はじめに
こんにちは、植野です。この記事では、Datadogを使って基本的なシステムメトリクスを監視する方法と、ホストごとに1つのクエリで監視する方法について解説します。Datadogは強力な監視ツールですが、日本語のドキュメントが少ないので、この記事が皆さんのお役に立てれば幸いです。
メトリクス監視について
メトリクス監視は、システムの安定性と性能を維持する上で極めて重要です。Datadogを使えば、複数のホストを一元的に監視しすることができます。今回は、基本的なロードアベレージ、メモリ使用率、ディスク使用率の監視に焦点を当てます。Datadog Agentのインストールは省略します。
1. ロードアベレージの監視
ロードアベレージは、システムの負荷を示す重要な指標です。しかし、単純なロードアベレージの値だけでは、マルチコアシステムの実際の負荷を正確に把握できません。そこで、CPUのコア数を考慮したモニタリングを行います。
クエリ
system.load.1{host:*} by {host} / system.cpu.num_cores{host:*} by {host}
このクエリは、各ホスト(by {host})の1分間のロードアベレージ(system.load.1)をCPUコア数(system.cpu.num_cores)で割ることで、相対的な負荷を計算します。
閾値
CPUコア数の80%以上の負荷でアラート、60%以上でワーニングを設定しています。

設定例

2. RAM使用率の監視
RAM使用率の監視は、アプリケーションのパフォーマンスと安定性を確保するために不可欠です。
クエリ
(system.mem.total{host:*} by {host} - system.mem.usable{host:*} by {host}) / system.mem.total{host:*} by {host}
このクエリは、各ホストの全RAM容量(system.mem.total)から使用可能なRAM容量(system.mem.usable)を引き、それを全RAM容量で割ることで使用率を計算します。
注意が必要なのが、system.mem.usedというメトリクスで、名前から使用されているメモリ量が分かりそうですが、キャッシュも含まれているのでそのままでは使いづらいです。クエリも複雑になるので、system.mem.usableを利用するのが良さそうです。
閾値
全容量の80%以上の利用率でアラート、60%以上でワーニングを設定しています。
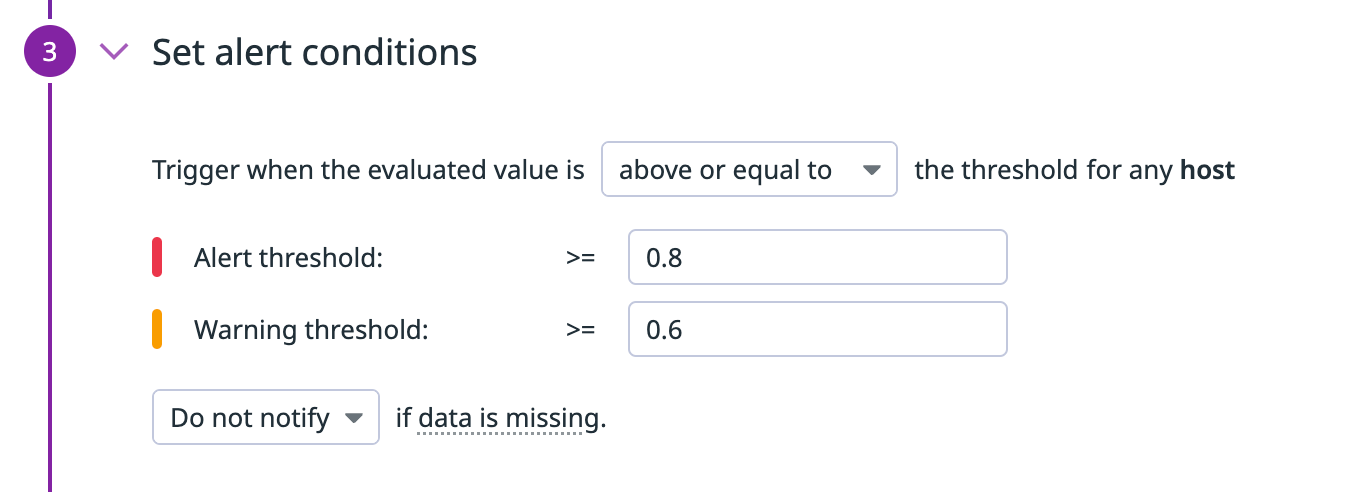
設定例

3. ディスク使用率の監視
ディスク容量の監視は、データ損失やアプリケーションの停止を防ぐために重要です。
クエリ
system.disk.used{host:*,!device:*loop*,!device:*snap*,!device:*containers*} by {host,device} / system.disk.total{host:*,!device:*loop*,!device:*snap*,!device:*containers*} by {host,device}
このクエリは、各ホストの使用中のディスク容量(system.disk.used)を全ディスク容量(system.disk.total)で割ることで、使用率を計算します。
ループバックデバイスやLXDコンテナのディスクは!演算子で除外しています。
閾値
全容量の80%以上の利用率でアラート、60%以上でワーニングを設定しています。

設定例

ホストごとの監視
検索してもなかなか見つからなかったのですが、ホストごとに監視するには、各クエリの項の末尾にby {host}をつける必要があります。これにより、全てのホストを個別に監視しすることができます。
同様にデバイス(by {device})やサービス(by {service})ごとに監視したり、組合せ(by {host,device})ごとに監視したりすることもできます。
まとめ
Datadogを使ったメトリクス監視は、クエリを活用することで、監視対象の多寡を問わず効率よくかつ柔軟性に設定できる、優れたサービスだと思います。
もっと良いやり方があればぜひ教えてくださいね。

Discussion