この記事の概要
AIエージェントは、「Profile」「Memory」「Planning」「Action」から構成されます。

引用:A Survey on Large Language Model based Autonomous Agents (2023)
その内の「Planning(計画)」は、次の5つのカテゴリに分類できます。
- タスク分解
- マルチプラン選択
- 外部プランナー支援計画
- 反省と洗練
- 記憶拡張計画
この記事では、AIエージェントのPlanningのうち、「マルチプラン選択」について説明します。
さらに、代表的なマルチプラン選択フレームワークであるTree of Thoughts(ToT)の論文についても解説しました。
復習:Planningとは
概要
AIエージェントの「計画」とは、目標達成のために一連の行動を構成・選択するプロセスです。
具体的には、タスクや目標に応じて、必要なステップを論理的・時系列的に整理し、エージェントがその通りに行動できるようにすることを指します。
なぜLLMベースのエージェントにPlanningが必要か?
- LLMは非常に強力な推論能力を持っていますが、そのままでは「複雑なタスクの段階的実行」には不向きです。
- 単発の出力だけでタスクを完了できない場面では、事前に「どんなステップで進めるか」を考えるPlanningが重要になります。
マルチプラン選択とは
LLMによって導き出される計画は、多様であり、最適でなかったり、実行不可能であったりする場合も少なくありません。
「マルチプラン選択」は、これを解決するために、複数のプランを生成し、その中から最適なプランを選択するという方法です。
複数のプランを生成
いくつかの方法があります。
-
Self-consistency
同じ問題に対しても唯一の解が存在しないという直感に基づき、温度サンプリングやtop-kサンプリングなどの手法で多様な出力を得る方法。 -
Tree-of-Thought
複数のプロンプトによる多様な解法を生成し、それぞれに対して解答を出力する方法。 -
etc
最適なプランの選択
これもいくつかの方法があります。
-
ナイーブ戦略
最も得票数が大きいプランを選択する方法。 -
Tree構造による選択
従来の幅優先探索(BFS)や深さ優先探索(DFS)のアルゴリズムを用いて拡張候補を評価する方法。 -
etc
マルチプラン選択は、AIエージェントの精度を向上させる上で、有効な手法です。
しかし、計算コストであったり、プラン評価もLLMが行うため、毎回同じ評価基準でプランを評価できないなどの課題もあります。
論文紹介:Tree of Thoughts: Deliberate Problem Solving with Large Language Models (2023)
ここではマルチプラン選択の1つの手法である、Tree of Thoughtsについて解説します。
概要
Tree of Thoughts(ToT)は、Chain-of-Thoughts(CoT)を一般化した理論です。(※ この解説はCoTの前提知識は不要です。)
ToTは、心理学・認知科学などで定義される「システム2」のような計画プロセスをAIエージェントに提供することを目的としています。
| 特徴 | システム1 | システム2 |
|---|---|---|
| 思考タイプ | 直感的・素早い | 論理的・遅い |
| 処理の意識性 | 無意識・自動的 | 意識的・制御的 |
| 使用リソース | 低(ほぼ瞬間的) | 高(集中力・注意を要する) |
| 使用例 | 顔の認識・簡単な計算(2+2) | 数学の証明・戦略的意思決定 |
| エラー傾向 | ヒューリスティック・バイアスに弱い | 精度は高いが時間がかかる |
Tree of Thoughtsのアーキテクチャ
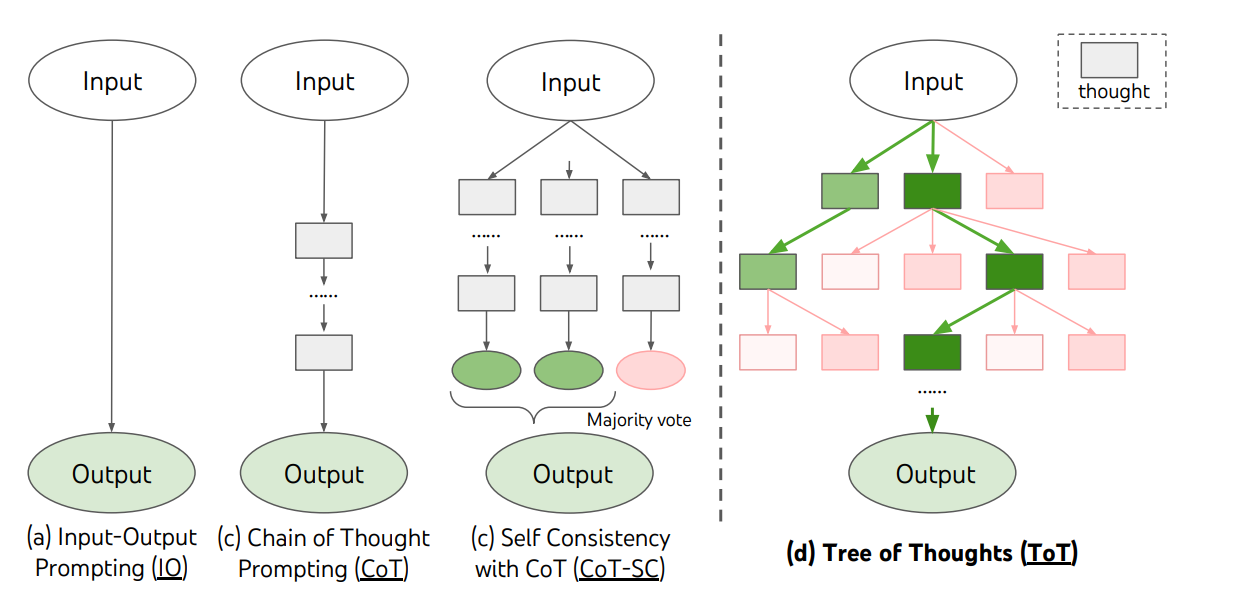
(引用:Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Fig1)
