GKE Autopilotで画像生成AI Stable Diffusionの推論APIをデプロイする
GCP(Google Cloud Platform) Advent Calendar 2023 の4日
ヤプリ#1 Advent Calendar 2023 の4日
の投稿です。
概要
先日、2023年11月21日にStable Video Diffusionが公開されました。
画像生成に止まらず、Stable Diffusionで動画の生成も行えるようになりました。
生成AIブームの中でプロダクトの一部にStable Diffusionを含む何かしらの生成AIを組み込むシーンも増えてきました。
特に、GPU環境で処理が動くアプリケーションを継続的にデプロイしていくという観点で、アプリケーションエンジニアも関わることが多くなるような気は個人的にはしています。
そこで、今回はGKEのAutopilotモードでGPUを使える環境を用意し、Stable Diffusionの画像生成モデルを動かす技術検証をします。具体的にはpromptを受け取って、生成した画像を返すWeb APIを作ることを想定しており、その推論APIのエンドポイントをGKE Autopilotで公開することを実現できるかを調べます。
GKE Autopilotを選んだのは
- GPU環境が用意できる
- できるだけマネージドにしたい
- 継続的デプロイに向いている
という事情があったからです。
今まで自分の経験上Cloud Runはよく使ってきました。しかし、Cloud RunだとGPU環境が現時点で使えません。(Cloud Run For Anthosは使えそう).
GCEでももちろんやりたいことは実現できますが、自前で色々用意しなくてはいけないのと継続的デプロイのやりやすさを考えるとGKE Autopilotが良さそうでした。
GPUに関しては、Google ColaboやGoogle Virtex AI, Amazon SageMakerでもGPU環境は用意できますが、やはりマネージドサービスを使いたかったということがありました。
Google ColabでStable DiffusionのDiffusersが動作することを確認する
DiffusersとはHaggingFace製のいわゆる拡散モデルです。MLの専門家ではないのでこのあたりは誤魔化しますが、Stable Diffusionが提供するモデルを含めた世の中に出ている学習済モデル(.safetensorsとか.ckptの拡張子のファイルがよくある)から拡散モデルをインスタンス化し、提供してくれます。
ColabでDiffusersを動かすことについての情報はググればたくさん出てくるので、ここでは簡単に紹介します。Stable Diffusionとの関わりは以下のページをみるとよくわかります。
このページに従ってColabで確認したのは以下のコードです。
promptは↑のページで例に出ていた
「a photograph of an astronaut riding a horse」を使いました。
import torch
print(torch.__version__)
print(torch.cuda.is_available())
# 2.1.0+cu118
# True
!pip install diffusers accelerate
model_id = "CompVis/stable-diffusion-v1-4"
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(model_id, use_safetensors=True)
pipe.to('cuda')
prompt = "a photograph of an astronaut riding a horse"
result = pipe(prompt)
image = result.images[0]
image

出力はこんな感じです。ちゃんと宇宙飛行士が馬に乗っていますね!
GKE Autopilotにデプロイする
では、これをGKE Autopilot上で動かしてみます。
GKEクラスターを用意する
に従いました。
gcloud container clusters create-auto stable-diffusion-cluster --location=asia-northeast1
をCloud Shell上から実行します。
create-autoコマンドによってAutopilotモードでクラスターが作成できます(Standardモードのcreateコマンドももちろんあります)。
kubeconfig entry generated for stable-diffusion-cluster.
