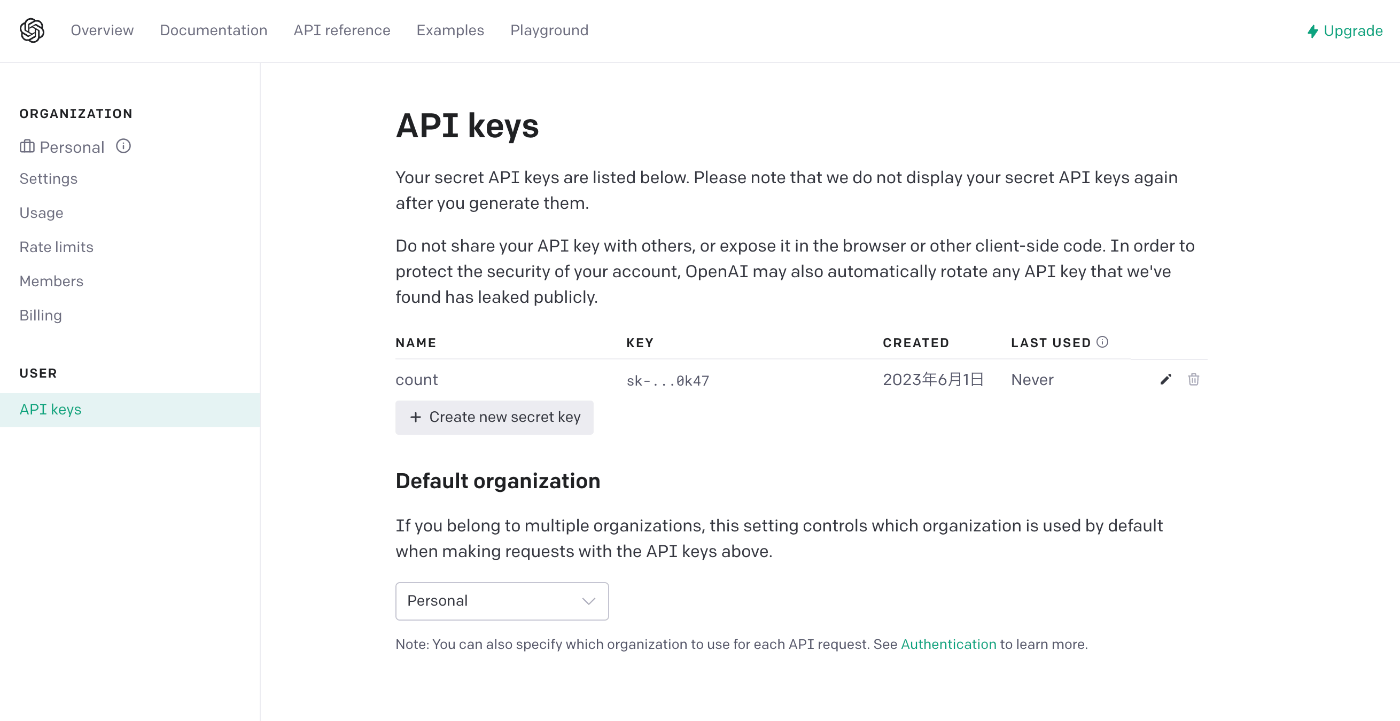
After signing up & logging in to OpenAI, click this link to go to the API Key setting page.
The API Key setting screen will appear.
If the screen is fresh, it will look almost the same as the image.
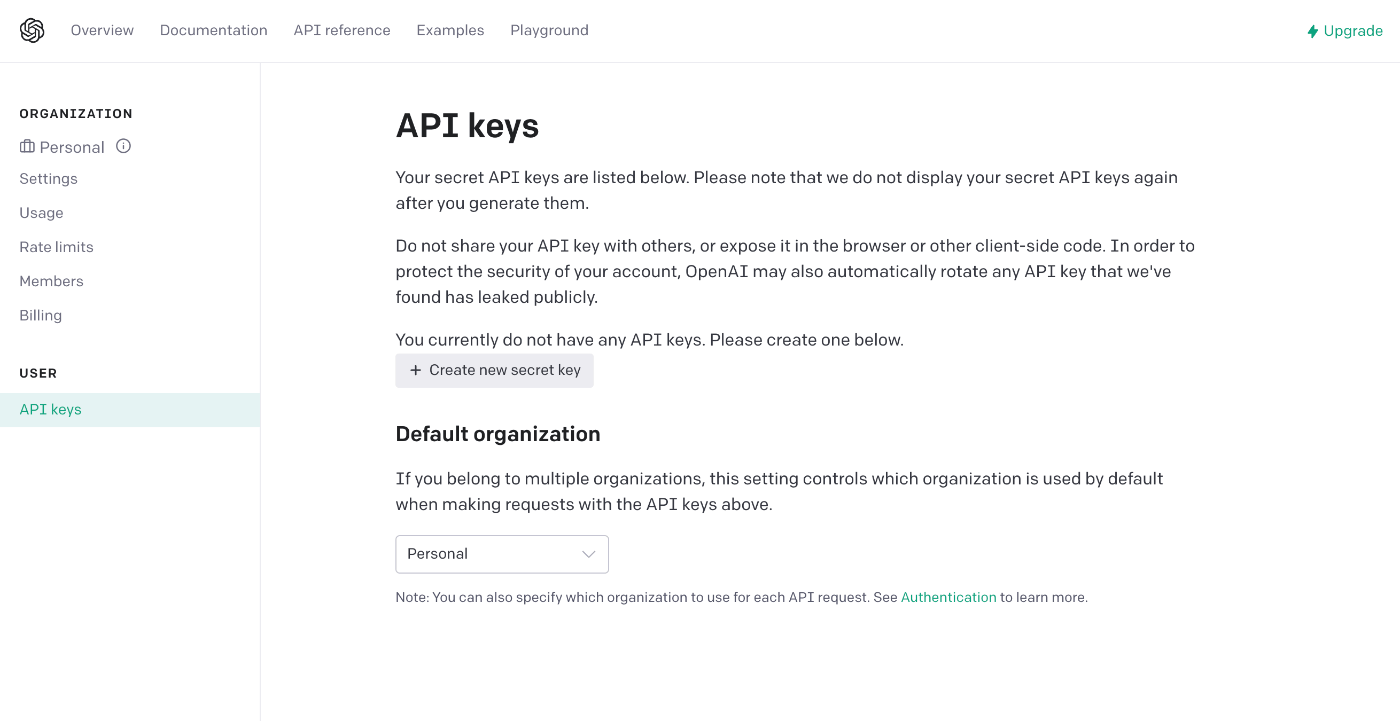
Get an API Key as soon as possible.
Click the + Create new secret key button in the center of the screen.
