こんにちは、本田です。
本記事では、LLMアプリの観測性(オブザーバビリティ)や評価機能を提供しており、OSSでセルフホストできること等を強みに企業での導入率が高い「Langfuse」を Dify と連携させることで、どんな効果が期待できるのか、実際に触りながら検討してみました。(2025年5月時点)
1. Langfuseのトレース vs Difyのトレース機能:どちらが「見える」のか?
LLMアプリケーション開発において、問題発生時の原因究明やパフォーマンスチューニングに不可欠なのが「トレース」機能です。DifyとLangfuseはそれぞれトレース機能を提供しますが、その深さと粒度には違いがあります。
Dify のトレース機能:
Difyは、開発プロセスを支援するための基本的な機能を提供しています。
- 会話/実行ログ: 各ノード(LLM呼び出し、ツール実行など)の入力、出力、トークン消費量、実行時間を確認できます。
- ステップ実行: ノード単位で実行し、処理を追跡できます。
- プレビューと実行: Test Run として開発中にテストできます。
これらの機能だけでも一定開発はできますが、以下のような限界があります。
-
ノード単位で深堀ができない
例えば、エージェントノードで複数のツールを呼び出して処理するとき「どのツールが使われたのか」がトレースからはわかりません。
-
ネスト構造が把握しづらい
イテレーションノード内での各回の実行のログ等、ネスト構造の配下にあるノードのログは確認はできますが見づらいです。
-
ログをエクスポートできない
トレース上での確認にとどまるため、一つ一つ開いて評価する必要があり精度改善プロセスの効率が下がります。
Langfuse のトレース機能:
上記の二点の課題を解決するのが Langfuse のトレース機能だといえそうです。
単なるログの複製ではなく、データをより深く分析・デバッグ可能な形に昇華させるのです。
前提: Langfuse のトレース機能は Test Run/バックエンドAPI/アプリ/埋め込み等どんな形式で実行しても記録されます。
-
より深い粒度感のログを取得できる
- 例えば、エージェントノードから Zappier MCP を介して Google Calendar から予定データを取得する要件を実装するとします。
- Dify のトレースだと、先ほど説明した通り「予定照会」「予定結果」の部分しか取得できません。
- つまり Zappier MCP の内部的な処理に関するログが含まれていないため、例えば Zappier MCP に電子メール送信機能や、他のカレンダー操作機能も設定されている場合に、どのツールが使われているのかがわかりません。
より実践的な精度改善のためには、単にAIの回答が良いか悪いかを評価するだけでなく、「お手本」となる理想的な回答(ベンチマーク回答) を事前に用意し、それとAIの回答を比較評価させることが有効です。
-
ツリー表示/タイムライン表示を切り替えられるなどトレースが見やすい

- 完全なコンテキスト: API呼び出しの詳細、送受信されたプロンプトと生成結果、並列処理の状況など、実行に関するあらゆるコンテキストをキャプチャします。
- タイムラインビュー: 各ステップの開始・終了時刻を視覚的に表示し、Dify の実行時間だけではわからない、APIの応答遅延や特定の内部処理の遅さをピンポイントで特定できます。
- Input, Output, Metadata の形式で、Dify よりもワイドな画面でログが表示されており、情報量はより多いのでずっと見やすいため効率的にデバッグできます。