上の図の一番右(d)が、Tree of Thoughts(ToT)のアーキテクチャ図です。
【要点】
-
問題を樹形図で探索
- ゴールまでの途中経過(思考)をノードに置き、枝を広げながら解を探す。
-
ステップは「生成 → 評価 → 選択」の繰り返し
- 生成 (Propose) : LLM が次に取り得る思考の候補をいくつか出す。
- 評価 (Value/Vote) : LLM が各候補の有望度をざっくり点数付け or 投票。
- 選択 (Search) : 高得点だけ残し、次の深さへ進む。
- 良い候補だけを残すヒューリスティックで計算量を抑える。
- バックトラックが可能なので、行き詰まったら1つ戻って、別の枝を再探索できる。
【処理の流れ】
ざっくり説明すると、
- LLM に「次にあり得る手」を複数出させる。
- 同じ LLM にそれぞれの手をざっくり評価させ、良いものだけ残す。
- 残った手で木を伸ばし、ゴールが出るまで 1 - 2 を繰り返す。
という流れです。
具体例:Game of 24
論文で紹介されていた「Game of 24」というベンチマークタスクを使って理解を深めます。
- 「Game of 24」とは
例えば、入力に「4, 9, 10, 13」という4つの数字が渡されたとします。
AIは、4つの数字を1回ずつ使い、四則演算のみで、24を作れるかというベンチマークタスクです。
この問題の正答率が大きいほど、AIの推論能力が高いということになります。
この例だと、
( 10 - 4 ) × ( 13 - 9 )
が正解になります。
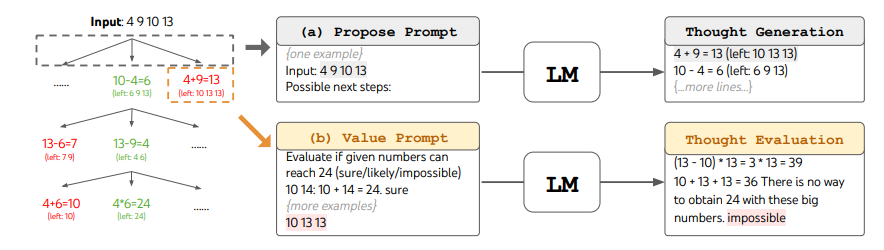
(引用:Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Fig2)
ToTは、次のようにこの課題を解決しようとします。
-
問題入力
- 例:数字 4, 9, 10, 13 を使って 24 を作る。
-
思考を 3 ステップに分解
-
ステップ1:4 個の数字から 2 個を使い “中間式” を作る
- 例:10 − 4 = 6
-
ステップ2:残り 2 数字 + 中間結果で次の式
- 例:13 − 9 = 4
-
ステップ3:2 つの結果で最終式
- 例:6 × 4 = 24
-
ステップ1:4 個の数字から 2 個を使い “中間式” を作る
-
各ステップで枝を広げる
- Propose Prompt で “次に作れそうな式” を LLM が 5 候補ほど生成。
- Value Prompt で 「24 に届きそうか」を sure / maybe / impossible の 3 段階で採点。
- 採点が低い候補はそこで枝切り。
-
探索アルゴリズム
- BFS(幅優先):深さごとに上位 5 候補だけ保持して次へ。
- こうして不要な式を捨てつつ、ゴール 24 に到達する枝を探す。
まとめ
AIエージェントのコンポーネントの1つである「Planning」における「マルチプラン選択」について説明しました。
さらに、マルチプラン選択の代表的なフレームワークである、Tree of Thoughts(ToT)についても説明しました。
参考
Understanding the planning of LLM agents: A survey (2024)
A Survey on the Memory Mechanism of Large Language Model based Agents (2024)
Tree of Thoughts: Deliberate Problem Solving with Large Language Models (2023)

株式会社アップグレードは、エンタープライズ企業の生成AI活用における戦略立案から実装までを一貫して支援する専門企業です。本ブログでは、AI Workflow設計、AI Agent開発、RAGシステム構築、各種LLMの実践的活用手法など、技術的知見を共有します。| Dify公式パートナー
Discussion