Git が内部でデータを取り扱う方法
Git が内部でデータをどう取り扱っているかの解説記事が GitHub 社のブログで連載されていた。
ソフトウェア開発において Git が分散データベースとしてどのように機能するか、という一貫した主題に沿って様々な角度からその仕組みを全5回で説明している。
-
Part1: packed object store
- リポジトリのバージョン管理に必要なデータをどのように保存しているのか
- 保存したデータをどうやって取り出しているのか
-
Part2: commit history queries
- commit はどのようなデータ構造を持っているか
- commit 履歴の探索をどうやって高速化しているのか
-
Part3: file history queries
- あるファイルが変更されていることをどのように把握するのか
- ファイルの変更履歴をどうやって効率的に探索しているのか
-
Part4: distributed synchronization
- ローカルとリモートの間でリポジトリをどのように同期しているのか
- それぞれの commit 集合の差分を効率的に計算するにはどのような方法があるのか
-
Part5: scalability
- 巨大なリポジトリを Git で効率的に管理するにはどのような方法があるのか
本記事では以下に上記連載を読みながら書いたメモと自分が調べたことをまとめておく。文中の画像は全て上記 GitHub 社連載記事からの引用。
Part1: packed object store
第一回は Git object の概念と packfile について。
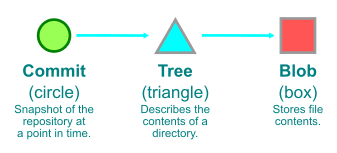
Git は全てを object として保存する
Git はデータを永続化するために短時間で終了するプロセスとファイルシステムを利用している。その実態はファイルの内容によってそのアドレスが決まる(content-addressable)ファイルシステムであり、その上にバージョン管理システムとしてのインターフェイスが実装されている。
Git がバージョン管理のために保存するデータは Git object と呼ばれ、リポジトリの .git/objects に保存される。Git object が欲しくなったときは、その内容から計算した SHA-1 ハッシュを使って取得する。つまり、ハッシュがデータベースのテーブルにおける primary key のように働く。
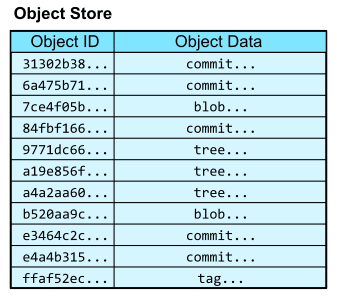
しかし、このハッシュは普通の人間には覚えられない。そこで、そのハッシュを示す参照を表す object に人間が読みやすい名前をつけた上で、その参照 object のハッシュとあわせて .git/refs ディレクトリに保存しておく。ここでは参照名が primary key となる。
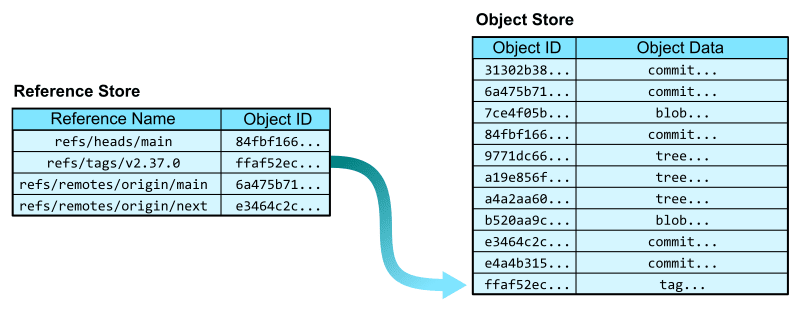
これで ffaf52ec... のようなハッシュではなく refs/tags/v2.37.0 のような人間が読みやすい名前を使って object にたどり着けるようになった。これは Git において annotated tag と呼ばれる概念で、特定の commit object を参照している。なお tag と同様に branch も commit への参照である。
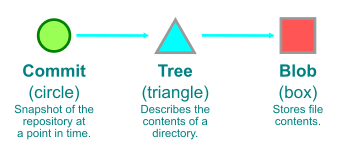
commit とは特定時点におけるリポジトリの work tree のスナップショットであり、以下の情報を含んでいる。
- 親となる commit のハッシュ
- commit のスナップショットに対応する root tree のハッシュ
- commit 時刻や author やメッセージなどのメタデータ
root tree のハッシュがあれば、その配下にある tree や blob を取得することができる。以降 Git object を示すハッシュを id または object id と呼ぶことにする。
Git を使って Git のリポジトリを探索する
Git が object をどのように保存しているかを確かめるために GitHub の git/git にある Git のリポジトリを clone してくる。
$ git clone git@github.com:git/git.git
v2.37.0 の tag が打たれた時点の README.md の内容を取得するために Git object へのリンクを辿ってみる。
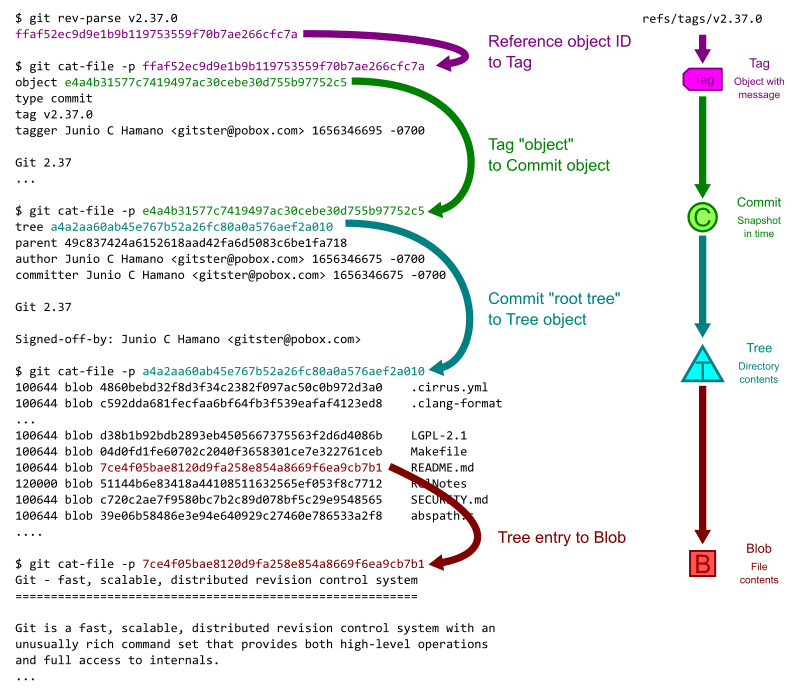
まずは git rev-parse コマンドの引数に tag の名前を渡すことで object id を取得する。今回は tag を使うが branch でも可。rev は revision の略で rev-parse コマンドは引数の参照名を解析して object id を出力する。
$ git rev-parse v2.37.0
ffaf52ec9d9e1b9b119753559f70b7ae266cfc7a
結果として得た id ffaf52... を git cat-file コマンドで調べると tag object であることが確認できる。これは当然 v2.37.0 の tag を示す。
$ git cat-file -t ffaf52ec9d9e1b9b119753559f70b7ae266cfc7a
tag
この id を cat-file に渡すことで、tag が参照する先の commit が分かる。
$ git cat-file -p ffaf52ec9d9e1b9b119753559f70b7ae266cfc7a
object e4a4b31577c7419497ac30cebe30d755b97752c5
type commit
tag v2.37.0
tagger Junio C Hamano <gitster@pobox.com> 1656346695 -0700
Git 2.37
-----BEGIN PGP SIGNATURE-----
...(省略)
-----END PGP SIGNATURE-----
これで v2.37.0 の tag が指し示す commit の id である e4a4b3... を取得することができた。
次に e4a4b3... を cat-file してみると、その commit の詳細な内容を取得できる。
$ git cat-file -p e4a4b31577c7419497ac30cebe30d755b97752c5
tree a4a2aa60ab45e767b52a26fc80a0a576aef2a010
parent 49c837424a6152618aad42fa6d5083c6be1fa718
author Junio C Hamano <gitster@pobox.com> 1656346675 -0700
committer Junio C Hamano <gitster@pobox.com> 1656346675 -0700
Git 2.37
Signed-off-by: Junio C Hamano <gitster@pobox.com>
さて、前述の通り commit は以下の情報を含んでいる。
- 親 commit の id
- スナップショットに対応する root tree
- commit 時刻や author などのメタデータ
次は root tree を取得するために tree を示す id a4a2aa... を cat-file してみる。
$ git cat-file -p a4a2aa60ab45e767b52a26fc80a0a576aef2a010
100644 blob 4860bebd32f8d3f34c2382f097ac50c0b972d3a0 .cirrus.yml
100644 blob c592dda681fecfaa6bf64fb3f539eafaf4123ed8 .clang-format
100644 blob f9d819623d832113014dd5d5366e8ee44ac9666a .editorconfig
100644 blob b0044cf272fec9b987e99c600d6a95bc357261c3 .gitattributes
040000 tree cc4b96c0e88525496147ba18b8d25cbbdc9859c5 .github
100644 blob a45221576418e77de53f2776912ad62cce00c85b .gitignore
100644 blob cbeebdab7a5e2c6afec338c3534930f569c90f63 .gitmodules
100644 blob 07db36a9bb949c4c911d07baeb1c4c10c13bec4c .mailmap
100644 blob 5ba86d68459e61f87dae1332c7f2402860b4280c .tsan-suppressions
100644 blob 0215b1fd4c05e668f37973549384aae24dcc65cf CODE_OF_CONDUCT.md
100644 blob 536e55524db72bd2acf175208aef4f3dfc148d42 COPYING
040000 tree 31302b38c02d2bc08af02a9bdc6e7c7b6846370c Documentation
100755 blob b210b306b7554f28dc687d1c503517d2a5f87082 GIT-VERSION-GEN
100644 blob 4140a3f5c8b6946ca821c2a876cd4390a1a05f1b INSTALL
100644 blob d38b1b92bdb2893eb4505667375563f2d6d4086b LGPL-2.1
100644 blob 04d0fd1fe60702c2040f3658301ce7e322761ceb Makefile
100644 blob 7ce4f05bae8120d9fa258e854a8669f6ea9cb7b1 README.md
...(以下省略)
root tree が示すのは root ディレクトリ直下に含まれる object である。tree object はディレクトリに似ており、その配下に tree(ディレクトリ)や blob(ファイル)を持つ。
上記の出力を見ると最後の行に
100644 blob 7ce4f05bae8120d9fa258e854a8669f6ea9cb7b1 README.md
とあるが、 100644 blob が object の種類、 7ce4f0... が object id、 README.md が object のファイル名を指している。100755 の blob もあるが、これは実行可能ファイルであることを意味している。シンボリックリンクなら 120000 になる(参考)。
最後に README.md の blob object を示す 7ce4f0... を cat-file してみる。
$ git cat-file -p 7ce4f05bae8120d9fa258e854a8669f6ea9cb7b1
[](https://github.com/git/git/actions?query=branch%3Amaster+event%3Apush)
Git - fast, scalable, distributed revision control system
=========================================================
Git is a fast, scalable, distributed revision control system with an
unusually rich command set that provides both high-level operations
and full access to internals.
...(以下省略)
これでようやく Git の tag v2.37.0 時点の README.md を読むことができた。
なお、 blob は "b"inary "l"arge "ob"ject の略で、その名の通り binary なので人間には読むことはできず cat-file 等を通じて読むことができる。
上記の通り、「この tag の時点での README.md をくれ」という非常に単純な要求でも、Git object id を飛び回る必要がある。これを効率化する手法は第二回 ~ 第四回で扱う。
git add や git commit は何をしているのか
add や commit など Git ユーザーが使うコマンドは、実際には複数の動作で構成されている。
Git コマンドは配管(Plumbing)と磁器(Porcelain)の2種類があり、ユーザーフレンドリーな「磁器」コマンドと、UNIX 流に繋ぎ合わせることを目的に設計された単純な処理を行う「配管」コマンドに分かれている。Git の挙動を理解するには「配管」コマンドを使ってみるのが良い。
まずは配管コマンドの一つである git hash-object を使って直接 blob に書き込んでみる。このコマンドは書き込まれた blob object の id を返す。
$ git hash-object -w --stdin
Hello, world!
af5626b4a114abcb82d63db7c8082c3c4756e51b
cat-file に object の id を渡すと blob であること、内容が書き込まれていることが分かる。
$ git cat-file -t af5626b4a114abcb82d63db7c8082c3c4756e51b
blob
$ git cat-file -p af5626b4a114abcb82d63db7c8082c3c4756e51b
Hello, world!
