フロントエンドの認可について(その1)
概要
どうもukmashiです。今年は年末なのに、年末感がなくて逆にびっくりしますね。
年末で時間を持て余してるので、燻製を作りながら、年末に仕事で練っていたフロントエンドにおける認可について、整理しようと思います。
なお、RBACやPBACなどの認可の種類に対する考え方については基本的に触れません。
本記事は2部作です。
本記事は3部作になりました。
-
フロントエンドの認可について(1)← 本記事
ReactやVueを始めとして、SPA、Next.js、Nuxt.jsに関する認可についてまとめます。 -
フロントエンドの認可について(2)
後半では、FEとBEで認可の処理が二元化してしまうのをどうクリアするかの提案です。 -
フロントエンドの認可について(3)
2での提案を具体的にReactのコードとして落とし込みました
本記事での用語
話を始める前に、用語整理しておきます。
-
Page
ブラウザで描画されるページのこと。
APIからデータがなくても、描画自体は可能です。 -
Data

APIから取得してくるJSONのこと。
と本記事内では定義します。
認可の目的
まずは、認可を行う目的と、FEに認可を入れると何が嬉しいかを整理します。
認可を行う目的
認可をすることで、適切なユーザーが、適切な処理を行うことが目的になります。
- Who is making the request?
誰がリクエストしているのか? - What are they trying to do?
何をしようとしているのか? - What are they doing it to?
何のために?
これを認可三大要素(Three main aspects of authorization)といい、認可をする上で、常に問い続ける内容です。
例えば、Postコントローラーへのアクションがあった場合
- Current Userが
- PostControllerのIndexにリクエストを
- Postの一覧を取得するために
参考:認可のアーキテクチャに関する考察(Authorization Academy IIを読んで)
もっと認可について、詳細を知りたい場合は、こちらがおすすめ