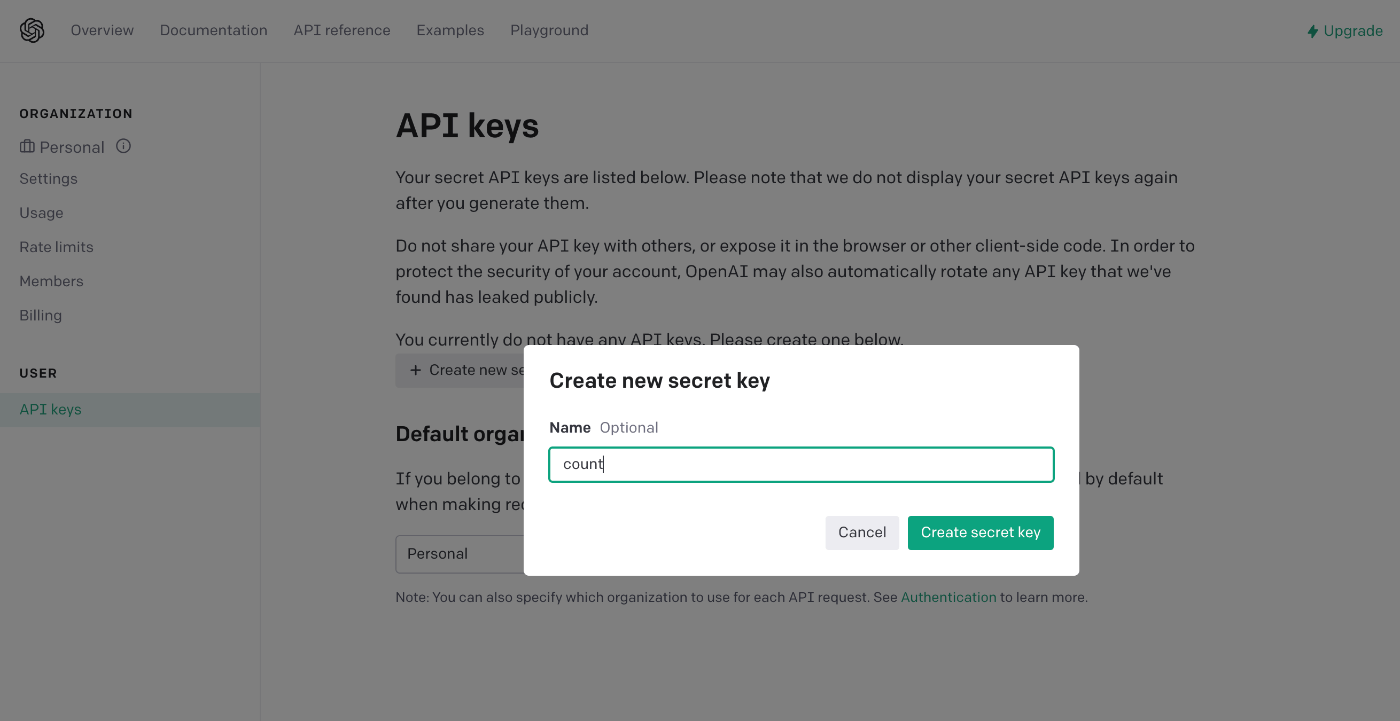
Enter the distinguished name of the API Key.
Here, enter count for simplicity.
After entering it, click the Create secret key button.

An API Key will be issued.
Make a note of this string.
When you have finished writing it down, click the Done button and you are ready to go.
Secret registration method
Next, register the API Key to Count as a secret.
Count can use a secret in order not to display secret information on the canvas.
This allows you to manipulate data on the canvas without being particularly aware of the access key.
For an explanation of the secret, please refer to the following
Prepare a project to operate on.
In this example, we prepare a new empty project.
Click on the red Manage project button.
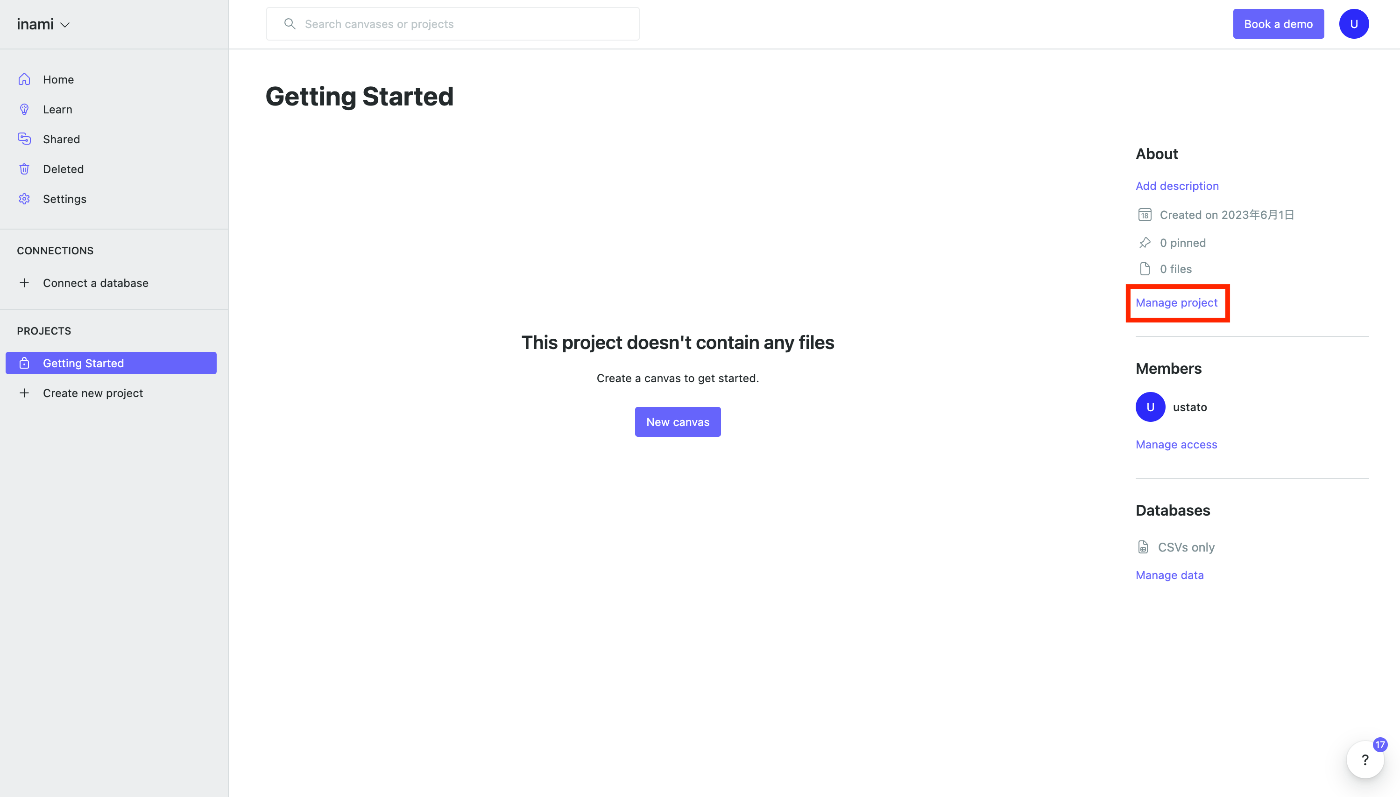
The project management screen will appear.
Next, click on Edit secrets in the red frame.
Click on the Edit secrets button in the red frame.