さて、この blob が実際にどこにあるかというと .git/objects/ に af/ というディレクトリが追加されていて、そこに格納されている 5626b4a114abcb82d63db7c8082c3c4756e51b というファイルに書き込まれている。
ここで Git が管理しているファイルの正体が見えてきた。要するに Git がやっていることを単純化すると、管理対象のリポジトリを構成するディレクトリやファイルをハッシュして Git object とそれを示す id を生成し、必要に応じてその id を使い object を探している。
ただし上記の hash-object コマンドで生成した Git object はただ存在しているだけで、これを参照する tag や branch が無いため実用的ではない。
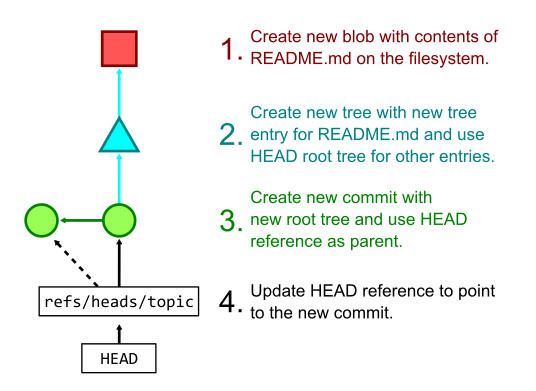
一般的にリポジトリに新たな変更が生じたときは git add コマンドで Git の管理対象に追加するが、これは内部で以下の操作を行っている。
- work tree 内の新しい変更をハッシュし、それを Git object として格納する
- 変更された Git object のリストを Git index(次に commit される対象)に staging する
その後 git commit することにより、以下の操作が行われる。
- Git index を受け取り、全ての新しい blob を示す tree を作成する
- 新しい tree を指す commit object を作成する
- 現在の branch を更新し、新たな commit を指し示すようにする
例えば README.md のみを編集して git commit -a -m "Update README.md を実行した場合、次のような順序で処理される。
ここまで見てきた通り Git が管理対象のデータを object として格納するとして、以下のような疑問が生じる。
- commit がスナップショットならば、新しい commit の度にリポジトリの大きさだけファイルをハッシュする必要があるのでは?
- そうだとしたら、ファイルシステムの限界をすぐに超えてしまうのでは?
Git は packfile と呼ばれる仕組みでこれを解決している。
packfile ... の前に loose object について
自分が作業している適当な git リポジトリで .git/objects ディレクトリを見ると、16進数で2桁の名前のディレクトリがあり、そこに38桁の名前のファイルが格納されていることが分かる。
$ ls -R .git/objects
03 08 0e 35 4b 6a 74 8a 9a aa b4 d4 e8 fb pack
04 0b 13 43 5d 6c 76 95 9d b1 c8 de e9 fd
06 0c 2d 45 66 71 7b 96 a9 b3 c9 e6 ef info
.git/objects/03:
87b4452f0fa95c042a92364ed99b95fcd3f87d
...(以下省略)
これらは loose objects と呼ばれ、Git を使って作業をしているとこれが積み重なっていく。その実態は後述の packfile に含まれない Git object である。
ディレクトリ名2桁 03 とファイル名38桁 87b4452f0fa95c042a92364ed99b95fcd3f87d を繋げて40桁にすることで Git object の id となる。試しに cat-file で Git object の中身を見てみる。
$ git cat-file -t 0387b4452f0fa95c042a92364ed99b95fcd3f87d
tree
$ git cat-file -p 0387b4452f0fa95c042a92364ed99b95fcd3f87d
100644 blob 35fe178ae0d932de85c3df7e7278a3a459096e58 index.ts
...(以下省略)
と tree であることが分かった。
上記は自分のローカル環境なので、皆さんも自分の環境で試してみてください。
packfile の概要
さて、loose objects として全ての Git object を格納することも不可能ではないが、ファイルが増えれば増えるほどファイルシステム全体に負担がかかるし、同じテキストファイルの多くのバージョンをスナップショットとして保存するのも非効率的と言える。
そこで Git では ./git/objects/pack ディレクトリに Git object を zlib で圧縮して格納するためのファイル *.pack とそのインデックス *.idx を作ることで、より効率的にファイルの保存とデータの取り出しを実現している。
*.pack は正確には Git object の連結リストを保存していて object の id は含んでいない。これだけで特定の id と対応する Git object を見つけることも技術的に不可能ではないが、
-
*.packを解凍し - 各 object を SHA-1 ハッシュし
- 特定の id と比較する
という手順を踏む必要があって面倒である。ここで重要な役割を果たすのがインデックス *.idx で、ここには辞書順に object id が保存されている。*.pack と *.idx はそれぞれ複数存在する場合があるが、 * の部分が同じ文字列であれば対になっていることを意味している。
さて、*.idx には辞書順で id が保存されているのだから、ある特定の id は binary search によって簡単かつ効率的に見つけ出すことができる。
*.idx では id と *.pack 内でその id が示す object が始まる場所を指し示すオフセット値を保存している。つまり object id が分かれば *.pack から簡単に object を取り出すことができる。
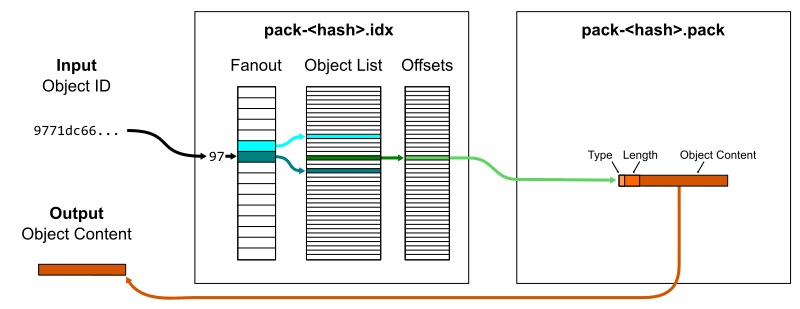
このとき256行(16進数2桁)のキーとそれに対応するハッシュの境界を持つ fanout テーブルを使って binary search を効率化している。
例えば 9771dc... という id がどこにあるか探すには fanout テーブルに保存されている 96 の終わりと 97 の終わりの境界の間を探せばよい。全ての object id はその内容の SHA-1 ハッシュであるから、全く同じ内容のファイルが並んでない限りは fanout テーブルのキーは一様に分散すると期待できる。つまり fanout テーブルで絞り込んだ後に検索対象となる object は、元々の総数の 1/256 に近づくと考えられる。
packfile のファイル形式
ここまでで、特定の object id が *.pack 内のどこから出現するかのオフセットを効率的に入手する方法が分かった。
次に *.pack の中身について見ていく。Git が保存する目的であるソースコードは、典型的には「多数のバージョンが存在し、それぞれ共通する部分を多く持つテキストファイル」であり、変更箇所の分量に応じた差分を取ることができる。
packfile のフォーマットは以下のようになっている(参考: packfile のフォーマット)。
- ヘッダー
- 4 byte の signature: 内容は
'P','A','C','K'で、 packfile の開始位置を正しく示すために存在する - 4 byte の version number: 2 か 3
- 4 byte の ファイル数
- 4 byte の signature: 内容は
- Git object
- n byte の type (6種類) と length
-
base object 名もしくは packfile 内の delta object の位置からの相対オフセット
- base object とは、それ自体で完全な object を再現できるもの
- delta object とは、base object からその delta までの連続した差分の和として完全な object を再現できるもの
- 圧縮された Git object の中身
Git object の type には以下の6種類がある(括弧内は type を示す数字で、5は将来のために予約されている)。
- OBJ_COMMIT (1)
- OBJ_TREE (2)
- OBJ_BLOB (3)
- OBJ_TAG (4)
- OBJ_OFS_DELTA (6)
- OBJ_REF_DELTA (7)
Git object は本来 (1) ~ (4) の4種類だが、ファイルの格納スペースを節約するために「base object の delta」として格納されることがある。(6) と (7) はそのための type で、 OBJ_OFS_DELTA は base object に適用される delta 自体(もしくは、同じ packfile 内に base object がある場合はオフセット)を格納し、 OBJ_REFS_DELTA は base object の名前をエンコードして格納する。
packfile の圧縮効果
さて、 Git ではこの packfile を使ってどの程度 object を圧縮できるのだろうか。
v2.37.0 に戻り、どのように pack されるのかを確認する。このタグが指すコミット e4a4b3 では、GIT-VERSION-GEN だけが変更された。
変更前の blob object の id は 120af3 であり変更後の id は b210b3 である。このとき、 base となる tree から新しい tree を作るには 120af3 の前までを COPY し、 b210b3 の id を書き込み、そこから先はまた同じなので COPY すればよい。
つまり、実際に新たに保存する必要があるのは下記画像の緑色の部分 b210b3 のみである。
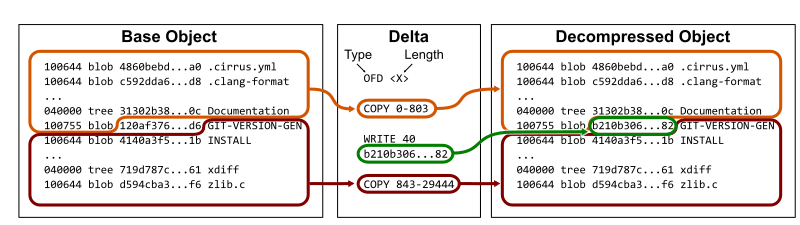
(ここから先は元記事の結果を再現できなかったので v2.37.1 の root tree で検証してみる)
cat-file でファイルサイズを調べると v2.37.1 の root tree は約 19KB だが、delta はたったの 183B であり百分の一未満となっていることが分かる。
$ git rev-parse v2.37.1^{tree}
430fb9dda5d208ab2621c723a6711f9122f8b25e
$ git cat-file -s v2.37.1^{tree}
19388
$ git rev-parse v2.37.1^{tree} | git cat-file --batch-check="%(objectsize:disk)"
183
OBJ_OFS_DELTA は同じく OBJ_OFS_DELTA である別の object につなげることができ、これは delta chain と呼ばれる。この delta chain を base object まで辿って連結することで、その時点の完全な object を再現できる。
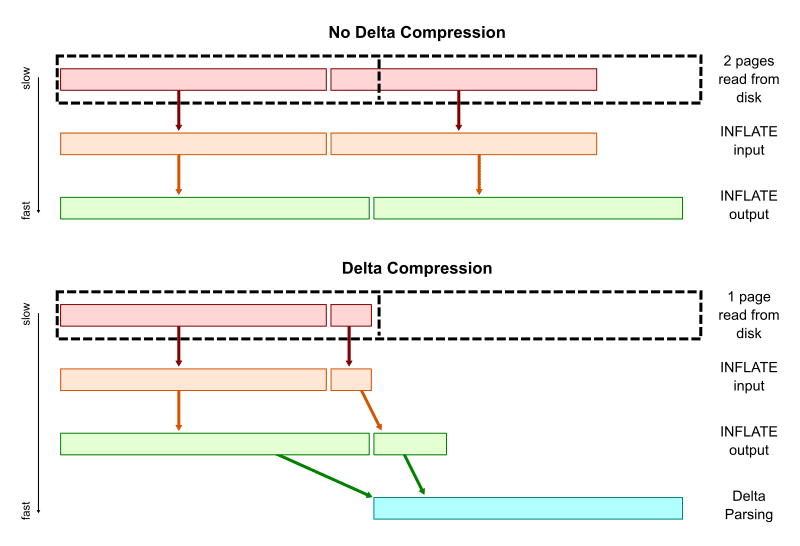
delta chain のトレードオフ
delta chain によって効率的に object を格納できるが、chain が長すぎると object を再現するために多くの object を取り出して解析する必要があるため時間がかかる。
つまり、ここでは格納と取得の効率がトレードオフになっている。Git では以下のような仕組みでこれに対応している。
- delta chain を短く保つ
- デフォルトの上限は 50
- pack.depth で上限値を書き換えられる
- 逆時系列つまり新しい順に delta chain を並べる
- 最近の object の方がよくアクセスすると考えられるため
packfile の再生成
このように、Git は object を圧縮して格納し効率的に探索するために packfile を利用している。しかし、新たに object を書き込むたびに動的に packfile を再生成するのはコストがかかるため、明示的に特定のコマンドによって行う。
git pack-objects で packfile を作成したり git index-pack で index を作成することもできるが、一般的には git gc を使って Git object store 全体を pack する新たな packfile を作ることが多いかもしれない。
リポジトリが成長するにつれ、新しい packfile を作るコストは高くなる。このような packfile のメンテナンスは Git を通じてソースコードを管理する上で重要になる。
packfile 再生成の作業量を減らすために git maintainance コマンドによるバックグラウンドでのメンテナンスを活用するという方法もある。詳しくは下記 GitHub 社の記事が参考になる。
Git と一般的なデータベースとの違い
Git のファイルシステムは一般的なデータベースで効率的にデータを探索するために使われている B-tree が存在しない。
Git のデータベースから blob の中身を取得する流れは以下の通りだった。
- 管理対象となる Git object の id としてハッシュを取る
- commit id を使って commit object の中から tree や blob の id を取り出す
- blob の id を使って
*.idxから*.packファイル内でその object の開始位置を示すオフセットを取り出す -
*.packから圧縮された object を取り出す
B-tree は、データが挿入されたり削除されたりする中でデータを効率的に探索するとき効果を発揮する。
一方で Git の packfile はリアルタイムで更新されるものではなく、一度書き込まれると別の packfile によって置き換えられるまで内容が固定されている。新しい packfile の生成は git add や git commit によって Git object が追加された後に git repack などで packfile を生成したり git gc によるガベージコレクションの発動によって行われる。
*.idx では fanout テーブル等によって効率的な binary search ができるので、実質的には B-tree と同等の効果がある。
git gc について
Git はときどき自動的に GC を行う。これを git gc コマンドから手動で行うこともできる。
ガベージコレクションが発動すると、
- 全ての loose object を集めて packfile に入れ
- 複数の packfile を一つの大きな packfile に統合して
- その index ファイルを更新し
- どの commit からも到達不可能かつ一定期間更新がない object を削除する
という一連の操作が行われる。このとき、どの commit からも指されていない loose object は pack されずに残る。GC の挙動や起こりうる問題については下記 GitHub 社の記事が参考になる。
第一回のまとめ
- Git は(VCS の皮を被った)ファイルシステムで、取り扱う対象のデータは Git object として格納されており、その内容から計算したハッシュを用いて取得できる
