はじめに:Difyで画像生成機能を実装する
AIアプリ開発プラットフォーム「Dify」では、OpenAIのGPTシリーズやGoogleのGeminiなど、様々な最先端のLLM(大規模言語モデル)を自由に選択して利用できます。しかし、これらはあくまでテキスト生成に特化しており、LLM単体で画像を生成することはできません。
ですが、Difyの強みはそれだけではありません。プラットフォーム上で「DALL-E 3」や「Stable Diffusion」といった画像生成AIツールを呼び出すことも可能です。
この記事では、これら画像生成AIをDifyのワークフローに組み込むことで、ユーザーの指示に基づいた画像を生成し、チャットの応答やアプリの機能として実装する方法を具体的に解説していきます。
1. テキストを操る「LLM」と、絵を描く「画像生成AI」
Difyで高度なAIアプリを構築する上で、中核となるAIモデルの役割を理解することは非常に重要です。ここでは、文章を生成する「大規模言語モデル(LLM)」と、画像を生成する「画像生成AI」の根本的な違いについて、より詳しく解説します。
画像生成AIとは? ― テキストから画像を”描く”技術
画像生成AIは、テキストで与えられた指示(プロンプト)を解釈し、それに応じた全く新しい画像をゼロから作り出すことに特化したAIです。その心臓部には、主に「拡散モデル(Diffusion Model)」と呼ばれる技術が使われています。
拡散モデルの仕組み(イメージ)
-
学習フェーズ(壊す過程):
- まず、AIは大量の画像データ(例:「猫の写真」)に少しずつノイズを加えていき、最終的に完全なノイズ(砂嵐のような画像)にする方法を学びます。
- この「画像を段階的に壊していく過程」を何百万、何億もの画像とテキストのペア(例:「走る犬」「青い空と白い雲」)で繰り返し学習します。
-
生成フェーズ(復元する過程):
- ユーザーが「夜空に輝くオーロラ」というプロンプトを入力します。
- AIは、まずランダムなノイズ画像からスタートします。
- そして、学習した知識を元に、「夜空に輝くオーロラ」というテキストの指示に合致するように、ノイズを段階的に取り除いていきます。
- この「ノイズから意味のある画像へ復元する」プロセスを経て、最終的にプロンプトに沿ったユニークな画像が生成されていきます。
このようにして画像生成AIは、単に既存の画像を切り貼りしているのではなく、テキストの意味を理解し、それを元にピクセルレベルで画像を再構築している、まさに「デジタルな画家」と言える存在です。
LLMと画像生成AIの決定的違い
両者は「AI」という点で共通していますが、その目的、学習データ、そして得意なことが根本的に異なります。
| 比較項目 | 大規模言語モデル(LLM) | 画像生成AI |
|---|---|---|
| 主な目的 | 言語の理解と生成。テキストの文脈を読み解き、論理的で自然な文章を作り出すこと。 | 視覚的コンテンツの創造。テキストで表現された概念や情景を、具体的なビジュアルとして表現すること。 |
| モデル | Transformerモデル | 拡散モデル(Diffusion Model) |
| 学習データ | 膨大なテキストデータ。(Webサイト、書籍、論文など) | 膨大な「画像」と「その画像を説明するテキスト」のペアデータ。 |
| 処理プロセス | 次に来る単語を予測することで、文章を生成していく。「単語」の連なりとしての意味を処理する。 | テキストの意味に対応するように、ノイズから画像を復元していく。「ピクセル」の集合体としてのビジュアルを処理する。 |
| 得意なこと | 要約、翻訳、質疑応答、文章作成、対話、プログラミングコード生成 | アイデアの視覚化、デザイン案の作成、イラスト生成、写真のようなリアルな画像の作成 |
| 思考のタイプ | 論理的・記号的思考。言葉と言葉の関係性を扱う。 | 感覚的・空間的思考。色、形、構図といった視覚的要素を扱う。 |
