こんにちは!この記事では、Difyで表形式の文字列を出力し、Excelに貼り付けられるようにする方法について解説します。
Difyで開発を進めていると、「Excel形式でデータを出力したい」といったニーズが出てくることがあります。しかし、現時点でDifyにはExcelファイルを直接出力する標準ブロックは備わっていません。
一部プラグインを使えばExcelファイルの出力は可能ですが、開発環境によってはセキュリティ上の理由から外部プラグインの使用が制限されるケースも少なくありません。
参考:https://marketplace.dify.ai/plugins/bowenliang123/md_exporter?language=ja-JP
※こちらのアドインはソースコードの公開やデータ収集を行わない旨が明記されていますが、開発者が個人であることから、企業利用には不向きと判断されることがあります。
そのため、Excelが表と認識可能な形式の文字列をDifyから出力させ、それをコピー&ペーストでExcelに貼り付けるのが現実的な解決策です。以下でその具体的な方法を紹介します。
表として扱える主な文字列
表を表す際に使われる文字列は主に4種類あります。
TSV形式
Excelに表として直接貼り付けることができます。
文字列内の\t(半角タブ)を列の変更、\n(改行)を行の変更として読み取り、入力のような文字列をExcelに貼り付けると出力のように表示されます。
入力


出力

CSV形式
こちらもExcelに表として直接貼り付けることができます。
文字列内の,(カンマ)を列の変更、\n(改行)を行の変更として読み取り、入力のような文字列をExcelに貼り付けると出力のように表示されます。
入力


出力

HTMLTable形式
こちらもExcelに表として直接貼り付けることができます。
プログラミング言語のHTMLを利用して表を作成します。一目で構造が分かりやすいのが特徴的です。
枠線や見出しなど表の装飾を簡単に行うことが可能です。
入力のような文字列をExcelに貼り付けると出力のように表示されます。
入力

出力

MarkdownTable
Excelにテキスト抽出ブロックを用いた際の出力形式です。これはExcelにそのまま表として貼り付けることはできません。
文字列内の|(縦線)を列の変更、\n(改行)を行の変更として読み取ります。


※Markdown TableをExcelに貼り付け可能にするアドインも存在します。
https://www.nuits.jp/entry/copy-to-markdown-2_0_0_0 (こちらのアドインはソースコードの公開を行っていますが、開発者が個人であることに留意して下さい。)
セル内での改行の扱いについて
TSV・CSV・HTMLlTable形式で出力する際、セル内の改行と行の改行を区別する必要があります。
CSV/TSV形式
CSV/TSV形式では、””にはさまれている\n(改行)はセル内の改行として扱われます。
つまり出力のような表を貼り付けたければ、入力のような文字列を挿入するということになります。
出力

入力


HTMLTable形式
HTMLTable形式では、<br style="mso-data-placement: same-cell;">がセル内の改行として扱われます。
通常のHTMLTableでは<br>のみでセル内の改行を表しますが、<br>のみでExcelに貼り付けると、普通の改行情報と読み取られてしまうので注意が必要です。
つまり出力のような表を貼り付けたければ、入力のような文字列を挿入するということになります。
なお、入力ではstyleタグに<br style="mso-data-placement: same-cell;">の情報を書き込むことでコードを簡略化しています。
出力

入力

Excelへの貼り付け方法
まず注意するべきなのは、出力されたタブや改行情報が特殊文字として出力されているかです。
文字列として出力されている場合、表として貼り付けることはできません。しっかり文字列リテラル内の特殊文字として出力されているかを確認しましょう。
またDifyの出力をExcelがうまく読み取ってくれずに、完成した文字列をコピーし、そのままペーストしても一つのセル内に文字列が収まってしまうことがあります。
そのような場合には以下の手順で貼り付けを行ってください。
TSV・HTMLTable形式
1.セルを左クリックした後、「形式を選択して貼り付け」を選択

2.「Unicodeテキスト」での貼り付けを指定(「テキスト」でも可)