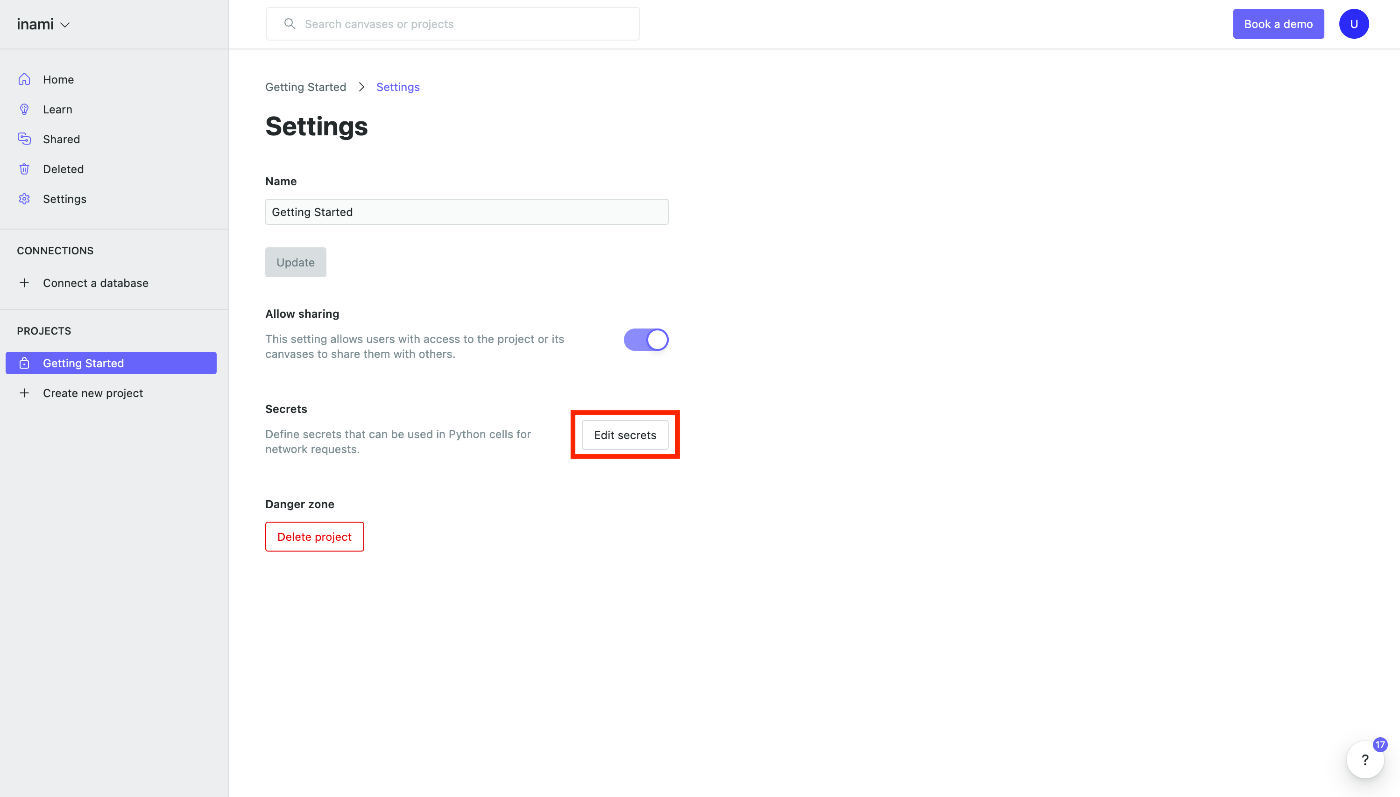
The secret registration screen will appear.
Enter the OpenAI API Key you wrote down earlier.
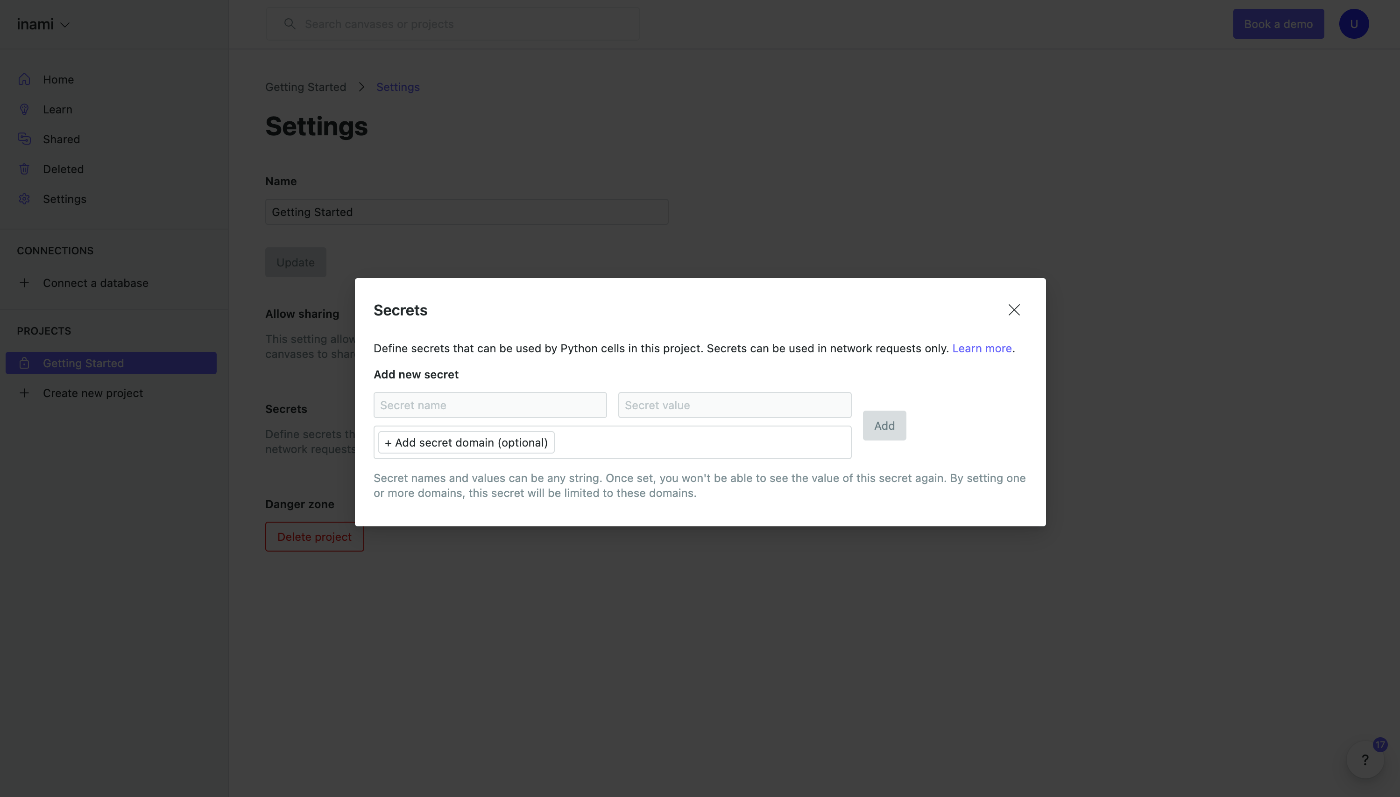
You have entered the secret's distinguished name and API Key.
Again, enter openai-api-key for clarity.
After entering, click the Add button.
