PytorchによるLLMの高速化
アドベントカレンダー「ほぼ横浜の民」の11日目の記事です。
今年は LLM の高速化実装について書いています。私はLLMの専門家ではないですが前々から興味があったので少し勉強してみました。
この記事を読んでわかること
- LLMが文章を生成する仕組み
- torch.compile によって LLM はどのように高速化されるのか?
- Speculative Decoding とは?
背景
少し前に Accelerating Generative AI with Pytorch II: GPT, Fast という素晴らしいブログ記事を見かけました。この記事は Pytorch チームから出されたもので、素の Pytorch のみを用いて LLM の推論を 10 倍高速化できるというものでした。一体どのように 10 倍もの高速化を実現しているのか気になったので、個人的な勉強も兼ねてこの記事を書いています。本記事では、そもそも LLM がどのように文章を生成しているのかその仕組みを説明した後で、ブログ記事の公式実装である gpt-fast のコードを追いかけつつ、LLM の処理と高速化のための工夫を説明していきます。
LLM が文章を生成する仕組み
私たちが LLM にプロンプトを与えた場合、そのプロンプトはどのように処理されて LLM は応答文を生成するのでしょうか?gpt-fast で利用されている Llama2 の実装例を追いかけながら見ていくことにしましょう。(以降、Llama2 のことも LLM と呼んじゃってます)
モデル構造
まずはモデルを読み込みます。高速化のためにいろいろなオプションが定義されていますが、32層の transformer ブロックを含むモデルが読み込まれます。OpenAI の GPT シリーズも類似のモデル構造です。
model = _load_model(checkpoint_path, device, precision, use_tp)
>>> model
Transformer(
(tok_embeddings): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x TransformerBlock(
(attention): Attention(
(wqkv): Linear(in_features=4096, out_features=12288, bias=False)
(wo): Linear(in_features=4096, out_features=4096, bias=False)
(kv_cache): KVCache()
)
(feed_forward): FeedForward(
(w1): Linear(in_features=4096, out_features=11008, bias=False)
(w3): Linear(in_features=4096, out_features=11008, bias=False)