- 全ての commit はその時点のリポジトリのスナップショット
- スナップショットやその差分を効率的に格納して取り出すために packfile と呼ばれる仕組みがある
Part2: commit history queries
第二回は commit 履歴への query について。
Git の commit 履歴を可視化する
バージョン管理システムとしての Git の役割には以下の二つがある。
- チームが共通のリポジトリに共同で変更を加えるのを助ける
- 個人がリポジトリの履歴を検索し調査することを助ける
Git における「履歴」が意味するものは幾つかあるが、第二回では commit 履歴を、第三回で file の変更履歴を扱う。
今回も第一回と同様に Git 本体のリポジトリを使う。まずは git log --oneline --graph で 091680472db から最近の変更を表示する。
$ git log --oneline --graph 091680472db
* 091680472d Merge branch 'tb/midx-race-in-pack-objects'
|\
| * 4090511e40 builtin/pack-objects.c: ensure pack validity from MIDX bitmap objects
| * 5045759de8 builtin/pack-objects.c: ensure included `--stdin-packs` exist
| * 58a6abb7ba builtin/pack-objects.c: avoid redundant NULL check
| * 44f9fd6496 pack-bitmap.c: check preferred pack validity when opening MIDX bitmap
* | d8c8dccbaa Merge branch 'ds/object-file-unpack-loose-header-fix'
|\ \
| * | 8a50571a0e object-file: convert 'switch' back to 'if'
* | | a9e7c3a6ef Merge branch 'pb/use-freebsd-12.3-in-cirrus-ci'
|\ \ \
| * | | c58bebd4c6 ci: update Cirrus-CI image to FreeBSD 12.3
| | |/
| |/|
* | | b3b2ddced2 Merge branch 'ds/bundle-uri'
|\ \ \
| * | | 89c6e450fe bundle.h: make "fd" version of read_bundle_header() public
...(以下省略)
commit はその親となる別の commit への参照を持っており、順番に辿ることができる。
cat-file で 091680472d の commit の中身を見ると、確かに上記の log で可視化されているように2つの親 commit 4090511e40 と d8c8dccbaa を持っている。
$ git cat-file -p 091680472d
tree 7905dcefc711731411f3d8a31f06bb0de0d6ad21
parent d8c8dccbaafd35879493a95840ae52153f1d1136
parent 4090511e408a37091e7812bc1828a763a035e0a2
author Junio C Hamano <gitster@pobox.com> 1654291835 -0700
committer Junio C Hamano <gitster@pobox.com> 1654291835 -0700
...(以下省略)
commit を順番に表示するだけでなく、「ある commit が含まれている tag はどれか」も簡単に分かる。
以下は git tag --contains の結果だが、これを git branch --contains で実行すれば「ある commit が含まれている branch はどれか」を得ることができる。
$ git tag --contains 091680472d
v2.37.0
v2.37.0-rc0
v2.37.0-rc1
v2.37.0-rc2
v2.37.1
v2.37.2
v2.37.3
v2.38.0-rc0
merge base の計算方法
ある branch を別の branch に merge するとき Git は 3-way merge と呼ばれるアルゴリズムを使う。これは次のように処理される。
- merge 対象となる2つの独立した commit
A,Bに対して、その双方に共通して存在する commit(これを merge base と呼ぶ)を取り出す - merge base と
A、merge base とBをそれぞれ比較し、差が小さい方を merge する
merge base となる commit は技術的には共通の祖先であればどれでも構わないのだが、Git は「他のどの merge base からも "到達不可能" である単一の merge base」を実際にマージで用いる merge base として選択するように動作する。通常は一つに定まるが、複数存在する場合もある。この「到達不可能」とは何を意味するか。commit はリポジトリ内のそれぞれの commit を node とする有向グラフを形成し、各 commit は自身の親に対して有向の edge を持つ。このため、子から親に対しては edge が向いているので到達可能、親から子に対しては到達不可能と表現する。
git merge-base コマンドに2つの commit A, B を入力すると、出力として merge base となり得る commit id を返す。
$ git merge-base 3d8e3dc4fc d02cc45c7a
3d8e3dc4fc22fe41f8ee1184f085c600f35ec76f
つまり、commit 範囲 B..A に対する merge base は以下の条件を全て満たす。
- commit
AとBの両方から到達可能な commitCが存在する -
Aから到達可能だがBからは到達不可能な commit が少なくとも一つあり、その親がCである
この条件を満たす commit は 3d8e3d... の祖先に複数あるが、 3d8e3d... は条件を満たす他の commit から到達不可能であり、これが boundary commit と呼ばれ原則的に単一の merge base となる。
$ git log --graph --oneline --boundary 3d8e3dc4fc..d02cc45c7a
* d02cc45c7a Merge branch 'mt/pkt-line-comment-tweak'
|\
| * ce5f07983d pkt-line.h: move comment closer to the associated code
* | acdb1e1053 Merge branch 'mt/checkout-count-fix'
|\ \
| * | 611c7785e8 checkout: fix two bugs on the final count of updated entries
| * | 11d14dee43 checkout: show bug about failed entries being included in final report
| * | ed602c3f44 checkout: document bug where delayed checkout counts entries twice
* | | f0f9a033ed Merge branch 'cl/rerere-train-with-no-sign'
|\ \ \
| * | | cc391fc886 contrib/rerere-train: avoid useless gpg sign in training
| o | | bbea4dcf42 (tag: v2.37.1) Git 2.37.1
| / /
o / / 3d8e3dc4fc Merge branch 'ds/rebase-update-ref' ← これが merge base になる
/ /
o / e4a4b31577 (tag: v2.37.0) Git 2.37
/
o 359da658ae (tag: v2.35.4) Git 2.35.4
3-way merge は merge される commit, merge する commit, そしてこの merge base の三者間で行われる。
commit のデータ構造
Git はリポジトリのスナップショットを commit として保存し、各 commit には以下の情報が含まれる。
- その時点の root tree object の id
- 一つ前(parent)の commit object の id
- parent がない場合、最初の commit を意味する
- parent が1つの場合、それは parent commit に対する単なる patch である
- parent が2つの場合、それは独立した2つの commit を共通の履歴にまとめる(merge)commit を意味する
- parent が3つ以上の場合は octopus merge と呼ばれる
- author と committer の名前やメールアドレス等のデータ
- commit メッセージ
commit はリポジトリ内のそれぞれの commit を node とする有向グラフを形成し、各 commit は自身の親に対して有向の edge を持つ。
このようなグラフ構造を格納するためのデータベースは様々なものがあり、それらに commit や tree, blob などを入れることもできる。しかし、それらの多くは限られた深さのクエリ用に設計されており、1つの頂点から多くの関係を辿ることを想定している。
例えばソーシャルネットワークについて考えてみると、「六次の隔たり」という言葉もあるようにほとんど全ての node に短い距離で到達可能である。このような一般的なグラフ構造では、ある node が持つ edge の数は大きく変動する。
しかし Git のデータ構造はソーシャルネットワークとは大きく異なる。
Git object の id によって commit を直接参照することは少なく、多くの Git コマンドでは参照(tag や branch)の集合を扱う。これらは commit の数より遥かに少ないが、単純なクエリでも多くの edge を移動する必要があるかもしれない。また、複数の commit を merge する際には node 間の親子関係も重要な役割を果たす。
このように Git が管理するデータへのアクセスパターンは多くの汎用的なグラフデータベースの想定とは異なるため、そのユースケースに最適化したストレージやアルゴリズムを利用している。
第一回で見たように、Git では commit オブジェクトから tree や親 commit を辿ることで blob を取り出すことができ、その本体は packfile に圧縮されて格納されている。これでも十分に効率的なように見えるが、実際にはリポジトリの規模が大きくなり履歴が長くなるほど commit を解析して辿る繰り返し処理のオーバーヘッドが大きくなる。
packfile から index を使って binary search で高速に見つけられるとしても、 commit を解析して id を取り出す操作が必要であることには変わりがない。
Git では commit-graph ファイルを使うことでこの課題に対処する。これは特定のコマンド git commit-graph write や auto gc によるバックグラウンドでの packfile メンテナンス時に /objects/info/ 以下に作ることができ、主に2つの目的に使われる。
- commit 履歴の取得やフィルタリング
- merge base の計算
commit-graph は packfile 内に存在する全ての commit に関する特定の情報を含むデータベースのテーブルとみなすことができ、以下のデータを保持する。
- commit id
- root tree id
- commit 日時
-
親の commit を示す
commit-graph内のインデックス- 2カラムに分かれており、その commit の親の位置を示すインデックスを格納する
- 親の commit id ではないことに注意
- 通常の merge なら親を2つ、既存 commit に対する単なる patch であれば親を1つ持つ
- 3つ以上の親を持つ octopus merge の場合、2つめのカラムにはそれを示す特別な bit と overflow edge と呼ばれる追加のテーブルにおける開始位置を示すインデックスを格納する
- 2カラムに分かれており、その commit の親の位置を示すインデックスを格納する
下の図では、0 行目の commit は 2 行目を唯一の親として持っている。4 行目は2つ目の親として 5 行目を持っている。8 行目は octopus merge であり、 overflow edge の 3 行目を見れば 2, 5, 1 行目が親であることが分かる。なお、親の -1 はその位置に親が存在しないことを示すので、両方の親に -1 が入っている 5 行目は最初の commit ということになる。なお、これは object id に対して辞書順にソートされている。
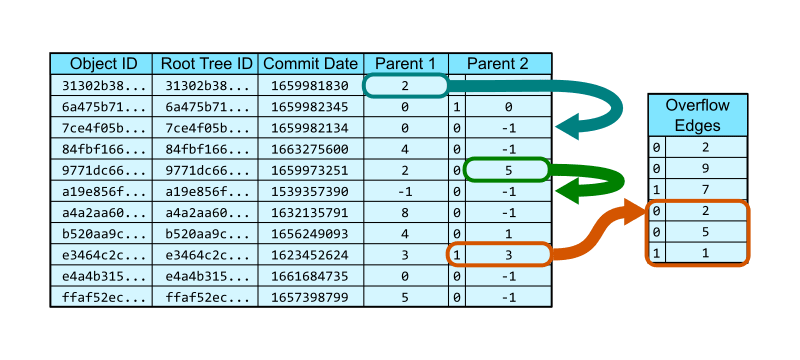
commit-graph は到達可能性のもとで閉じているグラフなので、ある commit が commit-graph に存在する場合は(最初の commit を除き)必ずその親となる commit も存在している。これにより、 commit id がなくても親 commit を示すインデックスだけを保存していれば十分である。インデックスは commit id よりも短いので解析や格納の効率が良い。
commit-graph を利用した探索効率化
この構造は commit 履歴を辿る際にどのような役割を果たしているのだろうか。
commit-graph が存在しないとしたら、第一回で実践したように Git は次のような順序で commit を辿る必要がある。
- 開始点の commit id を得る
- object store のどこに格納しているかを探す(基本的には packfile)
- object 本体を loose object から取り出す、もしくは packfile から取り出して解凍する
- object 本体をパースして親 commit を取り出す
- 1 に戻る
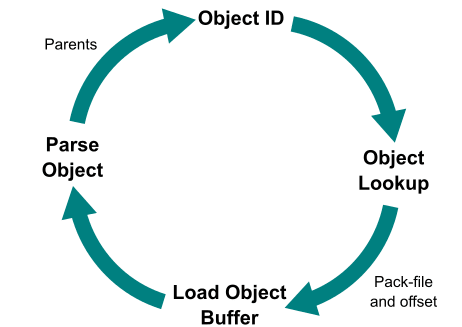
しかし commit-graph があることで、 1. と 2. の間に commit-graph に保存されたインデックスを解析して 親 commit の id を探索することができる。commit-graph には commit のみが含まれるので、全ての Git object(tree や blob, refs も含む)から探し出すより効率がよくなる。