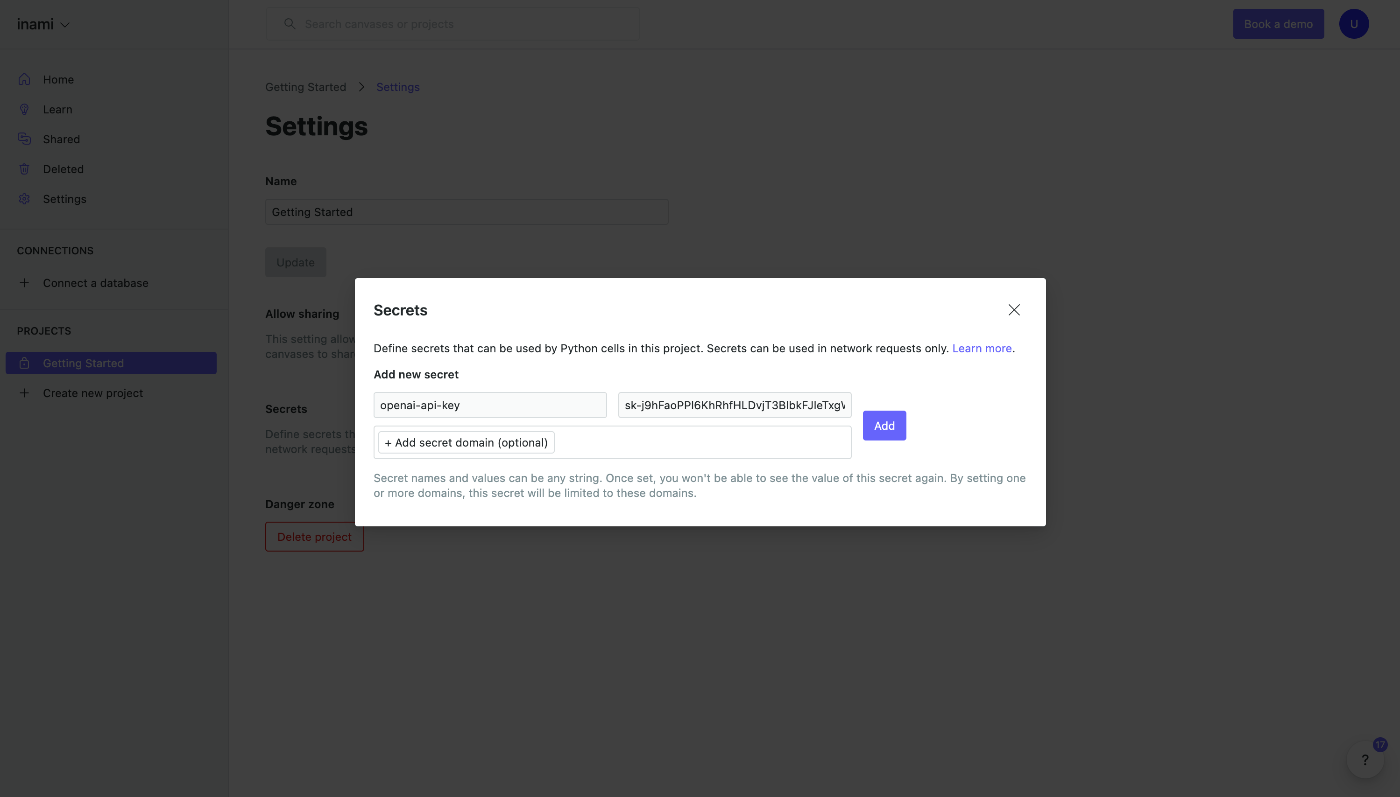
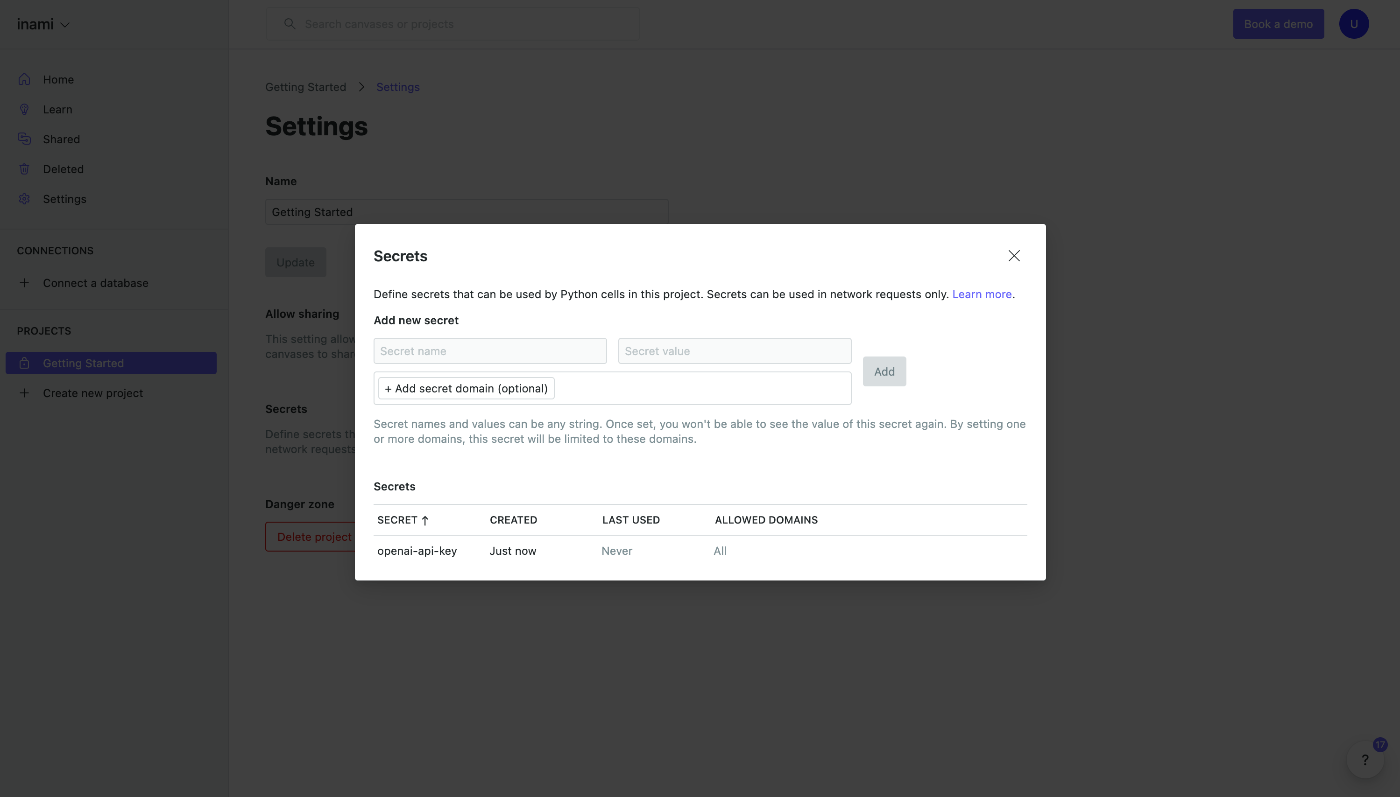
The secret has been registered.
You can add more restrictions to the secret itself, but this is not really relevant in this case, so let's continue on.
Canvas creation
Let's create a canvas to send POST requests to the OpenAI API.
Click the New canvas button.
