スコアベース生成モデルと Consistency Models
本記事は、裏アドベントカレンダー「ほぼ横浜の民2024」の9日目の記事です。最近は業務でも生成モデルを扱うことが多く、生成モデルの高速化にも興味が出てきたので書いてみようと思います。生成モデルと言いつつ、本記事では拡散モデルに絞って基本的な理論とその高速化手法の1つである Consistency Models についてざっくり説明していこうと思います。あまり数学的に厳密に説明できていない部分もあり、私なりの解釈に基づく説明も入ってしまっていますがご容赦ください。
この記事を読んでわかること
- 拡散モデルがデータを生成する仕組み
- スコアベース生成モデルとは? SDE, PF ODE とは?
- Consistency Models とは?
拡散モデルの理論を振り返ってみる
拡散モデルのコンセプト
改めて拡散モデルの理論をざっくりと説明したいと思います。拡散モデルは生成モデルの一種であり、以下の2つのプロセスから構成されます。なお、以下の図では実データの分布における時刻を
- 順拡散過程:微小なノイズを繰り返しデータに付与し、完全なノイズ状態とする
- 逆拡散過程:各時刻で付与された微小なノイズ量を繰り返し推定し、最終的なデータを生成する
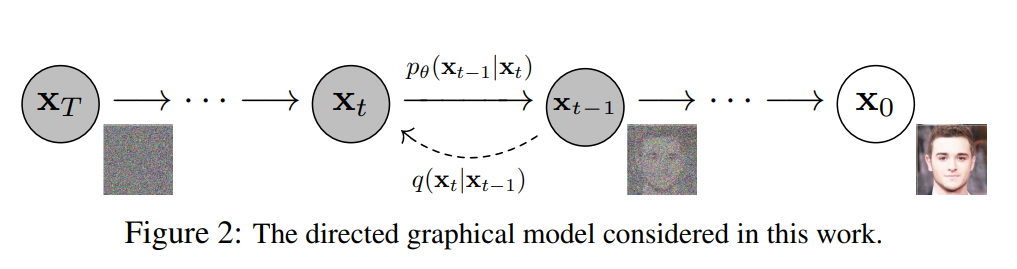
有名な拡散モデル手法である上図の DDPM (Denoising Diffusion Probabilistic Models) は離散的な拡散過程を考えるものですが、連続的な拡散過程を考える研究の流れもあり、そちらでは拡散モデルは「スコアベース生成モデル」として定義されることが多いです。今回、Consistency Models を理解するにあたって、拡散モデルをスコアベース生成モデルとして解釈するところから始めようと思います。(論文の流れがそんな感じです)
連続的な拡散過程(stochastic differential equation: SDE)
連続的な拡散過程を考えるとき、拡散モデルの順拡散過程は以下の確率微分方程式 (stochastic differential equation: SDE) で定義されます。
数式において、
以下の図は、連続的な拡散過程における SDE の軌道を可視化したものになります。実データ

ノイズが付与された各時刻の画像も一緒に可視化すると以下のような感じです。この動画は、実データの分布
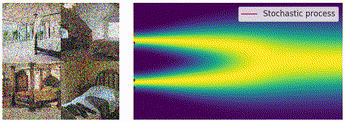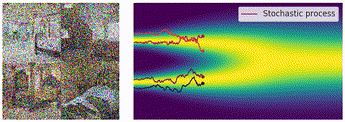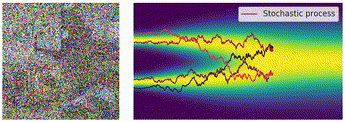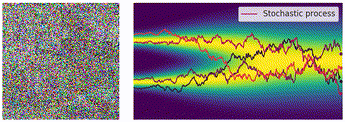
連続的な逆拡散過程(Reverse SDE)
なお、任意のSDEには逆SDEを定義することができ、この逆SDEをSDEのソルバーなどで数値的に解くことで、逆拡散過程を解くことができます。逆SDEは以下で定式化できます。
逆SDEを解くときには任意の時刻
今回も先ほどのように図でイメージを確認しておきます。今回は逆拡散過程にあたるので、ノイズサンプル
ノイズ画像から徐々にノイズが除去されていく過程も一緒に可視化したものがこちらになります。こちらも順拡散過程と同様に、SDEの軌道がかなり不安定になっていることがわかります。
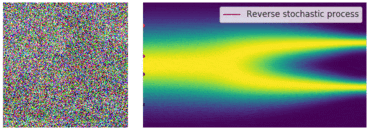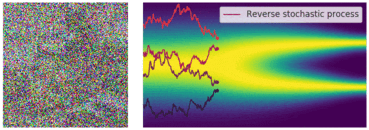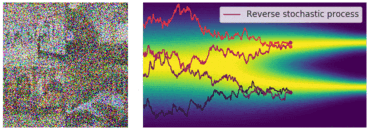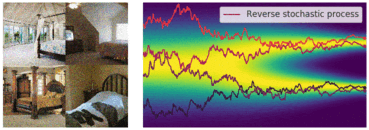
連続的かつ決定論的な過程で制御しやすくする(Probability Flow ODE)
SDEによっても高品質な生成は可能なのですが、定式化にランダムなノイズ頂が含まれるために厳密に正確なスコア関数を求めることができていません。この問題に対して提案されたのがProbability Flow ODEです。PF ODEは以下の式で定義されます。
実は、任意のSDEの周辺分布