NAME: stable-diffusion-cluster
LOCATION: asia-northeast1
MASTER_VERSION: 1.27.3-gke.100
MASTER_IP: 35.221.108.189
MACHINE_TYPE: e2-small
NODE_VERSION: 1.27.3-gke.100
NUM_NODES: 3
STATUS: RUNNING
の出力があり、クラスターが作成されます。
Docker imageを作成する
方針
内部的な推論処理はColabで動かしたようにmodelを読み込んだStableDiffusionPipelineによって行います。prompt等をhttp requestで指定して推論を行えるようにFlaskでweb apiとして提供します。
シンプルなFlaskアプリケーションを作る
Flaskアプリケーションを以下のように/txt2imgで作ります。
import torch
from diffusers import StableDiffusionPipeline
from flask import Flask, request
import base64
from io import BytesIO
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16)
pipe.to("cuda")
app = Flask(__name__)
@app.route("/")
def health():
return {"body": "healthy"}
@app.route("/txt2img", methods=["POST"])
def txt2img():
body = request.get_json()
prompt = body['prompt']
result = pipe(prompt)
image = result.images[0]
buffer = BytesIO()
image.save(buffer, "jpeg")
img_str = base64.b64encode(buffer.getvalue()).decode('ascii')
return {'data': img_str}
diffusersの使い方は先ほどのColabと全く同じことを確認できると思います。
GKEデプロイ用のbaseとなるDocker imageを選ぶ
https://github.com/anibali/docker-pytorch を使いました。
これはNvidiaが提供しているcuda環境が使えるubuntuのimage
nvidia/cuda:11.8.0-base-ubuntu22.04
にpytorchがインストールされているものです。
もちろん、Nvidiaが提供しているイメージに自前でpytorchをインストールしても良いと思います。
このイメージを使うことで後述のデプロイ時にGPUドライバのインストールをわざわざ自分でする必要がなくなります。これがめっちゃ楽です。
例えばGCE上でpytorchのGPU使用を実現する、つまり、
import torch
torch.cuda.is_available()
がTrueになるためには以下のような面倒なドライバのインストール作業が必要になります。
GKE AutopilotのノードはContainer-Optimized OSのGCE VMを内部的に使うそうです。
このContainer-Optimized OSのVMであったとしても以下のように非常に面倒なドライバインストール作業が必要になります。
Dockerfileを作る
Dockerfileは以下のように書きました。
FROM anibali/pytorch:2.0.1-cuda11.8
WORKDIR /app
COPY . .
RUN sudo apt-get update
RUN pip install transformers==4.30.1 diffusers accelerate flask
CMD flask --app main run --port 8080 --host=0.0.0.0
pytorchはすでにインストールされているので新たにpip installする必要はありません。