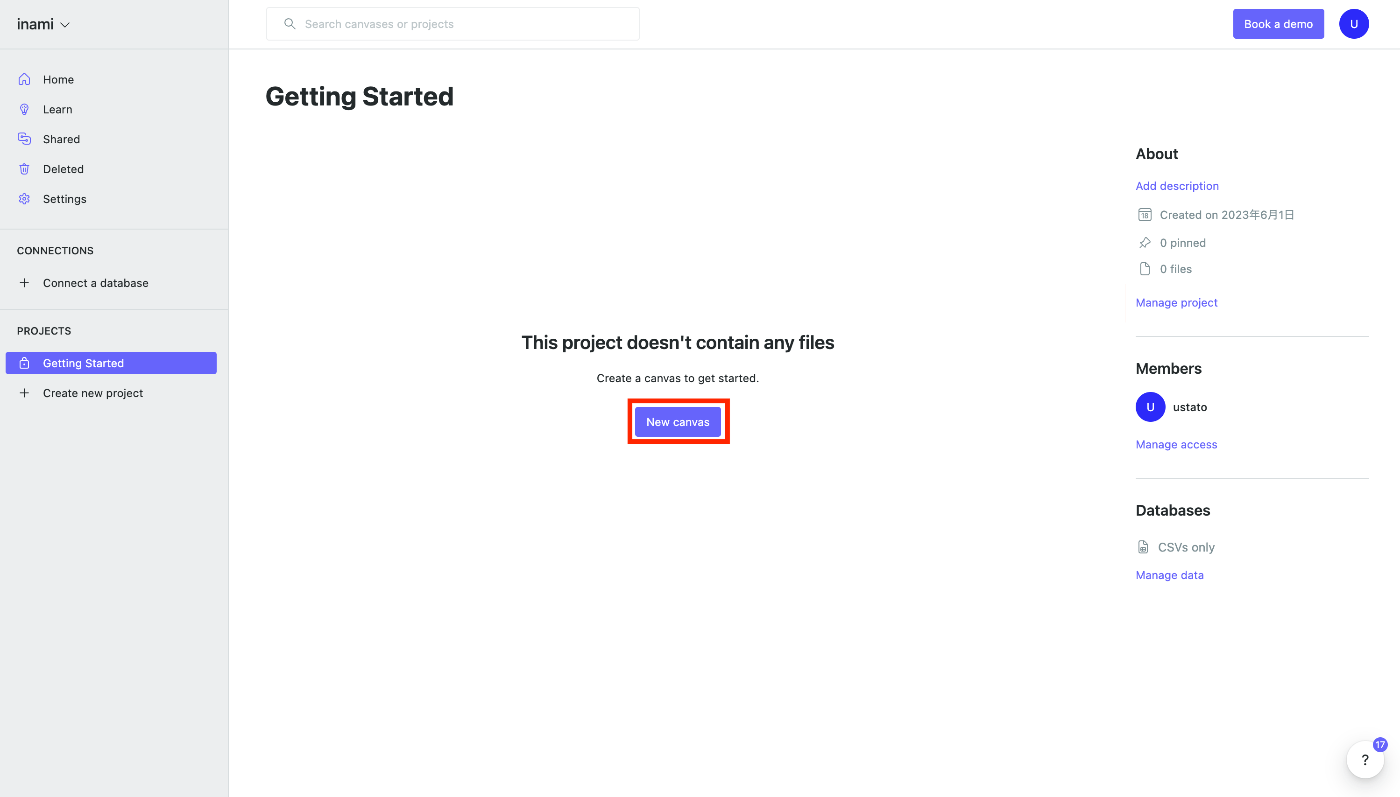
An empty canvas will appear.
Select Python Cell from the icons below.
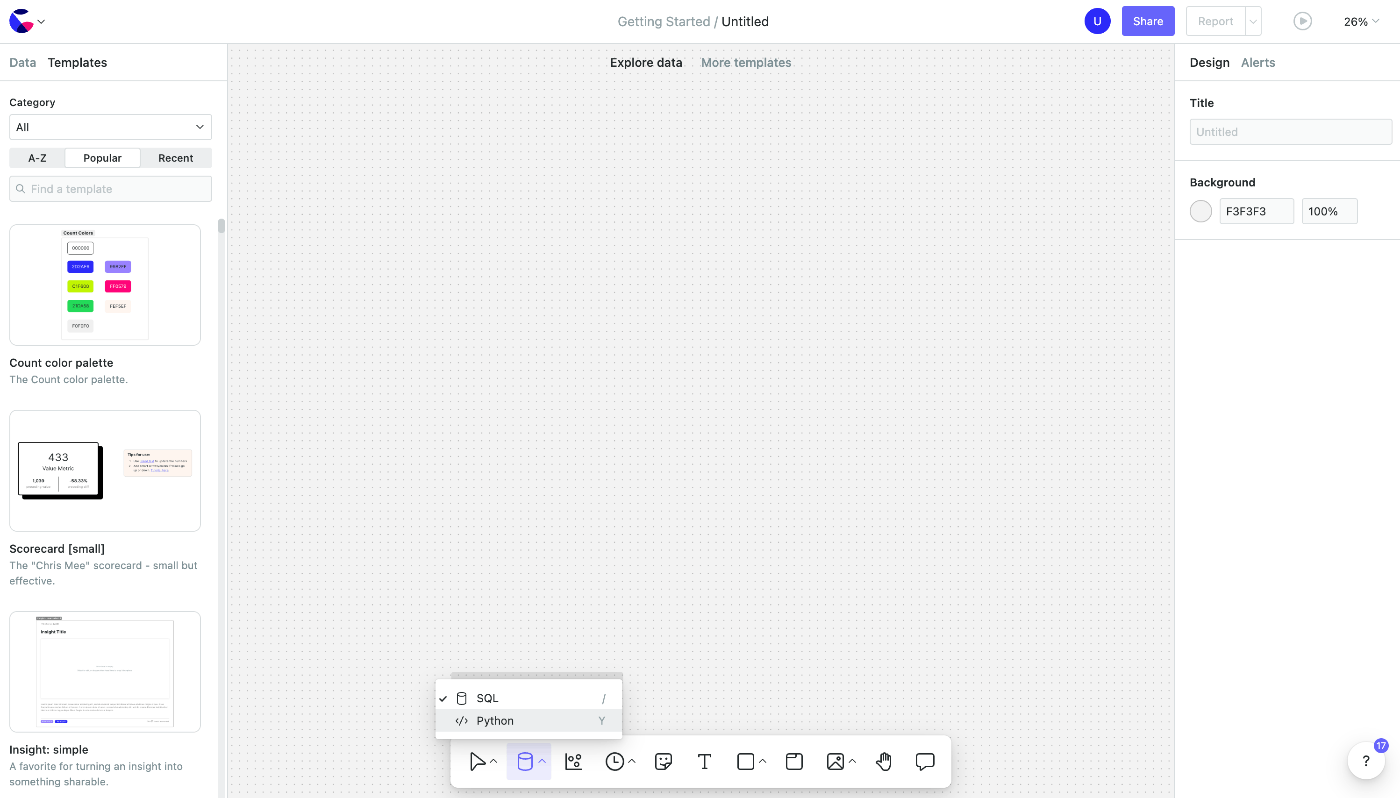
The Python Cell will appear.
Let's try Hello, world for starters.