最初の探索は commit 数に対して対数時間となるが、いったん目的の commit を見つけると commit-graph の該当行に保存されたインデックスを使って(つまり binary search すら必要ない)親 commit を定数時間で発見することができる。
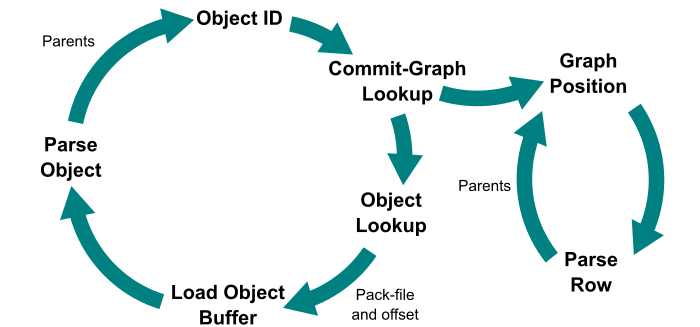
このように commit-graph を活用して commit の解析を回避することでクエリを高速化できるようになったが、まだまだ効率化の余地はある。
commit 間の到達可能性判定
「commit A は別の commit B に到達できるかどうか」を素早く判定できる場合、 git tag --contains や git branch --contains を大幅に高速化することに繋がる。
commit-graph ファイルは、 commit がデフォルトでは持たない世代番号という概念を持っている。これには「ある commit A の世代番号が別の commit B のそれより小さい場合、 A は B に到達することができない」という特性がある。
最も単純な世代番号は「トポロジカルレベル」と呼ばれ、次のように定義される。
- 親を持たない commit のトポロジカルレベルは
1となる - 親を持つ commit のトポロジカルレベルは
その親のトポロジカルレベルの最大値 + 1となる
下図で左端のトポロジカルレベルは 1 である。右端のトポロジカルレベル 9 のうち下側の commit はレベル 7 と 8 の親を持つので、最大値 8 + 1 = 9 がこの commit のトポロジカルレベルとして計算される。
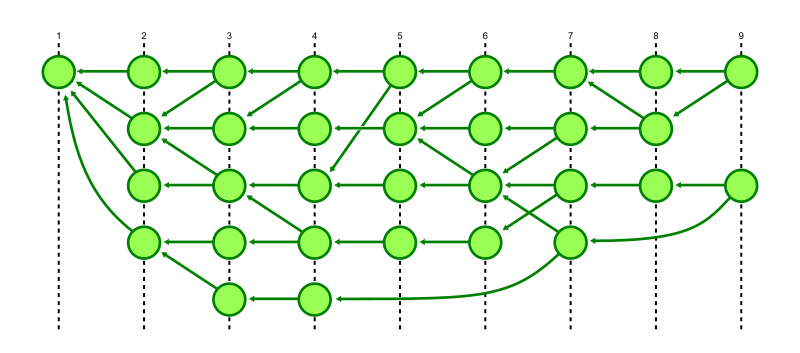
あらゆる commit は必ずその親より大きなトポロジカルレベルを持つ。即ち、自分より大きなトポロジカルレベルを持つ commit には到達できない。ただし、自身よりトポロジカルレベルが小さい commit に必ずしも到達できるとは限らない。この概念の目的はあくまで「確実に到達不可能な経路を探索しない」ということにある。
2つの commit の世代番号が等しい場合は到達不可能であるとみなすこともできるが、「到達可能か不可能か判別できない」という状態にしておくと便利である。
というのも、 commit-graph は明示的に git commit-graph write コマンドもしくは暗黙的に git gc コマンド等で作成されるものであり、これはその時点の packfile に格納された Git object を材料とする。よって、commit-graph を使って commit を探索するとき「commit されているが commit-graph ファイルには追加されていない」 commit が存在する可能性があるためだ。
Git はそれらの commit の世代番号を commit-graph 内における全ての世代番号より大きい infinity を持つものとして扱い、それらの比較においては何もしない。つまり、到達可能であるか到達不可能であるか分からない。よって、探索経路の決定においてその commit を排除しない。
トポロジカルレベルを世代番号とした場合の commit 探索効率化
commit 履歴へのクエリを高速化するために、世代番号はどのように活用されるのだろうか。以下の例で考えてみる。
-
git tag --contains b: commitbを含む tag の一覧を返す -
git merge-base --is-ancestor b a: commitbがaの祖先である場合に exit code0を返す
これらのクエリはどちらも commit b へのパスを探している。しかし、開始地点から b までの全ての commit を辿っていくのは時間がかかる。世代数がそれほど大きくない場合は commit 日時を使って幅優先探索することで効率化できるが、これは b が見つからない場合もある可能性を考慮すると効率的ではない。
Git では世代番号を活用することで、この探索を次のように効率化できる。
- commit 履歴を辿る途中にある commit の世代番号が目的の commit のそれより小さい場合、その経路の探索をやめる
- なぜなら、その経路の先にはより世代番号がより小さい commit しか存在しないため
- 世代番号が自身より大きい commit へ到達することは不可能であるとみなせる
- これにより、探索空間から多くの commit を切り捨てることができる
下の図では commit A が B へ到達できることが見て取れる。この探索を行うとき B の世代番号 4 未満の世代番号を持つ commit はその先に B が存在しないとみなせるため無視できる。
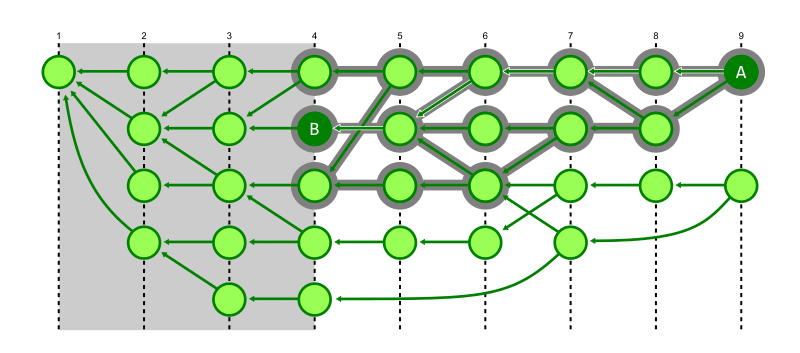
上記の特性により、幅優先探索ではなく深さ優先探索を行うことで、目的の commit により少ない歩数で辿り着くことができる。
典型的な commit 履歴では、親は1つか2つになる。どちらの場合でも Git の履歴は最初の親(commit object で最初に記録される親)commit に対して直線的になるため、最初の親を辿ることで素早く目的の commit と同じ世代番号まで辿り着くことができるので、幅優先より深さ優先の方が探索効率が高い。
下図では前図で訪問済みとなった多くの commit へ訪問せず探索を完了できていることを示す。
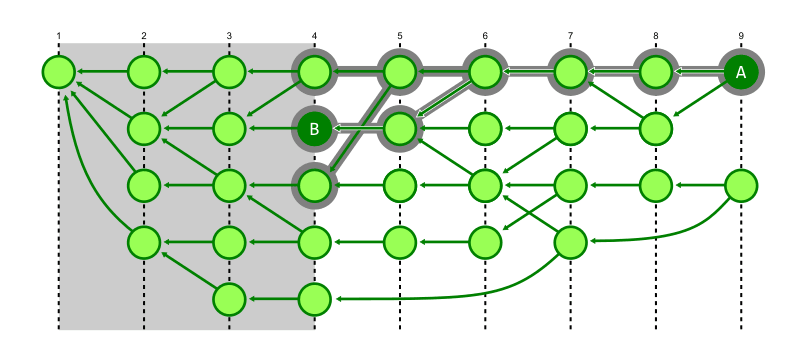
しかし、このアルゴリズムが効率的である背景には commit の分岐や接続方法に関する仮定があり、これが成立しない場合は効率が落ちる。例えば分岐が多い commit-graph で非常に古い commit を探索する場合は効率が悪くなってしまう可能性がある。
git log における commit のトポロジカルソート
世代番号は到達可能性の判定以外にも git log --graph による commit の可視化に役に立つ。
このコマンドは commit 履歴を人間に見やすいように表示するために、トポロジカルソートと呼ばれるアルゴリズムを使う。ここで「人間に見やすい」とは以下の要件を満たしていることを意味する。
- 全ての commit をその親より前に表示する
- デフォルトの
git logではこれが保証されていない
- デフォルトの
- merge によって加わった commit の祖先を、 merge commit の最初の親より前に表示する
後者はつまり、以下のような graph において 49c837 の first parent である 5dba4d よりも merge によって加わった fc0f8b (と、もしあればその祖先)が先に表示されるということ。
$ git log --graph --oneline -5 ffaf52ec9d9e1b9b119753559f70b7ae266cfc7a
* e4a4b31577 (tag: v2.37.0) Git 2.37
* 49c837424a Merge branch 'jc/revert-show-parent-info'
|\
| * fc0f8bcd64 revert: config documentation fixes
* | 5dba4d6540 Merge tag 'l10n-2.37.0-rnd1' of https://github.com/git-l10n/git-po
|\ \
| * | 71e3a31e40 l10n: sv.po: Update Swedish translation (5367t0f0u)
なお、このコマンドに --date-order オプションをつけると commit の日時順で並ぶので fc0f8b より 5dba4d が先に表示される。少し読みづらくなった。
$ git log --graph --oneline --date-order -5 ffaf52ec9d9e1b9b119753559f70b7ae266cfc7a
* e4a4b31577 (tag: v2.37.0) Git 2.37
* 49c837424a Merge branch 'jc/revert-show-parent-info'
|\
* \ 5dba4d6540 Merge tag 'l10n-2.37.0-rnd1' of https://github.com/git-l10n/git-po
|\ \
| | * fc0f8bcd64 revert: config documentation fixes
| * | 71e3a31e40 l10n: sv.po: Update Swedish translation (5367t0f0u)
commit をトポロジカルソートするためには Kahn のアルゴリズムが使われる。
- まず到達可能な commit を辿り、ある commit が他の commit の親として現れる回数を数える。この数を in-degree と呼び、その commit に向いた edge の数を意味する
- in-degree が 0 の commit をキューに入れ、順番に訪問していく
- 訪問時にその commit の親の in-degree をデクリメントする
- 2 に戻る(3 でデクリメントした結果 in-degree が 0 になった commit がキューに入る)
最新の commit にはそれを親とする commit が存在しないため in-degree は必ず 0 となる。その親は 1 以上の値を持ち、複数の子があれば in-degree は 2 以上になるが子 commit の訪問時にその分だけデクリメントされていく。これにより、常に in-degree が 0 の commit が1つ以上あるため、到達可能な commit を全て訪問することができる。
一方で、このアルゴリズムを使うと手順 1. により ユーザーに git log の結果を表示する前に到達可能な全ての commit を走査しなければならないという問題がある。
解決策としては、Git では less のようなページャーで結果を表示しているので、全ての commit を走査せずともユーザーに表示する箇所までを先に計算すればよい。Git では世代番号を使い手順 1. の in-degree 計算と手順 2. ~ 4. で行われる commit 訪問を同時に実行することで、このアルゴリズムを大幅に効率化している。
Git は commit を世代番号順にキューに入れて in-degree を計算しはじめ、最大の世代番号(キューから取り出すと下がっていくはず)が走査開始位置となる commit のうち最小の世代番号を下回るまで in-degree の計算を行う。その後 Kahn のアルゴリズムに沿って走査した commit をスタックし、順番に取り出してユーザーに表示する。in-degree の計算は commit を走査する必要があるときだけ先に進む。
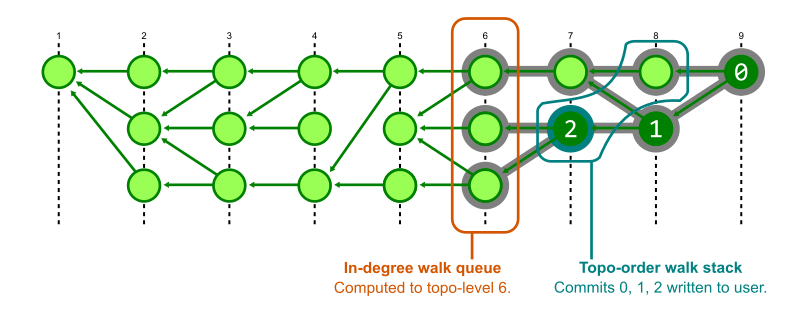
これによりトポロジカルソート済 commit を必要なだけユーザーに表示することができる。
トポロジカルレベルの欠点と世代番号の改善
トポロジカルレベルでは基本的に世代番号の要件を満たす最小の整数を使用するが、これには欠点もある。
例えば昔からあるバグを修正する際に、非常に古い commit を基にバグを修正しそれを古い branch に merge する場合、そのトポロジカルレベルは最近の commit と比較して非常に小さくなる。
もしその commit を対象とした探索が到達不可能である場合、その小さい世代番号までの commit を全て探索することになるため効率が非常に悪くなってしまう。
この解決策として commit 日付を基に加工した世代番号を使うという案が2020年の Google Summer of Code で実装された。
世代番号の基になる訂正後の commit 日付は次のように定義される
- ある commit が親を持たない場合 commit 日をそのまま使う
- 親を持つ場合は、親の中で最新の commit 日と自身の commit 日の新しい方に 1 を加算する
訂正された commit 日付を使用すると、単純なトポロジカルレベルによる世代番号と比べて値が多様になる。つまり、下図のように横方向に世代番号がずれる。
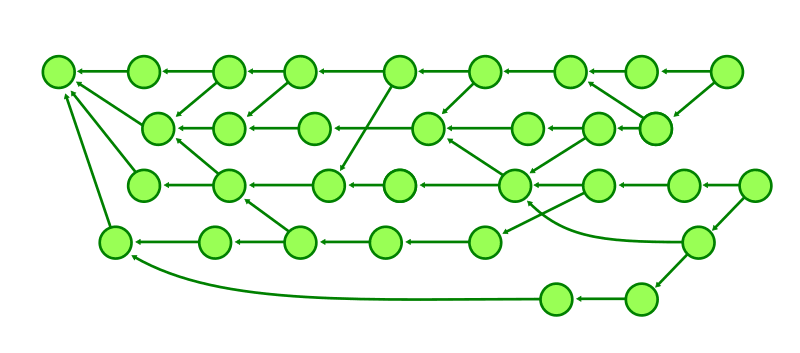
このような実装にすることで、古い commit に基づく最近の commit による性能問題を解決することができる。例えば下図では A から古い commit C に到達を試み、トポロジカルレベル 3 までを深さ優先探索する。実際には到達不可能だが、それを確かめるために高いコストがかかる。
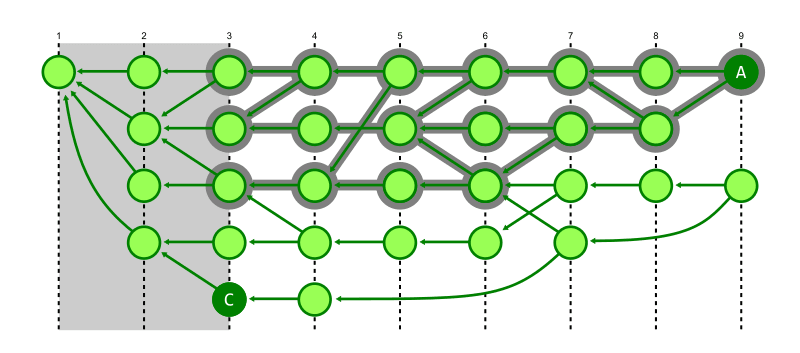
一方で commit 日付を基にした新しい世代番号では commit C より古い世代から C に到達することはできないとみなすことができるから、到達不可能性を判定するために探索する必要がある commit を大幅に減らすことができる。
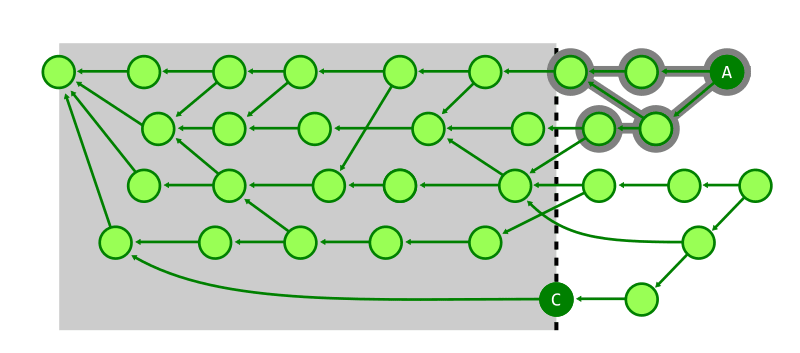
このように、Git では commit-graph を活用することで以下の機能を効率的に実現していることがわかった。
- 過去の commit 履歴を閲覧、検索する
- merge-base を決定するために到達可能な commit を素早く探す
- ある commit から別の commit に到達できるかどうかを素早く判断する
第二回のまとめ
- Git では commit 履歴の可視化や merge-base の探索を効率化するために commit 履歴のグラフ構造を活用している
- 予め packfile の生成などのタイミングで作られる
commit-graphファイルに commit の親子参照を記録しておくことで、 commit object を解析せずに参照を辿ることができる - commit に世代番号という概念を導入することで、履歴の探索空間を大幅に削減できる
Part3: file history queries
第三回はファイルの変更履歴へのクエリについて。
Git でバージョン管理をするにあたり、コードの背景を理解するために変更されたファイルや特定の行を探す場合がある。これを効率的に探索するための仕組みにはどのようなものがあるか。
ファイル履歴としての git log <path>
git log にファイルへの path を与えることで、あるファイルを変更した commit、すなわち自身の親とその path において異なる Git object id を持つ commit、を知ることができる。
$ git log --graph --oneline -5 README.md
* 2981dbea78 Merge branch 'po/readme-mention-contributor-hints'
|\
| * 4ed7dfa713 README.md: add CodingGuidelines and a link for Translators
* | df7375d772 CI: use shorter names that fit in UX tooltips
|/
* 6081d3898f ci: retire the Azure Pipelines definition
* 9ae7dcb402 README: add a build badge for the GitHub Actions runs