インストールするコマンド等はColabでした作業と同じで必要なライブラリをインストールします。
今回は技術検証目的なので、flaskコマンドベタ打ちで、WSGIの使用等に対応していません。
プロダクションコードで使う場合注意してください。
buildとArtifact Registryへのupload
以下のコマンドでbuildとuploadを行います。
自分の場合、M1 Macのローカル環境でbuildしましたが、好きな環境で大丈夫だと思います。
$ DOCKER_BUILDKIT=1 docker build --platform linux/amd64 . -f Dockerfile -t asia-northeast1-docker.pkg.dev/<PROJECT_ID>/<REPOSITORY_NAME>/<IMAGE_NAME>
$ gcloud auth configure-docker asia-northeast1-docker.pkg.dev
$ docker push asia-northeast1-docker.pkg.dev/<PROJECT_ID>/<REPOSITORY_NAME>/<IMAGE_NAME>
この操作自体は、Docker imageをアップロードしているだけなのでGKE Autopilot文脈では特別なことはしていません(Cloud Runにデプロイする時も大体同じだと思います)。
deploymentを作成する
GPUが使える環境を作るために、deployment.yamlで指定します。
に従ってdeploymentを定義したyamlファイルを作成します。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: stable-diffusion
name: stable-diffusion-deployment
spec:
replicas: 1
revisionHistoryLimit: 1
progressDeadlineSeconds: 30
selector:
matchLabels:
app: stable-diffusion
template:
metadata:
labels:
app: stable-diffusion
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-tesla-t4
containers:
- image: asia-northeast1-docker.pkg.dev/<PROJECT_ID>/<REPOSITORY_NAME>/<IMAGE_NAME> # 先ほどuploadしたimage
name: stable-diffusion
resources:
limits:
nvidia.com/gpu: "1"
requests:
cpu: "8"
memory: "8Gi"
ポイントは
cloud.google.com/gke-accelerator: nvidia-tesla-t4
と
nvidia.com/gpu: "1"
です。この指定によってGPUをGKEノードが使用するGCE VMに割り当てます。
割り当て自体はGKE Autopilotが自動でやってくれます。
deploymentの適用
Cloud Shell上にdeployment.yamlを作成し、以下のコマンドを実行することでdeploymentを作成します。
kubectl apply -f deployment.yaml
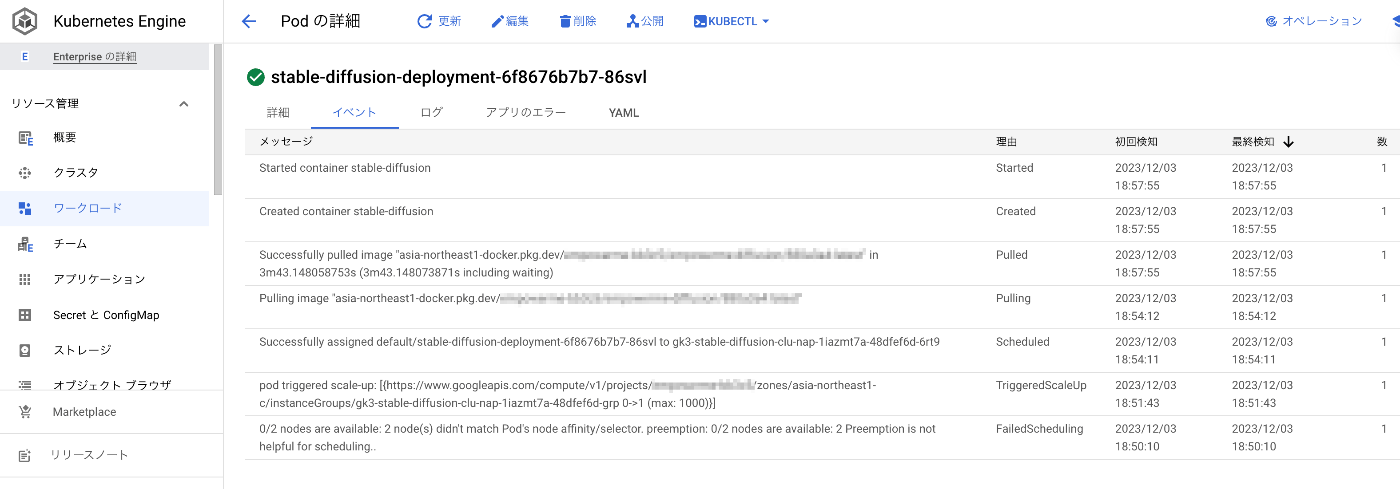
コンソール上でpodの状態をみてみます。以下のように一度要求したresourceが足りずにscale upしていることが確認できます。これも全て自動でやってくれるのは嬉しいですね。結果、7分後ぐらいにはContainer startedの表示が出ました。
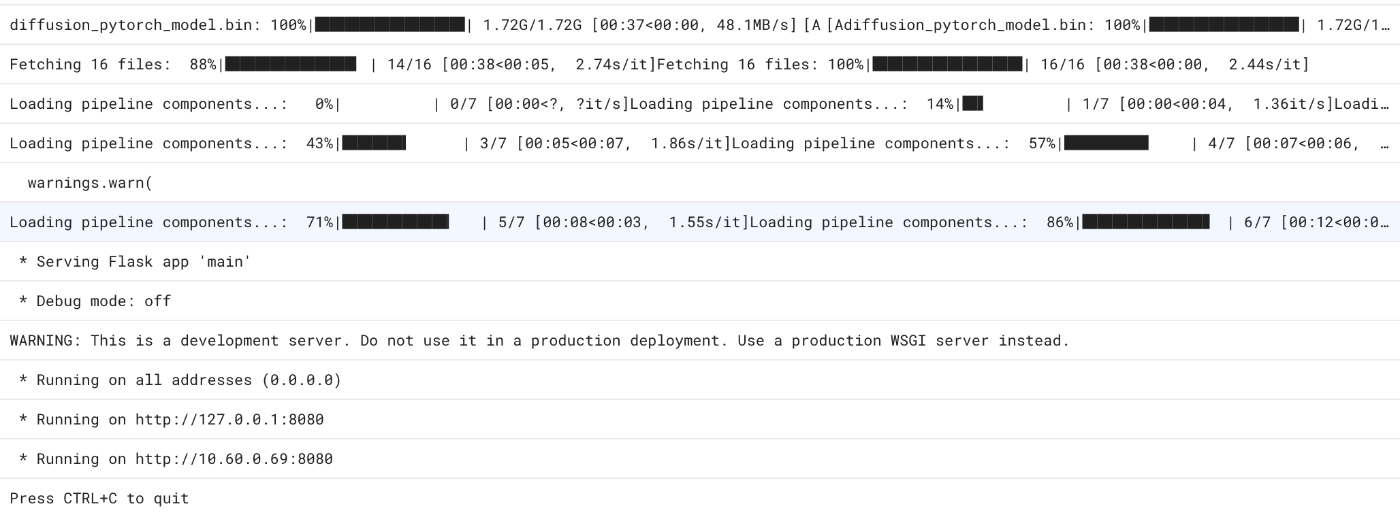
また、ログを確認してみるとFlask起動のログが確認できます。
サービスの公開
に従い、DeploymentをKubernetes Serviceとして公開できます。
今回はコンソール上でポチポチで公開しました。