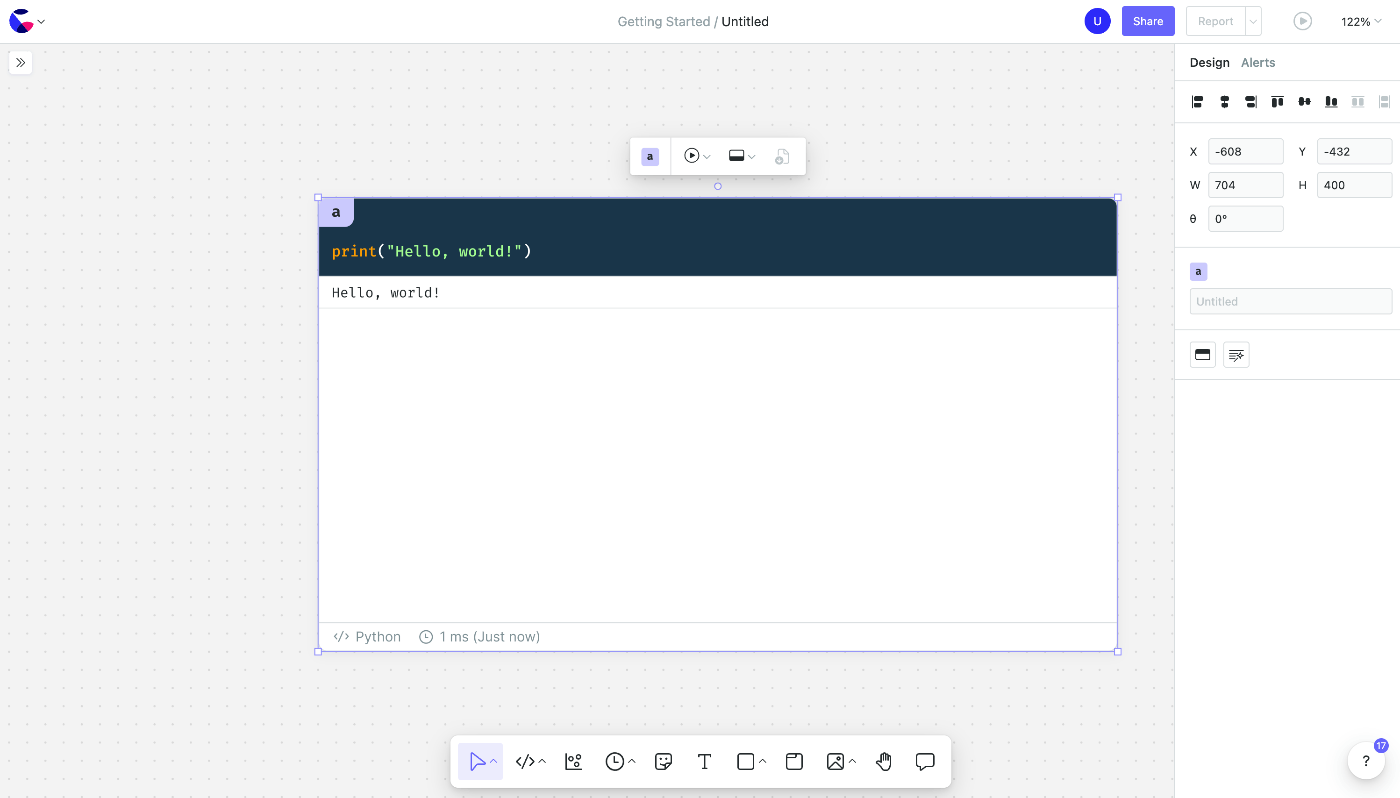
It works.
Now all we have to do is send a request.
Let's make it by referring to the example in the API reference.
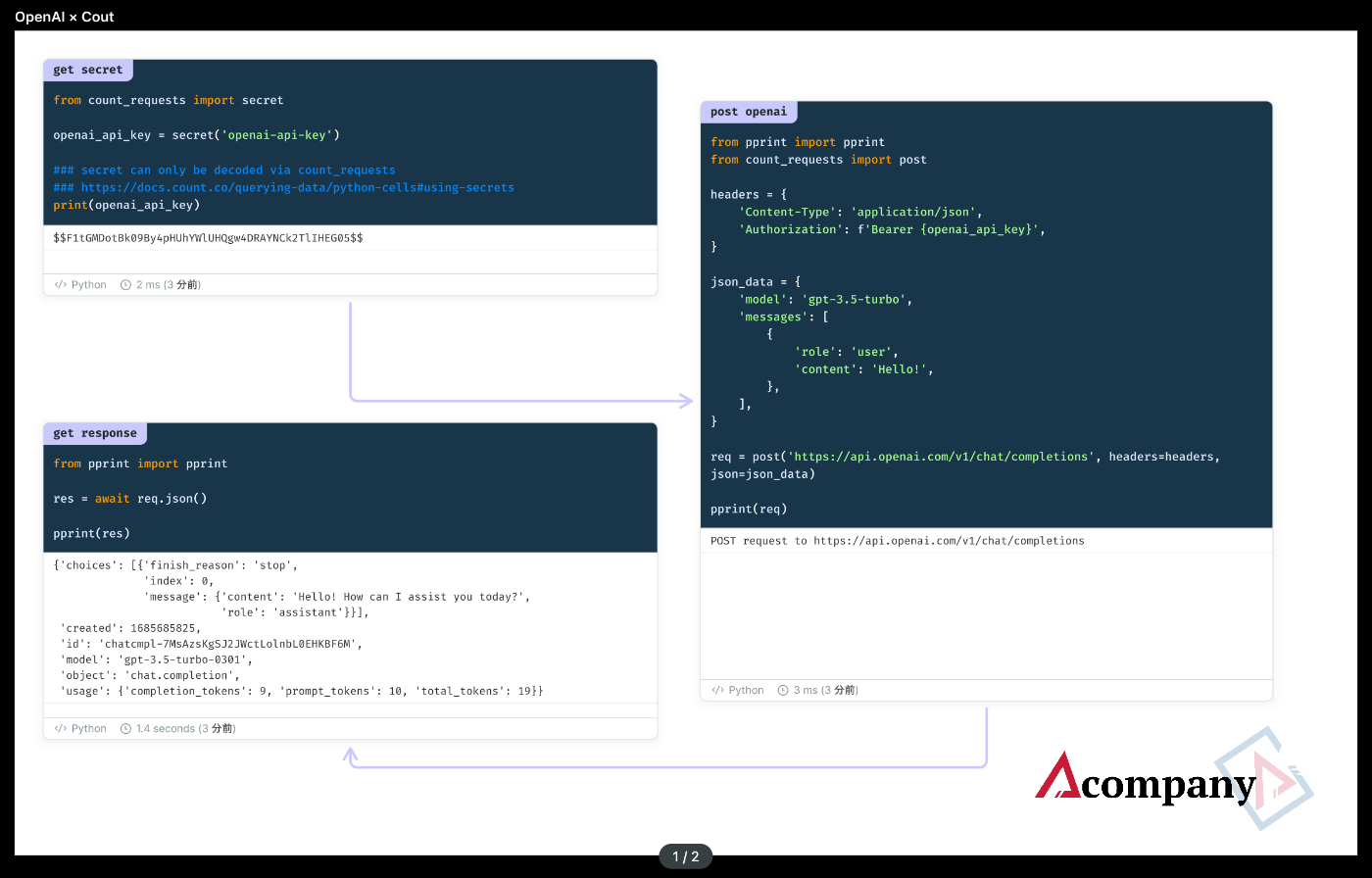
With a little ingenuity, you can create a group of cells like the one in the image.
First, the top left cell is loaded with a secret.
However, it seems that the secret cannot be printed normally and is only expanded on Count's HTTP library.
I actually tried to print the secret, but it displayed a meaningless string.
It looks like base64, but it remained meaningless even after removing the $ mark and decoding.
Next, I pass a variable with a secret from the top left cell to the cell on the right.
Count makes it easy to read the value of another cell.
Using the variable with the secret, we send a POST request from Count's HTTP library to OpenAI.
Finally, the response is awaited, and the results are displayed.
You can receive the results from OpenAI in JSON format.
Python cells notes.
openai's Python package is not available in Count as of 6/1/2023
The official Python package is not available as of 6/1/2023.
In this article, I have responded by posting directly to the API as an alternative.