ここで重要なこととして第一回でやった通り commit はスナップショットであって差分ではないということがある。下図の通り Git において commit は特定時点のリポジトリのスナップショットであり、その時点のディレクトリ構造は tree、ファイルの内容は blob として持っている。
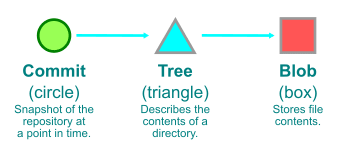
Git は path のファイルが変更されたかを知るために、二つの commit 間の差分を計算しなければならない。これは次のように行われる。
- 二つの commit に記録された root tree をロードする
- path のディレクトリの tree を基にそれぞれの配下にある Git object id を比較する
- 同じ path に同じ object id がある場合、その path は変更されていない
- なぜなら object id はその object の中身のハッシュであるため
- 少しでも変更されていればハッシュが変わっているはず
- 同じ path で異なる object id がある場合、その path は変更されている
- これを再帰的に繰り返す
二つの commit の間である同一の path に異なる object id が存在しない場合、その状態をその path に対して treesame であると呼ぶ。
また、親が一つしかない commit と親の比較が treesame ではない場合、または全ての親 commit に対して treesame ではない場合、その commit は interesting であるという(interesting というのは興味深い、つまり詳しく調べる必要があるということ)。
下図左は treesame である。赤い □ は新たな path に加わった object であり、既存の object の変更ではない。一方で、下図右は treesame ではない。
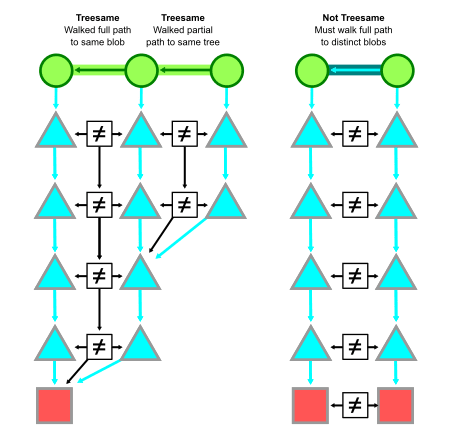
同様に merge commit についてもその親に対して treesame になっていなければ interesting であるとみなす。
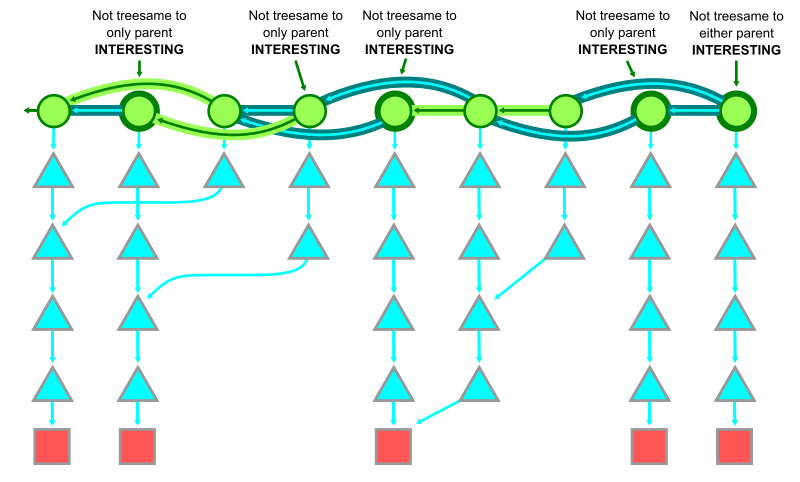
少なくとも一つの treesame な親を持つ interesting ではない merge commit について、 Git はクエリの種類によって異なる判断をする。
簡略化された履歴
git log で表示される履歴は、デフォルトでは簡略化されており merge commit に遭遇したときそれを順番に親 commit と比較していく。
もし親 commit が treesame だった場合は、親 commit 時点で存在していたファイルは変更されていないことが確実とみなせるため Git はその親 commit をスキップし別の親を調べる。もし treesame でない親 commit がある場合は、既存のファイルが変更されているため root tree のロードから始まる一連の流れで diff を計算する。
あまり頻繁に変更されない path では、ほとんどの commit で最初の親(commit object で最初に表示される親)に対して treesame になるため、親 commit より先の到達可能な commit を diff 計算から省略できる。
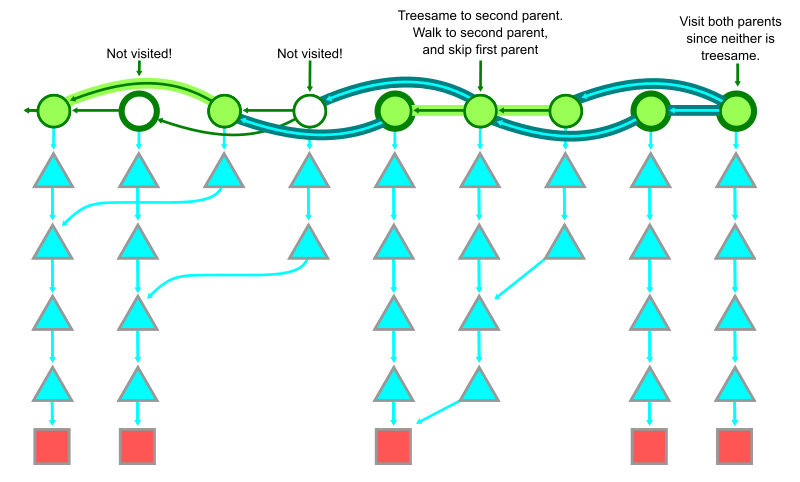
これにより最新のバージョンに寄与していない(つまりそのバージョンに対して treesame である)多くの commit をスキップできるためパフォーマンスが向上するが、一方でスキップによって混乱を招くこともあるため、どのような commit が簡略化された履歴においてスキップされるかを知っておくことが重要になる。
-
Revert:
- ある topic branch 内で行われた変更を取り消すために revert した場合、少なくとも2つの commit でそのファイルが編集されている
- 最終的には元に戻るためファイルに変更はないとみなすことができる
- その topic branch が merge されると、merge commit が(revert 対象の変更がされる前の)親 commit につながり、topic branch はスキップされる
-
Cherry-pick:
- ある commit を様々な branch で cherry-pick で取り込むと、同じ変更が複数の branch で並行して行われているように見える
- それらの branch が merge されると、そのうちの一つを選んで可視化し、他をスキップする
-
Merge conflict resolution:
- merge commit で conflict が生じ、その解決時に誤って他方の変更を全て消してしまうことがある
- Git は treesame な親を見て、 conflict の解決時に誤って削除された側をスキップする
簡略化されていない完全な履歴を出すには git log --full-history を使う。これは treesame かどうかに関係なく履歴の全ての commit を簡略化せずに可視化するが、ノイズが多いので --simplify-merges オプションを追加するとよい。
通常の git log 以外 の履歴表示
-
git log -L: ファイル全体ではなくファイルの一部を指定することができる- 履歴クエリを特定の関数や行に絞り込むために使われる
- 例えば...
-
git log -L <from>,<to>:<path>で path のファイルにおいて from から to までの行の変更を全て表示する -
git log -L:<identifier>:<path>で path のファイルにおいて identifier (関数やクラス、構造体)に関連するコードを見つけてそれぞれの行に変更があった場合に表示する
-
-
git blame,git annotate: ファイルの各行を最近変更した commit を表示する- 出力の形式が少しだけ異なる
- ある行を変更した commit を発見したらそれ以上遡らない
ファイル履歴のクエリ高速化
ファイル履歴のクエリは第二回のコミット履歴のクエリと似ているが、diff の計算にあたって treesame の判定に時間を割いているという違いがある。
ある commit で指定された path を示す Git object へ移動するには、次の順序でリンクを辿る場合を考えてみる。
- commit から root tree の object id を取り出す
- このとき第二回で学んだように commit-graph に root tree を含めることで高速化できる
- path に至るまでディレクトリを示す tree object を辿る
- 最後に path の object id を得る
- 上記の object id を使って
*.idxと*.packから目的の object を取り出す
このような解析を行うとき、リポジトリの構造が大きく影響する場合がある。
- tree の深さ: 指定された path が深ければ深いほど、解析しなければならない tree も多くなる
-
隣接する変更: 指定された path が頻繁に変更される他のファイルがたくさんあるディレクトリを指している場合、 treesame でなくなるため解析の手間が増える
- あるディレクトリより下のファイルが全く変更されない場合、 tree object の id が変わらないためそこから下は変更されていないことから解析をスキップできる
この2つはトレードオフになる。なぜなら、 tree を浅くしようとするとその分だけ一つのディレクトリで管理されるファイルが多くなり、隣接する変更が増えるためだ。
これを効率化するためには「2つの commit はこの path において同じ(もしくは異なる)内容である」ということが分かればよい。例えば、「この commit ではこの path が変更された」という commit-path のペアを保存しておき、そこから検索するという方法が考えられる。
しかし、これを正確に実行するには非常に多くのストレージが必要となる。VSTS(現 Azure DevOps)でこのペアをデータベースに保存していたとき、 Linux のカーネルだけで 60GB を超えていたらしい(参考)。これはカーネル本体のサイズより遥かに大きい。
...ということで困るのだが、実は 100% 正確に比較することを諦めて以下の近似解を探すことで大幅にクエリを高速化することができる。
- 2つの commit はこの path において同じである
- 2つの commit はこの path においておそらく異なっている
これを実装するために Bloom filter という手法を使う。
Bloom filter
このスライドが非常にわかりやすい。
Bloom filter を一言で表すと「要素が集合に属しているかを確率的にチェックするフィルタ」といえる。非常に効率よく計算でき、計算量がデータ量に依存しない。
- Bloom filter の判定に用いる bitmap の容量の係数と密度を決める
- 例えば容量を 10 とし密度を 7 とする
- 10N 個の bit を確保し、全て 0 で初期化する
- filter に要素を追加する
- このとき、要素を予め用意したハッシュ関数に入力し、その結果として 7 bit のハッシュ値を得る
- 7 bit のハッシュ値に対応する bit が 0 であれば 1 に変更する
- Bloom filter に要素が存在するかどうかは、その要素のハッシュ値に対応する 7 bit が 1 になっているかどうかで確認できる
- 1 bit でも欠けていれば、確実に存在しないことが分かる
高速に計算ができる代償として、ハッシュ値の衝突によって集合にない要素を「ある」と誤検知してしまう偽陽性の問題がある。逆に偽陰性(要素が存在するのに無いと検出してしまう)はあり得ない。なお、この検出精度はハッシュ関数やビットマップの容量によって操作できるが、検出精度を上げすぎると逆に計算の効率が落ちるため上げればいいというものではない。
Git においては「2つの commit はこの path においておそらく異なっている」という課題に対して誤検出(つまり、本当は同一なのに異なっていると判定)したとしても tree を走査すれば本当に異なっているかどうかを検出できるため偽陽性によって致命的な問題が起きることはない。
Git における Bloom filter
Git ではファイル履歴のクエリを高速化するために、全ての commit に対して Bloom filter 用の index を commit-graph に保存している。
commit の Bloom filter では親 commit から変更された各 path を格納する。このとき path をそのまま保存するのではなく、各 path をハッシュ関数に通した結果として得た bit の集合を保存する。
これにより、親 commit との間で特定の path が treesame になっているどうかを判定することができ、結果は以下のいずれかになる。
- おそらく違う
- 間違いなく treesame である
Bloom filter で特定の path が treesame ではないと判定されたら(偽陽性の可能性もあるが) diff を計算するために tree を解析する。一方で treesame であると判定された場合は確実に treesame であるから tree を解析する必要はない。
Bloom filter はパラメータによって偽陽性の確率を操作でき、Git の場合は 1~2% となる。つまり 98% 以上のケースで tree の解析を避けることができ、大幅な効率化につながる。
第三回のまとめ
- Git にはファイルの変更履歴を効率よく探索するために treesame という概念が存在する
- 「親 commit に対して treesame である」とは「親 commit において存在していた path が変更されていない」ことを指す
- 言い換えると「同じ path に異なる object が存在しない」とも言える
- Bloom filter と呼ばれる手法で確率的集合を取り扱うことで、tree の探索と解析を多くの場合で回避することができる
Part4: distributed synchronization
第四回は Git がどのように分散データベースとして機能するかについて。具体的には git fetch と git push がローカルとリモートでどのように同期するのかについて。
Git では原則的に中央のリポジトリに接続する必要はなく、各開発者のローカルコピーを用いて開発を進める。GitHub のような中央リポジトリがある場合であっても、開発者はその中央リポジトリからコードを入手して作業を進め、手元で作業が完了したときに中央リポジトリにコードを送る。このローカルとリモート間の同期には git fetch や git push コマンドが使われている。
CAP 定理と Git
分散システムにおいて CAP 定理と呼ばれる理論がある。これによれば、分散システムは同時に Consistency(一貫性), Availablity(可用性), Partition tolerance(分断耐性)の全てを満たすることができない。
Git ではデータはデフォルトで分断されている。各開発者のローカルのコピーは分散しており、それぞれ違った状態を持ち、情報を同期するタイミングやどの部分を同期するかを開発者が選択することができる。これにより、他のデータベースの同期メカニズムとは異なる。
まずはクライアントから git fetch を実行しリモートリポジトリと同期する場合を考える。
この時 Git のクライアントは最初にリモートで利用可能な ref のリストを要求する。これを ref advertisement と呼び、実質的には git ls-remote コマンドで同じことができる。このとき Git object は何もダウンロードされない。
$ git ls-remote --heads origin
4b79ee4b0cd1130ba8907029cdc5f6a1632aca26 refs/heads/main
a0feb8611d4c0b2b5d954efe4e98207f62223436 refs/heads/maint
4b79ee4b0cd1130ba8907029cdc5f6a1632aca26 refs/heads/master
7147cddc233140dc1cbfb9e5c541f722106e4b3b refs/heads/next
85b92d5bb8667c4286791fc99519c2f0ebadf5e6 refs/heads/seen
2aec5765247f83052c6ac926ca53deb75d4dce8c refs/heads/todo
git maintainance による prefetch
クライアントは通常は手動で git fetch や git pull を実行した時のみリモートと同期するが、より頻繁に同期を行うことで必要な Git object の転送量を減らすことができる。
例えば git maintenance コマンドで定期的な prefetch を設定するといった方法がある。これによりバックグラウンドで Git object を同期しておくことで、手動で git fetch を実行したときには ref を更新するだけでよくなる。
どの object がどのコピーにあるのか?