PF ODE を扱いやすい過程とする (empirical PF ODE)
ここで、PF ODEの式を解析的に扱いやすい過程とするために、ドリフト項
この式を経験的 PF ODE (Empirical PF ODE) と呼びます。ここで、時刻
拡散モデルは推論コストが高い
ここまで連続的な拡散過程の定式化を見てきたことで、拡散過程は微分方程式で表現することが可能で、定式化を工夫することにより安定的な解軌道を獲得することができるとともに既存のODEソルバーで計算できることがわかってきました。ただ、高速なODEソルバーの利用や蒸留などの高速な推論を行うさまざまな工夫がなされていたとしても、最低でも10回程度のforwardが必要なことには変わりなく、拡散モデルの推論が高コストであるということは明確な問題として残っていました。
この問題に対する解決策として「1ステップで推論する」というアイデアが提案され、これが Consistency Models のコンセプトとなっています。前置きが長くなりましたが、ここからは Consistency Models の内容を具体的に説明していきます。
Consistency Models とは?
基本的なアイデア
どのように1ステップで推論するのかと言うと、「ODE軌道上のどの位置からも一貫して同一の終点を予測できるようにする」という学習を行います。この一貫した予測に関わる制約から Consistency Models(一貫性モデル)と呼ばれています。PF ODE の解軌道

- Consistency Distillation (CD): 既存の拡散モデルを蒸留して学習する
- Consistency Training (CT): ゼロから一貫性モデルを学習する
Consistency Distillation (CD): 既存の拡散モデルを蒸留して学習する
具体的には、以下の式で「同一ODE軌道において隣接したサンプル点が同じ終点を予測する」という条件で学習を行います。
少し複雑に見えますが順を追ってみていきます。
-
任意の時刻の一貫性モデルの予測値を計算する:任意の時刻
t_{n+1} \mathbf{x}_{t_{n+1}} f_{\boldsymbol{\theta}} (\mathbf{x}_{t_{n+1}}, t_{n+1}) -
同一 ODE 軌道上において隣接する時刻の予測値を計算する:同一 ODE 軌道上における隣接する時刻のサンプルはどのように計算されるかというと、学習済みの拡散モデル
\phi \hat{\mathbf{x}}_{t_n}^{\phi} f_{\boldsymbol{\theta}} (\hat{\mathbf{x}}_{t_n}^{\phi}, t_n) f_{\boldsymbol{\theta}^{-}} (\hat{\mathbf{x}}_{t_n}^{\phi}, t_n) -
一貫性モデルの予測値が隣接点同士で同じになることを計算する:隣接点における終端の予測を距離関数
d l_1 l_2 \lambda(t_n)
Consistency Training (CT): ゼロから一貫性モデルを学習する
次に既存の拡散モデルを用いずに一貫性モデルを学習する方法を紹介します。損失関数は以下で定式化されます。
Consistency Distillation と非常に似た定式化になっていることがわかります。この定式化の理論的な詳細は省きますが、「同じノイズを異なる強度でデータに付与する」という処理によって同一ODE軌道上の隣接データのサンプリングを実現しています。なお、学習済み拡散モデルがスコアを正しく推定できている場合には、Consistency Distillation も Consistency Training も理論的には同じということがわかっています。
Consistency Models の推論
Consistency Models の推論は基本的に1回の forward だけで実現できますが、forward の回数を増やして生成品質を向上させることも可能です。具体的には、一度生成された

まとめ
今回は離散時間における拡散過程を扱ったDDPMの説明に始まり、連続時間における拡散過程とも捉えることができるスコアベース生成モデルについてざっくりと概念を説明し、最終的には Consistency Models について紹介しました。Consistency Models の後継の研究として Latent Consistency Models、Improved Consistency Models、Consistency Trajectory Models などいくつかあるのですが、今回はここまでにしておきます。最後まで読んでいただきありがとうございました。
Reference
- Jonathan Ho et al. “Denoising diffusion probabilistic models.” arxiv Preprint arxiv:2006.11239 (2020).
- Yang Song, et al. “Score-Based Generative Modeling through Stochastic Differential Equations.” ICLR 2021.
- Song et al. “Consistency Models” arxiv Preprint arxiv:2303.01469 (2023)
- What are Diffusion Models?
- Generative Modeling by Estimating Gradients of the Data Distribution
- 【AI論文解説】Consistency ModelsとRectified Flow ~解説編Part1~
Discussion