【基礎練習】タイタニック号の分析
基礎練習として定番のタイタニック号の分析を自分で実施してみることにした。
(将来的にPokeAPI使って分析の方も面白いかも?)
参考になるサイトを見つけた。
Kaggle Notebookを使うとjupyterと同じ感覚で使えそう。
データセットまで準備してくれるので楽。
.profile_report()が便利そう。
基本統計量の詳細を一発で出してくれる。
これでビックデータの概要が簡単につかめる。
以下のようなデータの特徴まで出してくれるのが良い。
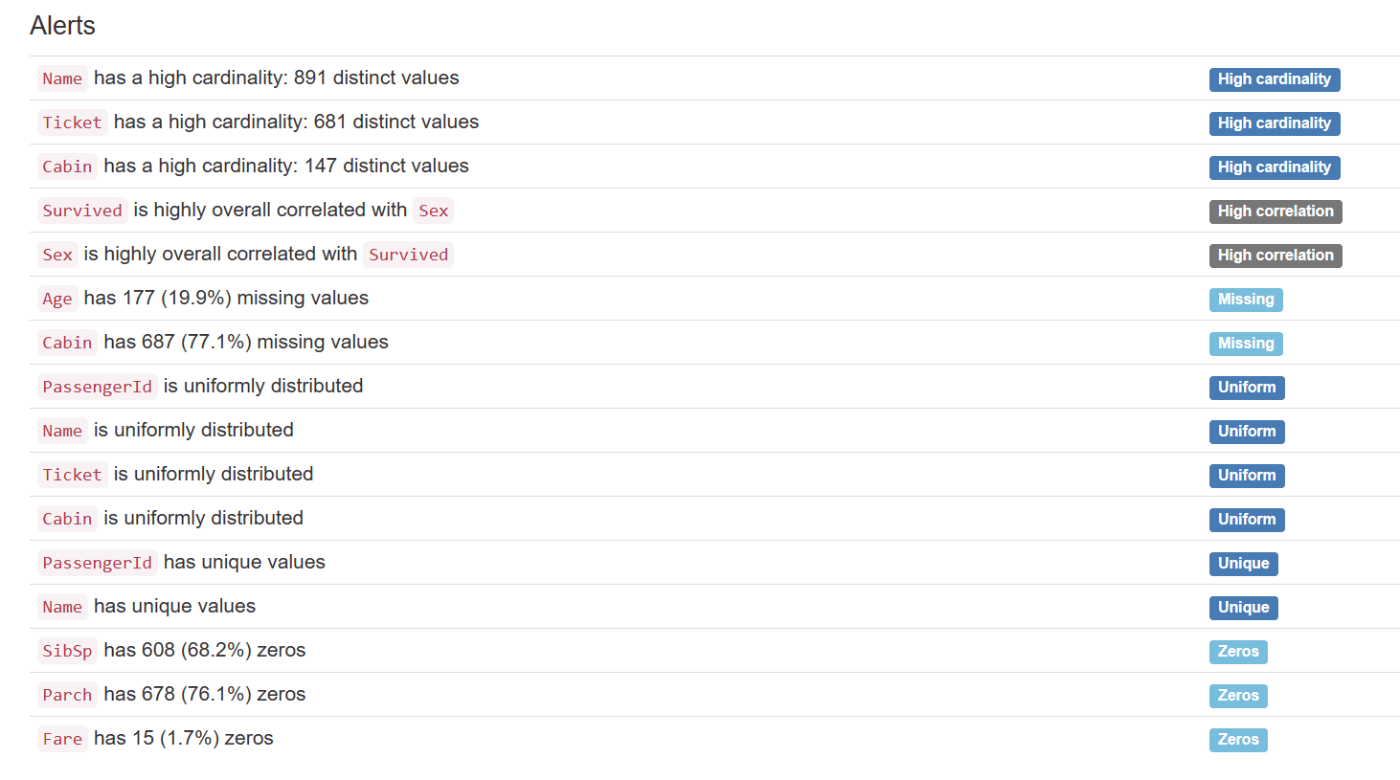
ここにあるように、まずは以下のあたりで簡易的に統計量出すのもありかも。
data_train.describe()
data_train.info()
data_all.drop(['PassengerId','Cabin'...........], axis=1, inplace=True)
inplace = Trueは元のデータセットを書き換える。axis=1は列を指す。
カテゴリ値をダミー変数に置換するとどういう結果になる?試してみるか。
ほとんど上のURLの人のコピペで以下を作成。微妙にアレンジ。
#PassengerId、Ticket:ただの順番で関係ない、Cabin:欠損値多すぎ、Name:どう考えても関係ない、Fare:出航地により変わりそうだから消す、Parch、SibSp:相関係数から関係なさそうだから消す
data_all.drop(["PassengerId","Cabin","Name","Fare","Parch", "SibSp","Ticket"], axis=1, inplace=True)
data_all.info()
さらに欠損値補完(ほぼコピペ)をした。
#欠損値補完。
#年齢は分散が小さいので、平均値を補完
data_all["Age"].fillna(np.mean(data_all['Age']),inplace=True)
#搭乗港は文字列なので、最頻値補完
data_all["Embarked"].fillna(st.mode(data_all["Embarked"]), inplace=True)