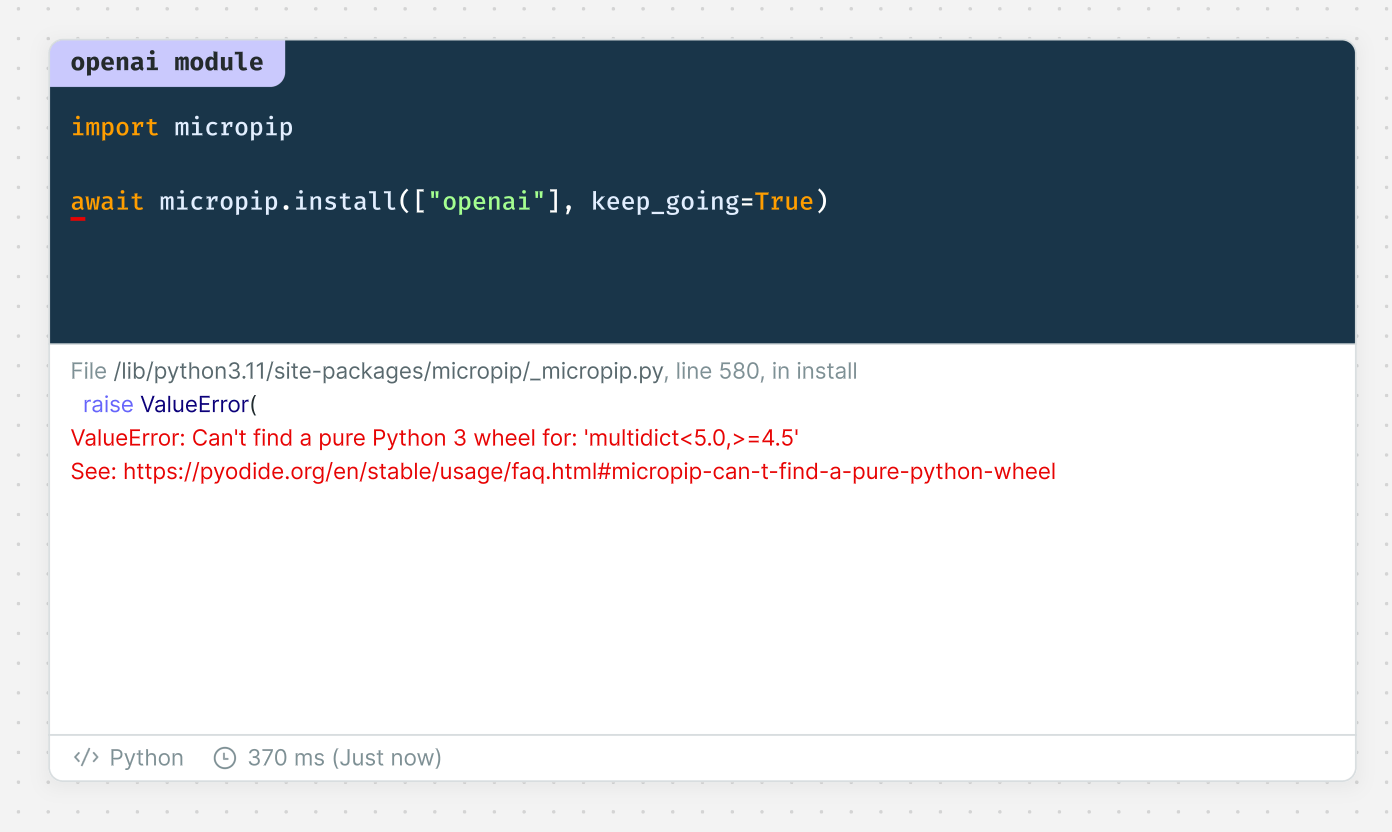
I checked and found that both Pyodide and OpenAI have issues up.
Only packages with resolved dependencies are available.
The cause of the issue is that the Python packages in openai's Python package is not available in Count as of 6/1/2023. Count is not available.
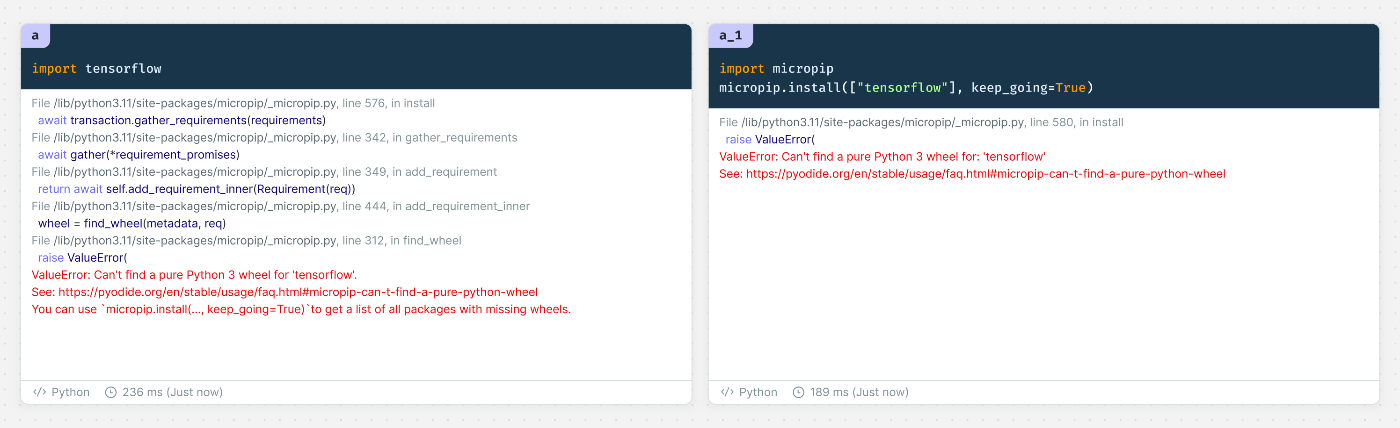
If various package-specific dependencies are not resolved, it seems that installation is also not possible.
I tried to install TensorFlow, but it failed.
The following is a list of packages whose dependencies have been resolved by Pyodide officials and are now available.
LightGBM and XGBoost also seem to be available.
Possibly import <package> to pip install
It seems to be possible to import and load packages that would not be installed in Python cells.