(w2): Linear(in_features=11008, out_features=4096, bias=False)
)
(ffn_norm): RMSNorm()
(attention_norm): RMSNorm()
)
)
(norm): RMSNorm()
(output): Linear(in_features=4096, out_features=32000, bias=False)
)
トークン化
次に、読み込んだモデルにテキスト文字列を与えて処理していくのですが、最初にテキスト文字列をモデルが解釈可能なフォーマットに変換する処理が必要になります。このとき、テキスト文字列は小さい文字列の単位 (トークン) に分割され、これをトークン化といいます。Llama2 におけるトークン化の実装を見てみましょう。例えば、プロンプトとして "Hello, my name is" という書きかけの文章を与えた場合を考えてみます。
[ 'Hello', ',', 'my', 'name', 'is']
こんな感じで分割されます。今回は単語や記号ごとに綺麗に分割されていますが、トークンの定義によって分割のされ方はさまざまです。では、このトークン化はどのように実行するのでしょうか?実は一般的にトークナイザーと呼ばれるトークン化を実行するためのモデルがあります。
トークナイザーにはテキストの分割 (トークン) の定義が予め登録されており、入力テキストを登録されたトークン単位に分割してくれます。なお、各トークンにはトークナイザーで管理される ID が存在し、トークナイザーは入力テキストをこの ID に変換し LLM に渡します。これも具体例を見てみましょう。

[引用]
GPT のトークナイザーは上のような感じで入力文字列を分割します。英語はもちろんさまざまな言語にも対応しています。ちなみにLlama2のトークナイザーのトークン定義ですが、以下のコードで確認したとこ ろ 32000 個でした。
from sentencepiece import SentencePieceProcessor
tokenizer = SentencePieceProcessor(model_file='Llama-2-7b-chat-hf/tokenizer.model')
print(tokenizer.GetPieceSize())
# 32000
ここまでの処理をまとめると、入力テキストはトークナイザーによってトークン単位に分割され、各トークンの ID 配列に変換される、ということがわかりました。ここまでの処理を gpt-fast の実装で確認してみましょう。
def encode_tokens(tokenizer, string, bos=True, device='cuda'):
tokens = tokenizer.encode(string)
if bos:
tokens = [tokenizer.bos_id()] + tokens