※1.2の手順はAlt→E→S→選択しEnter(ショートカットキー)でも行えます。
CSV形式
TSV・HTMLTable形式と同様に、まずはセルを左クリックした後、「形式を選択して貼り付け」を選択し、「Unicodeテキスト」での貼り付けを指定します。しかし、このままでは改行情報は反映されていますが、列の情報が反映されていません。
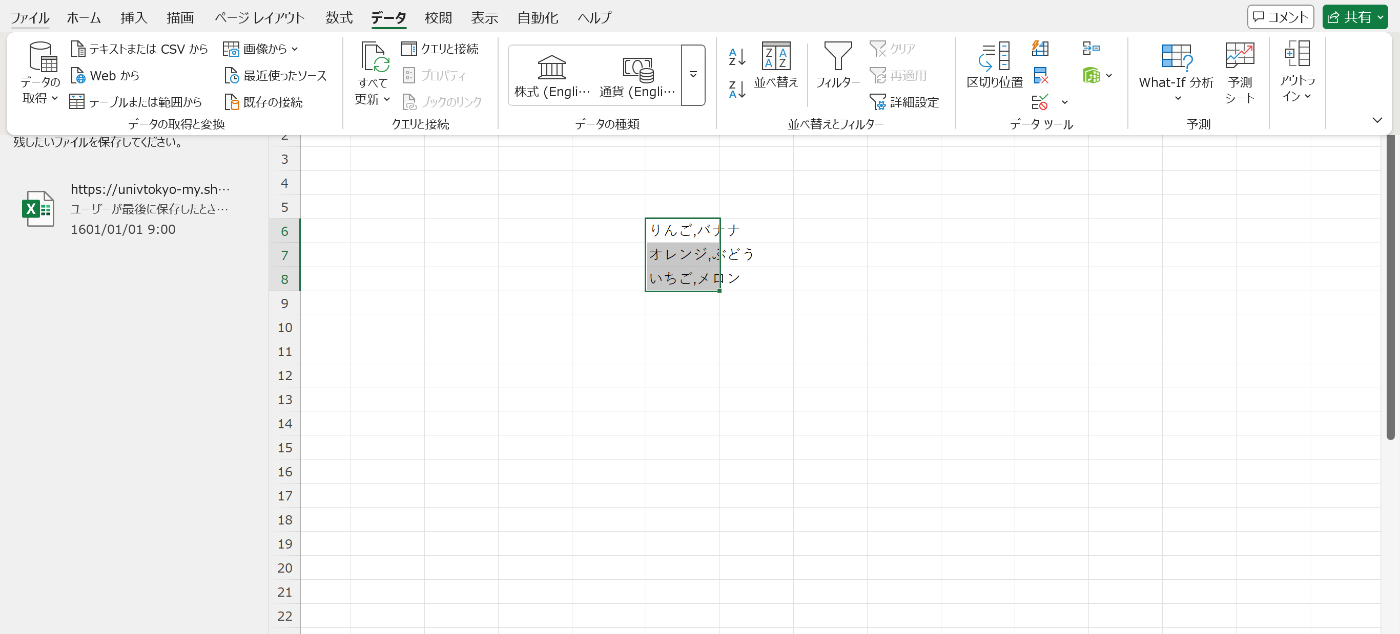
1.表が選択されたままの状態で、「データ」の「区切り位置」で「コンマやタブなど~」を選択します

