この記事の概要
AIエージェントは、「Profile」「Memory」「Planning」「Action」から構成されます。
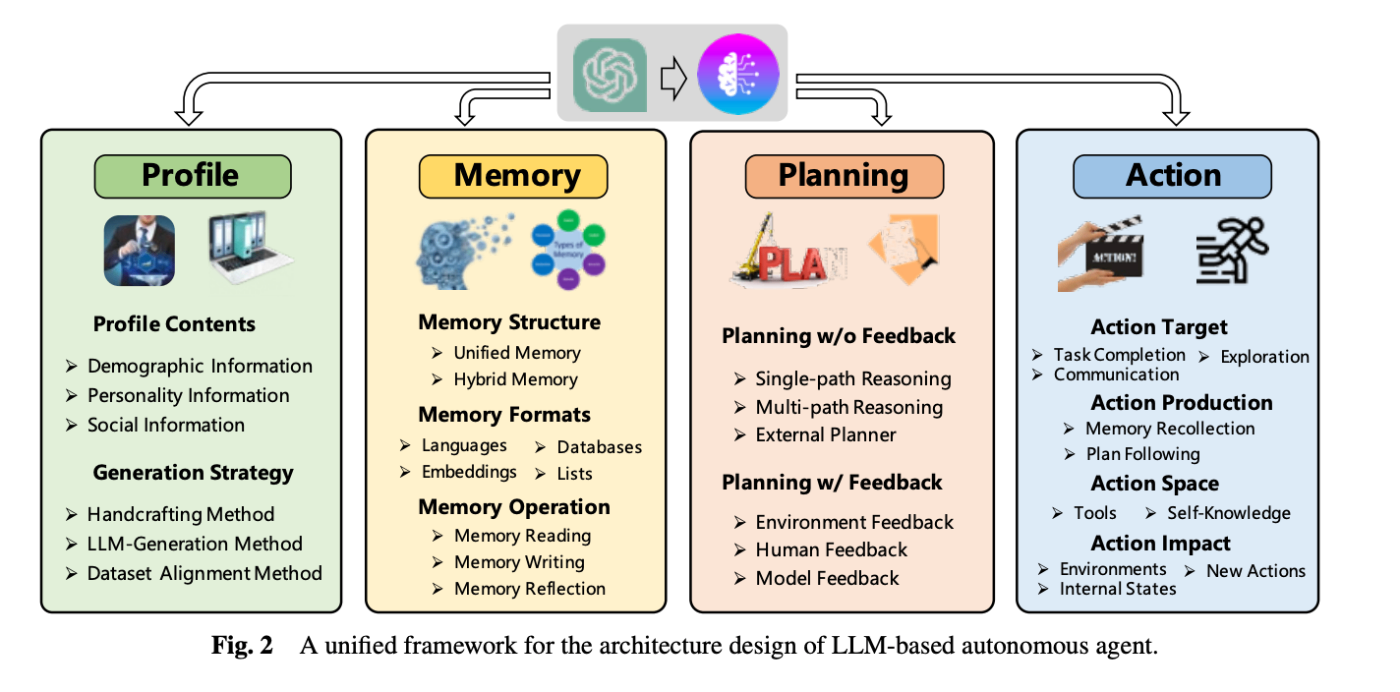
引用:A Survey on Large Language Model based Autonomous Agents (2023)
その内の「Planning(計画)」は、次の5つのカテゴリに分類できます。
- タスク分解
- マルチプラン選択
- 外部プランナー支援計画
- 反省と洗練
- 記憶拡張計画
この記事では、AIエージェントのPlanningのうち、「タスク分解」について説明します。
復習:Planningとは
概要
AIエージェントの「計画」とは、目標達成のために一連の行動を構成・選択するプロセスです。
具体的には、タスクや目標に応じて、必要なステップを論理的・時系列的に整理し、エージェントがその通りに行動できるようにすることを指します。
なぜLLMベースのエージェントにPlanningが必要か?
- LLMは非常に強力な推論能力を持っていますが、そのままでは「複雑なタスクの段階的実行」には不向きです。
-
単発の出力だけでタスクを完了できない場面では、事前に「どんなステップで進めるか」を考えるPlanningが重要になります。
タスク分解とは