return torch.tensor(tokens, dtype=torch.int, device=device)
prompt = "Hello, my name is"
encoded = encode_tokens(tokenizer, prompt, bos=True, device="cuda")
encode_tokens 関数でプロンプトをトークン化し、トークナイザーに登録されている ID を取得します。なお、トークナイザーの bos_id メソッドにより Beginning of String(文字列の開始)を示す特別なトークンを追加しているため、最初にID 1 の空文字が追加されています。
>>> encoded
tensor([ 1, 15043, 29892, 590, 1024, 338], device='cuda:0',
dtype=torch.int32)
続いてモデルの forward 部分について説明します。トークナイザーによって得られたトークンの ID 配列をモデルに渡すと、モデル内部で保持している各トークンに対応した embedding を取り出して transformer の処理を実行していきます。Llama2 では (32000, 4096) の embedding 配列を保持しており、各トークンに対応する embedding の次元が 4096 であることが分かります。transformer 内部の計算については説明しませんが、各トークンの関係性をアテンションを用いて計算し、最終的には各トークンの次にくるトークンについてのロジット値が出力されます。
T = encoded.size(0)
input_pos = torch.arange(0, T, device=device) # [0, 1, 2, 3, 4, 5]
logits = model(encoded.view(1, -1), input_pos) # (1, 6, 32000)
logits の shape が (1, 6, 32000) であることからも分かるように、入力トークンそれぞれについて、事前登録されたトークンのロジット値が格納されています。この logits は 32000 個のトークンの出現確率を算出するためのロジット値です。
このロジットをもとに、入力トークンの次のトークンを決定する実装も見てみましょう。文章の生成においては、最後の入力トークンの次に来るトークンが知りたいので、logit[0, -1] で最後の入力トークンに対応するロジットのみを取得し、確率値に変換してます。最終的に得られる next_token もトークン ID になっています。
def multinomial_sample_one_no_sync(probs_sort):
q = torch.empty_like(probs_sort).exponential_(1)
