株式会社Unseedの伊藤です。普段は、通信技術とAIの融合に焦点を当て、新しい通信技術の創出やその応用に関する研究を行っています。
近年、AI技術の進化により、ドローンなどの無人航空機(UAV)の自律飛行が注目されています。特に、深層学習の一種であるDDPG(Deep Deterministic Policy Gradient)が、自律的に状況を判断し、精度を高める手法として重要な役割を果たしています。本記事では、DDPGの基本概念と、自律飛行技術の未来について解説します。
DDPG(Deep Deterministic Policy Gradien)
基本的な強化学習の枠組み
DDPG(Deep Deterministic Policy Gradient)は、強化学習の一手法であり、特に連続的なアクション空間を扱う問題に対して有効です。従来の強化学習アルゴリズムの多くは、離散的な行動選択に依存していましたが、DDPGは連続的な制御が求められるシステム、例えばロボットアームの操作や自律走行車の制御などに適用することができます。
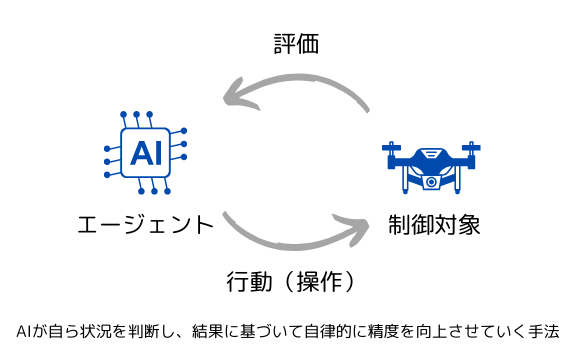
DDPGは、深層Qネットワーク(DQN)の考え方を基にしており、Actor-Critic方式に基づいています。ここでの「Actor」は、最適な行動を選択する役割を担い、「Critic」はその行動がどれだけ良かったかを評価します。DDPGは、オフポリシーの手法であり、経験再生(Experience Replay)とターゲットネットワークを使用して、安定した学習を実現しています。これにより、複雑なタスクでも効率的に学習を進めることが可能です。
Actorネットワーク
Actorネットワークは、状態
Criticネットワーク
Criticネットワークは、状態
Actor-Criticの更新手順

1. Criticの更新
Criticネットワークは、Bellman方程式に基づいて更新されます。Bellman方程式は、将来の報酬を割引率
ターゲットQ値
ここで、
この損失関数を最小化するように、Criticネットワークのパラメータ
2. Actorの更新
Actorネットワークは、Criticネットワークの勾配を使用して更新されます。Actorの目的は、Criticが評価するQ値を最大化することです。Actorのパラメータ
ここで、
3. ターゲットネットワークの更新
DDPGでは、ターゲットネットワーク(ターゲットActorとターゲットCritic)を使用して学習の安定性を高めています。ターゲットネットワークは次のように更新されます。
ここで、
DDPGの自律飛行への応用
自律飛行におけるDDPGの応用は、特にUAV(無人航空機)のナビゲーションと制御において重要です。自律飛行では、リアルタイムで環境の変化に対応し、複雑な経路を計画しながら障害物を回避する能力が求められます。DDPGは、これらの連続的な操作を高精度で実現するために利用されます。
具体的には、UAVが自律的に飛行する際、DDPGは次のような内容で期待されえています
ナビゲーションと障害物回避
ドローンは、自律飛行中に障害物を回避しながら目的地に向かう必要があります。DDPGは、ドローンの位置、速度、センサーデータを入力として、最適な飛行経路を計算します。これにより、ドローンは安全かつ効率的に飛行できます。最適なアクションは次のように選択されます。
ここで、
エネルギー管理と飛行効率
自律飛行では、バッテリー寿命を考慮して飛行経路や高度を最適化することが重要です。DDPGは、エネルギー消費を最小限に抑えるためのアクションを選択することができます。Criticネットワークはエネルギー消費を含めた総合的な価値を評価し、Actorネットワークがそれに基づいて最適な行動を決定します。
自律飛行技術の可能性と未来

DDPGを活用した自律飛行技術の未来は非常に明るく、さまざまな分野での応用が期待されています。今後、さらに技術が進化することで、次のような可能性が現実になるでしょう。
都市交通管理
UAVを利用した空中交通管理システムの構築が進むことで、都市部の渋滞緩和や交通事故の減少が期待されます。DDPGによる高度な飛行制御が、これを実現するための重要な技術となるでしょう。
新しい産業の創出
自律飛行技術は、新たなビジネスモデルの創出にもつながります。例えば、自律飛行を活用した宅配サービスや、観光地での自律飛行ガイドツアーなどが考えられます。
法規制の整備
自律飛行技術が普及するにつれて、関連する法規制の整備も進む必要があります。安全性やプライバシーの保護に対する対策が求められ、技術の進化と法制度のバランスが重要になります。
まとめ
DDPGは、自律飛行技術を支える強力なアルゴリズムであり、連続的な制御が必要なタスクに対して特に有効です。自律飛行におけるナビゲーションや障害物回避など、さまざまな場面でその力が発揮されています。DDPGを活用することで、UAVはより安全で効率的な飛行が可能となり、今後ますます多様な分野での応用が期待されます。
自律飛行技術は、今後もAI技術とともに進化を続け、私たちの生活や社会に大きな影響を与えるでしょう。技術の進展により、さらに多くの可能性が開かれ、DDPGを含む強化学習技術の役割はますます重要となることは間違いありません。

Discussion