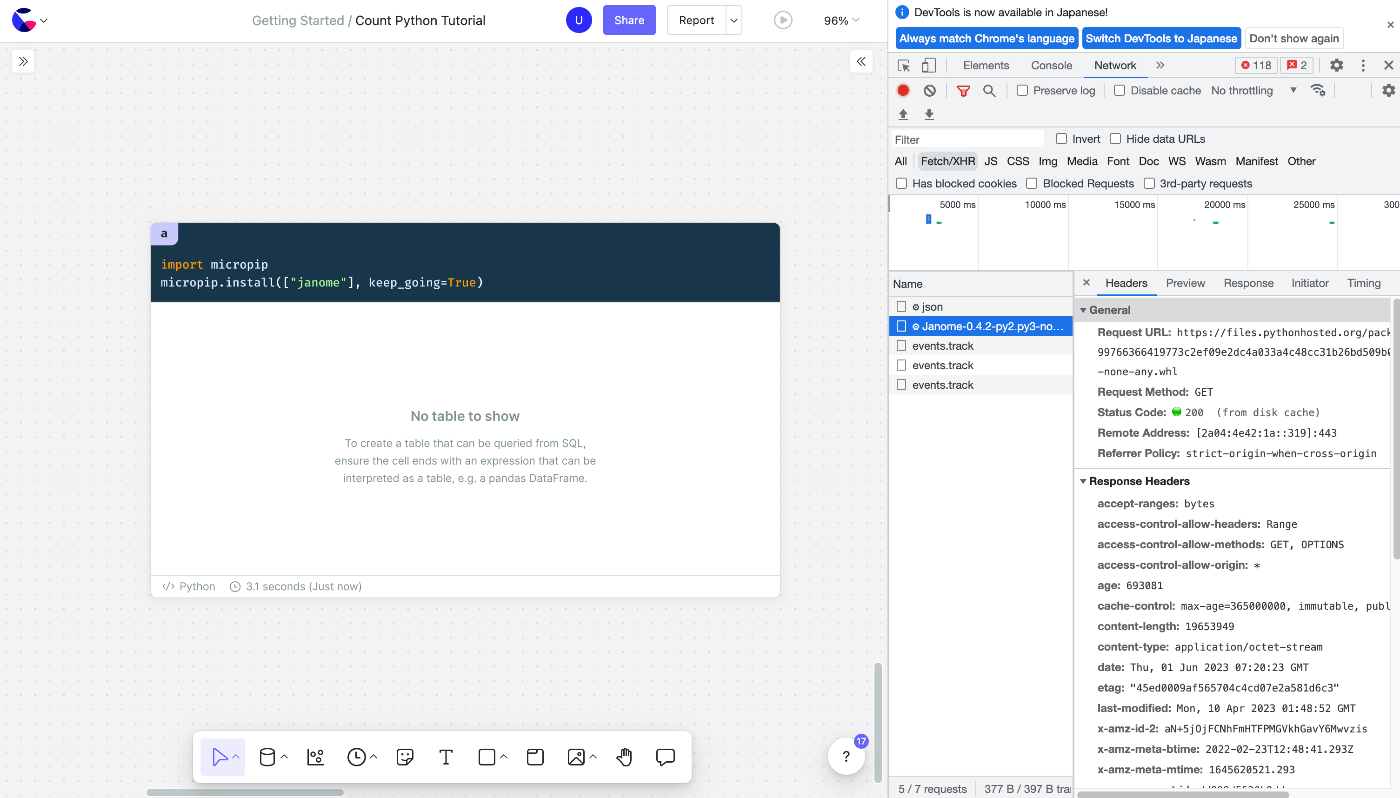
An example is janome, a morphological analyzer, which I have the impression is basically used in Japan.
Therefore, we think it is unlikely to be installed in Count from the beginning.
However, when I actually try to import it, it seems to be usable without any problem.
I was looking for something being fetched by Chrome's developer tools because Pyodide is a wasm, and it seems to be pulling whl files from PyPI when importing.
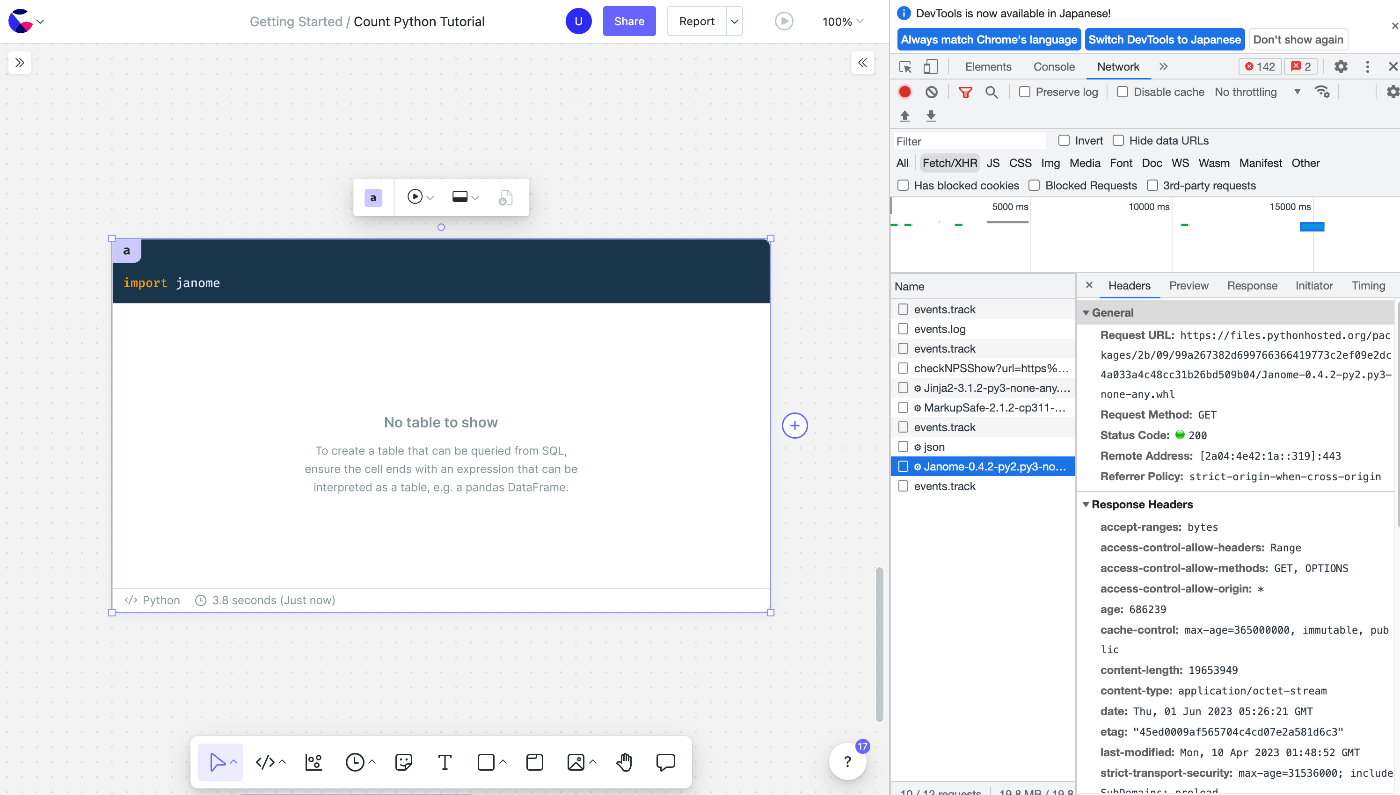
It's just a hypothesis, but I'm thinking that when import occurs, it's installing directly.
I can read that if I do a micropip.install() when I should refresh the page and re-install, it does the same thing.
Future Prospects
Speeding up the PoC cycle
As a practical use case for Count, we feel that it can handle PoC for data infrastructure and data pipelines in a fast cycle.
When creating a data infrastructure or data pipeline, if you implement it out of the blue, you may end up in a situation where the final output is not clear.
In order to avoid such a situation, we may process the data at hand and reconcile it once, but if it is in Count, it may be used as a report or dashboard as it is after processing and reconciliation.
In other scenarios, you can use Count to roughly solidify an image of the data pipeline, and then use a workflow orchestration tool such as Airflow or Dagster to implement it.
I have actually used this procedure for a PoC on a data pipeline, and I find it quite comfortable to use.
I feel that it is also useful to have a common understanding at the implementation level, so it is useful to have a common understanding with business partners.
ChatGPT x SQL
Since ChatGPT is now available in Count and the results can be further processed, it is likely that we will be able to receive implementations in SQL format from ChatGPT in the future.
If this happens, it seems possible to build a semi-automatic SQL-based pipeline on Count!
As a shared tool for data processing
Until now, there have been situations where data engineers, AI engineers, data scientists, etc. have reported using the tools they each want to use.
- Data Engineer
- SQL
- Workflow orchestration
- AI Engineer (typical)
- Data Scientist
- R language
- Python
- BI tools
These personnel may have Python in common, but they do not often work together.
In order to produce refined and consistent figures without aggregating individual reports, it is necessary to share logic with each other.
Although there are still some parts that are not ideal, Count is able to handle most of the elements listed at this point, and it may become possible to link the logic of each other's work.
I felt that by using Count as a sharing tool for members of various professions, we can get closer to our business goals in the shortest possible time!
Discussion