return torch.argmax(probs_sort / q, dim=-1, keepdim=True).to(dtype=torch.int)
def logits_to_probs(logits, temperature: float = 1.0, top_k: Optional[int] = None):
logits = logits / max(temperature, 1e-5)
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
pivot = v.select(-1, -1).unsqueeze(-1)
logits = torch.where(logits < pivot, -float("Inf"), logits)
probs = torch.nn.functional.softmax(logits, dim=-1)
return probs
probs = logits_to_probs(logits[0, -1], temperature=0.8, top_k=200) # (32000)
next_token = multinomial_sample_one_no_sync(probs)
ここで予測された次のトークンを入力トークンの最後に加えて、更に次のトークンの予測を行うという処理を繰り返していけば文章を生成することができます。
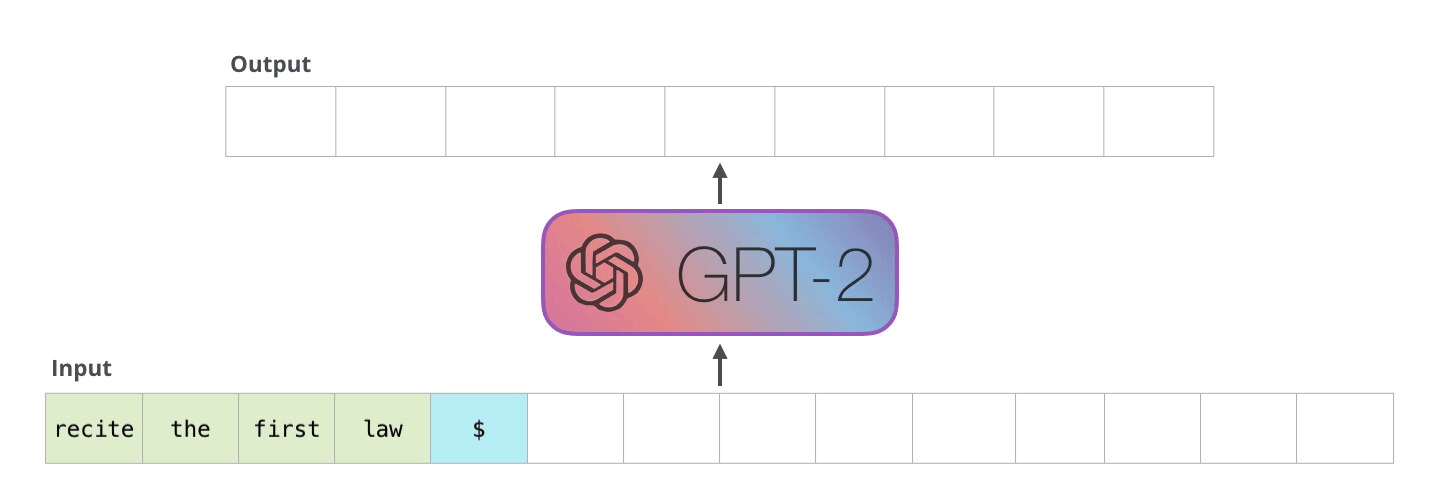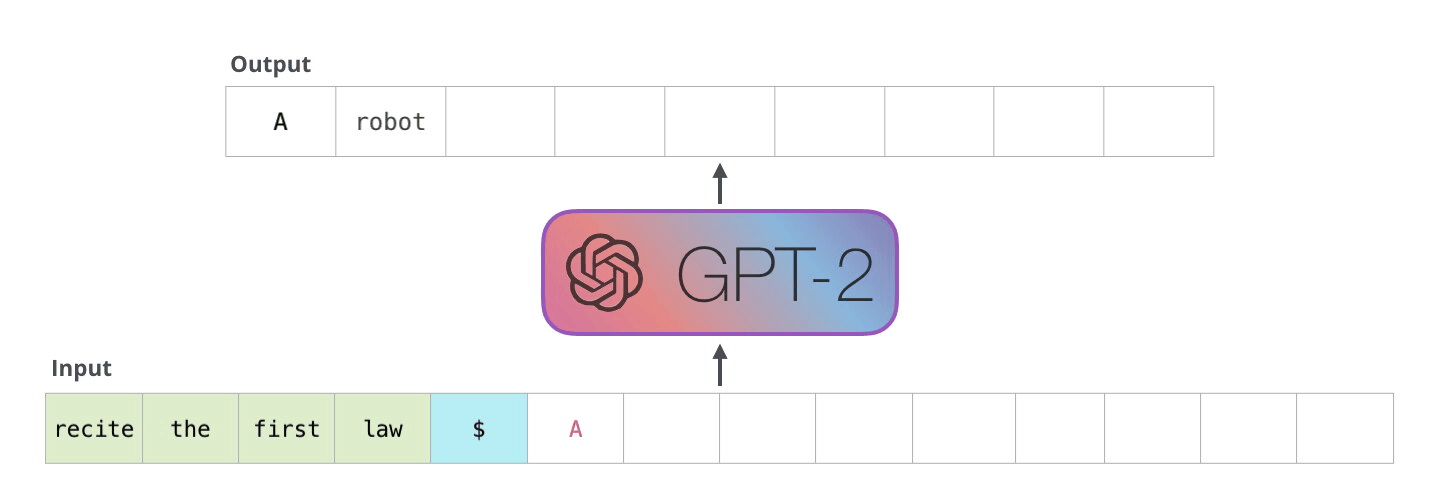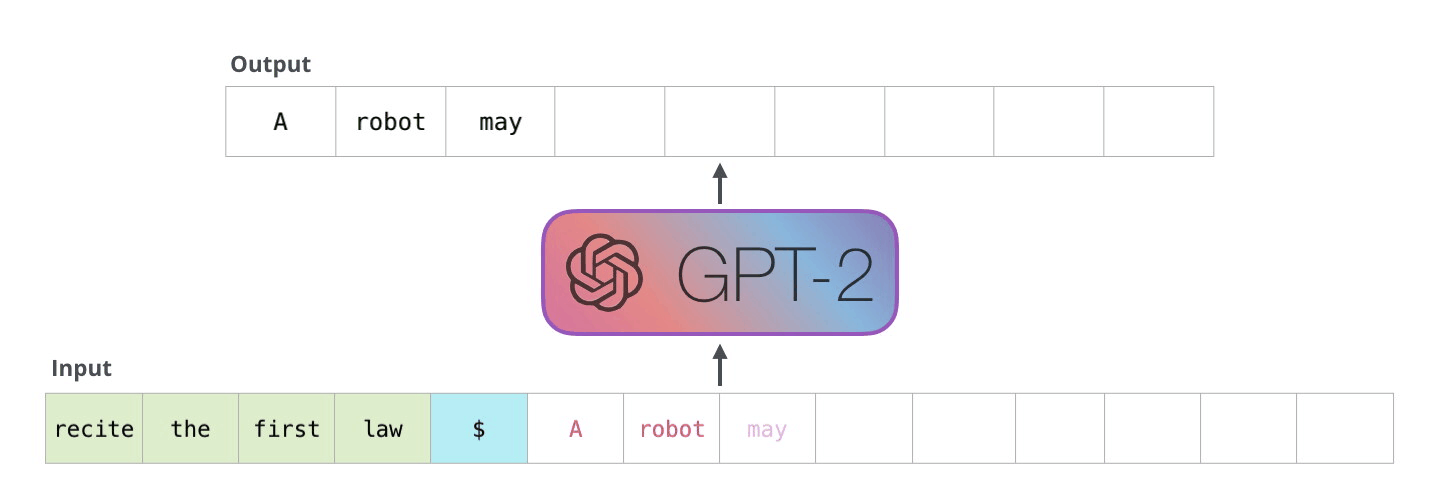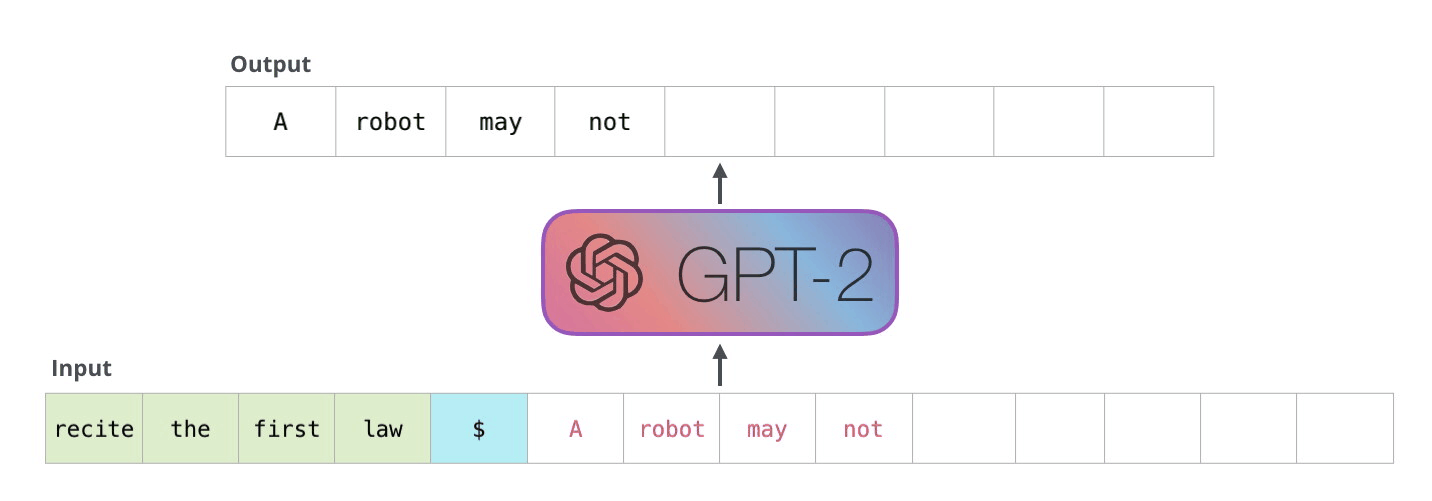
[引用]
ただ、このままでは大きな問題があります。それは無駄な計算が多いという点です。先ほどの図を見てもらうと分かりますが新しく追加したトークン以外は同様の処理を繰り返すことになります。このままでは 1 つのトークンを予測するために同じ計算を何回も実行してしまい非常に非効率的です。そこで提案されたのが kv-cache になります。簡単に言うと、同じ計算を繰り返す部分は計算の途中出力をキャッシュしておこうというもっともな実装になります。なぜ “kv”-cache というのかというと、アテンションにおける key ベクトルと value ベクトルをキャッシュするためです。以下の図で、入力トークンが増えたときも同じ計算が繰り返されてしまう様子が伝わると思います。
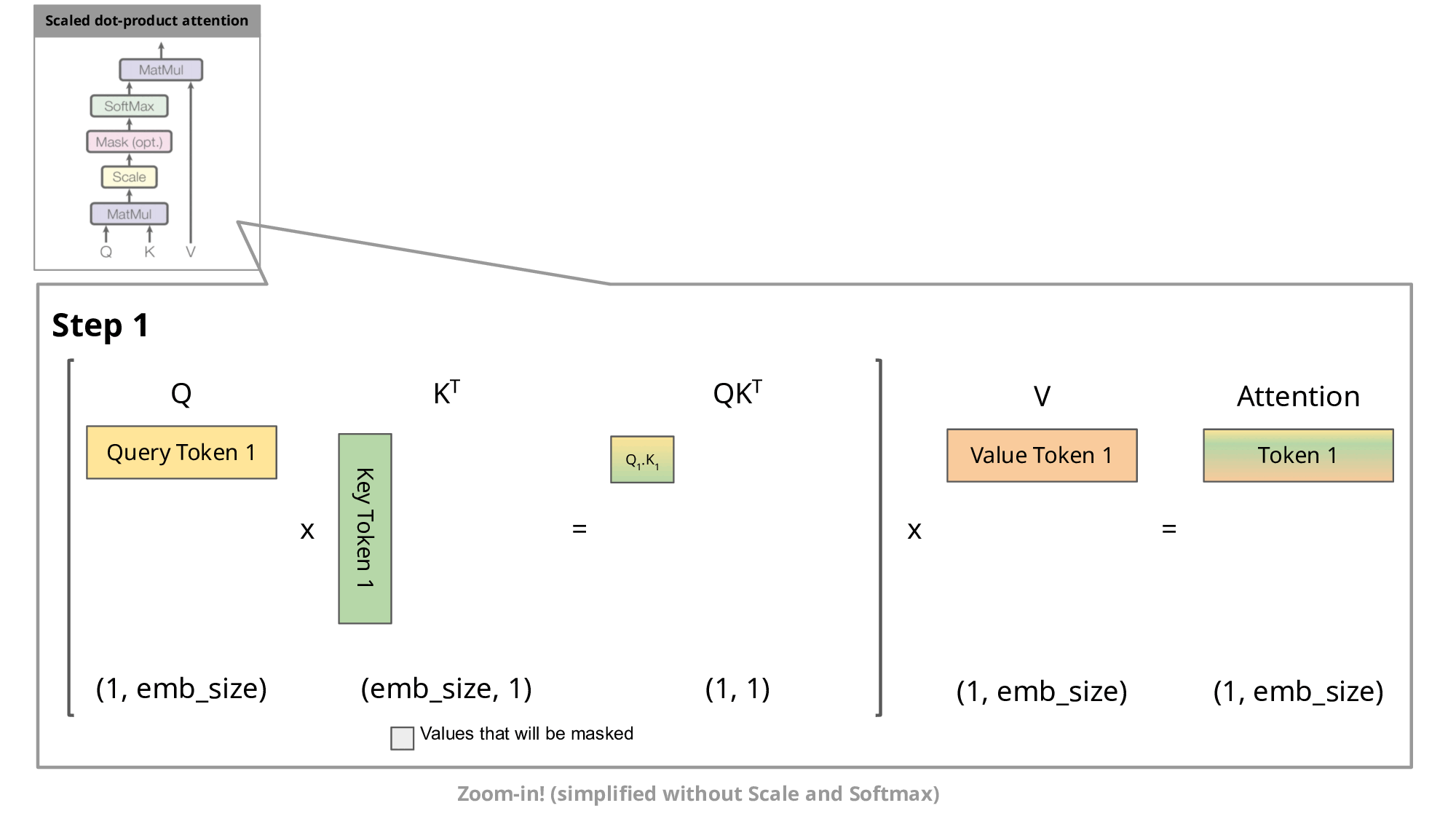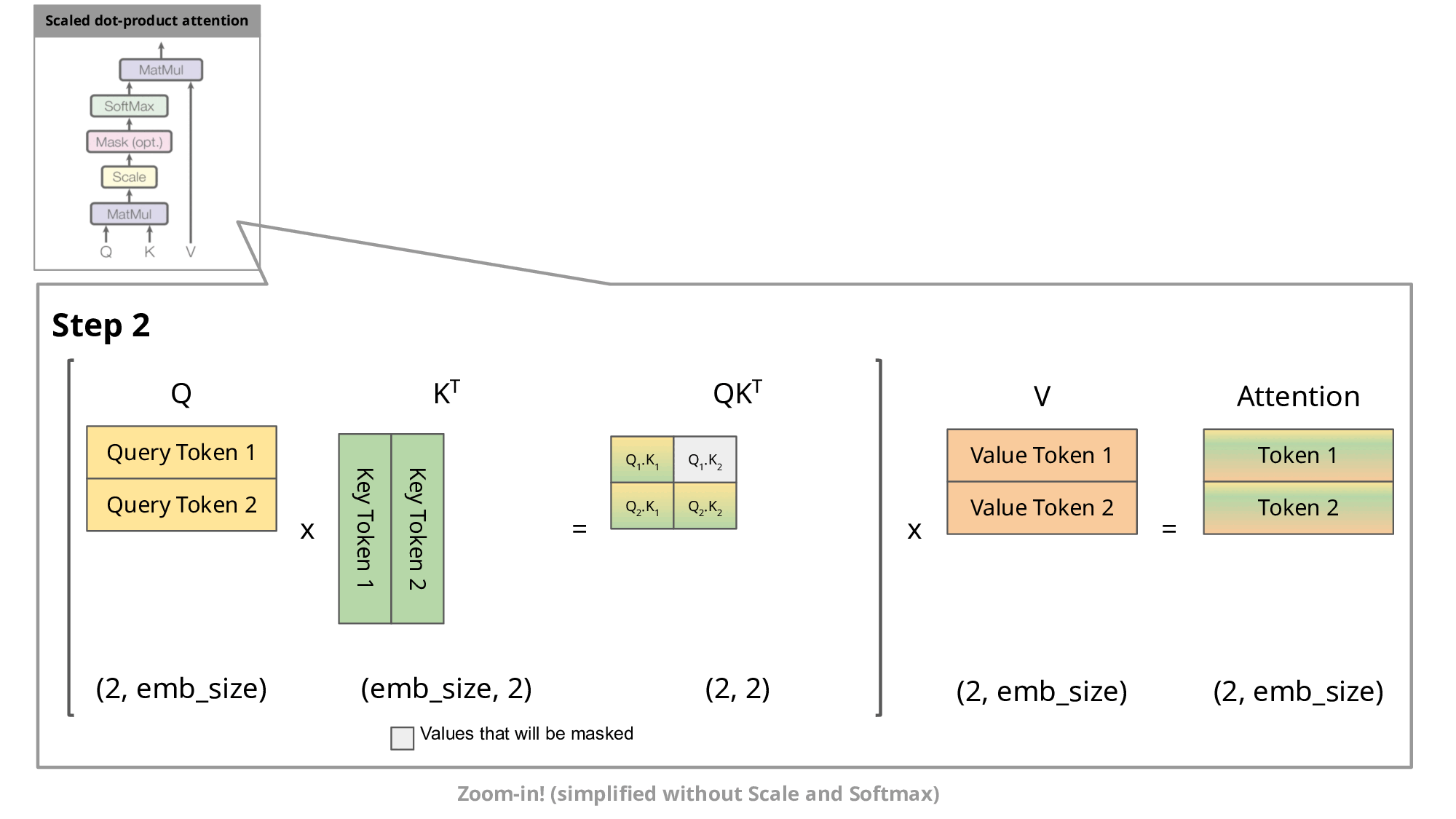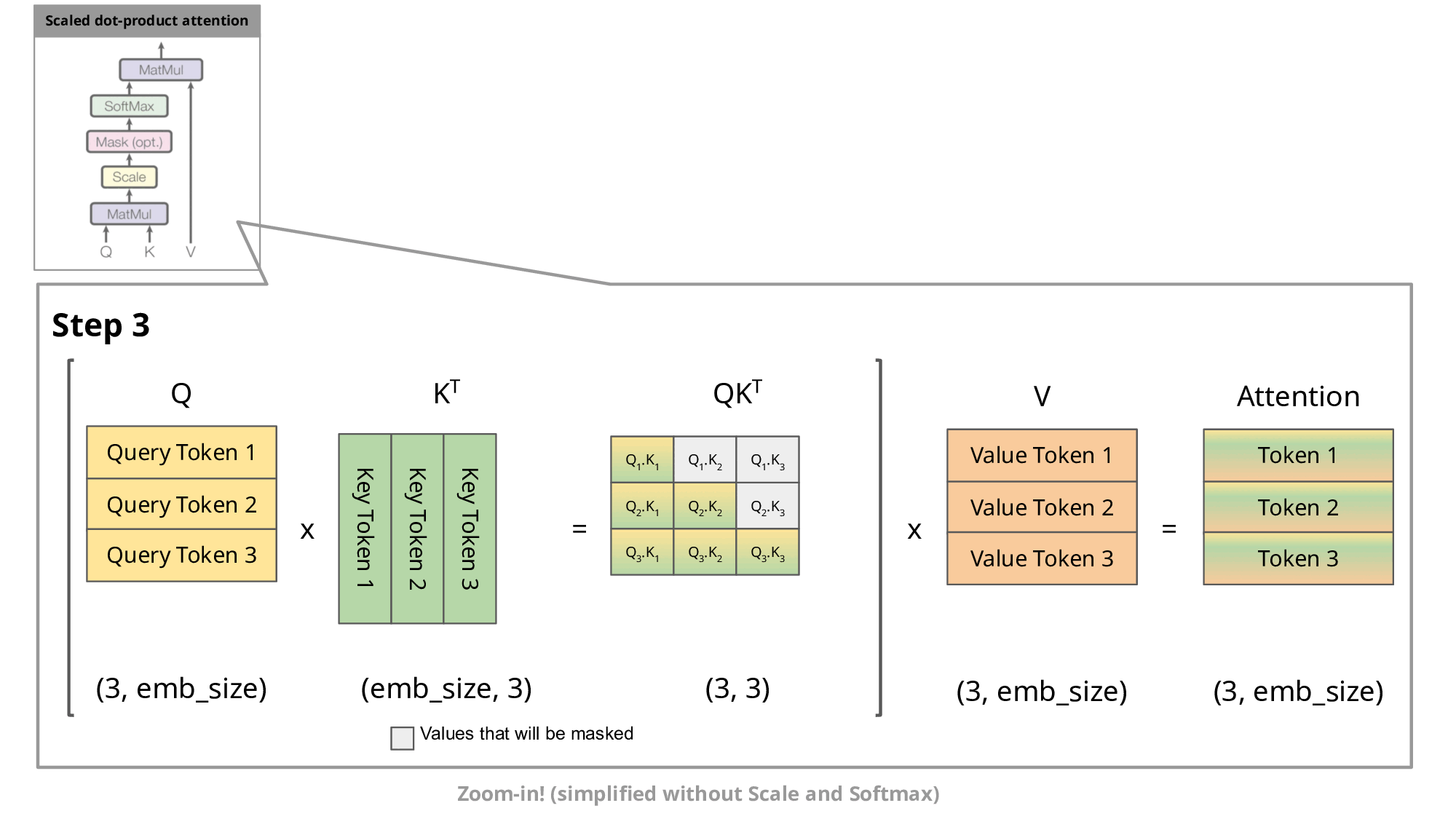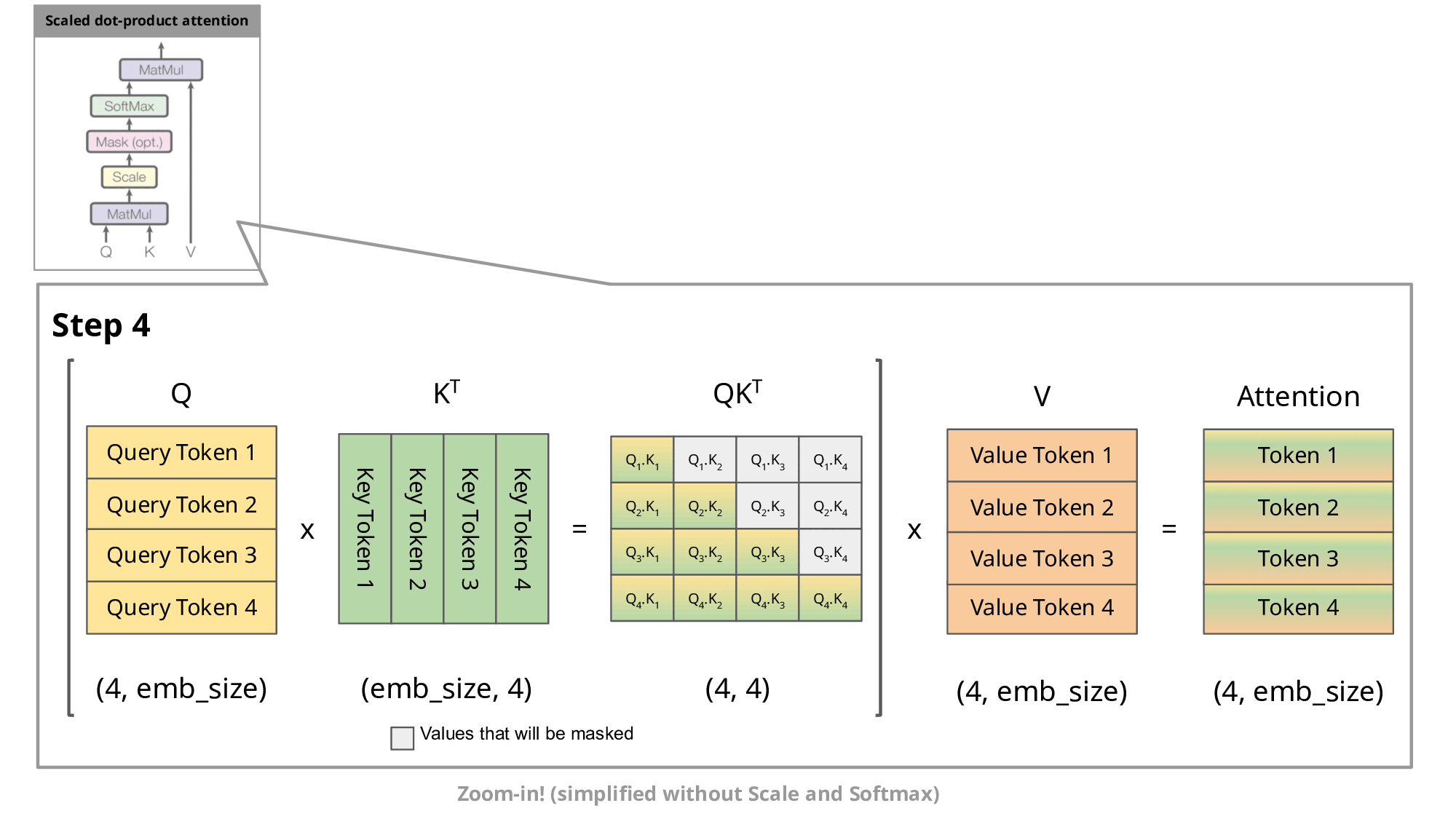
[引用]