2.「コンマ」にチェックを付けます
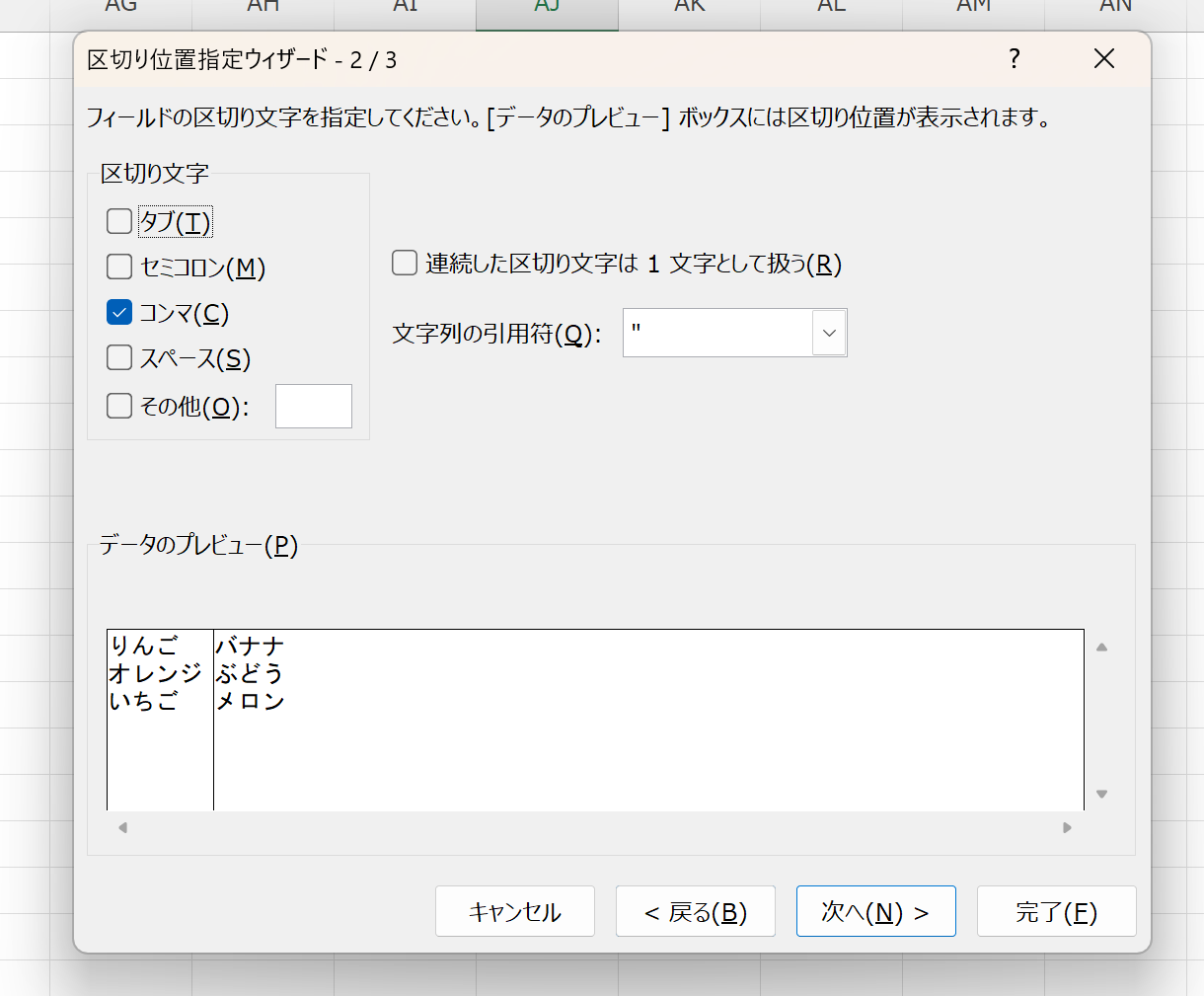
これで列の情報が反映されます。
TSV形式が貼り付けるだけでよいのは、この区切り位置のデフォルト設定がタブだったからです。
実際にDifyを触る
今までの解説を踏まえ実際にDifyを触っていきたいと思います。
HTMLTable形式はコードブロックでの編集がTSV・CSV形式より複雑であること、CSV形式はTSV形式の半角タブをカンマに変えたものであることから、以降の説明はTSV形式として出力する場合を扱います。
PDFデータから表を作成しExcelに貼り付ける
PDFの情報をExcelにまとめたい時どのようなコードブロックを書けばよいのでしょうか。
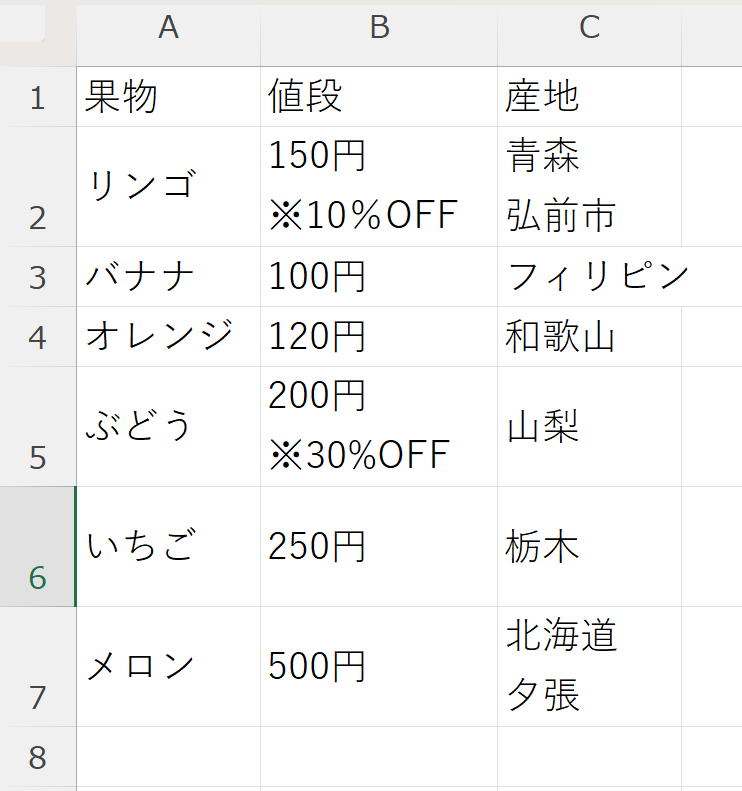
今回は試しに、(数字)ごとで文章を区切り表にまとめてみたいと思います。また※でセル内改行を行います。
入力例

