この記事の概要
AIエージェントは、「Profile」「Memory」「Planning」「Action」から構成されます。

引用:A Survey on Large Language Model based Autonomous Agents (2023)
その内の「Action(行動)」は、次の2つのカテゴリに分類できます。
- Tool Use(ツールの利用)
- Physical Interaction(物理的相互作用)
この記事では、AIエージェントのActionのうち、Toolの連携のプロトコルについて説明します。
復習:AIエージェントのToolとは
「ツール」とは、AIエージェントが呼び出すことができるあらゆる機能や関数を指します。
例えば
- 外部のデータソースと連携
- 既存のAPIから情報を送受信
- ウェブ検索
- コード実行
- ドキュメント操作
- GUI操作
など、AIエージェントが多様なタスクを実行したりすることを可能にします。
ツールは、LLMの推論や計画の能力を拡張し、複雑な目標達成や現実世界の問題解決を可能にするために必要な要素です。
ツール活用のためのアーキテクチャ
次の2つに分類できます。
- シングルエージェント型
- マルチエージェント型
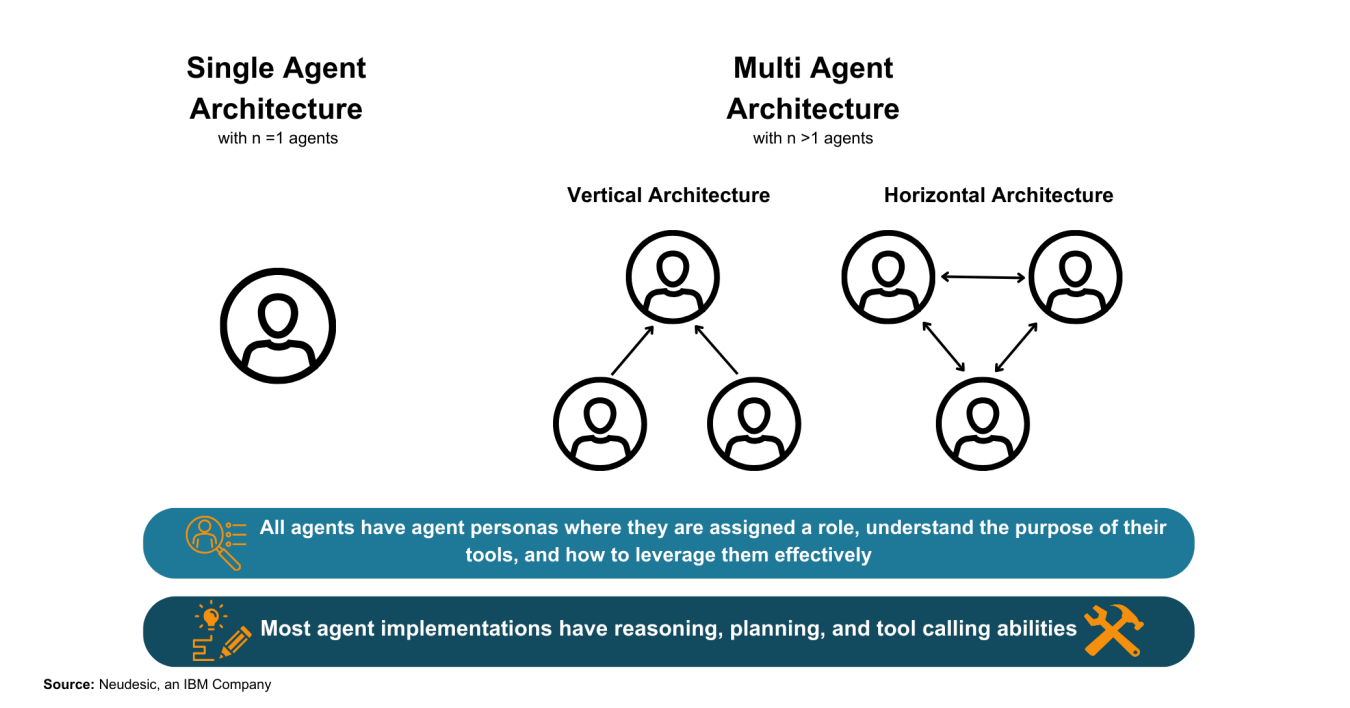
(引用:The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey, Fig1)
シングルエージェント型
- 1つのLLMが全てを担う。
- フィードバックは人間のみ(他エージェントの介入なし)。
- 明確に定義されたタスクや簡易なツール連携に向く。
【代表的なフレームワーク】
| 手法 | 特徴 |
|---|---|
| ReAct | 思考→行動のループ。透明性高いがループ脱出に課題。 |
| RAISE | ReActに短期・長期メモリ追加。文脈保持強化。 |
| Reflexion | 自己評価で改善。長期記憶に限界。 |
| AutoGPT+P | ロボット計画特化。LLMと古典プランナー統合。 |
| LATS | 木探索を使った強力な行動選択。計算コスト高。 |
【補足】
例えば、ReActフレームワークでは、タスク解決のための「思考」と、それを実現する「行動」を繰り返し、さらにそれの評価を外部(ツールの実行結果など)から受け取り、次の「思考」に繋げます。
これらの「思考」「行動」は全て単一のLLMが行っており、シングルエージェント型に分類されます。
マルチエージェント型
- 複数エージェントが協働。
- 【垂直型】:リーダー中心に上下関係あり。
- 【水平型】:全員が平等に情報共有。
- 複雑なコラボやマルチ視点のタスクに向く。
【代表的なフレームワーク】
| 手法 | 特徴 |
|---|---|
| Embodied LLM Agents | 人間リーダーがいる方が10%効率高い。 |
| DyLAN | 動的貢献度評価でメンバー再編成。 |
| AgentVerse | 明確なフェーズ分け(採用→協働→実行→評価)。 |
| MetaGPT | 無駄な会話を抑制、構造化出力で効率化。 |
アーキテクチャ紹介:Embodied LLM Agents
概要
このアーキテクチャは、マルチエージェント型における「垂直型」に分類されるアーキテクチャです。
論文では、リーダーとなるLLMを設けることで、全体のタスク解決において効果的であることが示されました。
GPT-4をリーダーとした時に最もスコアが大きくなりましたが、まだ「LLM」ではなく「人」がリーダーでを務めた時の方がタスク完了までの時間が短くなるみたいです。
アーキテクチャの説明
次の2つのLLMを組み合わせることで、「より良い組織構造(プロンプト)」をAI自体が進化させていく仕組みです。
- Critic:評価役
- Coordinator:改善提案役