この kv-cache までは多くの OSS で実装されており、ここまでが LLM の基本的な処理フローと実装についての説明になります。いよいよここから LLM の高速化について説明していきます。
LLMの高速化テクニック
Pytorch チームのブログでは高速化のための工夫が主に4点説明されていました。
- torch.compile の活用
- モデルの量子化
- Speculative Decoding
- テンソル並列化
個人的には、1 と 3 が気になりましたので、今回はこの2つについて説明していきます。
torch.compile による高速化
torch.compile は、PyTorch 2.0 から導入された機能で、Pytorch コードを最適化されたカーネルに JIT コンパイルして実行速度を向上させることができます。ちなみに JIT コンパイルは Just-In-Timeコンパイルの略で、プログラムの実行時にコンパイルを行うという意味です。
JITコンパイルすれば、何らかの最適化が実行されて速度が向上しそうな気はしますが、具体的に何が最適化されて高速化につながっているのでしょうか。ブログの内容を参照しつつ説明したいと思います。今回、LLMを torch.compie することによって高速化する主なポイントは2つです。
CUDAGraph によるオーバーヘッド削減
1つ目は CUDAGraph による最適化です。CUDAGraph は CUDA 10 から導入された機能で、一連の CUDA カーネルを個別に起動される操作ではなく、単一のユニット (複数の操作のグラフ) として定義およびカプセル化してくれます。これによって、単一の CPU 操作を通じて複数の操作が GPU に送信されるため、GPU への送信オーバーヘッドが削減されます。以下の図を見ていただくのが早いですね。
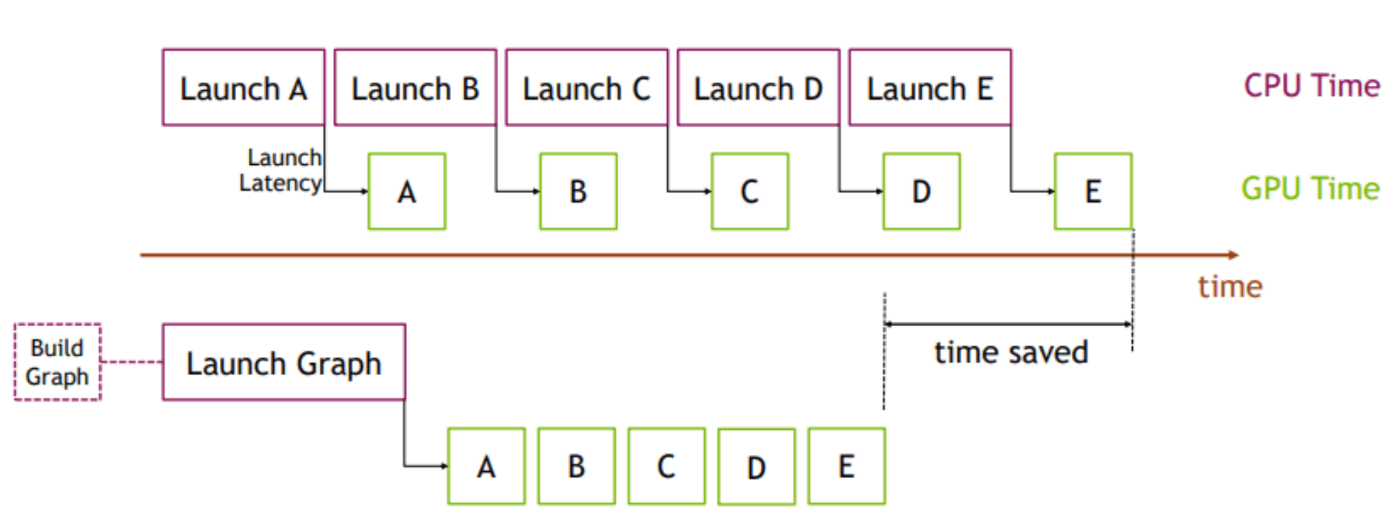
CUDAGraph の利用メリットのイメージ [引用]
torch.compile を使うことで、自動で CUDAGraph の恩恵を受けることができるようになるので非常に便利です。なお、さらに詳細な説明については Accelerating PyTorch with CUDA Graphs をご覧ください。
Transformer デコードにおける高速なカーネルの生成
2つ目は、torch.compile がより高速なカーネルを生成できるという点になります。CuBLAS や FlashAttention2 といったカーネルよりもさらに高速になるというのはちょっと違和感があるかもしれませんが、Transformer のデコード処理ならではの高速化ポイントになります。Transformer のデコード処理では、バッチサイズが 1 であるとともに、kv-cache のおかげで、アテンションの計算は「行列と行列の積」ではなく「行列とベクトルの積」で計算されることになります。