Difyのフローは以下の通りです。
テキスト抽出ブロック(PDFテキストをテキスト抽出)→コードブロック(テキスト整理&表化)
Difyフロー

コードブロックの内容は以下の通りです
import re
def main(arg1: str) -> dict:
# 1. 改行をすべて削除(\r\n)
text = arg1.replace('\r', '').replace('\n', '')
# 2. (数字)の直前に\n、直後に\tを挿入
text = re.sub(r'\((\d+)\)', r'\n(\1)\t', text)
# 3. 各グループをリストとして抽出
groups = text.strip().split('\n')
processed = []
for group in groups:
if not group:
continue
if '\t' in group:
key, content = group.split('\t', 1)
else:
key, content = group, ''
# 3. ※がある場合は、文章を""で囲み、※の前に\nを挿入(複数対応)
if '※' in content:
# 「※」の前に改行を入れ、トリム
content = re.sub(r'※', r'\n※', content)
content = f'"{content.strip()}"'
else:
content = content.strip()
processed.append(f"{key}\t{content}")
# 4. グループを一つにまとめる(TSV形式)
result_text = '\n'.join(processed)
return {
"result": result_text
}
流れとしては
改行情報を抜く→(数字)の直前に\n、直後に\tを挿入→グループ分けをしセル内改行に対応
です。
なお、コードブロックを扱う際は以下の点に注意しましょう
- PDFをテキスト抽出すると改行情報が\nではなく\r\nとして出力される場合があります。これはWindowsのシステムで使用される改行コードのようです。出力を見て改行がどのように出力されているか確認しましょう
- 関数の名前がmainであること(コードブロックは関数名がmainでないと基本動作しません)
- 入力変数名と出力変数名がコードブロック内のものとあっていること
出力をExcelに貼り付けたもの

入力されたPDF情報が整理された形で出力されていることが分かると思います。
※(1)→-1のような変換が起きているのは、Excelの自動変換によるものです。
(1)と出力したい場合は、対象のセル範囲を選択し、「ホーム」→「数値」→「セルの書式設定」から表示形式を文字列にするか、(数字)前に’(シングルクォート)を挿入するコードを追加してください。
テキスト抽出ブロックで抽出したExcelデータを再びExcelに貼り付けられる形にする
先述のとおり、テキスト抽出ブロックで抽出されたデータはExcelに貼り付けることのできないMarkdowntableなため、どこかでMarkdowntableをTSV形式に変える必要があります。そのコードについてここでは解説します。
今回は試しに、Excelファイルから特定の列を抽出するアプリを作ってみます。セル内改行情報も引き継ぐようなアプリにします。
入力例
Difyのフローは以下の通りです。
テキスト抽出ブロック(Excelをテキスト抽出)→コードブロック(列抽出&表化)
Difyフロー