(引用:Embodied LLM Agents Learn to Cooperate in Organized teams, Fig3)
【各LLMなどの説明】
Environment(環境)
- エージェントたちが実際にタスクを行う場所
- たとえば「部屋の掃除を協力してやる」などの課題
LLM Agents(複数のAIエージェント)
- それぞれが役割を持って動く
- 赤いロボットがリーダー
LLM Critic(批判役のAI)
- エージェントの行動履歴(Trajectory)を読んで分析
- 「誰が良かった?」「どこで問題が起きた?」を評価
LLM Coordinator(改善役のAI)
- Criticが出した評価と、外部コスト(タスクにかかった時間・通信量)を使って、
- 次の試行のための 新しい組織プロンプト を提案する
【処理の流れ】
-
今のプロンプトで1回実行(Run for One Episode)
エージェントたちが今のルールに従って協力しタスクを実施 -
Criticが評価(Critic Evaluation)
行動履歴を読んで「誰が良かった?」「問題は何だった?」を分析 -
Coordinatorが改善案を考える(Organization Design)
よりよいチーム構造(プロンプト)を提案 -
新しいプロンプトで次の試行に進む
まとめ
AIエージェントのコンポーネントの1つである「Action」におけるツール(Tool)のツール活用のアーキテクチャについて説明しました。
全ての処理を1つのLLMで処理する「シングルエージェント型」と、複数のLLMを利用する「マルチエージェント型」があります。
本記事では、マルチエージェント型の代表的なアーキテクチャである「Embodied LLLM Agents」を紹介しました。
参考
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey (2024)
Embodied LLM Agents Learn to Cooperate in Organized Teams (2024)

株式会社アップグレードは、エンタープライズ企業の生成AI活用における戦略立案から実装までを一貫して支援する専門企業です。本ブログでは、AI Workflow設計、AI Agent開発、RAGシステム構築、各種LLMの実践的活用手法など、技術的知見を共有します。| Dify公式パートナー
Discussion