あるリポジトリのコピーにあり別のコピーにはない Git object はどのようにして見つけることができるか。
両方の全コンテンツを取得して一つずつリストアップすることもできるが、高い計算コストがかかる。実際には全てのコピーが必要なわけではなく、要求した branch や tag から到達可能な commit だけを取得できればよい。つまり、実際に必要なのは「片方の Git object(の集合)から到達可能であり、もう片方からは到達できない Git object の集合」となる。
Git ではこのクエリの開始点を定義するために want と have という用語を使用する。
-
want: クライアント側に存在せず、クライアントからの要求とサーバー側に存在する object
- これはクライアントには存在せず、サーバー側からの ref advertisement によって入手した id で参照する
- have はクライアント側が既に持っている object
クライアント側が git fetch や git pull でサーバーから取得したい object は「want に含まれるどの object からも到達可能だが have のいずれからも到達できない object」である。なお git clone では have を無視して want だけを取得する。
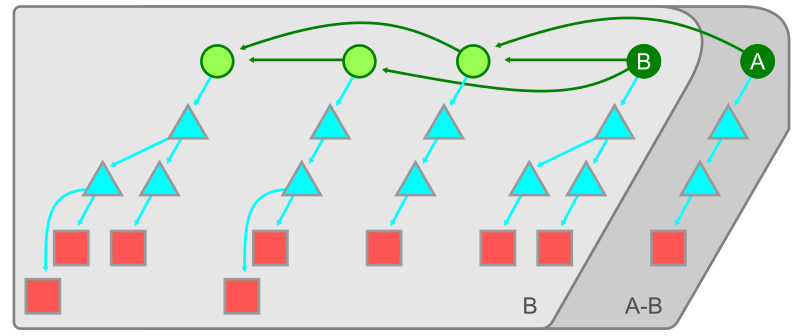
集合の差分を探索する
Git ではまず have に含まれる commit から到達可能な object を発見するためにグラフを走査し、次に want から到達可能な object を探す。
第一回で見たように Git object には commit, tree, blob, そして ref の4種類があり、 commit は tree への参照を持ち、 tree は blob への参照を持っている。
そして第二回で見たように Git は commit 履歴を commit-graph ファイルに保存することで高速に履歴を辿ることができる。これを活用し have から全ての commit とそれが指す root tree をもとに再帰的に blob を探す。
下図では commit B が have で、 commit A が want である。まずは B から到達可能な object を辿り、その後 A から到達可能な object を辿る。この時 B で訪問済みの object を無視することで、 B と A の差分のみを取り出すことができる。
このアルゴリズムはうまく動くように見えるが、弱点もある。
まず tree の解析に時間がかかる。第三回では特定の時点におけるファイル履歴の探索を効率化する仕組みを紹介したが、これとは異なり commit 履歴内にはたくさんの tree がある。例えば OSS のライセンスファイルは一度だけ追加され変更されることは滅多にないが、commit をする度に root tree が変わるので、Git はその tree を解析するたびにライセンスファイルが格納されているかを確かめる必要がある。
次の問題として、have と want の差分を取り出すためには多くの commit object を移動しなければならないことがある。集合の差分が README を少し変更しただけであっても、それを確かめるためには大部分の commit object を渡り歩く必要がある。
commit のフロンティアを発見する
多くの commit を移動しなければならない問題については Git の commit 履歴の構造と Git リポジトリの使われ方に関する仮定を利用することで解決することができる。
Git リポジトリをソースコードの格納場所として捉えると、基本的にコードの変更は「新しいコードを追加する」ことによって行われる。つまり、遠い過去の object を探すことは少ない。この仮定に基づき commit の「フロンティア」つまり have 側から到達可能な commit でありながら、 want との差分と have/want 共通履歴の境界にある commit の発見を試みる。
ある commit A がフロンティアであるためには A を親とし wants からは到達可能だが have からは到達不可能な commit B が少なくとも一つ存在しなければならない。
つまり、フロンティアは want と have が枝分かれする commit と言うことになる。これは git log --boundary で確かめることができる。下記では d02cc4 から到達可能だが 3d8e3d からは到達不可能である境界となる commit が o でマークされている。
$ git log --graph --oneline --boundary 3d8e3dc4fc..d02cc45c7a
* d02cc45c7a Merge branch 'mt/pkt-line-comment-tweak'
|\
| * ce5f07983d pkt-line.h: move comment closer to the associated code
* | acdb1e1053 Merge branch 'mt/checkout-count-fix'
|\ \
| * | 611c7785e8 checkout: fix two bugs on the final count of updated entries
| * | 11d14dee43 checkout: show bug about failed entries being included in final report
| * | ed602c3f44 checkout: document bug where delayed checkout counts entries twice
* | | f0f9a033ed Merge branch 'cl/rerere-train-with-no-sign'
|\ \ \
| * | | cc391fc886 contrib/rerere-train: avoid useless gpg sign in training
| o | | bbea4dcf42 (tag: v2.37.1) Git 2.37.1
| / /
o / / 3d8e3dc4fc Merge branch 'ds/rebase-update-ref'
/ /
o / e4a4b31577 (tag: v2.37.0) Git 2.37
/
o 359da658ae (tag: v2.35.4) Git 2.35.4
一旦「フロンティア」が決まると、その commit の root tree から到達可能な tree を再帰的に辿ることでほとんどの commit 履歴を辿らずに済むため効率的になる。
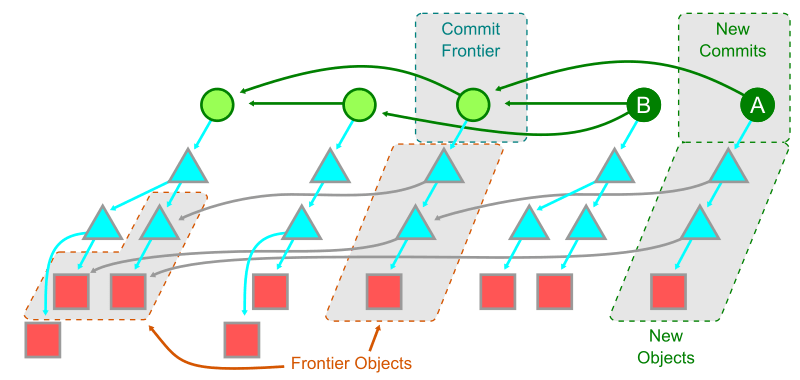
このアルゴリズムでは辿る必要がある tree が大きく減り、全歴史の全 object を辿る必要がなくなった。しかし、巨大な tree を持つリポジトリでは tree を辿るコストは高いかもしれない。これを解決するデータ構造として Git では次のビットマップを利用している。
到達可能性 bitmap
一般的に、集合の差分演算をするとき bitmap と呼ばれるデータ構造をよく使う。これは一般的なデータベースのクエリインデックス等でも使われている。
先ほどの図を基に考えてみる。図の最上部の数字が bitmap で、commit A から到達可能な object は 1, 到達不可能な object は 0 とする。
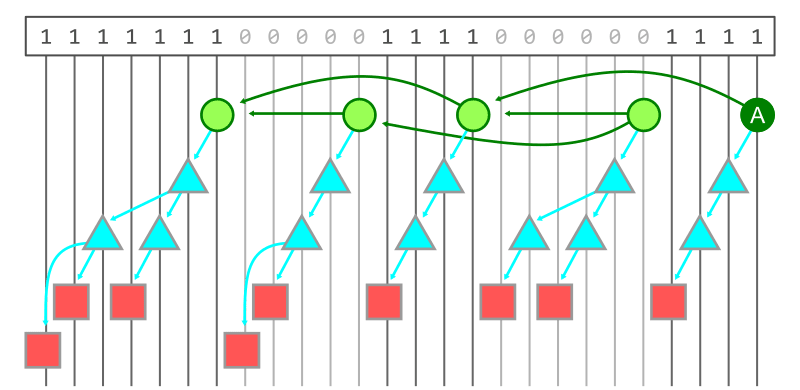
2つの bitmap(つまり want と have)の差を計算するためには、bitmap を辿り、最初の bitmap で 1 かつ二番目の bitmap で 0 となる object を探せば良い。
ここで疑問に感じる点として、以下の点において計算やメモリのコストが高いのではという疑問がある。
- このような bitmap を計算するには到達可能な object を探索するのと同じくらい計算コストがかかる
- bit を全探索するには object の数だけメモリが必要になる
Git はこのコストを下げるために到達可能な bitmap を事前に計算し、それをディスクに保存する。第一回で紹介した packfile を使う。
git repack --write-bitmap-index コマンドにより、 Git object を新しい packfile に入れながら到達可能 bitmap を計算し .bitmap ファイルを生成することができる。各 bitmap は一つの commit に対する到達可能性を示し、.bitmap ファイルは複数の commit に対応する bitmap を格納できる。
もし全ての commit が到達可能性 bitmap を持っている場合、次のような手順で want と have の差を計算できる。
- have commit の bitmap を全て結合し、少なくとも一つの have から到達可能な object を格納した union bitmap を計算する
- want commit の bitmap を全て結合し 1. と同様に union bitmap を作る
- 1 と 2 の差分を計算する。
下の図は上記 3. の処理を実行したもので、 A - B bitmap は A が 1 かつ B が 0 の場合のみ 1 となる。
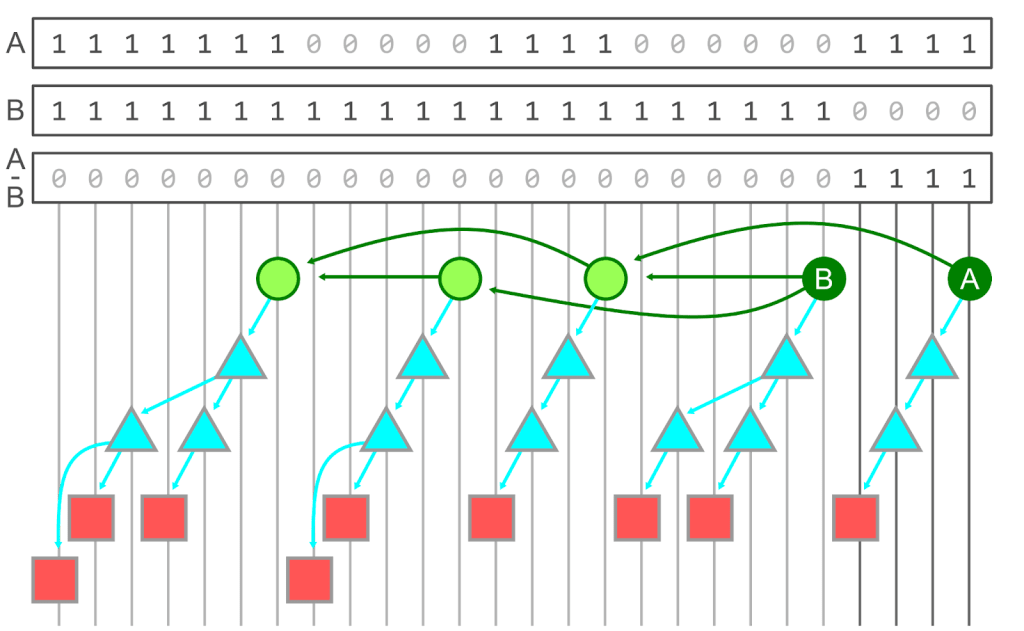
しかしながら、全ての commit に対する到達可能性 bitmap をディスク内に保持することは現実的に難しい。というのも、 bit は Git object ごとに1つ必要で bitmap は commit ごとに必要だから、 commit が増えていくと二次関数的に増えてしまうからだ。実際には Git は bitmap や bitmap 間の差分を圧縮して保持しているのだが、コストが大きいことに変わりはない。
また、たとえ全ての commit に対して到達可能性 bitmap を保持していても別の開発者が新しい commit をリポジトリに push したらその bitmap が計算される前に fetch/pull される可能性はある。したがって、ディスクに bitmap を保存することは万能な解決策ではなく、別の方法を考える必要がある。
Git はこれを解決するために commit 履歴を辿る際にひと工夫している。have から始めて、事前に計算された到達可能性 bitmap を発見するまで commit 履歴を辿る。そこから先は bitmap を使って到達可能性を判定できるので commit を辿る必要がない。これを want の commit 集合でも繰り返し、探索を完了したら have と want の差分を計算する。