これが何を意味するかといいますと、Transformer のデコード処理は従来のアテンションの計算よりも行列積にかかる計算コストが小さく、処理全体がメモリ帯域幅に制限される、つまり、行列積部分の処理高速化よりもメモリアクセスの最適化やデータ転送の効率化などが支配的になるということを意味しています。このようなデータの読み込み・書き込みに関する処理はコンパイラによって自動生成される範囲になるため、torch.compile は Transformer のデコード処理において高速なカーネルを生成できるのです。
Pytorch チームのブログでは、torch.mm([1, D_IN], [D_IN, D_OUT]) というベクトルと行列の積に対して、CuBLAS による行列積と torch.compile が生成したカーネルによる行列積を比較しており、torch.compile のカーネルのほうが高速であることが示されています。

torch.compile 適用における課題
では実際に torch.compile を用いて LLM の推論を高速化していきたいのですがちょっとした問題があります。それは kv-cache 部分の高速化です。何も考えずに kv-cache の実装をしてしまうと、forward するたびにキャッシュ配列の要素数が増加していきます。キャッシュが増大するたびに kv キャッシュの再割り当ておよびコピーが発生してしまいコストがかかるという点は自明な問題ですが、CUDAGraph のような予めGPU上の操作グラフ構造を定義しておく高速化アプローチを有効活用できなくなるというのが最も手痛いですね。この課題を解決するために gpt-fast では静的な kv-cache を採用しています。ご想像の通り、あらかじめ kv-cache のための配列を準備しておき、必要な部分のみ読み込むというものです。gpt-fast では以下の部分で実装されているようです。
with torch.device(device):
model.setup_caches(max_batch_size=1, max_seq_length=max_seq_length)
静的な kv-cache を導入したことにより、CUDAGraph のような高速化アプローチの恩恵を最大限に受けることができるようになりましたので、デコード処理を最適化していきます。torch.compile は以下のように簡単に適用することができます。
decode_one_token = torch.compile(decode_one_token, mode="reduce-overhead", fullgraph=True)
なお、テキスト生成のタスクは、プロンプト全体を処理する「プレフィル」と、各トークンが自己回帰的に生成される「デコード」の2段階のプロセスと考えることができ、前者はプロンプトの長さを固定できないため別々にコンパイルする必要があります。以下のように入力が可変のときにも簡単に対応できるのは良いですね。