(引用:Understanding the planning of LLM agents: A survey, Fig2)
タスク分解の方法は2つあります。
- Decomposition-First
- Interleaved
Decomposition-First
先にサブゴール(中間目標)にタスクを分解し、その後、それぞれのサブゴールについて個別に計画を立てます。
例えば、
- 「まず計画を立てよう(Let’s first devise a plan)」
- 「その計画を実行しよう(Let’s carry out the plan)」
の2段階に、推論などの精度を向上させることができます。
Decomposition-First方式は、サブタスクと元のタスクとの相関が強く、全体像の把握と忘却防止に寄与できます。ただし、全てのサブタスクを最初に決めるため、実行途中の調整が難しくなり、どこかで失敗すれば全体が破綻するリスクがあります。
Interleaved
サブゴールの分解と計画立案を交互に進めます。
この手法は、いくつか提案されている方法があります。
- LLMが思考と行動を交互に繰り返しながら問題を解決する。(Chain-of-Thought)
- 複雑な問題を複数の推論経路で段階的に考える。(ReAct, Program-of-Thought)
Interleaved方式は動的に計画を調整しながら実行できるため、失敗への耐性は高くなります。ただし、複雑なタスクでは全体方針とのズレや目標喪失のリスクがあります。
Decomposition-Firstの具体例:Hugging GPT
LLMと、Hugging Faceコミュニティに存在する多様なAIモデルを連携させることで、複雑なタスクを解決することを目指すAIエージェントです。
HuggingGPTは、
- タスク分解
- モデルの選択(Hugging Face上に存在する多様なモデルの中から、最適なモデルを選択する)
- タスク実行
- 応答生成
の機能を持ちますが、今回は、その中でも「タスク分解」について焦点を当てます。
【タスク分解の方法】
Hugging GPTでは、まずタスクをサブタスクに分解する時、LLMを用いて次のJSON形式で整理します。
[
{
"task": "image-classification",
"id": "T1",
"dep": [], // 依存タスク
"args": {"image": "<input>"}
},
{
"task": "image-caption",
"id": "T2",
"dep": ["T1"], // T1 の完了が前提
"args": {"image": "<input>"}
}
]
-
id:各タスクのID -
dep:依存関係(どのタスクが先に完了している必要があるか) -
args:入力引数(タスクの対象となるリソース情報)
【Hugging GPTの特徴】
- 各サブタスクと依存関係を 一回のプロンプト でまとめて抽出します。
- これは「逐次ステップでタスクを拡張する」手法より効率的で、エラーが蓄積しにくい設計です。
Interleavedの具体例:Chain-of-Thought
Chain-of-Though(CoT)は、複雑な推論タスクに対して、中間ステップ(思考過程)をプロンプトに書き出しながら解かせる手法です。

(引用:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Fig1)
CoTのポイント
- 標準的な few‑shot プロンプトでは「問題 → 解答」のみを提示しますが、CoT prompting では「問題 → (中間ステップ:思考過程) → 最終解答」を含む例を与えることで、設問の意図を段階的に解釈し、多段推論によって推論力が向上します。
- GSM8Kという数学問題を扱うベンチマークテストで、約17→58% へ飛躍的に推論力が向上しました。
- 次のどちらの方法でも、上記の効果を獲得できます。
- zero-shot形式:
- 単に「Let’s think step by step.」など一文を付け加える。
- few-shot形式:
-
複数の例を与える。
-
例:few-shot形式のCoT prompting
## Output Q1: 太郎は3個のリンゴを持っていて、次に5個もらいました。合計で何個ありますか? A1: まず、3 + 5 = 8。答えは8です。 Q2: 花子は2本の鉛筆を持っています。3本借りました。全部で何本? A2: まず、2 + 3 = 5。答えは5です。 ...
-
- zero-shot形式:
CoTを用いたAIエージェントの設計例

- Plannerは、CoTの仕組みによってサブタスクを1つまたは2つ生成します。
- このサブタスクを解決するプランが生成されます。
- 生成されたプランを実行し、結果からフィードバックを得ます。
- その結果に基づき、CoTによって次のサブタスクが生成されます。
まとめ
AIエージェントのコンポーネントの1つである「Planning」における「タスク分解」について説明しました。
タスク分解は、
- プランを立てる前に一度に全てのサブタスクを生成する方法
- サブタスクの生成から行動までを繰り返し、行動の結果のフィードバックを反映して次のサブタスクを生成する方法
の2つがあります。
タスク分解の過程で、「Hugging GPT」「Chain-of-Though(CoT)」についても簡単に説明しました。
参考
Understanding the planning of LLM agents: A survey (2024)
A Survey on the Memory Mechanism of Large Language Model based Agents (2024)
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face (2023)
Chain-of-Thought Prompting Elicits Reasoning in Large Language Model (2022)

株式会社アップグレードは、エンタープライズ企業の生成AI活用における戦略立案から実装までを一貫して支援する専門企業です。本ブログでは、AI Workflow設計、AI Agent開発、RAGシステム構築、各種LLMの実践的活用手法など、技術的知見を共有します。| Dify公式パートナー
Discussion