読者コミュニティ|オリジナル競馬予想AI 発展編
本の感想や質問をお気軽にコメントしてください。
回収率シミュレーションのコードを打つとエラーが出ます
2 # テストデータで予測
3 df_test['pred'] = model_exp.predict(test.drop(['馬番', '着順', '期待値', 'オッズ'], axis=1))
----> 4 df_test['return'] = df['着順']*df['オッズ']
5 # 各レースで一番評価が高い馬を抽出
6 df_test = df_test.sort_values('pred', ascending=False).groupby(level=0).nth(0)
NameError: name 'df' is not defined
すみません、ケアレスミスです。df を df_test にしてください。
書籍の方も修正しておきます。
ありがとうございます。
こちら修正後プロットするとグラフが右肩あがりになってしまっているのは
どこか違っているでしょうか?
どうしてもランダム要素が出てしまうので、全く同じにはなりません。
参考までに、グラフを見せてもらえないでしょうか。
このような感じです。
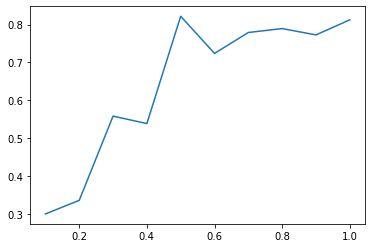
ありがとうございます。
回収率型モデルは、目的変数の設定がシビアな一面があります。
私の経験では、大穴ばかりを狙うようになって回収率がガタ落ちすることがありました。(大穴は統計上回収率が良くありません。)
今回も同様のケースかもしれません。
緩和する一例として、目的変数のオッズを足切りするのが考えられます。
df['期待値'] = df['着順'] * df['オッズ'].map(lambda x: 100 if x>100 else x)
オッズに傾斜をかけたりする手もあります。
これが正解というものは無く、私も試行錯誤しております。
df['jockey_id'] = jockey_id_list
を2行上にしてください! 書籍も訂正します。
予測の部分でValueErrorが発生するのですが、どういう意味の処理なのでしょうか?
また、解決方法はありますか?
#予測
pred_table = df_pred[['馬番']].copy()
pred_table['実力'] = model_rank.predict(df_pred.drop(['馬番'], axis=1))
どういったエラーが出ているか詳しく教えてもらえると助かります。
ValueError: Input 0 of layer "sequential" is incompatible with the layer: expected shape=(None, 251), found shape=(None, 254)
です
学習時と予測時の列数が合致していないということですね。おそらくdf_predに余計なものが入っていると思われます。コードを変更された点はありますでしょうか。
ありがとうございます!
再度見直ししたところ動くようになりました。
モデル学習のpickleファイルからデータの取り出し方に問題があったようでした。
本書籍でAIの興味を持ち基本コピペで実装ができ、感謝しています。
①予想図や偏差値数値は算出されるのですが、以下、のメッセージがでますが問題はありますか?

②予想精度のチューニングは、
・過去のINPUTレース数を増やす
・上記以外に方法などご紹介いただける範囲で結構なので、ご教示いただければうれしいです。