prefill = torch.compile(prefill, dynamic=True, fullgraph=True)
具体的な速度改善幅については、Pytorch チームのブログを引用させてもらいますが、静的な kv-cache を導入して torch.compile を適用するだけで4倍もの高速化を実現できるのですから驚きです。

Speculative Decoding
次にLLMならではのアプローチとして、Speculative Decoding による高速化が紹介されていたので説明していきます。これは Fast Inference from Transformers via Speculative Decoding で提案された Transformer の推論高速化手法です。Speculative Decoding では、同じトークナイザーを用いたドラフトモデル(小さいモデル)と検証モデル(大きいモデル)を使用します。ちなみに gpt-fast のリポジトリには、ドラフトモデルとして Llama-7B、検証モデルとして Llama-70B を用いた例が載っています。以下に Speculative Decoding の処理フローを示します。
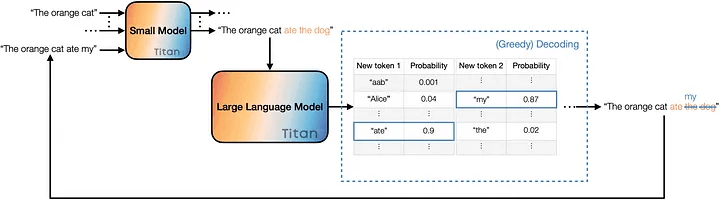
[引用]
-
ドラフトモデルで自己回帰的にK個のトークンを生成する。 Kは任意の個数でここでは 3 として考えてみましょう。上図のように "The orange cat" というプロンプトが与えられてその続きを生成することを考えます。ドラフトモデルは以下のように 3 回の forward を行い、"The orange cat ate the dog" というドラフト文を得ます。
- 1st forward: "The orange cat ate"
- 2nd forward: "The orange cat ate the"
- 3rd forward: "The orange cat ate the dog"
-
新しく生成された入力を検証モデルで forward させ、入力トークンに対応する確率値を得る。 ドラフトモデルは自己回帰的に複数回 forward させましたが、より大きな検証モデルは高速化のためにドラフトモデルの出力トークンを並列処理し、ドラフトモデルの出力の妥当性を検証します。
- (draft) output : "The orange cat ate the dog"
- (verifier) input : "The orange cat ate the dog"
- (verifier) output : "The orange cat ate my hoge1 hoge2"
-