LoadBalancerタイプで80->8080のポートマッピングで定義しました。
作成されると以下のようにServiceの詳細を見ることができ、外部エンドポイントが定義されていることが確認できます。

デプロイされたことの確認
外部からアクセスできることを
curl --location 'http://34.84.124.147/txt2img' \
--header 'Content-Type: application/json' \
-d '{
"prompt": "a photograph of an astronaut riding a horse"
}'
で確認しました。レスポンスは
{"data": "/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgK・・・・・"}
で画像データがBase64文字列で返ります。
いくつか生成された画像を載せます。




どれもちゃんと画像生成ができ、responseとして返せていることを確認できました。
また、全てのresponseは7~8秒ぐらいで返ってきます。Colabで試した時は25秒ぐらいかかるので、いい感じのレイテンシーです。
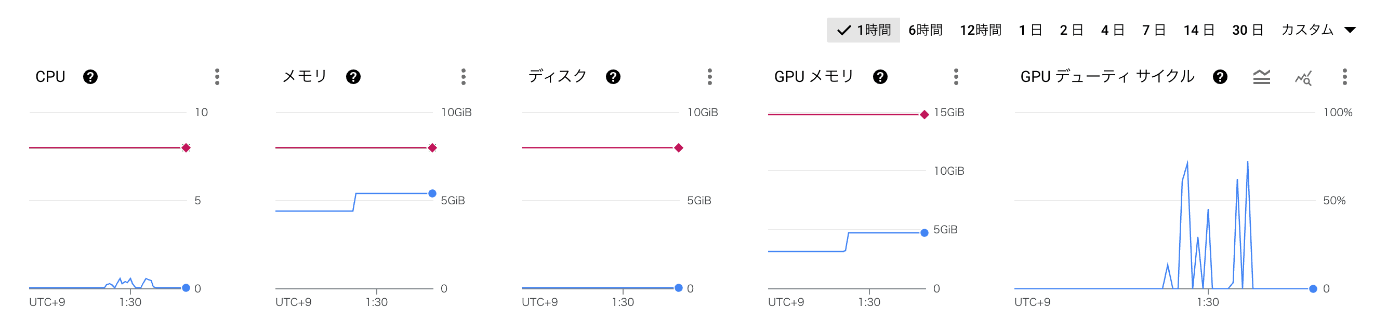
以下のようにリソース使用状況モニタリングできます。GPUが仕事してくれていることが確認できます。
まとめ
今回はGKE AutopilotでGPU環境を用意し、その上でStable Diffusionによる画像生成を行いました。また、その処理を推論エンドポイントで定義し、Web APIとしてリクエストを受け付けレスポンスを返すことができることを確認できました。
実は、巷で有名なstable-diffusion-webuiというWebアプリケーションがあります。これは内部的にDiffusersを使いつつもWebUIを提供し簡単に画像生成ができます。
そして、このstable-diffusion-webuiにはapiモードもありました。最初はこのapiモードでデプロイしようと試みましたが、
- docker build, deploy時の処理を分ける必要があった(そのままでは使えなかった)
- imageサイズが大きくなりすぎる
- buildに時間がかかる
等、APIを提供する上で不要なものまでついてきて色々不都合があったので、自前でDiffusersでモデルを操作する方法に変えました。これにより比較的柔軟に拡張ができます。
例えば、
- CheckPointのモデルを変更する
- CheckPointのモデルをコンテナ起動時に指定できるようにできる
- Loraモデルを追加する
- その他、Diffusersができることは全てできる
といったことは実現できます。また、この構成にすることでArtifact Registryにあげたimageのサイズが3.8GBと比較的小さく納めることができた(stable-diffusion-webuiをそのまま使うと17GBぐらいになる)ので、GKEでpod起動時のimage pullに時間がかかり、起動時間が長くなるという問題もそこまで顕著ではなくなりました。もちろんLoraの追加等すれば起動するのに時間はかかるようになるとは思います。
ちなみに、GKE上でstable-diffusion-webuiをデプロイする際に起動時間を最適化した話↓はとても勉強になります。
また、Diffusersを直接操作するので、diffuser modelとして公開されているモデルもsafetensors形式のモデルもloadすることができます。このモデルが差し替えやすいのは強みです。
また、Colabでの試行錯誤をそのまま反映できるのも良いところだと思います。もし実Productとして継続的に開発しデプロイし運用するとなるとGKE Autopilotとの組み合わせで高いメンテナンス性を担保できるようになる感触ではあります。
まとめると、GKE AutopilotはGPU環境を簡単に用意でき、パフォーマンスにも優れた生成AIの推論エンドポイントを提供することができます。以下でもおすすめのユースケースとして述べられています。
この生成AI時代にGKE Autopilot使ってみてはいかがでしょうか。
Discussion