このように、事前の計算による到達可能性 bitmap、適切な圧縮、そして最後の動的な bitmap 計算を組み合わせることで低コストで「ある commit 集合から到達可能で別の commit 集合から到達不可能である」commit を効率的に探索できるようになった。
push 固有の特性と sparse アルゴリズム
ここまでは fetch や pull などリモートから Git object を取得する仕組みについて見てきた。次に逆の流れである push について見ていく。
基本的には have と want の意味が反転する(つまり、 have はリモートが既に持っている commit の集合であり、want はクライアントがリモートに持たせたい commit の集合である)だけで、同じ仕組みを使って効率的に Git object を同期できる。
push の特性として、変更されるファイルの数がある。fetch や pull では自分以外の開発者すべてが加えた変更が含まれるのに対し、クライアントからの push はファイルの数が少なくなりがちである。この特性を利用することで、push される Git object の探索をより効率化できる。
また、 git push はそれほど頻繁に実行されないため、到達可能性 bitmap を計算するコストに見合わない。pull や fetch では到達可能性 bitmap がない場合 Git はフロンティア・アルゴリズムにフォールバックするが、これもクライアントリポジトリが大きくなると、ある root tree から到達可能な object を探すコストが高くなりすぎる。
そこで、 commit 履歴を利用して到達可能集合の差を計算するアルゴリズムが考案された。これは pack.useSparse オプションで有効にすることができる(デフォルトで有効)。このアルゴリズムの特徴としては、フロンティア・アルゴリズムと同様に commit 履歴を活用するのに加えて、 heuristic として tree 自体の構造を利用する。
まず Git はフロンティア・アルゴリズムと同様に have と want の間でどの object が共通しているかを調べるために commit フロンティアを探索する。そしてフロンティアの root tree から到達可能な全ての tree object および want の root tree を一度に辿る。
このときフロンティアの root tree から到達可能な object のみを格納している tree は uninteresting としてその先の tree および blob を探索せず、 want の commit 集合から到達可能な object を格納している tree または blob が一つでもあれば interesting としてその先の経路を探索する。
Git はこれらの tree で利用可能な経路を幅優先探索する。
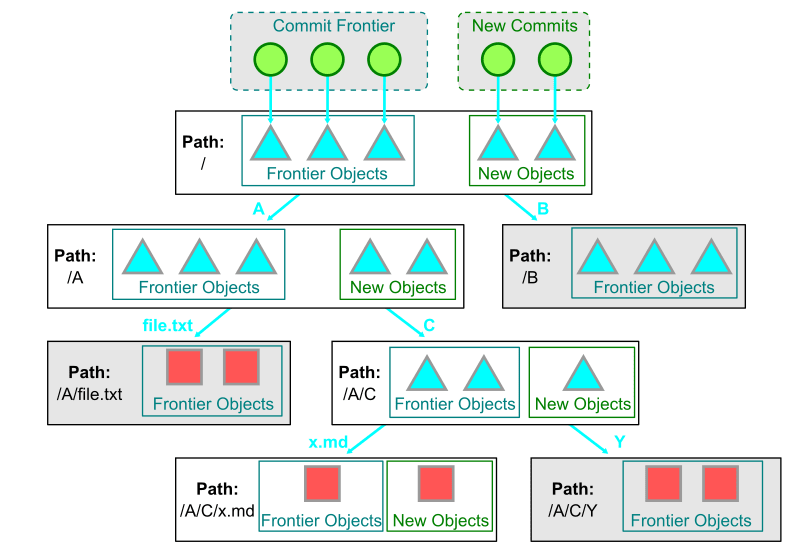
詳しくは以下の Microsoft 社の記事が参考になる。
YouTubeのvideoIDが不正です
実行計画の heuristic
Git 内部をデータベースと捉えたとき、クエリの実行計画にあたる機能がある。
一般的なデータベースは、クエリを実行する前にそのクエリと利用可能なインデックスを調べその実行計画を提案することができる。SQL のようなクエリ言語は宣言的である。つまり出力は定義するが操作をどのように行うかは定義せず、それはデータベースエンジンが行う。
Git で行われている実行計画とは次のようなものである。
- 到達可能 bitmap が存在する場合は、その bitmap を使う
- bitmap がない場合、
pack.useSparseが有効であれば sparse アルゴリズムを使う - どちらも成立しない場合、フロンティア・アルゴリズムを使う
これは非常に単純な実行計画で、常に最も効率のいいクエリを実行できるとは限らない。
というのも、例えば bitmap が古かったらフロンティア・アルゴリズムの方が速い場合があるし、 want から到達可能かつフロンティアから到達不可能な commit がある場合は bitmap より sparse の方が効率的になる。これは Git の pack.useSparse オプションや push.useBitmaps オプションによって挙動を変更することができる(Git 2.38.0 以降)。
第四回のまとめ
- Git で fetch/pull や push をする際には tree や commit を活用して「相手が持っていない Git object をやり取りする」仕組みがある
- 相手が持っていない Git object を計算するためにはフロンティア・アルゴリズムや bitmap など様々な手法がある
- 基本的には bitmap が最も効率的だが、状況によっては他の手法が効率的になることもある
Part5: scalability
第五回では Git リポジトリをシャーディングする方法について取り扱う。
一般的なデータベースでは、そのスケールの限界を越えるためにデータベースを一定の条件に従って複数に分割する(シャーディング)。Git で巨大なリポジトリを管理する際にもスケーリングの問題があり、working tree や commit 履歴など Git のデータ構造に内在する特性によって効率的にシャーディングするための戦略を考える。
リポジトリ単位での垂直分割
まず考えられるのは、リポジトリを互いに直接のリンクを持たない小さな複数のリポジトリに分割する方法だ。これは、モノリスをマイクロサービスに分割するのに近い。
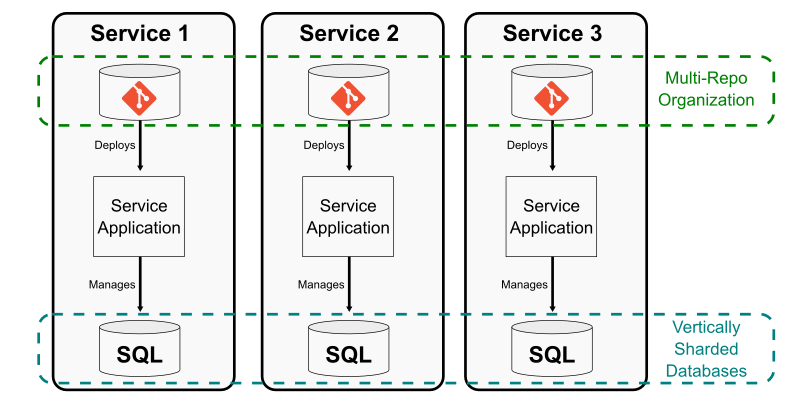
この方法は各マイクロサービスがその開発、テスト、デプロイ、監視の責任においてリポジトリを管理するチームと一体となっている場合に効果的に働く。通常はデータベースもアプリケーション単位で分割され、各マイクロサービス間のインターフェイスによって隠されているため、あるサービスが他のサービスのデータベースを意識することはない。
一方で、この方法には欠点もある。
一つはこれらのリポジトリがどこにあり、アプリケーション間にどのような相互関係があるのかを追跡するのにコストがかかることで、人間の経験やドキュメント化が必要となる。
もう一つは共有の依存先管理が難しくなること。各アプリケーションが依存しているパッケージをパッケージマネージャで更新する際に、依存をどこで使っているのか追跡するのが面倒になる。
submodule による水平分割
Git は submodules という仕組みでリポジトリの work tree 内に別のリポジトリへのリンクを含むことができる。
一つのスーパーリポジトリがあり、その work tree 内の特定のパスに一つまたは複数の submodules を格納する。submodule のパスを示す tree は submodule のリポジトリの commit を指す。
submodules はいくつかの小さなリポジトリを大きなリポジトリにつなぎ合わせることができ、それぞれのリポジトリで互いに異なる commit, ref, blob, tree を管理する。スーパーリポジトリの clone 時には Git はデフォルトで submodules を clone しないため、開発者は必要な submodule だけを選択してローカルにコピーできる。
この方法はデータベースを水平方向にシャーディングしクエリを分散するのに似ている。
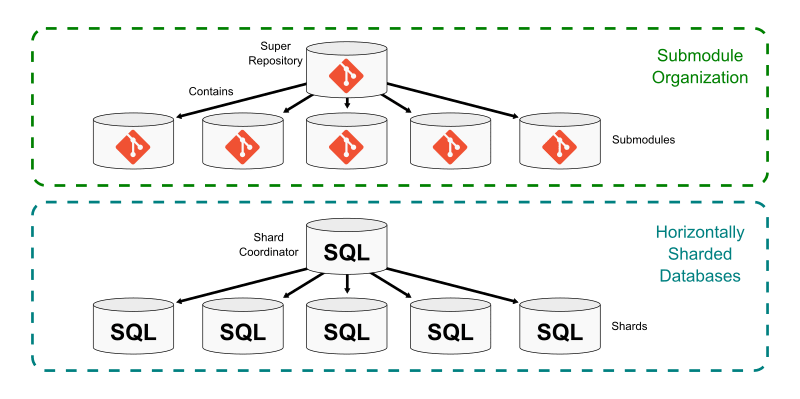
submodules 間の依存関係は CI 等で保証することができる。スーパーリポジトリ側で submodules へのパスを更新しない限り submodule 側の変更はスーパーリポジトリには反映されないため、submodule 側のテストとは別にスーパーリポジトリ側でテストを実行しそれに合格した場合のみ commit を進めることで、安全に開発できる。
一方で、 submodules は独立性を失い、スーパーリポジトリ側の開発が進まないと submodule 側の変更がマージされなくなる。その場合、スーパーリポジトリ側での受け入れを待たずに新たな開発を行うことが難しくなるかもしれない。
また、複数の submodules にまたがってソースに依存関係があるとき、ある submodule のリポジトリで破壊的な変更が加えられるとそのリポジトリに依存する全ての submodules に変更が必要で、かつその変更をスーパーリポジトリ側でも反映しなければならず、調整が必要となる。
submodules は便利ではあるが開発体制やワークフローに工夫が必要となる。有名な例としては Google の repo ツールがある。
monorepo(分割しない)
リポジトリ単位での分割や submodule による分割ではリポジトリは小さくできるものの、複数のリポジトリもしくは submodule にまたがって依存関係があると様々な調整が必要になるという問題がある。
これを避けるための一般的な方法は、リポジトリを一つにする(monorepo: 大規模なシステムをビルド、リリースするのに必要な全てのソースコードを含むリポジトリ)ことである。 monorepo では、同じリポジトリに何を含めるかをどのように選択するかという戦略が重要になる。
最近の流行りはサービス指向アーキテクチャ(SOA)で、アプリケーションの全てのコードが同じリポジトリに含まれるが、各コンポーネントは(monorepo に含まれる他コンポーネントの最新バージョンを使ってテストをした上で)独立した複数のサービスとしてデプロイされる。
この monorepo はリポジトリのシャーディングにおける依存や調整の問題の多くを解決する。
しかし、欠点もある。
一つはリポジトリ全体が非常に速く成長するため、 Git のパフォーマンスに関する高度な機能が必要になることがある。
また、ビルド時にインクリメンタルなビルドをするなど、開発者体験を改善するような特化チームが必要になることもある。ここでは sparse checkout や partial clone のような Git の機能を使ってクライアント側のリポジトリが monorepo と Git object を交換する際のデータ量を削減することが必要になる。
時間による分割
リポジトリが時間と共に大きくなるのであれば、時間を基準にシャーディングする方法も考えられる。
時間ベースのシャードを行う場合は、既存の monorepo をアーカイブし、新しい root commit で新しいリポジトリを作成する。このとき同じ root tree を使う。
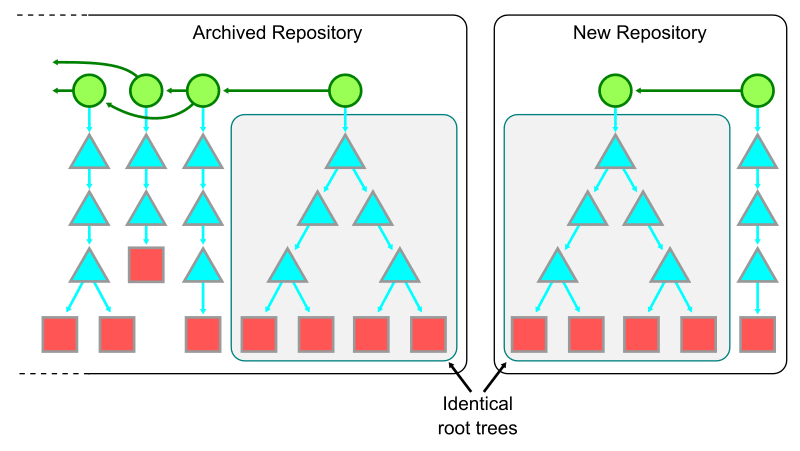
Git object は次のような関係を持っている。