コードブロックの内容は以下の通りです。
def main(arg1: str) -> dict:
cell_line_break = '\n' # Excelでセル内改行として認識される通常の改行コード
lines = arg1.strip().split("\n")
output_rows = []
current_processing_row = [] # 現在処理中の行の2列目と3列目の内容を保持するリスト
for line in lines:
line = line.strip()
# Markdown table 形式からセルごとの配列に変換
parts = [cell.strip() for cell in line.split("|")][1:-1]
# 区切り線を除外
if all(all(c in ": -" for c in cell) for cell in parts):
continue
# セル内改行の処理
# データが格納されていると期待される列の数をチェック
if len(parts) > 2:
current_col1 = parts[0] # 1列目の内容も取得
current_col2 = parts[1]
current_col3 = parts[2]
# この行のいずれかの列が空(または空白のみ)で、かつ他の列にデータがある場合
# (ただし、全列が空の場合は含めない)
is_potential_continuation = (
(not current_col1) or (not current_col2) or (not current_col3)
) and (
current_col1 or current_col2 or current_col3 # 全列が空ではないこと
)
if current_processing_row: # 前に処理中の行がある場合
if is_potential_continuation:
# 2列目と3列目の内容を前の行の該当セルに結合
# 現在の行の2列目と3列目に内容があれば、前の行に結合
if current_col2:
current_processing_row[0] += cell_line_break + current_col2
if current_col3:
current_processing_row[1] += cell_line_break + current_col3
else:
# 前の行に追加情報が結合されず、新しい通常のデータ行が始まる場合
output_rows.append(current_processing_row)
current_processing_row = [current_col2, current_col3]
else:
# 初めてのデータ行の場合
current_processing_row = [current_col2, current_col3]
# ループ終了後に残っているデータを追加
if current_processing_row:
output_rows.append(current_processing_row)
# TSV形式で出力
tsv_output_lines = []
for row_parts in output_rows:
processed_cells = []
for cell in row_parts:
# セル内に改行を含む場合、Excel対応のためダブルクォートで囲む
if cell_line_break in cell:
processed_cells.append(f'"{cell}"')
else:
processed_cells.append(cell)
tsv_output_lines.append('\t'.join(processed_cells))
return {
"result": "\n".join(tsv_output_lines).strip()
}
MarkdownTable形式をセルごとの配列に変換→セル内改行の処理→\nと\tを持ちいてTSV形式に変換という処理を行っています。
詳しくは以下の注意点のところで述べますが、セル内改行の処理は、直後の行に空白のセルがあるかどうかという条件で行っています。
出力をExcelに貼り付けたもの

セル内の改行情報が保たれ、2,3列目のみが抽出されていることが分かります。
注意点
テキスト抽出ブロックは、出力がMarkdownTableであり、以下のようにExcelのセル内の改行情報がまるで別の行のように出力されてしまいます。
つまり、すべての列でセル内改行が行われている行がある際、それがただの改行とセル内改行のどちらなのか、判断がつかなくなってしまうというところに注意が必要です。
今回は次の行で空白のセルが1つでも存在する場合、その行をセル内改行のためのものと判断し、直前の行と\nを介して中身を結合し、全体を""で囲むようなコードを書きました。しかしこれではすべての列でセル内改行を行っている列がある場合、うまく処理がされません…
対応策としては、入力データで、セル内改行を行い新しく情報を付与する際は改行直後に※を置く→PDF処理の章のように※を基準にセル内改行を判断するなどの方法が考えられます。
まとめ
今回はDifyでExcelの表形式の出力を行うやり方を解説していきました。
今回扱った例は非常に簡単なものですが、本記事で記した知識を基にフローを作成することで、Excelなどのデータを自由に整形しExcelに貼り付けられる形で出力することが可能になります。
みなさまの今後のDify開発の参考になれば幸いです。
参考文献

株式会社アップグレードは、エンタープライズ企業の生成AI活用における戦略立案から実装までを一貫して支援する専門企業です。本ブログでは、AI Workflow設計、AI Agent開発、RAGシステム構築、各種LLMの実践的活用手法など、技術的知見を共有します。| Dify公式パートナー
Discussion