このように、LLMが「言葉の世界」の専門家であるのに対し、画像生成AIは「ビジュアルの世界」の専門家です。Difyのワークフローでは、この異なる能力を持つAIたちを組み合わせることができます。例えば、LLMにアイデアを文章で出してもらい、その文章を元に画像生成AIに具体的なイメージを描かせる、といったこともできます。
2. Difyワークフローで画像生成AI(DALL-E 3)を動かす方法
ここからは、Difyで画像生成アプリを作るための具体的な手順を、DALL-E3を用いて詳しく解説します。
前提条件
画像生成AIの「DALL-E 3」と「Stable Diffusion」を利用するにはAPIキーが必要です。これがないとDifyと連携できません。
- DALL-E 3のAPIキー取得方法(OpenAI APIキー):https://platform.openai.com/account/api-keys
- Stable Diffusion APIキー取得方法(Stability AI):https://platform.stability.ai/account/keys
実践:ワークフローで画像生成アプリを構築する
画像生成の仕組み(ワークフロー)を構築していきます。ユーザーが「〇〇の画像を作って」と指示したら、DALL-E 3が画像を生成して返す、という一連の流れを設計図のように作っていきます。
-
アプリの作成を開始
- Difyのトップページから「最初から作成」をクリックします。
- アプリの種類で「チャットフロー」を選び、アプリ名(例:画像生成Bot)を入力して「作成」ボタンを押します。
-
DALL-E 3ツールを追加
- ワークフロー編集画面が表示されたら、「開始」ノードの右側にある「+」ボタンをクリックし、メニューから「ツール」を選択します。
- ツール一覧から「dalle3」を見つけてクリックします。これで、ワークフロー上にDALL-E 3ノードが追加されます。
-
各ノードの設定と接続
- 各ブロック(ノード)の役割を設定し、それらを線で繋いで処理の流れを作ります。
-
① DALL-E 3ノードの設定
- 追加した「dalle3」ノードをクリックして選択します。
- 画面右側に設定パネルが表示されるので、「prompt」の入力欄には変数リストから「開始/{x}sys.query」(ユーザーからの入力)を選択します。これで、ユーザーがチャットで入力した言葉が、そのままDALL-E 3への「描画指示」になります。
-
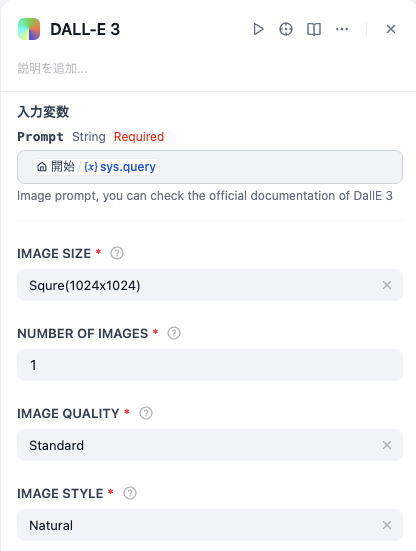
② 回答ノードの設定
- 次に、「回答」ノードをクリックして選択します。
- 「応答」欄をクリックし、「DALL-E 3/ {x}files」(DALL-E 3が生成した画像情報を格納したファイル)を選択します。DifyがこのファイルからURLを取り出し、自動的に画像としてチャット画面に表示してくれます。
-
③ ノードを線で繋ぐ
- 最後に、各ノードの丸い部分をドラッグ&ドロップして、処理の順番通りに線で繋ぎます。
- 「開始」→「dalle3」→「回答」の順に繋ぎます。
ワークフロー全体図

DALL-E 3の設定
回答ノードの設定
-
公開とテスト
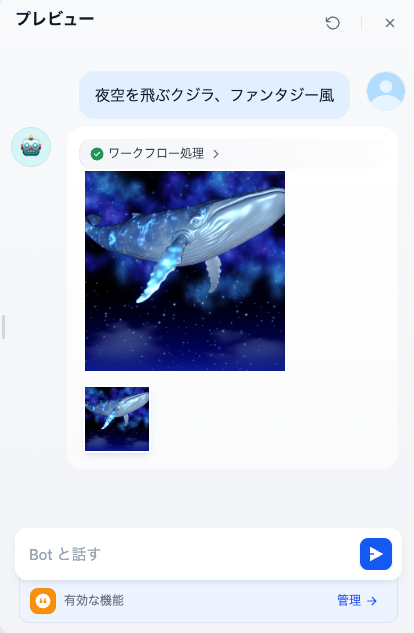
- 「プレビュー」を選択するとプレビュー画面が表示されるので、チャット入力欄に「
夜空を飛ぶクジラ、ファンタジー風」など、生成したい画像の内容を入力して送信してみましょう。 - 無事に画像が生成されれば成功です。
- 「プレビュー」を選択するとプレビュー画面が表示されるので、チャット入力欄に「
実際のイメージ
3. DALL-E 3を活用した具体的な応用例【コピペで使えるプロンプト付き】
基本的な使い方がわかったところで、次は一歩進んだ応用例をご紹介します。LLM(言語モデル)を組み合わせることで、より便利な画像生成アプリを作ることができます。ここでは、投稿したいテーマを一つ入力するだけで、SNS投稿用の画像と文章をセットで全自動生成する、時短Botを作成します。