-
CSV/JSON/JSONL の形式でログを一括エクスポートできて便利
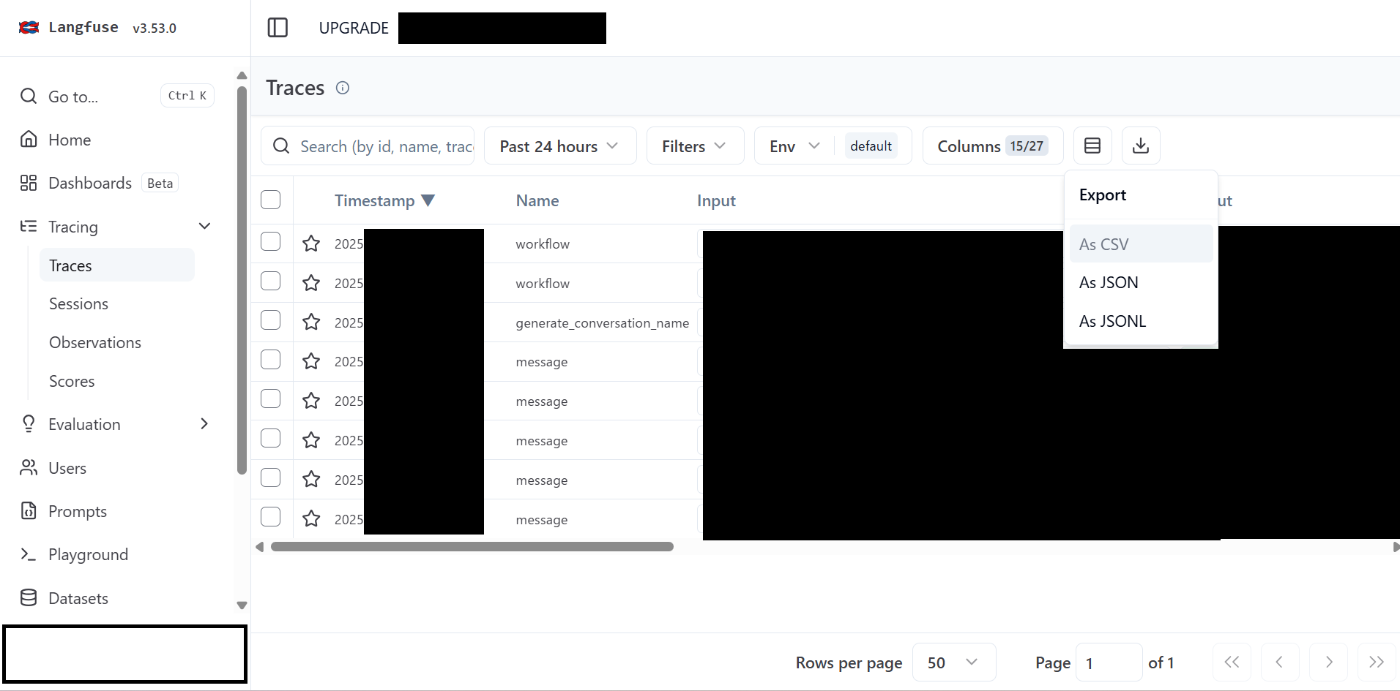
↓
- Tracing>右上のダウンロードボタンから三つの形式を選んでダウンロードできます。
- 人による評価や、LLMによる評価のスコア情報等もまとめて表形式でエクスポートできるため、精度改善フェーズにおいて重宝します。
2. Langfuse の LLM as a Judge はユースケース開発で有効か?
LLMアプリケーションの品質を担保・向上させるためには、その出力を評価する仕組みが不可欠です。Langfuse は「LLM-as-a-Judge」と呼ばれる、LLM 自身に評価を行わせる機能を提供しています。
LLM-as-a-Judgeとは?
開発者が定義した評価基準(例:回答の関連性、毒性の有無、指定したフォーマットへの準拠度など)に基づき、別の強力な LLM がアプリケーションLLMの出力を自動でスコアリングする手法です。
Langfuse では、「評価テンプレートの定義」「ジャッジLLMの選択」「人によるスコアリング結果の記録との比較」が可能です
ユースケース開発における有効性の評価
LLM による自動評価は、大量の出力を効率的に評価するポテンシャルがありますが、現場の具体的なユースケース開発レベルで全面的に依存するには、まだハードルがあると考えます。
①LLM評価と人間評価の乖離リスク
現状のLLM-as-a-Judgeは、一般的な基準(流暢さ、安全性など)では有効な場合もありますが、特定のドメイン知識や微妙なニュアンス、ビジネス要件への適合性といった、現場で本当に重要となる評価軸においては、人間の評価と乖離する可能性があります。
ジャッジLLM がユースケースの複雑な要求を完全に理解し、評価することはまだ難しい場面が多いでしょう。
②精度改善には「ベンチマーク比較」が有効だが…
より実践的な精度改善のためには、単にAIの回答が良いか悪いかを評価するだけでなく、「お手本」となる理想的な回答(ベンチマーク回答) を事前に用意し、それとAIの回答を比較評価させることが有効です。
(例えば、「この質問に対して、このベンチマーク回答と比べて、AIの回答はどの程度ポイントを押さえられているか?」といった評価です。)
これが、Langfuse ではデータセット機能を使って実現可能です。事前に「質問とベンチマーク回答のペア」をデータセットとして用意しておき、Difyアプリケーションの実行結果(AI回答)とそのデータセット内の対応するベンチマーク回答を自動で突き合わせて比較評価する、といった一括処理を実現できます。
(※ただし、Dify, LangfuseのGUI上の標準機能だけでは難しいです。また、精度については未検証のため、具体的な手順・精度所感については今後確認して加筆予定)
結論: ユースケース開発レベルでも運用次第で精度評価を効率化できる
具体的には、以下のような活用が考えられます。
- 基本的な品質チェックの自動化: 毒性チェックや簡単なフォーマットチェックなど、明確な基準で判断できる評価の自動化。
- 相対比較: 同じ入力に対する複数のプロンプトパターンや LLMモデルの出力を、LLM-as-a-Judgeで相対的に比較し、改善の方向性を探る。