古い monorepo で進行中の作業を新しい monorepo で replay するには、各 topic branch をアーカイブされた古い monorepo の最終 commit で rebase し、git format-patch で patch を生成して新しい monorepo に git am で適用すれば良い。
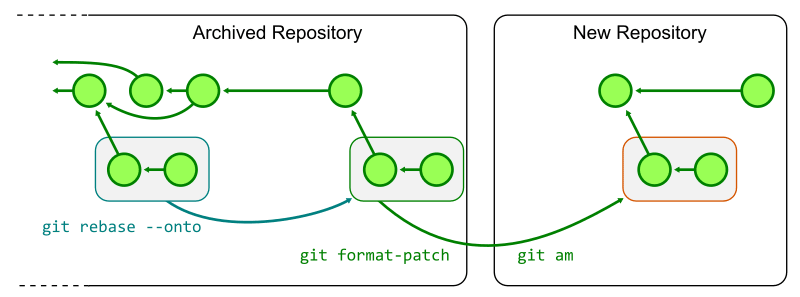
新たな monorepo で作業できるようにするにはビルド、テスト、デプロイ等の様々なワークフローの変更が必要になる。時間ベースのシャードはこのように破壊的な変更を伴うのでコストがかかる一方で、リポジトリの分割や submodule と異なりアーキテクチャの変更が必要なくいつでも(実行しようと思えば)実行できるという利点もある。
時間ベースのシャードが特に効果を発揮するのは commit 履歴に巨大なバイナリファイルがあるなど Git リポジトリのアンチパターンが存在しており、それを切り離せる点にある。一方で、古い commit を調査する必要が生じた際にはシャードを跨いだクエリが必要となる。
シャードを跨いでクエリするにはローカルに各シャードのクローンが必要となる。まずは古い monorepo の .git/objectsへのフルパスを新しい monorepo の .git/objects/info/alternates ファイルに追加する。これにより、新しいリポジトリから古いリポジトリの object を見ることができる。
次に git replace を使い、新しい root commit の内容を古いリポジトリの commit と入れ替えるように指示する。これらの commit は同じ root tree を共有しており、 commit の親が変更され、リンクを伝って以前の commit を参照することができる。
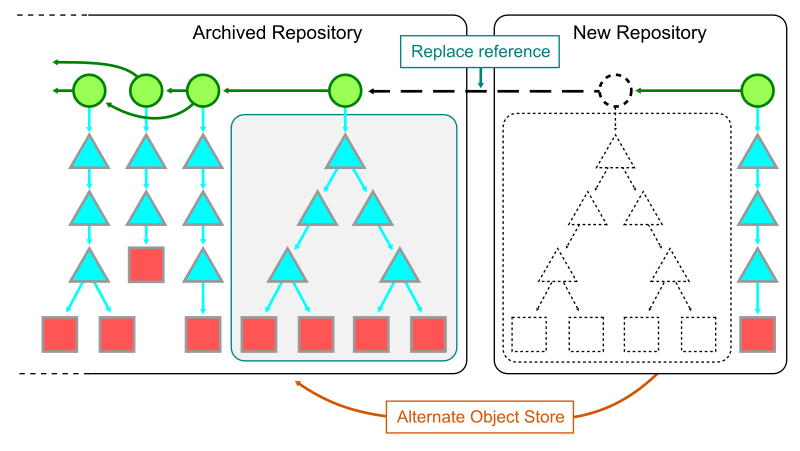
ただし、この replace による commit 履歴の参照では第二回の commit-graph のような機能が使えないため、パフォーマンスが低い。そのため、シャードを跨いだ参照は重要な場合のみ行うべきである。
データの Offloading
データベースが大きくなったとき、その一部のデータがあまり頻繁にアクセスされないのなら、より安価な(だが性能が低い)ストレージに移動させたくなる。
Git の場合は部分的 clone を安価なストレージに保管するといった方法が考えられる。
git clone --filter=blob:none を使うと origin サーバーから commit とそこから到達可能な tree を全てダウンロードするが、 blob はダウンロードしない。これにより最初の clone をより高速にすることができる。一方で、 Git が git checkout など blob を必要とするときネットワーク上で通信する必要がある。
一方で、このような効率化は clone 時にしか役に立たず、実際には fetch や pull によってローカルリポジトリが大きくなっていくという問題があるので効果は薄いかもしれない。他の方法としては、予め IT 部門がマシンに Git object を書き込んでおくとかローカルネットワーク上にリポジトリを置くなどで高速化することはできる。
使用頻度の低い object を切り離すという方法もある。何が使用頻度の低い object かを決めるには、 commit の履歴を利用すればよい。commit 自体はそれほど大きな object ではなく Git の多くの機能で役に立つのでローカルに保持しておき、最近の root tree やそこから到達可能な object もローカルに残しておく。これにより、古い blob や tree を減らしていくといったことも考えられる。
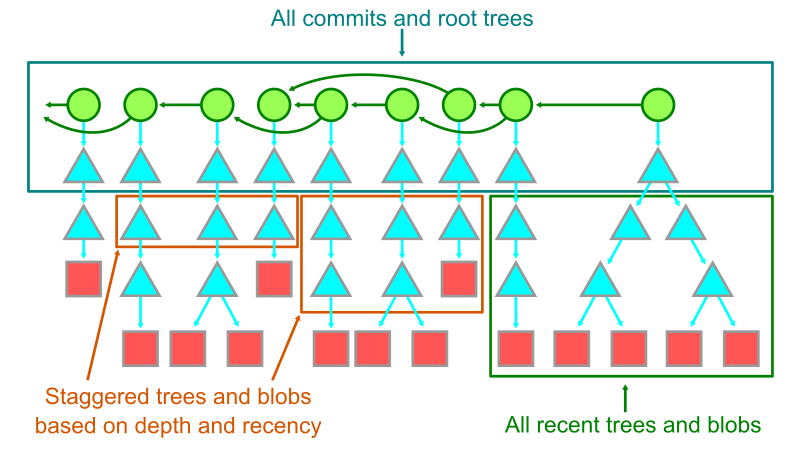
(GitHub 社の連載記事の著者である Stolee さんの言)このようなストレージへの offload を行う既存のツールは無いようだが、大規模な monorepo の管理に役立つと思うので自分で作ってみてください。
第五回のまとめ
- Git リポジトリを分割する手段はいくつかある
- 比較的かんたんなのはリポジトリ単位での垂直分割か submodule による水平分割
- monorepo や時間による分割はコストがかかるが、効果は大きい
その他の Git 関連記事
感想
一連の GitHub 社の記事を読んだ結果として、自分自身に以下の影響があった。
- Git コマンドへの理解が向上した
- 自分の中でデータ構造とアルゴリズムと heuristic の価値が上がった
- バージョン管理システム自体について考えるようになった
1. Git コマンドへの理解度が向上した
連載を読む前の自分の Git 理解度は add や commit など基本的なコマンドを問題なく使える程度で、困ったときには Google で「git commit 取り消す」のような検索をしていた。
しかし本連載記事で Git の背後にある概念やデータモデルを学習したことで、個々のコマンドの裏側で実際に何が起きているのかを想像し、コマンド実行後に意図通りの挙動となっているかを確認することができるようになった。
例えば git reset について。ドキュメントでは Reset current HEAD to the specified state と書いてあって意味がよく分からなかったのだが、Git のデータモデルを念頭に置くとこの文の意味が理解できる。
Git では、ある時点のリポジトリのスナップショットを commit として記録している。その commit を示す参照として branch や tag がある。HEAD は現在作業している branch を示す参照(参照を指しておらず commit を直接参照している場合は detached HEAD と呼ばれる)なので、reset は指定した引数に従い、(working tree や index に対して)現在の HEAD の参照先を適用するコマンドということになる。
例えば git reset HEAD -- README.md は HEAD が指す branch の README で working tree 及び index(staging)の README を上書きする。
2. 自分の中でデータ構造とアルゴリズムと heuristic の価値が上がった
普段の仕事でプログラムを書くときはクライアントからの入力をサーバーで受け取って検証や加工をしてデータベースに格納し結果をクライアントに返すような一般的な Web アプリケーションを書いていて、あまり高度なアルゴリズムに触れる機会はない。
もちろん、ループの中でループするとか 1+N クエリを発行するといったような明らかに悪いコードは書かないようにしているが...
一方で、Git では object の保存や取得、commit 履歴やファイル変更履歴の探索、pull や push などあらゆるワークフローにおいて様々なアルゴリズムや heuristic が使われている。例えば、
- packfile のどこに object が含まれているかは object の SHA-1 ハッシュの先頭2文字をインデックスとする fanout テーブルを作る
- ハッシュはランダムであることが期待できるので、均等に分散しインデックス効率がよい
- object の探索は単純な binary search だが、この fanout テーブルによって探索範囲を 1/256 に削減できる
- ある commit から別の commit に親を辿って到達できるかどうかを探索する際は、深さ優先探索で経路を探す
- Git の履歴は first parent に対して直線的であり、世代番号を使うことで古い commit が含まれる探索空間を削減できるので、深さ優先探索が向いている
- 更に、 commit の親子間の参照を事前に計算して保存しておくことで commit object のパースにかかるコストを削減できる
- pull/push でローカル・リモート間の同期を行うとき、最も高い効率ができる bitmap を使い、 bitmap が存在しないケースも考えて効率が期待できる順に fallback していく
現実の問題をコンピューターで解決する手段としてのデータ構造やアルゴリズム、そして対象の特性から導かれる heuristic が自分にとって身近なソフトウェアでも至るところで使われているという学びがあった。
なお、この連載記事では Git が採用している merge アルゴリズムについては触れられていないが、それにも興味が出てきたので調べてみたい。
3. バージョン管理システム自体について考えるようになった
今まで当然のように Git を使っていて、他の選択肢は考慮したことすらなかった。
しかし Git の内部への理解が進んだことで、バージョン管理システムについて考えるようになった。
Git はソースコードを管理するために開発されており、その特性やデータのアクセスパターンに応じた機能があり、それを支えるデータ構造やアルゴリズム、heuristic がある。もしもバージョン管理の対象となるソースコード(やその他のテキストファイル)に Git が向いていない特性があったら、他の VCS を使うときが来るかもしれない。
Git 以外の分散 VCS としては Pijul がある。Rust で書かれている。Pijul そのものは GPL-2.0 ライセンスで提供されている OSS だが、開発者は Nest という Pijul 版 GitHub のような SaaS を開発、運用しており将来的にこれで収益を得る予定に見える。また、Pijul のベースとなっている libpijul (libgit2 みたいなやつ?)を商用ライセンスで提供することも可能なようだ。
ちなみに Pijul は中南米の熱帯の乾燥地帯に生息するカッコウの一種のメキシコ名で、数組のつがいで協力して巣を作り、同じ巣に卵を産み共同で子育てをする習性があるらしい。Git と同様に複数の人間が分散してファイルの修正を進め必要に応じて統合することができる一方で、Git とは異なるデータモデルを採用している。
Git で 3-way merge する際その対象となる2つの commit と merge-base となる commit は当然ながら全てスナップショットであり、コンフリクトを解消する際にその間の文脈は全て失われる可能性がある。コンフリクトの発生を前提とすると Pijul のようなパッチベースのデータモデルの方が優れているように見える。
ソフトウェア開発以外の分野でも Pijul の方が優れている場合もあるかもしれない。例えば法令文書の変更管理は Git よりも Pijul の方が向いてそうだ。というのも、法令のような一つの巨大ファイルを複数人で並行して編集するときはコンフリクトがよく発生しそうだからだ。法令の場合は標準 XML と互換性があり人間が読み書きしやすいフォーマットが必要になるという別の問題があるが...(参考)
Discussion