data_all.info()
GPT先生に聞いてカテゴリ変数をダミー化した。
# "Pclass"列をダミー変数に変換
pclass_dummies = pd.get_dummies(data_all['Pclass'], prefix='Pclass')
# "Sex"列をダミー変数に変換
sex_dummies = pd.get_dummies(data_all['Sex'], prefix='Sex')
# "Embarked"列をダミー変数に変換
embarked_dummies = pd.get_dummies(data_all['Embarked'], prefix='Embarked')
# ダミー変数を元のデータフレームに結合
data_all = pd.concat([data_all, pclass_dummies, sex_dummies, embarked_dummies], axis=1)
# 元のカテゴリカル列を削除
data_all.drop(['Pclass', 'Sex', 'Embarked'], axis=1, inplace=True)
# 結果のデータフレームを表示
print(data_all)
Kaggle超入門!初めてのタイタニック提出。おすすめのUdemy講座も紹介
こちらに倣い、最後まで出力した。
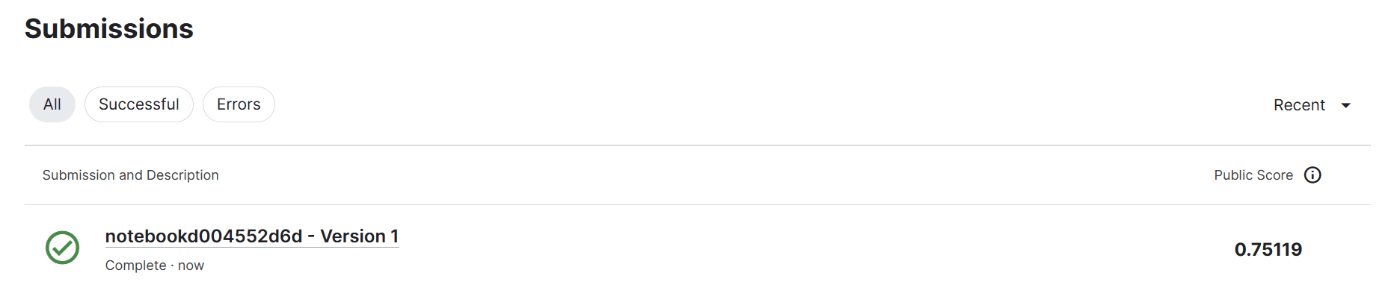
適合率0.75というところでそこそこ?
.profile_report()をつかうと相関係数と統計量が簡単にわかるので、それを使えば適当なライブラリを使えばそこそこの精度は出せる?
(ライブラリ開発レベルまで踏み込まないと更なる精度向上は厳しい?)
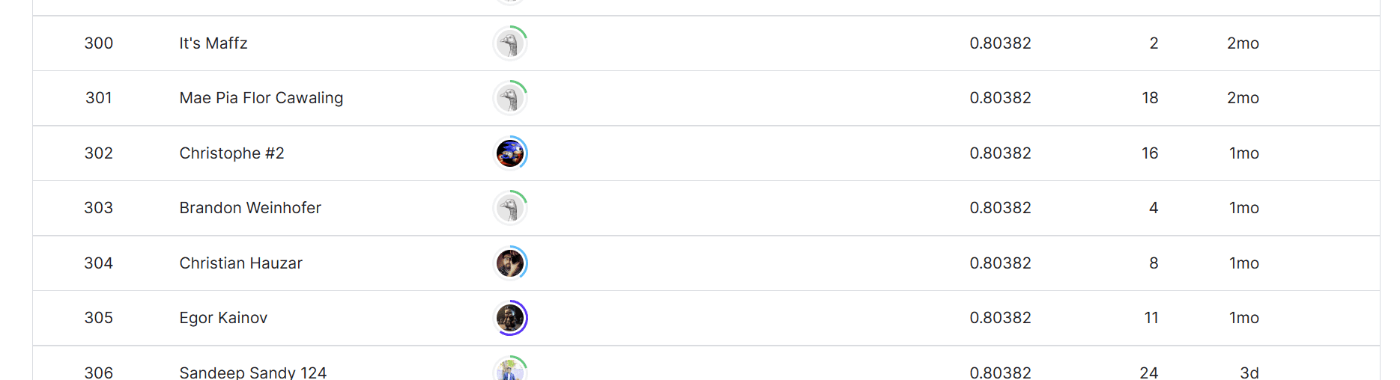
順位を見る。
12000位程度(自分):0.75程度
300位ぐらいの人:0.80程度
⇒①相関係数による取捨選択、②適切な欠損値補完(今回はほぼコピペ)、③カテゴリ変数のダミー変数化さえやっておけば、ライブラリを使ってある程度の精度は出せるものと理解。
これをうまくまとめてArticlesにするのは良い気がした。
時間があるときにやろう。