- 人間評価の補助: 自動評価の結果を参考にしつつ、最終的には人間によるレビューや評価を組み合わせる。Langfuseは手動でのアノテーションやフィードバック収集機能も備えています。また、人による評価機能と、人<>LLM の評価のスコア比較機能がついており、こうした機能も生かして精度評価を効率化する運用の仕組み化が肝要。
MCP の発展により、Langfuse 側でベンチマーク質問・回答を自動作成 - > Dify を実行してテストする機能が提供される可能性等もありえます。今後の機能拡充にも期待しましょう。
3. Langfuse を使う/使わないの判断基準(簡易版, ユースケース別)
| ユースケース | おすすめツール | 理由 |
|---|---|---|
| アイデア検証・PoC | Dify | 画面だけで完結、セットアップが最短 |
| 本番の品質改善サイクル(評価→改善) | Langfuse | 評価・メトリクスが豊富、プロンプト CMS で A/B テスト可能 |
| 複数サービス横断で一元監視 | Langfuse | アプリを問わずログを集約可能、RBAC で権限管理も可 |
| チーム外とダッシュボード共有 | Langfuse Cloud | URL 共有と RBAC が容易 |
| 機密データを社内だけで保持 | Langfuse Self‑host | MIT ライセンスで自前運用 |
4. まとめ
DifyはLLMアプリケーションの迅速な構築に強力なプラットフォームですが、その運用と継続的な改善には、より深い可観測性と評価の仕組みが求められます。Langfuseとの連携は、まさにこのギャップを埋めるための有効な手段です。
- 詳細なトレース: 複雑なワークフローのデバッグとパフォーマンス分析を加速します。
- 高度なコスト分析: 正確なコスト把握とユーザー/機能ごとの帰属を可能にします。
- 体系的な評価: LLM-as-a-Judgeやデータセット活用(今後の発展に期待)により、品質保証プロセスを強化します。
- 柔軟な導入: クラウド版とOSS版を選択でき、ニーズに合わせた運用が可能です。
LLMOpsプラットフォームの選定は、開発するLLMアプリケーションの成功に不可欠な要素です。Langfuseは、特にDifyユーザーにとって、開発の容易さと運用の堅牢性を両立させるための有力な選択肢となるでしょう。ぜひ、自社の状況に合わせてLangfuseの導入を検討してみてください。
5. 参考リンク
- https://github.com/langgenius/dify/releases
- https://langfuse.com/blog/2024-04-introducing-langfuse-2.0
- https://docs.langfuse.com/?utm_source=chatgpt.com
- https://langfuse.com/docs/datasets/example-synthetic-datasets?utm_source=chatgpt.com
- https://langfuse.com/changelog/2024-11-19-llm-as-a-judge-for-datasets?utm_source=chatgpt.com
- https://github.com/langfuse/langfuse

株式会社アップグレードは、エンタープライズ企業の生成AI活用における戦略立案から実装までを一貫して支援する専門企業です。本ブログでは、AI Workflow設計、AI Agent開発、RAGシステム構築、各種LLMの実践的活用手法など、技術的知見を共有します。| Dify公式パートナー
Discussion