めっちゃわかりやすいです。
FEに認可を入れると何が嬉しいか
FEに認可を導入する目的は、ユーザー体験を向上させることになります。
- 誤ったユーザーに、必要ないメニューを表示させない
- 誤ったユーザーに、誤ったページを表示させない
- 誤ったユーザーに、誤った操作をさせない
などなどユーザーが操作に迷うことのないように、行動に制限をかけることに目的を持っています。詳細は後述しますが、セキュリティに関する点でのFEにおける認可は意味がありません。
セキュリティについて
SPAについて
セキュリティに関して話す前に、SPAの仕組みを整理します。
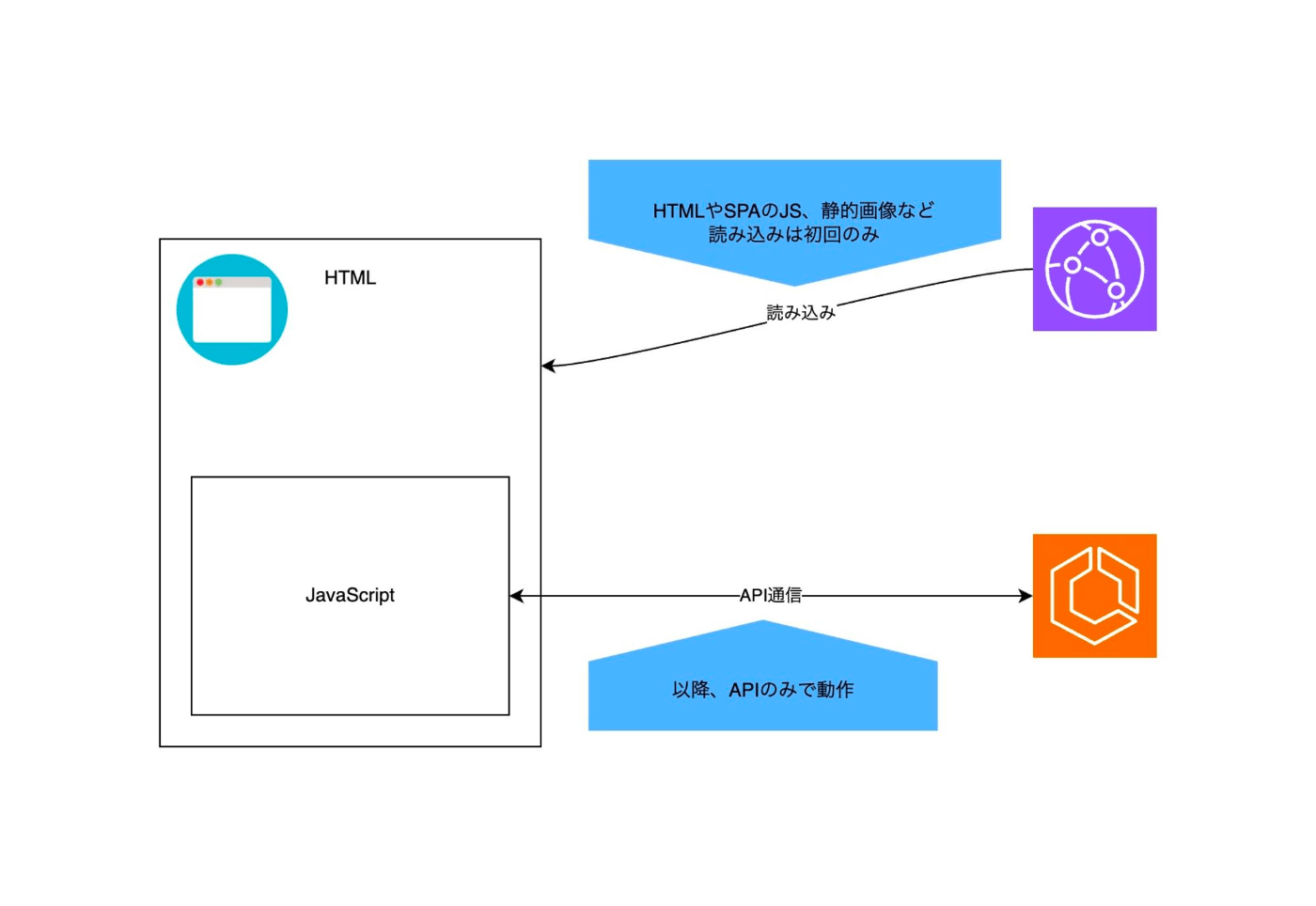
SPAは、初回訪問時にユーザーに全て(HTML、JS、画像など)を提供し、以後はブラウザ上で全てのレンダリングを完結させる仕組みです。データの取得に関しては、APIを通じて行います。このため、サーバー側にレンダリングの負荷がかからず、高速な表示が可能になります。
セキュリティについて
SPAの特性上、FEに関連するソースコードは全てクライアント側に公開されます。
- HTML
- JavaScript
- APIのエンドポイントに関するURL
- ロゴなどの静的画像
- i18nの翻訳情報
など、基本的にブラウザの検証モード等で閲覧可能です。
その上で、FEに認可を導入する主な理由は、先述の通りユーザー体験の向上のためです。
FEの認可の課題
FEに認可を導入すると、いくつかの課題が浮上します。これらの課題を一言で表すと、「認可処理が二元化する」ということです。
責務分離の観点から見ても
- BEはデータ操作に関する責任を持つ
- FEは表示制御に関する責任を持つ
という形になります。
例えば
- BE:管理者のみが操作可能なデータ処理
- FE:管理者のみに表示させたいメニュー
しかし、認可の処理は、BEとFEの両方で必要となります。
両方で認可処理を行うと、
- 認可処理が二元化し、管理が複雑になる
- 開発者のミスでBEとFE間で不一致が生じる
など課題がでてきます。
このような課題に関して、2部目では、どう解決するのがいいのかを提案していきます。
Discussion