ドラフトモデルの出力をいくつ受理するか決める。 ドラフトモデルと検証モデルの出力を比較して、ドラフトモデルの出力の何個目までを採用できるか決めます。Speculative Decoding の説明でよくあるのは、上図のようにドラフトモデルと検証モデルの出力トークンが一致しているところまでを採用するというものです。上図の例では ate までは同じ単語がサンプリングされていますので、検証モデルは ate までの生成結果を受理することになります。これが gpt-fast においてどのように実装されているかというと以下の部分になります。
# q: target prob, p: draft prob
# q >= p: always accept draft token
# q < p: q/p prob to accept draft token
p = draft_probs[torch.arange(0, speculate_k, device=device), draft_tokens]
q = target_probs[torch.arange(0, speculate_k, device=device), draft_tokens]
accept_draft_prob = torch.minimum(torch.ones(()), q[:speculate_k]/ p)
rejected_locations = (torch.rand_like(accept_draft_prob) > accept_draft_prob).nonzero()
target_prob というのは検証モデルの確率値を指しています。上のコードでは、ドラフトモデルの出力トークンについて、ドラフトモデルと検証モデルそれぞれの確率値を比較し、ドラフトモデルの確率値が高い出力トークンを棄却する、という処理になっています。つまり、ある出力トークンについてドラフトモデルの確率値のみ高い場合は、ドラフトモデルが当該トークンを過度に重視している可能性があるために採用しないということになります。ちなみに論文では確率分布の調整処理が入ったりしますがここでは割愛します。
あとは受理したトークンをドラフトモデルの入力トークンとして与え、1~3 の処理を繰り返していきます。モデルの組み合わせや生成されたテキストによっても異なりますが、うまくいけば 2~3 倍程度の高速化につながるようです。
Speculative Decoding は、「ドラフトモデルによるトークン生成 + 検証モデルによるトークンの並列検証」が「検証モデルによる自己回帰的デコード処理」よりも短い時間で済む場合に高速です。したがって、ドラフトモデルが “使える” ドラフトトークンを生成してくれなければ逆に遅くなってしまうこともあるので注意が必要です。また、ドラフトモデルでいくつのトークンを生成するかなども実際に動かしてみながらチューニングが必要だと思います。ただ、検証モデルの出力品質を担保したまま高速に推論できるという点は非常に魅力的ですね。
所感
こんなに書くつもりはなかったのですがわからない部分がたくさん出てきて時間がかかってしまいました。なんとなく雰囲気で理解していた部分をちょっとだけクリアに理解できたのでよかったです。
Discussion