応用例:SNS投稿(画像+テキスト)をワンクリックで自動生成
完成イメージのワークフロー

実装ステップ:
このワークフローは少し複雑に見えますが、やっていることは「①文章を作る流れ」と「②画像を作る流れ」を同時に進め、最後に合流させているだけです。
-
ワークフローの分岐
- 「開始」ノードの右側の「+」をクリックし、並列に「LLM」ノードを追加します。これにより、処理を分岐させることができます。
-
【分岐1】投稿文を作成するPlaintext
- 追加した1つ目のLLMノードを選択し、プロンプト欄に以下の指示文をコピー&ペーストします。
# 命令書 あなたはプロのSNSマーケターです。 ユーザーから入力されたテーマに基づき、読者の興味を引くような魅力的な投稿文を150字程度で作成してください。 文の最後には、関連性の高いハッシュタグを3つ付けてください。 # テーマ (「**開始/{x}sys.query**」を選択) -
【分岐2】画像を生成するPlaintext
- もう一方「LLM」ノードには、後続に「dalle3」ノードを追加します。(LLMで画像生成用の指示文を作り、それをDALL-E 3に渡すためです)
- LLMノード(画像指示文用)には、以下のプロンプトを貼り付けます。
# 命令書 あなたは優秀なアートディレクターです。 ユーザーから与えられたテーマを元に、SNSで目を引くような、高品質な画像を生成するための英語のプロンプトを1つだけ作成してください。 # 制約条件 ・プロンプトは写真のようにリアルな「photorealistic」スタイルで作成してください。 ・プロンプト以外の余計な説明は絶対に出力しないでください。 # テーマ (「**開始/{x}sys.query**」を選択)- 2つ目のdalle3ノードの設定は、直前のLLMノードの出力を受け取るように設定します。(「LLM 2/{x}text」 などを選択)
-
回答ノードで合体させる【最重要ポイント】
- 最後に「回答」ノードですべての出力を合体させます。
- 回答ノードを選択し、右側の設定パネルで以下のように両方の変数を入力します。
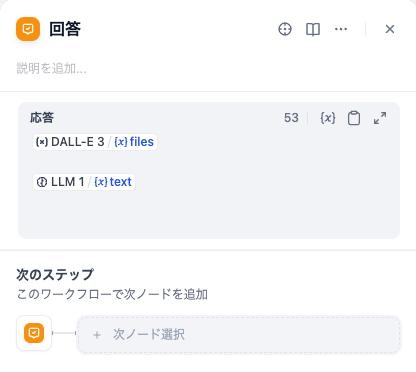
- まず、「応答」欄で 「DALL-E 3/ {x}files」(画像)を選択します。
- 次に、改行してから、 「LLM 1/{x}text」(投稿文)を選択します。
(※ 「LLM 1/{x}text」 や 「LLM 2/{x}text」 の番号は、ワークフロー内のLLMノードのIDによって変わる場合があります)
これで完成です。「新発売の抹茶ドーナツ」のようにテーマを入力するだけで、ドーナツの美味しそうな画像と、気の利いた紹介文&ハッシュタグがセットで生成されます。

まとめ
本記事では、Difyのワークフローを用いて、テキスト生成に留まらない画像生成AIの活用方法を解説しました。
- LLMはテキスト、DALL-E 3のような画像生成AIは画像の生成に特化している。
- Difyを使えば、
開始→DALL-E 3→回答という簡単なノード接続で画像生成アプリをノーコードで開発できる。 - LLMと組み合わせることで、画像とテキストの同時出力やプロンプトの自動生成や対話形式での画像カスタマイズなど、高度で実用的な応用が可能になる。
Difyと画像生成AIの連携は、アイデアを視覚的な形で簡単に実現できる強力なツールです。ぜひ、この記事を参考に、自分だけの画像生成アプリケーションを作成してみてください。

株式会社アップグレードは、エンタープライズ企業の生成AI活用における戦略立案から実装までを一貫して支援する専門企業です。本ブログでは、AI Workflow設計、AI Agent開発、RAGシステム構築、各種LLMの実践的活用手法など、技術的知見を共有します。| Dify公式パートナー
Discussion